はじめに
AIが業務に浸透し始めて、最近こんなことを思うようになりました。
それ即ち、「指示を出すのが面倒くさい」。
「いや、そんなことまでしろって言ってない」とか、「そこはもっとシンプルにしてほしい」とか。
対人なら雰囲気やこれまでの文脈で伝わることも、AI相手だとなかなかうまく伝わりません。
(ある意味、自分の指示出し能力の低さが露呈しているだけな気もしますが……)
さらにその面倒くささに拍車をかけているのが、プロンプトをタイピングしなければならない点です。
そこで、「様々なAIへの指示出しを音声入力でできれば、もっと楽になるのでは?」と考え、本アプリの作成に着手しました。
作ったもの
以下に公開しています。
https://github.com/SKZeeee/Transcribe-Bedrock.git
機能はシンプルです。
- 録音開始でマイク入力を文字起こし
- ライブ表示(partial/final)
- 録音停止後にテキスト編集
-
Bedrockで要約ボタンで要約生成
最初はSTT機能だけを実装していましたが、単純な文字起こしだと内容がどうしてもごちゃついてしまうため、Bedrockによる要約機能を追加しました。
使ってみた
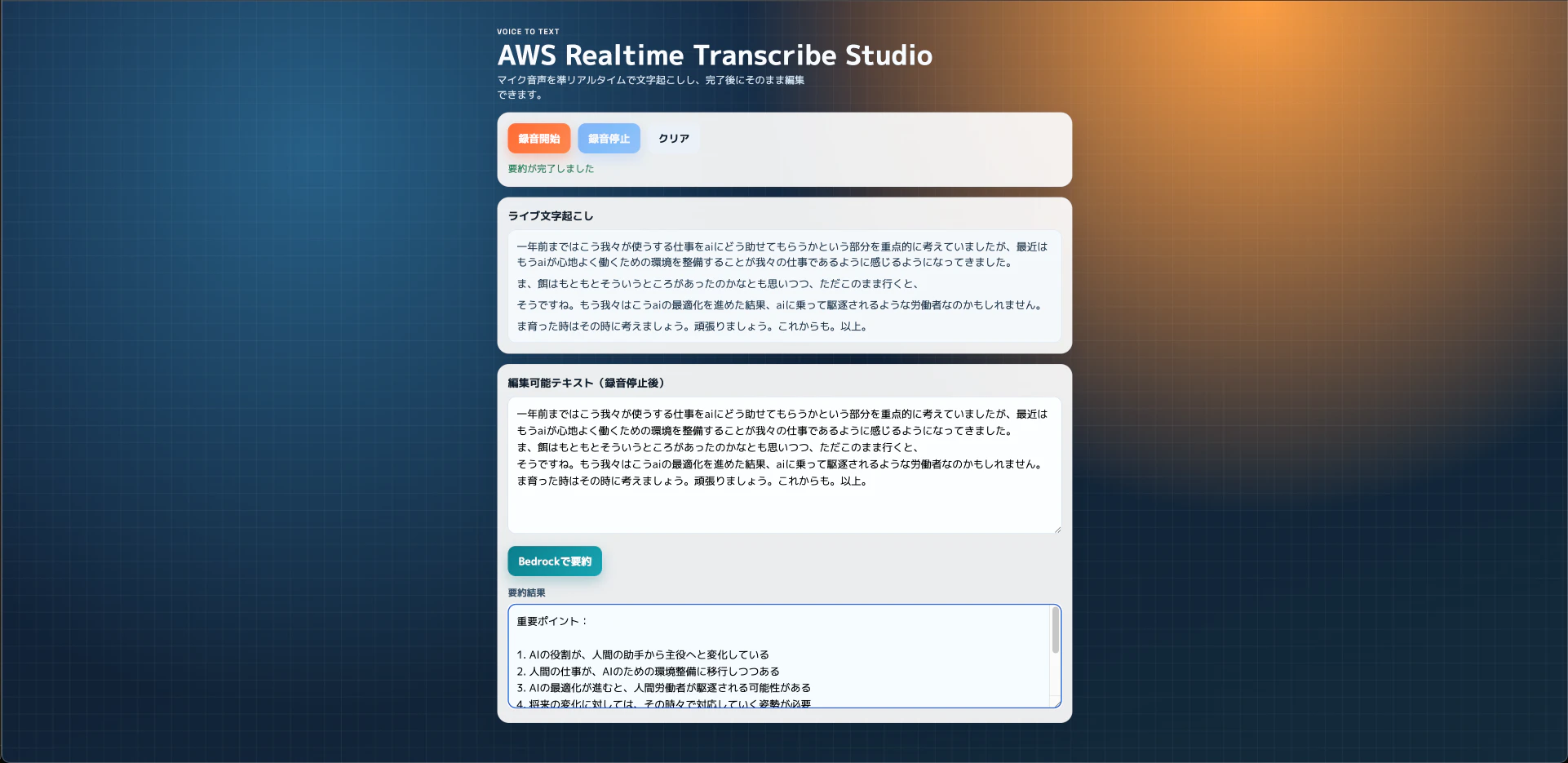
- 録音開始をクリックした状態でマイクに話しかけると準リアルタイムで文字起こしされる
- 二つ目のテキストフィールドでは文字起こしした内容をユーザーが編集できる
- その上で「Bedrockで要約」ボタンを押下すると要約が生成される
技術スタック
- Frontend: Vanilla JS + Web Audio API + WebSocket
- Backend: Node.js (Express + ws)
- Speech-to-Text: Amazon Transcribe Streaming
- Summarization: Amazon Bedrock (
ConverseCommand)
最後に
Transcribeを初めて使ってみましたが、かなりシンプルで扱いやすいですね。
コスト面を考えると、端末にWhisperを入れる構成も検討したいところですが、業務利用を前提にするならAWSのマネージドサービスを使っておいた方が色々と都合がいいので、今回はこの方針にしました。
最終的には、Codex CLIなどに送信するプロンプトをSTTで流し込んだり、レビュー対象物とレビュー内容をBedrockに突っ込んで、いい感じのレビュー記録表を自動生成させたり、といったこともやりたいなと思っています。