こんにちは〜。
@sori883です!
今更ながらRAGのキャッチアップを始めたので、自分の理解向上も兼ねて記事にまとめてみました。
Bedrock ナレッジベース、RAGのキャッチアップをされている方の参考なれば幸いです。
目的・ゴール
- 目的
- RAGの概要を理解する
- Bedrock ナレッジベースを理解する
- ゴール
- Bedrock ナレッジベースを作成する
- ベクトルDBはOpenSearch Serviceを使用する
- Bedrock ナレッジベースを作成する
RAGとは
LLMは事前学習時の学習データに基づいて回答を生成します。
つまり、LLMの知識は事前学習時のデータに限定されるため、最新情報や社内ルールに基づいた回答の生成は難しいという課題がありました。
RAGは、このような課題を解決するために、外部データと連携し、LLMに最新情報や社内ルールを参照させる仕組みです。
RAGの仕組み
RAGには、大きく以下の2ステップがあります。
なお、本書では非構造化データとベクトルDBを使用した例を記載します。
インデックス作成
インデックス作成とは、データを解析し、検索可能な状態に整理することをさします。
処理イメージは以下の通りです。
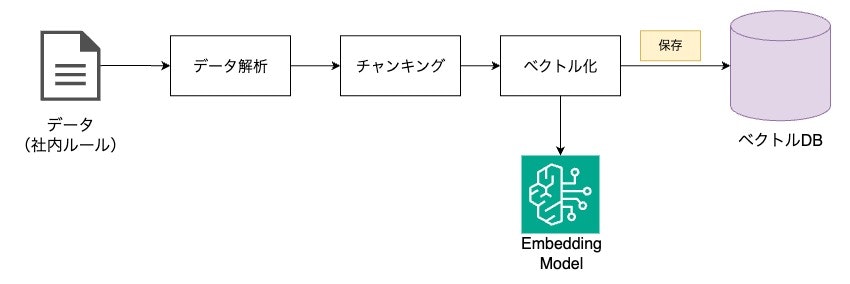
各処理の補足。
- データ解析
-
.txtや.mdを解析し、有効なテキストデータを取得 - 基盤モデルを使用することでマルチモーダルデータを解析可能
-
- チャンキング
- 解析したデータをLLMが利用しやすい単位に分割する
- ベクトル化
- Embedding Modelを使用し、チャンキングしたデータをベクトル化
処理された後、ベクトルDBには以下のような情報が格納されます。
テキスト: "Amazon Bedrock は、主要な AI 企業と Amazon の高性能な基盤モデルを使用しています。"
ベクトル: [0.041..., 0.056..., -0.018..., -0.012..., -0.020..., ...]
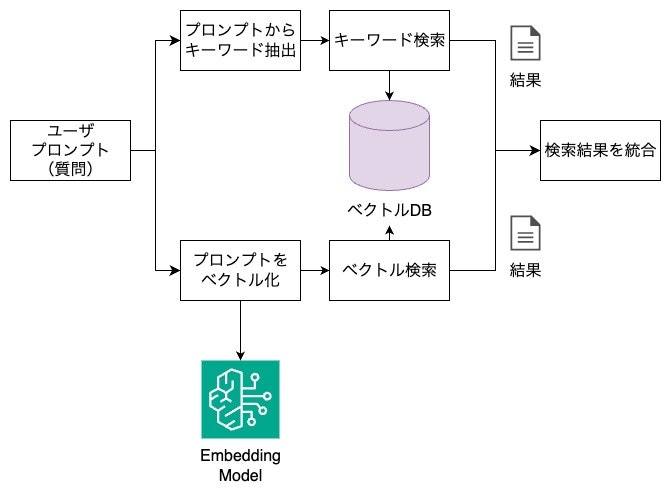
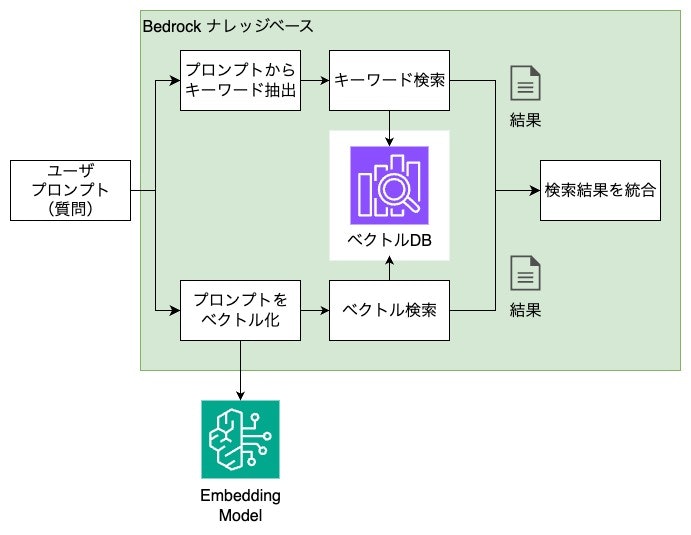
データ検索
データ検索とは、作成したインデックスを使用して、情報を検索することをさします。
データ検索には様々な手法がありますが、以下を一例として取り上げます。
- キーワード検索
- ユーザプロンプトからキーワードを抽出する
- キーワードに基づき、検索する
- キーワードで検索するためベクトルデータは不要
- ベクトル検索
- ユーザプロンプトをベクトル化する
- ベクトルに基づき意味的な類似性で検索する
- ハイブリッド検索
- キーワード検索とベクトル検索を組み合わせて検索する
- 両方の結果をスコアリングして統合
また、LLMのコンテキストには上限がありますから、データ検索では関連性の高いデータから上位数個だけ取得します。
ハイブリッド検索の処理イメージは以下の通りです。
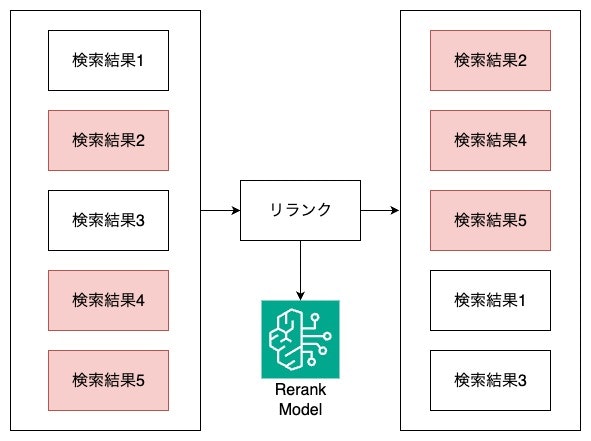
リランク
リランクでは、データ検索で一度取得した結果群を再評価し、関連性の高い回答順に並び替えをします。
これらの処理を行うことで、より信頼性の高い回答を得られやすくなります。
また、リランクの処理イメージは以下の通りです。
Bedrock ナレッジベースとは
RAGはなんとなく分かりました。
では、Bedrock ナレッジベースとは何をしているのでしょうか。
Amazon Bedrockユーザガイドを見ながら確認していきたいと思います。
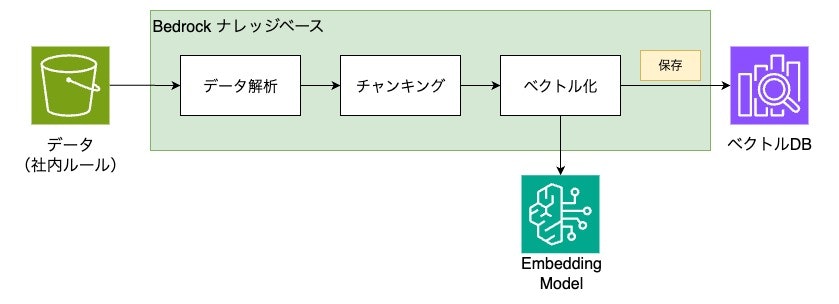
インデックス作成
Bedrockナレッジベースでは、インデックスを作成するために、以下の機能が利用できます。
- 解析戦略
- データソースに保存されているデータの解析戦略
- データソースの解析オプション
- チャンキング戦略
- 解析したデータをチャンキングする戦略
- ナレッジベースでのコンテンツチャンキングの仕組み
- ベクトル化、ベクトルの保存
上記の機能から、Bedrock ナレッジベースは、インデックス作成において以下の役割を担っていると言えそうです。
データ検索
さて、データ検索ではどうでしょうか?
Bedrockナレッジベースでは、データ検索をするためのAPIが用意されています。
ナレッジベースをクエリしてデータを取得する
RetrieveやRetrieveAndGenerateAPIにパラメータを渡すことで、ハイブリッド検索やセマンティック検索といった指定が可能となっています。
クエリとレスポンスの生成を設定してカスタマイズする
上記の機能から、Bedrock ナレッジベースは、データ検索において以下の役割を担っていると言えそうです。
また、リランクについてもリランク対応のモデルを選択することで利用できます。
ただし、対応モデルやリージョンは限定的です。
Bedrock ナレッジベースを構築してみる
Bedrock ナレッジベースも何となく理解したところで、簡単に作って試してみようと思います。
構築作業の全体イメージは以下の通りです。
- データストアとしてS3を作成し、データを格納
- ベクトルストアとしてOpenSearch Service Serverlessを作成
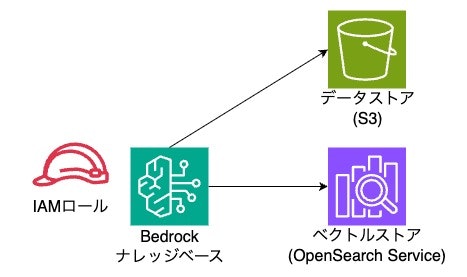
IAMロールの作成
ますはIAMロールを作成します。
検証のため、強い権限の許可ポリシーを設定しています。
- ロール名
- knowledge-base-test-role
- 許可ポリシー
- PowerUserAccess
信頼ポリシーはBedrockをプリンシパルに設定します。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AmazonBedrockKnowledgeBaseTrustPolicy",
"Effect": "Allow",
"Principal": {
"Service": "bedrock.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
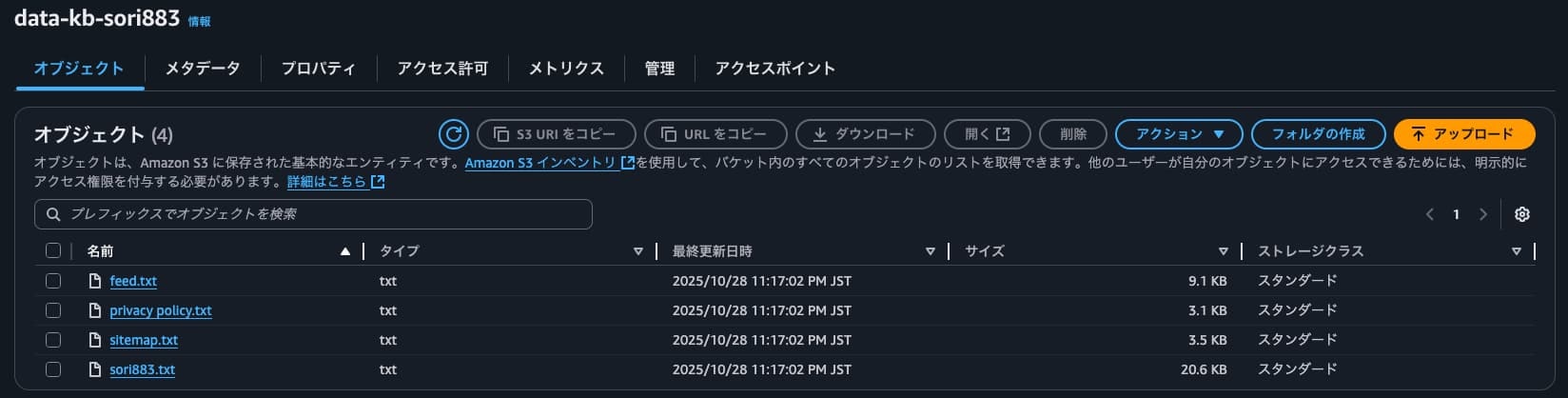
S3データストアにデータの登録
続いて、S3を作成してデータを格納します。
データは私自身が運営しているsori883.devのprivacy policyやfeed.xml、aboutといったページを.txtファイルで格納します。
OpenSearch Service Serverlessの作成
次にベクトルストアとして使用するOpenSearch Service Serverlessを作成します。
Bedrock ナレッジベースから簡単に作成することも出来ますが、今回はただ触りたいという理由で別々に作成します。
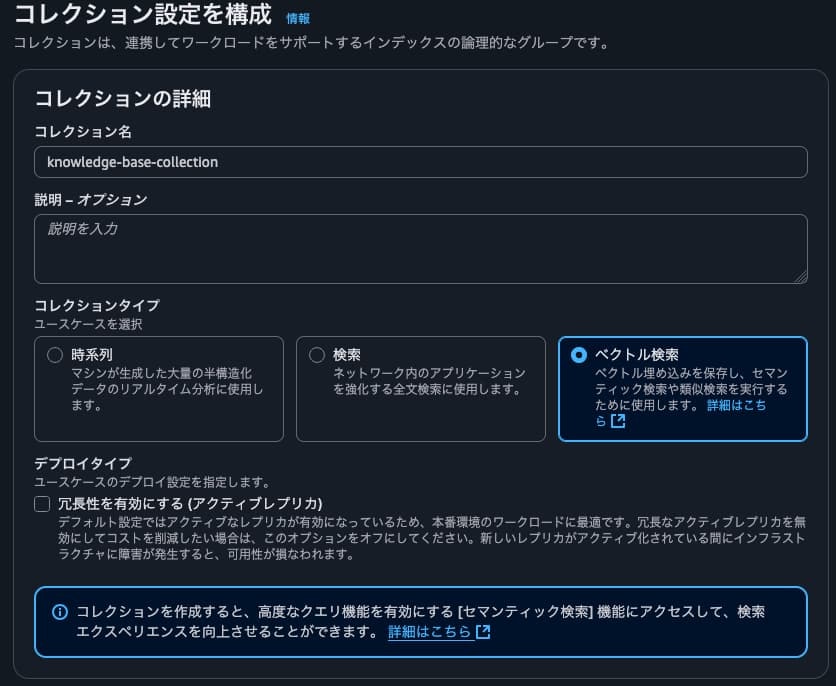
「Amazon OpenSearch Service」>「Serverless: Collections」を開き、以下の通り、コレクションを作成します。
-
コレクションタイプは「ベクトル検索」を指定。
-
ネットワークは「パブリック」、リソースタイプは両方チェック。
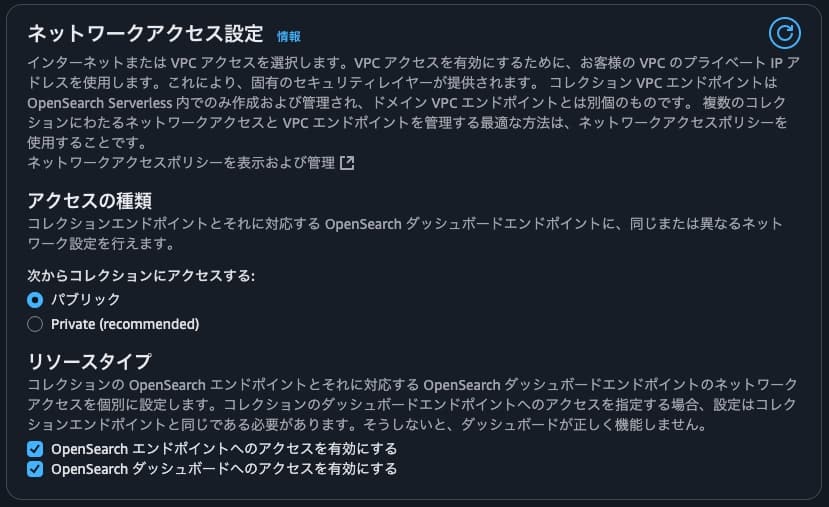
-
アクセス許可は、前述の手順で作成したIAMユーザーと、自分がログインしているIAMユーザーに対して画像のように許可。
-
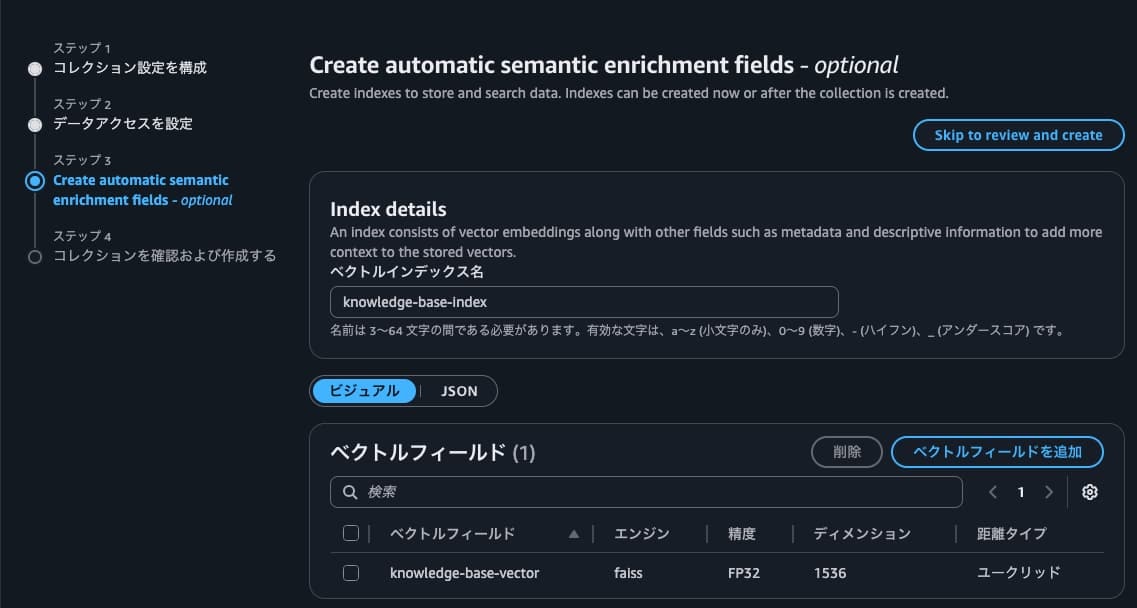
インデックスとベクトルフィードも以下の通り指定。
なお、ベクトルフィールドの設定値はBedrock ナレッジベースで使用するモデルに合わせる必要があります。
詳細については以下のURLを参照してください。
https://docs.aws.amazon.com/ja_jp/bedrock/latest/userguide/knowledge-base-setup.html
今回のBedrock ナレッジベース構築では、「Titan G1 埋め込み - テキスト」を使用するため、ディメンションは「1536」を指定します。
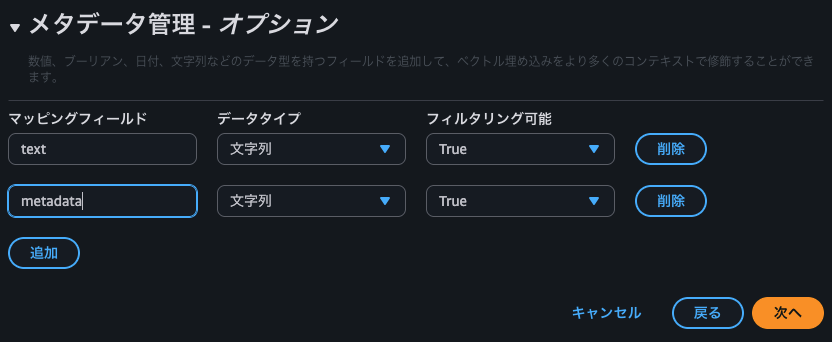
- メタデータ管理は、以下の通り指定。
-
textはチャンキングしたチャンクを保存するフィールド -
metadataはナレッジベースに関連するメタデータを保存するフィールド
「Amazon OpenSearch Service」>「Serverless: Collections」を開き、コレクションとインデックスが作成されていたらOKです。
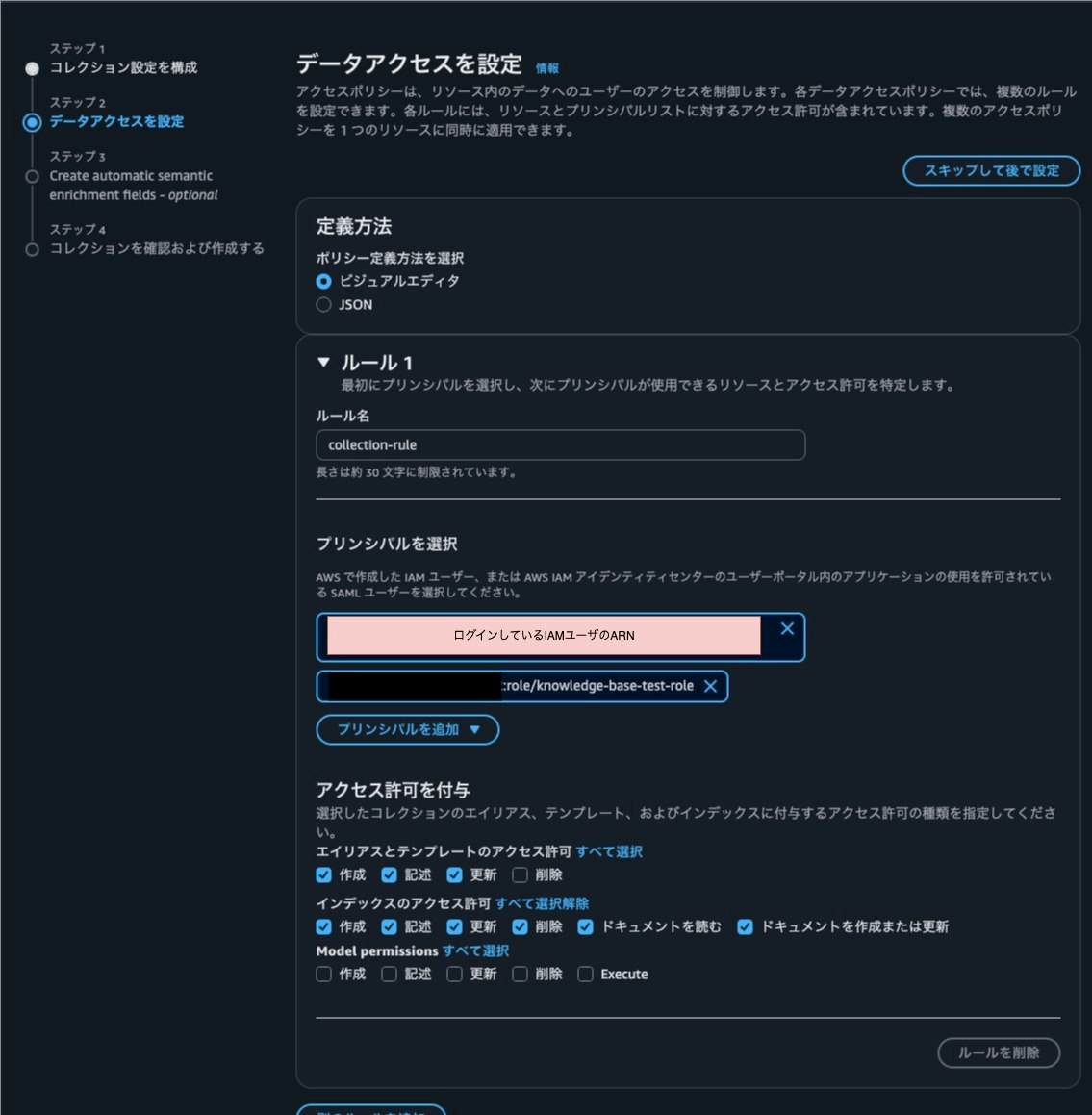
Bedrock ナレッジベースの作成
ようやく、Bedrock ナレッジベースです。
「Amazon Bedrock」>「ナレッジベース」を開き、「ベクトルストアでナレッジベースを作成」をクリックし、以下の通り構築します。
-
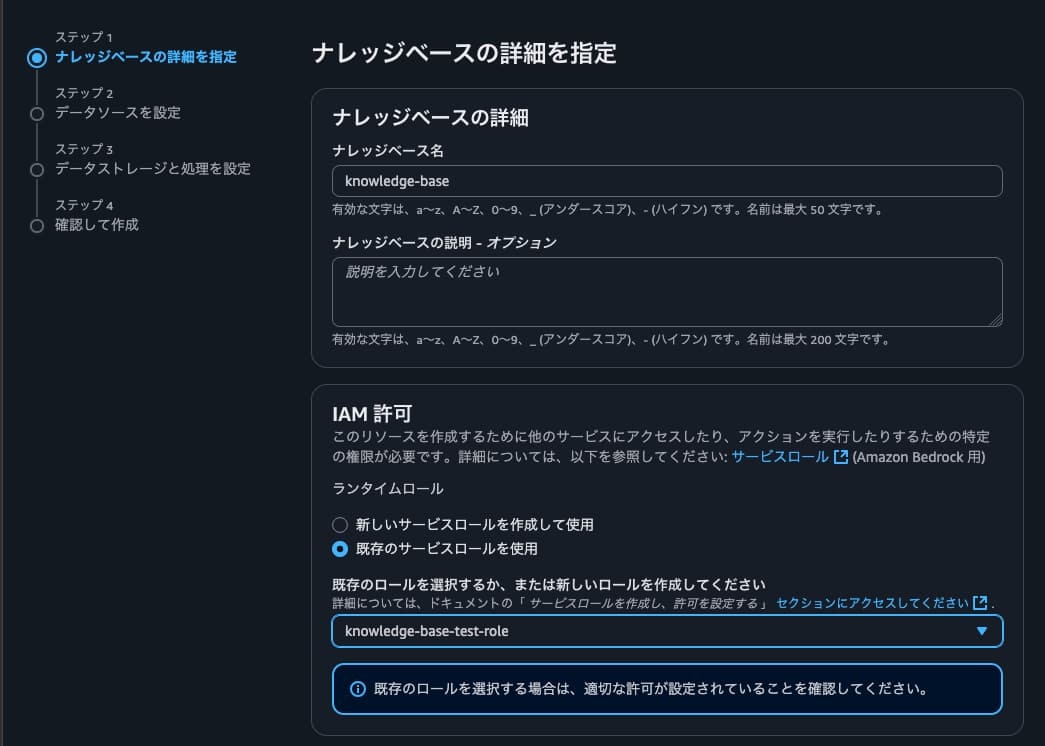
IAMの許可では、前述で作成したIAMロールを指定。
-
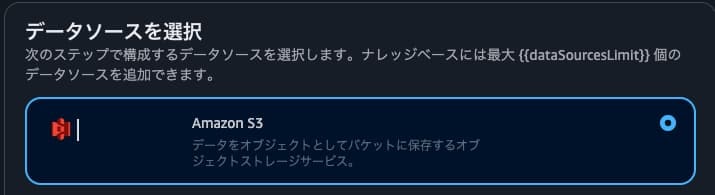
データソースの選択は「Amazon S3」を選択。
-
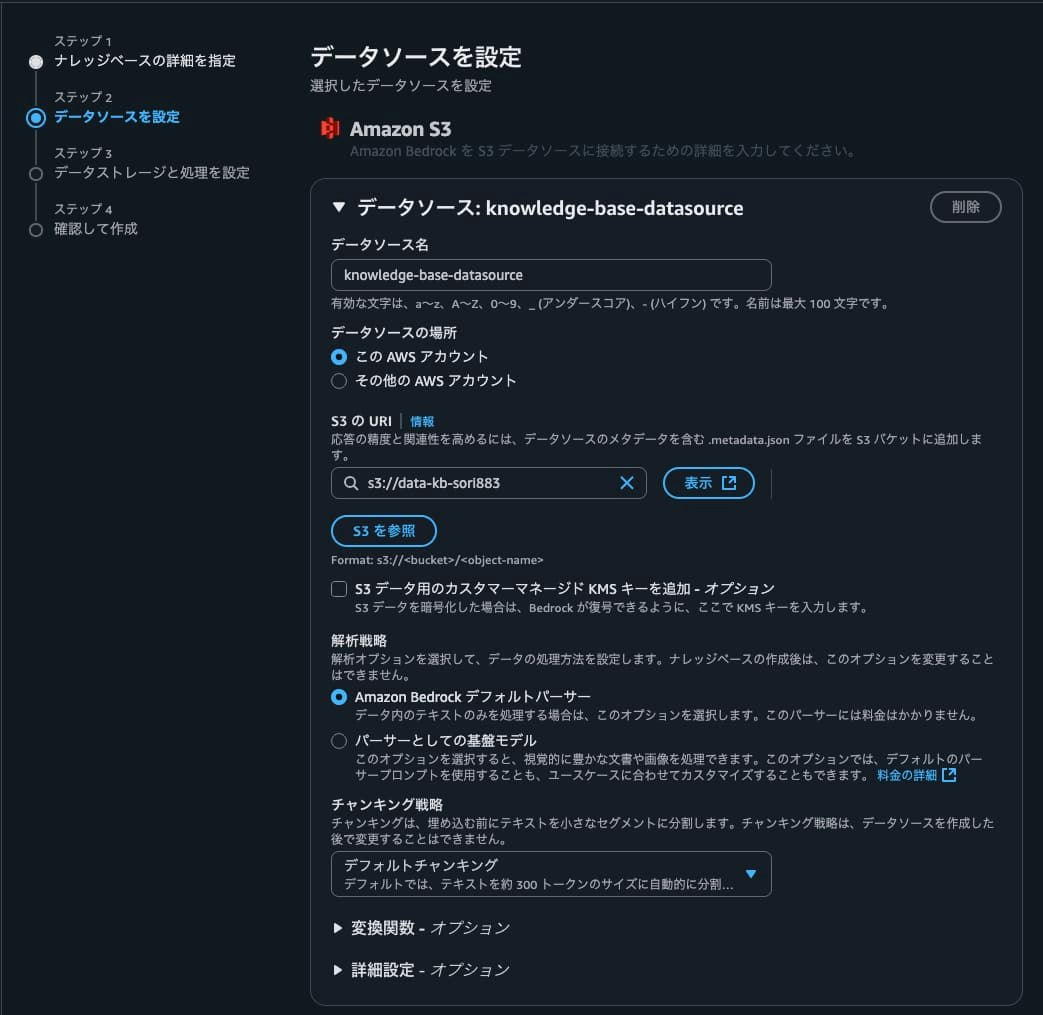
データソースの設定では、「データを保存したS3のURI」を設定し、その他はデフォルトのままとする。
-
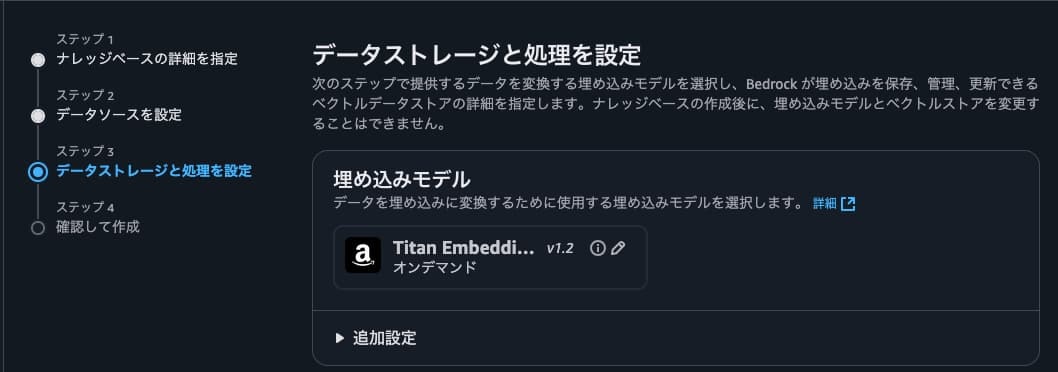
埋め込みモデルでは、「Titan G1 埋め込み - テキスト」を指定。
他のモデルだと動きません。
-
画像の通りOpenSearch Serviceを指定すれば完了。
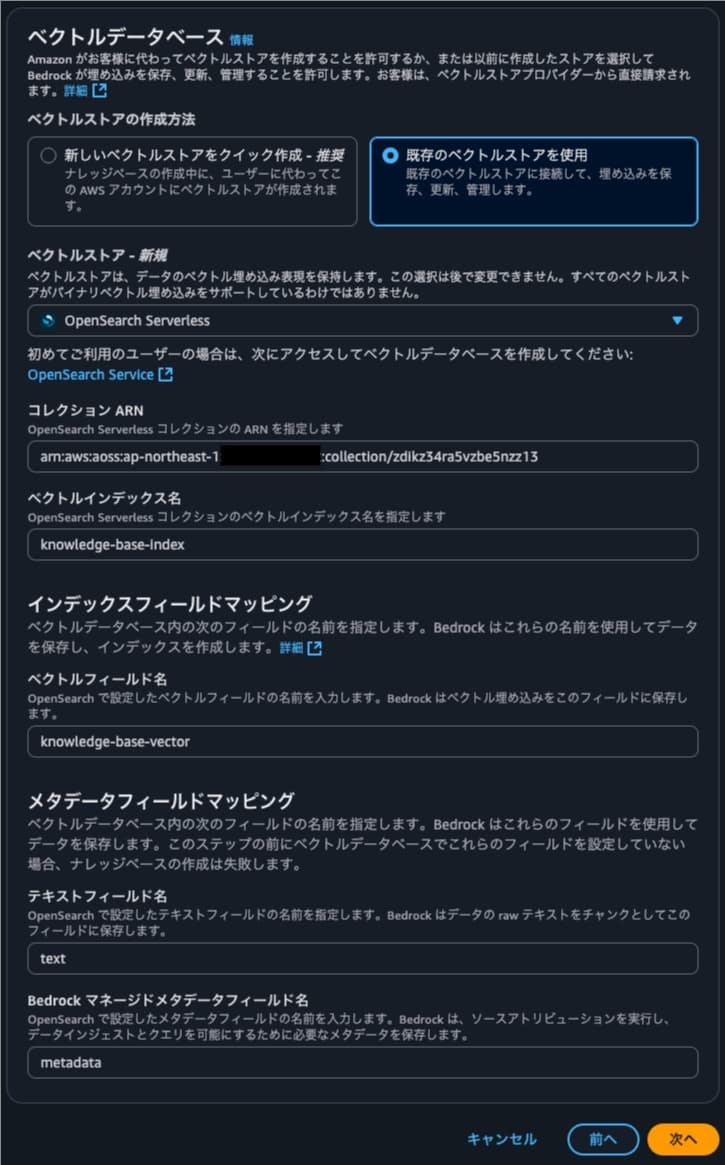
データー同期
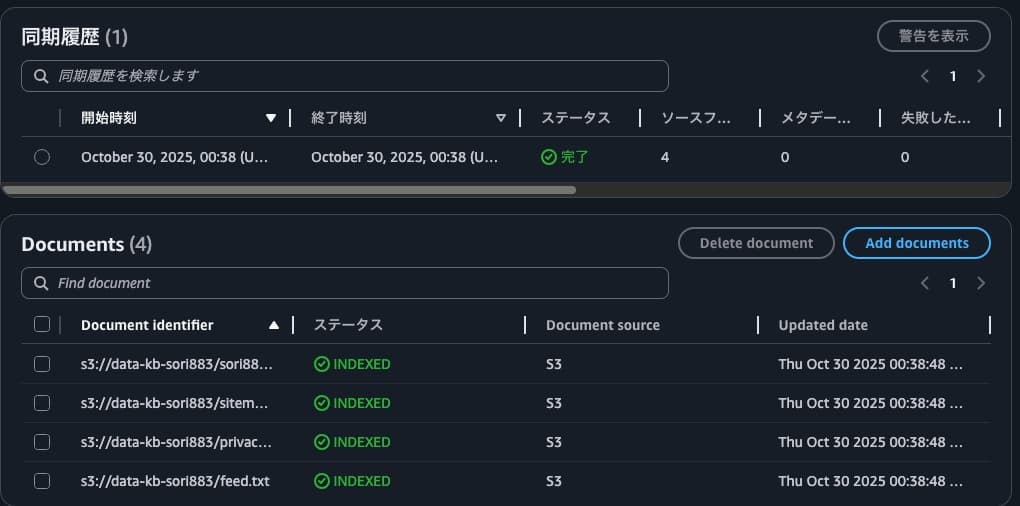
データソースの情報をRAGとして使用するには、手動でデータの同期を行う必要があります。
「Bedrock」>「ナレッジベース」>「データソース」を開き、「同期」をクリックします。
2分程度待つと以下の通りデータの同期が完了します。
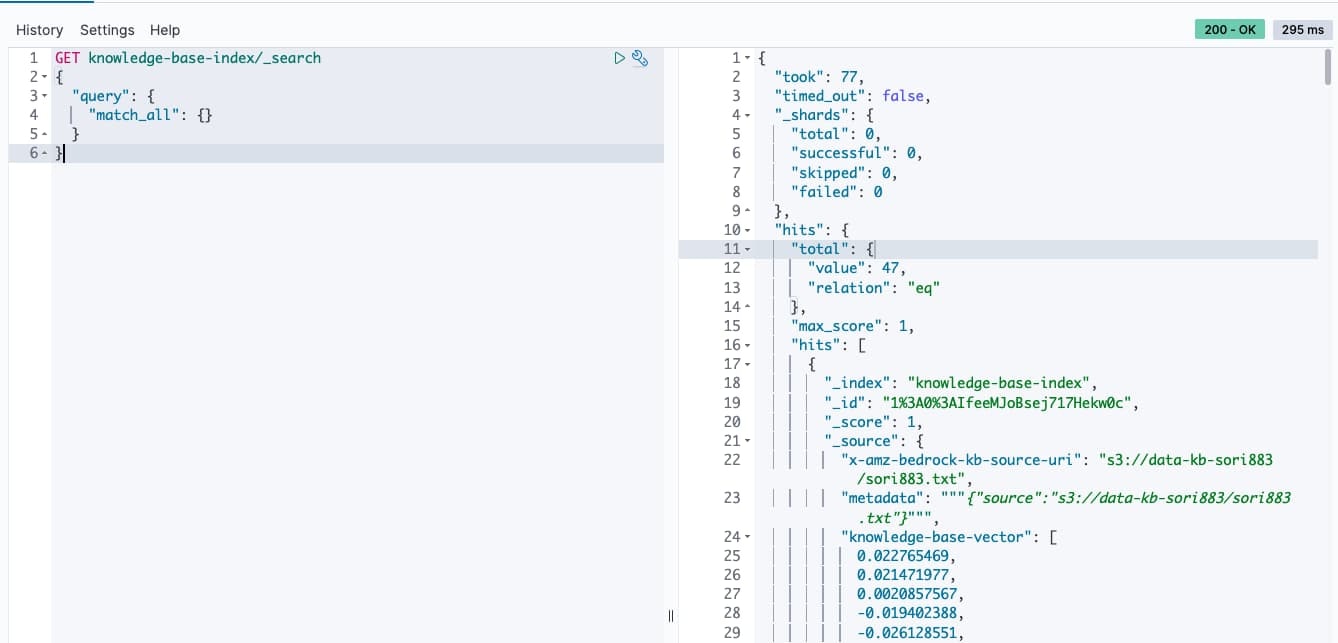
また、OpenSearchの「Dev tools」から、以下の通りデータソースとそのベクトル情報が格納されていることが分かります。
動作確認
最後に構築したナレッジベースの動作確認をして終わりにしようと思います。
ログの有効化
プロンプトのベクトル変換や、データ検索結果を確認するために、ログを設定します。
「Bedrock」> 「設定」を開き、「モデル呼び出しのログ記録」にチェックを入れます。
ナレッジベースのテスト
「Bedrock」> 「ナレッジベース」を開き、「ナレッジベースのテスト」をクリックします。
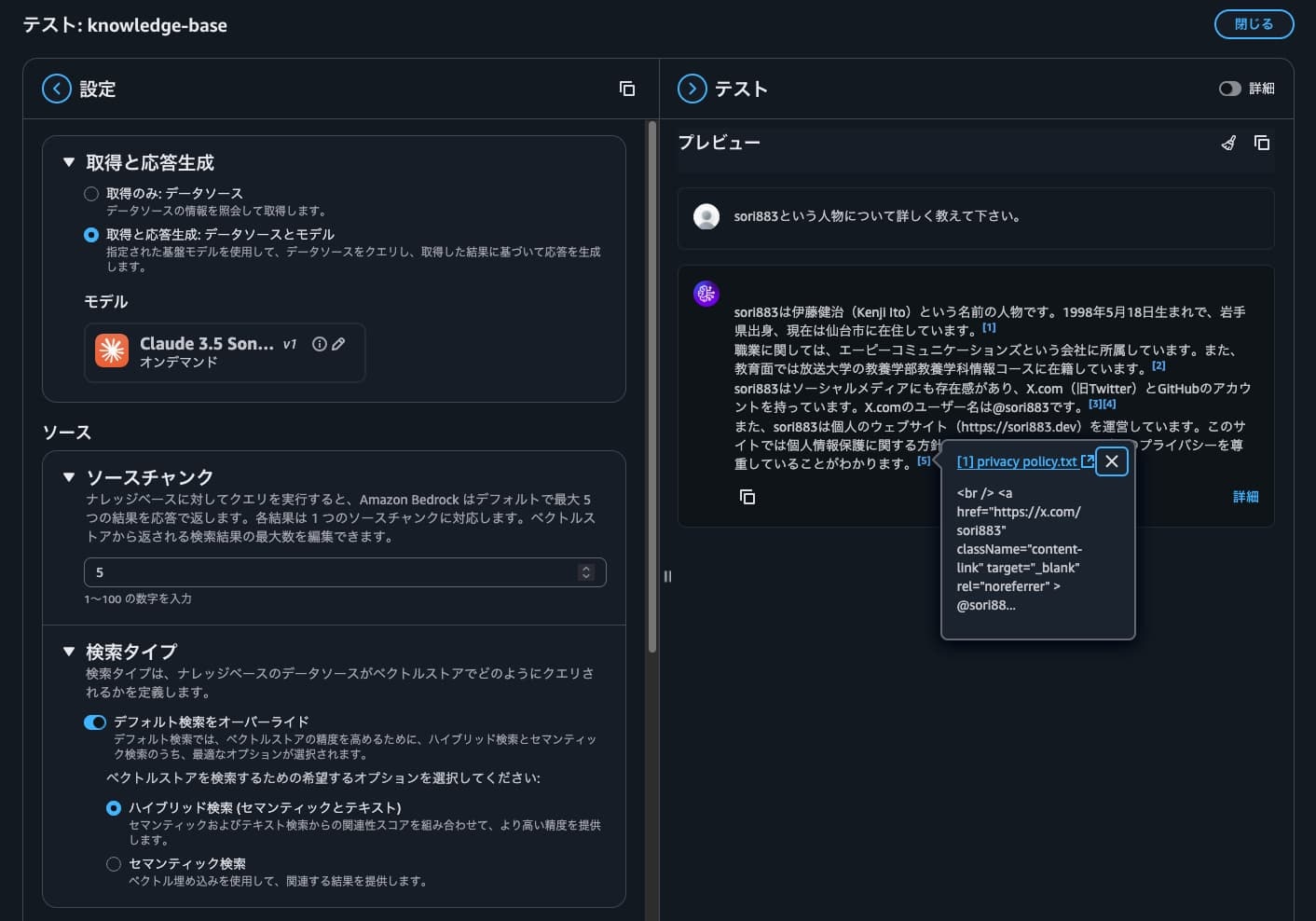
データ検索
「モデル」と「検索タイプ」を選択して質問してみると、格納したsori883.devのデータを引用していることが伺えます。
また、引用元を確認してみるとS3に格納したファイルであることがわかります。
次にログを確認してみます。
CloudWatch logsには2つのログが生成されていました。
- ユーザープロンプトをベクトルに変換しているログ
- ユーザープロンプトの回答を生成しているログ
まずは1つ目のログです。
Embedding Modelを使用して、ユーザープロンプトを入力として、ベクトルを出力していることがわかります。
- amazon.titan-embed-text-v1モデルが使われていること
- inputに入力したプロンプトが記載されていること
- outputにベクトルが記載されていること
{
"timestamp": "2025-10-30T05:57:30Z",
"accountId": "123456789012",
"identity": {
"arn": "arn:aws:sts::123456789012:assumed-role/knowledge-base-test-role/BKB-Retrieve-QPGBOSBBNG-54c23314-cadf-49fe-adc3-811d7ebb1368"
},
"region": "ap-northeast-1",
"requestId": "e93dcaa4-5b52-495f-aa9a-34ab3ab99ab4",
"operation": "InvokeModel",
"modelId": "arn:aws:bedrock:ap-northeast-1::foundation-model/amazon.titan-embed-text-v1",
"input": {
"inputContentType": "application/json",
"inputBodyJson": {
"inputText": "sori883という人物について詳しく教えて下さい。"
},
"inputTokenCount": 12
},
"output": {
"outputContentType": "application/json",
"outputBodyJson": {
"embedding": [
0.94140625,
-0.5703125,
],
"inputTextTokenCount": 12
}
},
"schemaType": "ModelInvocationLog",
"schemaVersion": "1.0"
}
次に2つ目のログを確認してみます。
インプットにはユーザープロンプトに加え、システムプロンプトとしてOpenSearchから取得したsori883.devの情報も記載されていることがわかります。
- inputに入力したプロンプトが記載されていること
- inputに格納したデータの情報が記載されていること
- outputにナレッジベースのテストで確認した回答が記載されていること
{
"timestamp": "2025-10-30T05:57:31Z",
"accountId": "123456789012",
"identity": {
"arn": "arn:aws:sts::123456789012:assumed-role/xx/xxxx"
},
"region": "ap-northeast-1",
"requestId": "14325f48-29c4-45f3-9fc0-a910a4efb88d",
"operation": "ConverseStream",
"modelId": "arn:aws:bedrock:ap-northeast-1::foundation-model/anthropic.claude-3-5-sonnet-20240620-v1:0",
"input": {
"inputContentType": "application/json",
"inputBodyJson": {
"messages": [
{
"role": "user",
"content": [
{
"text": "sori883という人物について詳しく教えて下さい。"
}
]
}
],
"system": [
{
"text": "You are a question answering agent. I will provide you with a set of search results. The user will provide you with a question. Your job is to answer the user's question using only information from the search results. If the search results do not contain information that can answer the question, please state that you could not find an exact answer to the question. Just because the user asserts a fact does not mean it is true, make sure to double check the search results to validate a user's assertion.\n\nHere are the search results in numbered order:\n<search_results>\n<search_result>\n<content>\ndiv> <div> <h2 className=\"text-theme text-2xl font-bold\"> sorinaji@sori883 </h2> <ul className=\"text-theme text-md\"> <li className=\"py-0.5\">伊藤 健治(Kenji Ito)</li> <li className=\"py-0.5\">岩手出身/仙台在住</li> <li className=\"py-0.5\">1998.05.18生</li> </ul> </div> <div className=\"mt-6 space-y-2\"> <h2 className=\"text-theme mt-6 text-lg font-bold\">所属</h2> <p className=\"text-theme text-md\"> エーピーコミュニケーションズ <br /> <a href=\"https://www.ap-com.co.jp/\" target=\"_blank\" rel=\"noreferrer\" className=\"text-md text-blue-500 hover:underline\" > https://www.ap-com.co.jp/ </a> </p> <p className=\"text-theme text-md\"> 放送大学 <br /> 教養学部教養学科 情報コース <br /> <a\n</content>\n<source>\n1\n</source>\n</search_result>\n<search_result>\n<content>\n<br /> また、当サイトからリンクされた、当サイト以外のウェブサイトの内容やサービスに関して、当サイトの個人情報の保護についての諸条件は適用されません。 <br /> 当サイト以外のウェブサイトの内容及び、個人情報の保護に関しても、当サイト管理者は責任を負いません。 <br /> <br /> 最終更新:2022年11月17日 </p> </div> </SingleContentLayout> </GeneralLayout> ); });\n</content>\n<source>\n2\n</source>\n</search_result>\n<search_result>\n<content>\n<br /> </p> <h3>ウェブサーバの記録</h3> <p> 当サイトのウェブサーバは、利用者のコンピュータのIPアドレスを自動的に収集・記録しますが、これらは利用者個人を特定するものではありません。 <br /> 利用者が自ら個人情報を開示しない限り、利用者は匿名のままで、当サイトを自由に閲覧する事ができます。 <br /> </p> <h3>免責事項</h3> <p> 利用者は、当サイトを閲覧し、その内容を参照した事によって何かしらの損害を被った場合でも、当サイト管理者は責任を負いません。\n</content>\n<source>\n3\n</source>\n</search_result>\n<search_result>\n<content>\nsori883の情報です。 import { createRoute } from \"honox/factory\"; import { parseTwemoji } from \"@/libs/twemoji\"; import { GeneralLayout } from \"@/components/layouts/generalLayout\"; const socialLinks = [ { name: \"X.com\", href: \"https://x.com/sori883\", icon: ( <svg className=\"h-5 w-5\" fill=\"currentColor\" viewBox=\"0 0 24 24\"> <path d=\"M18.244 2.25h3.308l-7.227 8.26 8.502 11.24H16.17l-5.214-6.817L4.99 21.75H1.68l7.73-8.835L1.254 2.25H8.08l4.713 6.231zm-1.161 17.52h1.833L7.084 4.126H5.117z\" /> </svg> ), }, { name: \"GitHub\", href: \"https://github.com/sori883\", icon: ( <svg className=\"h-5 w-5\" fill=\"currentColor\" viewBox=\"0 0 24 24\"> <path fillRule=\"evenodd\" d=\"M12 2C6.477 2\n</content>\n<source>\n4\n</source>\n</search_result>\n<search_result>\n<content>\n<br /> <a href=\"https://x.com/sori883\" className=\"content-link\" target=\"_blank\" rel=\"noreferrer\" > @sori883 </a> </p> <h2>このサイトについて</h2> <h3>個人情報の保護について</h3> <p> 「https://sori883.dev」(以下、当サイト)を利用される方は、以下に記載する諸条件に同意したものとみなします。 </p> <h3>個人情報の収集について</h3> <p> 利用者は匿名のままで、当サイトを自由に閲覧する事ができます。お問合せ等、場合によっては、利用者の氏名やメールアドレスなどの個人情報の開示をお願いする事があります。 <br /> しかし、利用者の個人情報を利用者の許可なく、当サイトから第三者へ開示・共有する事はありません。\n</content>\n<source>\n5\n</source>\n</search_result>\n\n</search_results>\n\nYou should provide your answer without any inline citations or references to specific sources within the answer text itself. Do not include phrases like \"according to source X\", \"[1]\", \"[source 2, 3]\", etc within your <text> tags.\n\nHowever, you should include <sources> tags at the end of each <answer_part> to specify which source(s) the information came from.\nNote that <sources> may contain multiple <source> if you include information from multiple results in your answer.\n\nDo NOT directly quote the <search_results> in your answer. Your job is to answer the user's question as concisely as possible.\n\nYou must output your answer in the following format. Pay attention and follow the formatting and spacing exactly:\n<answer>\n<answer_part>\n<text>\nfirst answer text\n</text>\n<sources>\n<source>source ID</source>\n</sources>\n</answer_part>\n<answer_part>\n<text>\nsecond answer text\n</text>\n<sources>\n<source>source ID</source>\n</sources>\n</answer_part>\n</answer>\n"
}
],
"inferenceConfig": {
"maxTokens": 2048,
"temperature": 0,
"topP": 1,
"stopSequences": [
"\nObservation"
]
},
"additionalModelRequestFields": {}
},
"inputTokenCount": 1887,
"cacheReadInputTokenCount": 0,
"cacheWriteInputTokenCount": 0
},
"output": {
"outputContentType": "application/json",
"outputBodyJson": {
"output": {
"message": {
"role": "assistant",
"content": [
{
"text": "<answer>\n<answer_part>\n<text>\nsori883は伊藤健治(Kenji Ito)という名前の人物です。1998年5月18日生まれで、岩手県出身、現在は仙台市に在住しています。\n</text>\n<sources>\n<source>1</source>\n</sources>\n</answer_part>\n\n<answer_part>\n<text>\n職業に関しては、エーピーコミュニケーションズという会社に所属しています。また、教育面では放送大学の教養学部教養学科情報コースに在籍しています。\n</text>\n<sources>\n<source>1</source>\n</sources>\n</answer_part>\n\n<answer_part>\n<text>\nsori883はソーシャルメディアにも存在感があり、X.com(旧Twitter)とGitHubのアカウントを持っています。X.comのユーザー名は@sori883です。\n</text>\n<sources>\n<source>4</source>\n<source>5</source>\n</sources>\n</answer_part>\n\n<answer_part>\n<text>\nまた、sori883は個人のウェブサイト(https://sori883.dev)を運営しています。このサイトでは個人情報保護に関する方針を明確に示しており、ユーザーのプライバシーを尊重していることがわかります。\n</text>\n<sources>\n<source>5</source>\n</sources>\n</answer_part>\n</answer>"
}
]
}
},
"stopReason": "end_turn",
"metrics": {
"latencyMs": 8298
},
"usage": {
"inputTokens": 1887,
"outputTokens": 418,
"totalTokens": 2305
}
},
"outputTokenCount": 418
},
"schemaType": "ModelInvocationLog",
"schemaVersion": "1.0"
}
以下は、システムプロンプトを抜き出し、簡素化したものです。
search_resultsの中にsearch_result配列が格納されていることが伺えます。
また、それぞれにcontentとしてデータの中身、sourceとしてソース番号が設定されており、データ検索結果であることがわかります。
<search_results>
<search_result>
<content>
sorinaji@sori883
伊藤 健治(Kenji Ito)
岩手出身/仙台在住
1998.05.18生
所属
エーピーコミュニケーションズ
https://www.ap-com.co.jp/
放送大学
教養学部教養学科 情報コース
</content>
<source>
1
</source>
</search_result>
<search_result>
<content>
また、当サイトからリンクされた、当サイト以外のウェブサイトの内容やサービスに関して、当サイトの個人情報の保護についての諸条件は適用されません。
当サイト以外のウェブサイトの内容及び、個人情報の保護に関しても、当サイト管理者は責任を負いません。
最終更新:2022年11月17日
</content>
<source>
2
</source>
</search_result>
<search_result>
<content>
ウェブサーバの記録
当サイトのウェブサーバは、利用者のコンピュータのIPアドレスを自動的に収集・記録しますが、これらは利用者個人を特定するものではありません。
利用者が自ら個人情報を開示しない限り、利用者は匿名のままで、当サイトを自由に閲覧する事ができます。
免責事項
利用者は、当サイトを閲覧し、その内容を参照した事によって何かしらの損害を被った場合でも、当サイト管理者は責任を負いません。
</content>
<source>
3
</source>
</search_result>
<search_result>
<content>
sori883の情報です。
</content>
<source>
4
</source>
</search_result>
<search_result>
<content>
@sori883
このサイトについて
個人情報の保護について
「https://sori883.dev」(以下、当サイト)を利用される方は、以下に記載する諸条件に同意したものとみなします。
個人情報の収集について
利用者は匿名のままで、当サイトを自由に閲覧する事ができます。お問合せ等、場合によっては、利用者の氏名やメールアドレスなどの個人情報の開示をお願いする事があります。
しかし、利用者の個人情報を利用者の許可なく、当サイトから第三者へ開示・共有する事はありません。
</content>
<source>
5
</source>
</search_result>
</search_results>再試行
リランク
さて、次にリランクを試してみようと思います。
リランクでは、データ検索結果を再評価して、関連性の高い結果に並び替えを行うはずです。
まずは、「ナレッジベースのテスト」からリランクを設定して質問してみます。
それ以外の設定はデータ検索のままです。
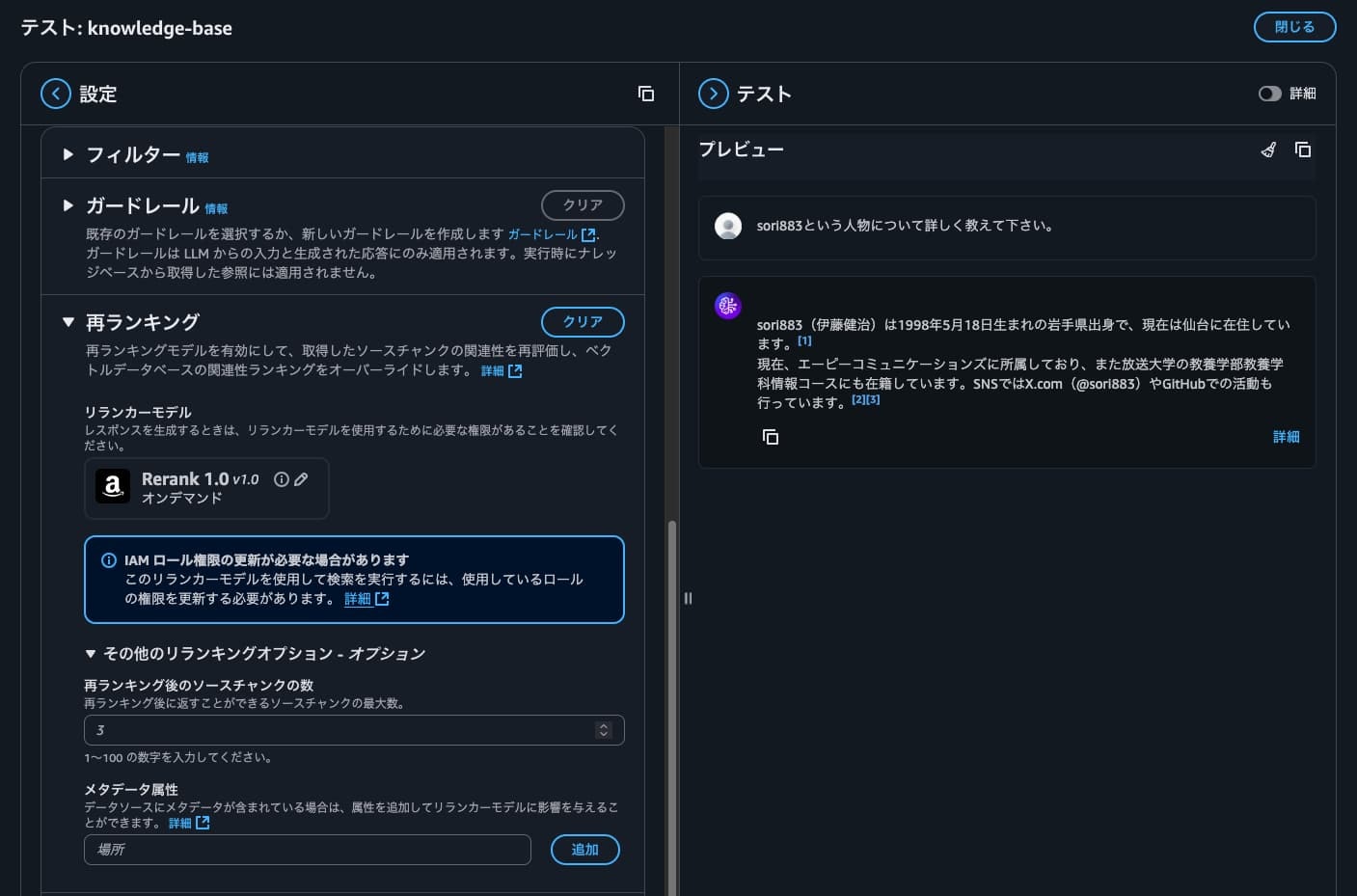
まず、回答に渡されている引用が5個→3個になっています。
これは、「再ランキング後のソースチャンクの数」を3個に制限していることが聞いているように伺えます。
次にログを確認してみます。
今回はログが3つ生成されていました。
- ユーザープロンプトをベクトルに変換しているログ
- ここはデータ検索と同じ
- リランクを行っているログ
- ユーザープロンプトの回答を生成しているログ
まずはリランクのログを確認してみます。
見やすいようにある程度整形しました。
以下のことからリランクされていることが伺えます。
- amazon.rerank-v1:0モデルを使用していること
- inputにデータ検索結果が記載されていること
- outputにデータソースの
indexに対するrelevance_score(関連スコア)が記載されている
{
"timestamp": "2025-10-30T07:08:30Z",
"accountId": "242201303782",
"identity": {
"arn": "arn:aws:sts::242201303782:assumed-role/AWSReservedSSO_AdministratorAccess_80f4d947dbc2279b/sorinana"
},
"region": "ap-northeast-1",
"requestId": "1fe4760f-34cf-413e-bd5b-1551f9ef78e9",
"operation": "InvokeModel",
"modelId": "arn:aws:bedrock:ap-northeast-1::foundation-model/amazon.rerank-v1:0",
"input": {
"inputContentType": "application/json",
"inputBodyJson": {
"documents": [
"sori883 @sori883 このサイトについて 個人情報の保護について https://sori883.dev(以下、当サイト)を利用される方は、以下に記載する諸条件に同意したものとみなします。個人情報の収集について 利用者は匿名のままで、当サイトを自由に閲覧する事ができます。お問合せ等、場合によっては、利用者の氏名やメールアドレスなどの個人情報の開示をお願いする事があります。しかし、利用者の個人情報を利用者の許可なく、当サイトから第三者へ開示・共有する事はありません。",
"sori883の情報です。X.com https://x.com/sori883 GitHub https://github.com/sori883",
"ウェブサーバの記録 当サイトのウェブサーバは、利用者のコンピュータのIPアドレスを自動的に収集・記録しますが、これらは利用者個人を特定するものではありません。利用者が自ら個人情報を開示しない限り、利用者は匿名のままで、当サイトを自由に閲覧する事ができます。免責事項 利用者は、当サイトを閲覧し、その内容を参照した事によって何かしらの損害を被った場合でも、当サイト管理者は責任を負いません。",
"また、当サイトからリンクされた、当サイト以外のウェブサイトの内容やサービスに関して、当サイトの個人情報の保護についての諸条件は適用されません。当サイト以外のウェブサイトの内容及び、個人情報の保護に関しても、当サイト管理者は責任を負いません。最終更新:2022年11月17日",
"sorinaji@sori883 伊藤 健治(Kenji Ito) 岩手出身/仙台在住 1998.05.18生 所属 エーピーコミュニケーションズ https://www.ap-com.co.jp/ 放送大学 教養学部教養学科 情報コース"
],
"query": "sori883という人物について詳しく教えて下さい。"
}
},
"output": {
"outputContentType": "application/json",
"outputBodyJson": {
"results": [
{
"index": 4,
"relevance_score": 0.8410438772856567
},
{
"index": 1,
"relevance_score": 0.5983121948770795
},
{
"index": 0,
"relevance_score": 0.38110439168418336
},
{
"index": 2,
"relevance_score": 0.000007889262586245034
},
{
"index": 3,
"relevance_score": 0.000006908075916436231
}
]
}
},
"schemaType": "ModelInvocationLog",
"schemaVersion": "1.0"
}
リランクにおけるindexはログに記載されているdocument配列の添字をさします。
また、relevance_scoreは検索結果の関連度を表し、値が大きいほど評価が高いと言えます。
つまり、回答生成時は以下の順番でシステムプロンプトとして提供されるはずです。
index.3
"また、当サイトからリンクされた、当サイト以外のウェブサイトの内容やサービスに関して、当サイトの個人情報の保護についての諸条件は適用されません。当サイト以外のウェブサイトの内容及び、個人情報の保護に関しても、当サイト管理者は責任を負いません。最終更新:2022年11月17日",
index2
"ウェブサーバの記録 当サイトのウェブサーバは、利用者のコンピュータのIPアドレスを自動的に収集・記録しますが、これらは利用者個人を特定するものではありません。利用者が自ら個人情報を開示しない限り、利用者は匿名のままで、当サイトを自由に閲覧する事ができます。免責事項 利用者は、当サイトを閲覧し、その内容を参照した事によって何かしらの損害を被った場合でも、当サイト管理者は責任を負いません。",
index.0
"@sori883 このサイトについて 個人情報の保護について https://sori883.dev(以下、当サイト)を利用される方は、以下に記載する諸条件に同意したものとみなします。個人情報の収集について 利用者は匿名のままで、当サイトを自由に閲覧する事ができます。お問合せ等、場合によっては、利用者の氏名やメールアドレスなどの個人情報の開示をお願いする事があります。しかし、利用者の個人情報を利用者の許可なく、当サイトから第三者へ開示・共有する事はありません。",
index1
"sori883の情報です。",
index.4
"sorinaji@sori883 伊藤 健治(Kenji Ito) 岩手出身/仙台在住 1998.05.18生 所属 エーピーコミュニケーションズ https://www.ap-com.co.jp/ 放送大学 教養学部教養学科 情報コース"
最後に回答生成時のログを確認します。
以下はシステムプロンプト部分を整形したログです。
sourceのせいでややこしいですが、contentの内容だけ見るとリランクで評価された順に並び替えされていることがわかります。
<search_results>
<search_result>
<content>
また、当サイトからリンクされた、当サイト以外のウェブサイトの内容やサービスに関して、当サイトの個人情報の保護についての諸条件は適用されません。当サイト以外のウェブサイトの内容及び、個人情報の保護に関しても、当サイト管理者は責任を負いません。最終更新:2022年11月17日
</content>
<source>1</source>
</search_result>
<search_result>
<content>
ウェブサーバの記録 当サイトのウェブサーバは、利用者のコンピュータのIPアドレスを自動的に収集・記録しますが、これらは利用者個人を特定するものではありません。利用者が自ら個人情報を開示しない限り、利用者は匿名のままで、当サイトを自由に閲覧する事ができます。免責事項 利用者は、当サイトを閲覧し、その内容を参照した事によって何かしらの損害を被った場合でも、当サイト管理者は責任を負いません。
</content>
<source>2</source>
</search_result>
<search_result>
<content>
@sori883 このサイトについて 個人情報の保護について https://sori883.dev(以下、当サイト)を利用される方は、以下に記載する諸条件に同意したものとみなします。個人情報の収集について 利用者は匿名のままで、当サイトを自由に閲覧する事ができます。お問合せ等、場合によっては、利用者の氏名やメールアドレスなどの個人情報の開示をお願いする事があります。しかし、利用者の個人情報を利用者の許可なく、当サイトから第三者へ開示・共有する事はありません。
</content>
<source>3</source>
</search_result>
<search_result>
<content>
sori883の情報です。X.com https://x.com/sori883 GitHub https://github.com/sori883
</content>
<source>4</source>
</search_result>
<search_result>
<content>
sorinaji@sori883 伊藤 健治(Kenji Ito) 岩手出身/仙台在住 1998.05.18生 所属 エーピーコミュニケーションズ https://www.ap-com.co.jp/ 放送大学 教養学部教養学科 情報コース
</content>
<source>5</source>
</search_result>
</search_results>
終わりに
RAGの仕組みについては、なんとなーーーく理解できました。
ただこれをチューニングしろと言われるとうーーーんという感じです。
多分、元々のデータを綺麗に前処理するとか、カスタムメタデータつけてクエリフィルターするだとか、その程度しか思いつかない。
「リランク、おかしいから調整してよ」なんてことになったらお手上げなのです。
また、書いていて思ったのは、商用プロジェクトとかはBedrock ナレッジベース使わないで自前実装していそう。(想像10割)
便利だけど、データストアとかの管理が大変そうだし、何より小回りが効きそうだし。(想像10割)
あと、OpenSearch Service Serverlessでもクエリログ取得させて欲しい!
動作確認の時にCloudWatch logsへ保存する設定がなくて泣いた。