2021-07-07 UPDATE: Sudachi公式チームへレポジトリを委譲しました。公式版が改めて公開される予定です (cf. https://github.com/WorksApplications/sudachi.rs, 日本語形態素解析器 SudachiPy の 現状と今後について - Speaker Deck)

TL;DR
- 🍋 形態素解析器「Sudachi」の非公式Rust実装「sudachi.rs」をつくっている
- 🦀 自然言語処理ではPythonやJuliaが主流だが、一部のツールにはRustは良いかも
注: 著者は、Sudachiの開発元であるワークス徳島人工知能NLP研究所に所属していますが、「sudachi.rs」は個人的にRustの勉強を兼ねて作っている趣味プロダクトです。
🍋 形態素解析器「Sudachi」
形態素解析は、伝統的な自然言語処理において基盤となる技術です。主には、テキストを分割する「Segmentaion」、語形を辞書形にする「Stemming」、動詞や名詞といった品詞を付与する「Part-of-Speech Tagging」を行います。
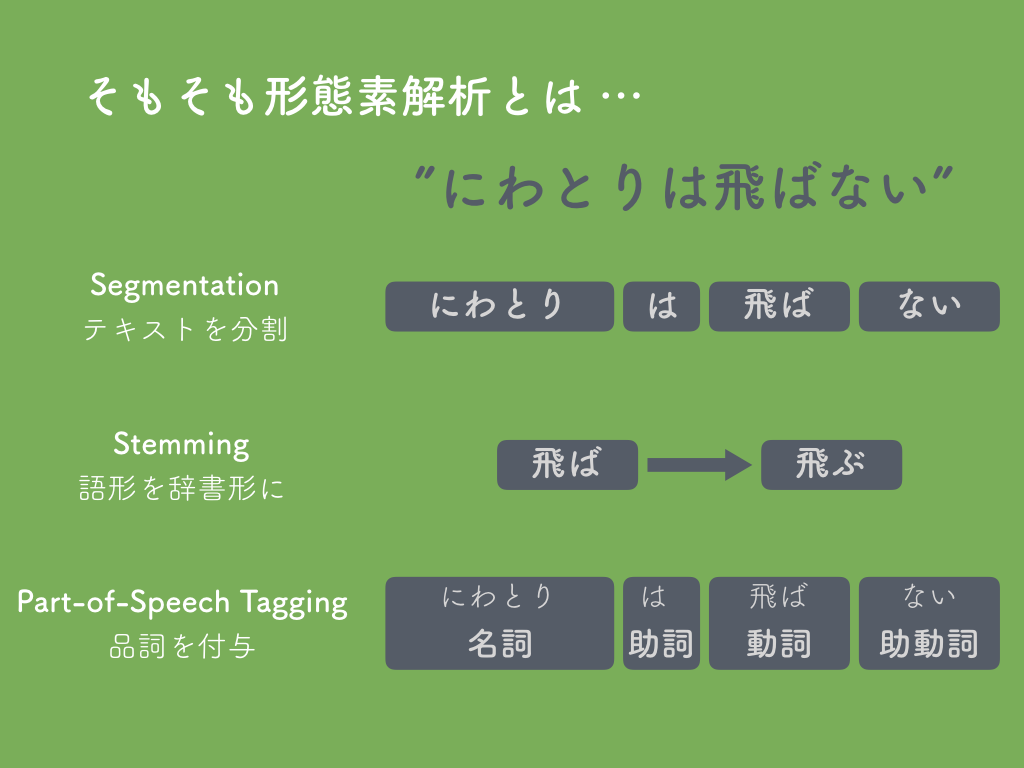
世の中には実に多くの(日本語向け)形態素解析ツールがあります。JUMAN、JUMAN++、ChaSen、MeCab、KyTea、sssla、fugashi、kuromoji、kagome、kuromoji.js、Janome、Rakuten MA、雪だるま、nagisa、そしてこの「自然言語処理 Advent Calendar 2019」初日にも登場したTaiyaki、などなど ...
そんな中、2017年に出たのが「Sudachi」です。株式会社ワークスアプリケーションズという営利企業が公開するツール&辞書です(筆者はSudachiの開発に社員として関わっています)。
特にこの言語資源(辞書)は貴重で、なかなかツールはつくっても辞書まで手を出せることは多くありません。このSudachi辞書(SudachiDict)は、専門家の手による高品質なものです。また、こういった辞書は、国立大学などで作られることが多くその更新が止まることがしばしばありますが、この辞書は営利企業が少なくとも向こう10年は続けていこうという気概の、非常に珍しいものです。
Sudachiの特徴としては、以下のものがあります;
- 複数の分割単位:
国立国語研究所→ A「国立国語研究所」、B「国立国語研究所」、C「国立国語研究所」 - UniDicとNEologdをもとにした300万語近い収録語彙: 一般的なIPADICは約24万語
- 表記の正規化: {
空き缶,空缶,空き罐,空罐,空きカン,空きかん} → 全て空き缶に - 機能のプラグイン化: 未知語処理、数値正規化、... ユーザーも独自のプラグインを作成できる(品番・型式の抽出、など)

この記事では詳しく述べませんが、ご興味ある方は以下の参考資料を是非ご覧ください。
Sudachiに関する参考資料
まずは ...
- スライド: Sudachi ❤︎ Elasticsearch - Speaker Deck (Elasticsearch勉強会 in 京都, 2018/08/02)
- Qiita記事: Elasticsearchのための新しい形態素解析器 「Sudachi」 - Qiita (Elastic stack Advent Calendar 2017)
論文 ...
- 論文(日本語): 形態素解析器『Sudachi』のための大規模辞書開発 (国立国語研究所 言語資源活用ワークショップ2018)
- 論文(英語): Sudachi: a Japanese Tokenizer for Business (LREC2018)
メイン開発者による資料 ...
- スライド: 形態素解析の話 by 高岡一馬 @ NLPエンジニアによる自然言語処理の実用化にむけた勉強会, 2017/6/22
- スライド: Javaでつくる本格形態素解析器 by 高岡一馬 @ JJUG CCC 2017 Fall, 2017/11/18
Sudachi ファミリー
まず、本家の「Java版Sudachi」があり、これが全てのもととなっています。これを全文検索エンジンElasticsearchで使うためのプラグイン「elasticsearch-sudachi」も提供されています。
Pythonクローンとして、その名も「SudachiPy」も公式で開発していますが、まだ本家に追いついていない機能があったりします。
言語資源は「SudachiDict」として公開されていて、定期的にアップデートされています(下のようにSudachi公式Slackワークスペースでもアップデートを随時告知しています。参加はGitHubページの末尾から)。
また、今年(2019年)11月には新たに、SudachiDictの語に同義語関係を付与した辞書もリリースしました。専門家による力作です。現在1.7万グループ、4.6万語収録。語彙辞書と同様、継続的に拡充していく予定です。
以上が公式のものですが、他にも、非公式のGo実装「msnoigrs/gosudachi」もあります。
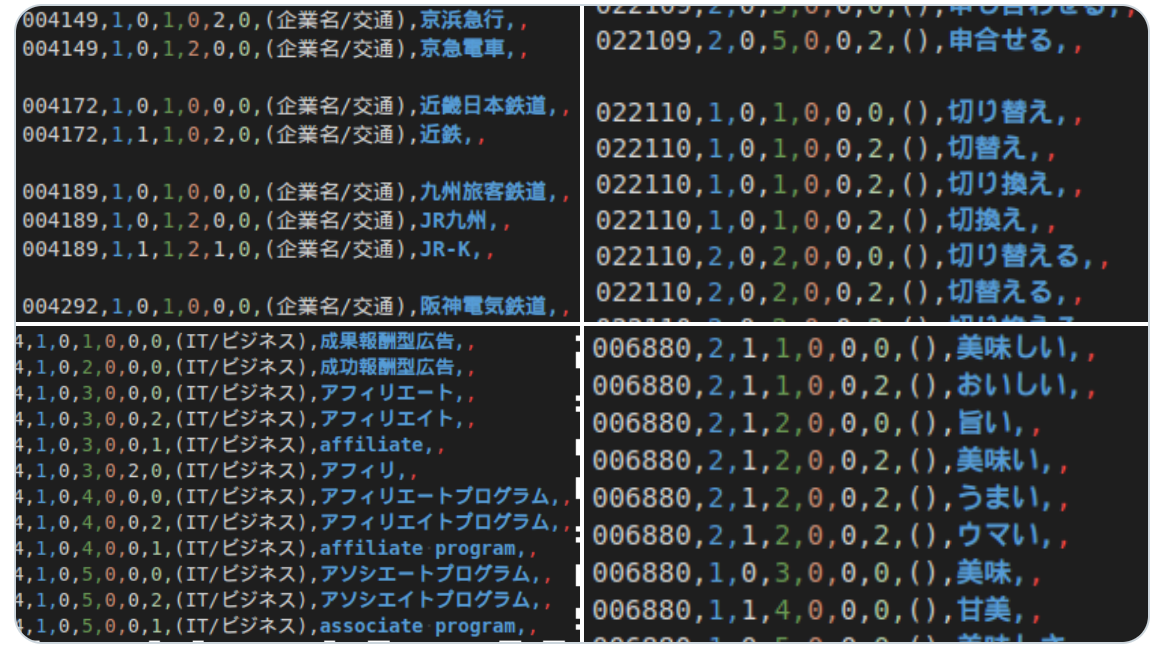
SudachiDictの構造
上で紹介したJava版とPython版は、同じ辞書バイナリを利用しています。バイナリ内には大きく「Header」「Grammar」「Lexicon」という三つのカテゴリに分けられています。
最初の「Header」には、辞書自体の情報が含められています。辞書バイナリの形式が変わったときに、ここでのversionも更新されます。
「Grammar」では、品詞の情報であったり、単語の”繋がりやすさ”を示す連接コストなどがみられます。
「Lexicon」には、語彙情報や、それを引くためのトライ木が収納されています。
この記事では残念ながら詳細にまでは踏み込みませんが、簡単に辞書バイナリ全体がどうなっているかを表にまとめてみました。もし皆さんが sudachi.jl であるとか sudachi.js 、 sudachi.rb 、などなどをつくることがあれば、参考になるかもしれません。
| Category | bytes | Name | Size (bytes) | Type | Desciption |
|---|---|---|---|---|---|
| Header | x | version | 8 | u64 | |
| Header | x | create_time | 8 | u64 | |
| Header | x | description | 256 | utf8 | |
| Grammar | x | pos_size | 2 | u16 | |
| Grammar | x | pos_list | (1 + length*2) * POS_DEPTH | u8, utf16 | utf16 text length, u16 * length, POS_DEPTH=6 |
| Grammar | x | left_id_size | 2 | i16 | |
| Grammar | x | right_id_size | 2 | i16 | |
| Grammar | o | connect_table | left_id_size * right_id_size * 2 | ||
| Lexicon | x | trie_size | 4 | u32 | number of elements |
| Lexicon | o | trie_array | trie_size * 4 | u32 List | |
| Lexicon | x | word_id_table_size | 4 | u32 | |
| Lexicon | o | word_id_table | word_id_table_size | ||
| Lexicon | x | word_params_size | 4 | u32 | {left,right}_id, cost |
| Lexicon | o | word_params | word_params_size * ELEMENT_SIZE | (i16, i16, i16) List | ELEMENT_SIZE=2*3 |
| Lexicon | o | word_infos | <rest> |
🦀 sudachi.rs: Rustによる実装
ここまで、Sudachiとその辞書SudachiDictについて述べてきました。
前置きが長くなりましたが、このSudachiDictを使うRustツール、「sudachi.rs」をつくっています。ここまで何度か述べましたが、私は会社でSudachiの開発に関わっています。ただ、このRust版Sudachiは、個人的にRustに興味があるけど仕事で使うこともないので、趣味でプライベートの時間に作っています。
なぜRustか
きっかけは忘れてしまいましたが、Rustをどこかで聞いて、少し触ってみると、自分の感性にあっているのか、良さそうだなあ、センスがいいなあという印象を持ちました。また、exa(lsコマンドのモダンな代替)やbat(catやlessの代替)、xsv(csv処理のためのCLIツールキット)といったクールなコマンドラインツールは、最近は軒並みRustで書かれているというのも、気になっていた理由のひとつです。
一方、近年の機械学習の世界、特にニューラルネットワークを用いるものは、ほとんどPythonで行われているという印象を持っています。それは、圧倒的なエコシステムがあるからで、ゼロから自分でフレームワークをつくるということは、奈良の山奥に籠もってでもいないとなかなかできないでしょう。
しかし、他の機械学習分野は詳しくないのですが、少なくとも自然言語処理では、行列計算に関わらないようなところのツールもちょくちょくあります。そしてそれらは、Pythonで書かれることも多いですが、C++やJavaで書かれることもよくあります。例えば、MeCabはC++で作られていますし、同じ作者によるSentencePieceもそうです。
ちょっとした前処理ならPythonでも十分かもしれませんが、大量のデータを高パフォーマンスに捌きたいとき、かつ数値計算をしないようなものであれば、「C/C++のようなレベルの言語」で書くことが適しているでしょう。そしてこの2019年には、そこには自然とRustが候補として挙がります。
私としては、たまたま形態素解析器「Sudachi」に馴染みがあったので、その流れで、Rustでゼロから作ってみようと思った次第です。
実際に使ってみて、ある種の自然言語処理ツールとRustは非常に相性がいいのではないかと感じています。現代の新しいプログラミング言語らしく他の言語にある欲しいものは一通りそろっていますし、CLIツールとしてつくるときも都合が良い。私はC++の深い経験がないのですが、もしC++の蓄積がなくて2019年に言語を選べるのであればRustはいいチョイスだと思いますし、逆に、C++を長くやってきた人こそRustの恩恵を深々と感じられるのだろうなあ、という風にも思っています。
例えば、Go言語でもいいのではないかと言われると、それはその通りだと思います。私は好みとしてRust寄りで、また、Rustをダシに計算機について理解を深めているというところがあります。普通の用途で、Rustレベルが求められるかというと、そうでもないことが多いでしょう。私は、楽しいからやっています。
Rustのありがたみを理解するには、CやC++を真剣に書いて、リソース管理の難しさを体験しなければいけない。あるいは、GCのある言語で難しいことをして、本来ありがたい存在であるはずのGCの挙動を理解しながらコードを書くことの不毛さを体験しなければいけない。そこまでやってはじめて、Rustを学ぶ価値が生まれてくる。彼らの言葉を借りるならば、低レベルを理解している人間にしかRustは価値ないんです。パターンマッチとか関数型のテイストだとか、そんなものが欲しいならばOCamlやScalaでもやればいいんです。わざわざこんな学習コストの糞高い言語を学ぶ価値なんかひとっつもないんです。
Rustを勉強したら低レベルが理解出来る!!!わけねえだろ - テストステ論
ちなみに、sudachi.rsの前にもすでに、Rustでの形態素解析の実装例はあります;
- agatan/yoin: A Japanese Morphological Analyzer written in pure Rust
- wareya/notmecab-rs: notmecab-rs is a very basic mecab clone, designed only to do parsing, not training.
参考にした資料
Rust は「学習コストが高い」言語というよりは「プログラミングの学習コストを可視化してくれる」言語といったほうがいいかもしれません。これまで「雰囲気でプログラミング」してきた人にとって Rust の学習コストが高く感じるのは、きちんと可視化がうまくいっている結果です。
六本木ではたらくソフトウェアエンジニアへのよくある質問とその答え (FAQ) (2015 - 2017) - hayato
Rustは「難しい」と感じましたが、一方で、「ちゃんと計算機科学を学べている!」という知的興奮も大きくあり、その学習はとても楽しいものでした。今でも分からないことは沢山ありますが、コミュニティとして、教材やドキュメンテーションに力をいれており、様々な読み物が用意されています。個人的には、以下のものが参考になりました。トピックは山のようにありますので、やりながら、手を動かしながら、またドキュメントに戻ってくる、というようにすると良いのではないでしょうか。
- Exercism - Rust: 練習問題が沢山あり、他人の回答がとても参考になる
- 実践Rust入門: 日本語、親切な本
- Programming Rust (O'Reilly): 分厚くて読み応えがある、良い本
- This Week in Rust Rustのニュースがまとめられたメルマガ、良質
- The Rust Programming Language (The Book): 公式ドキュメント、書籍バージョンも
また、C++とRustを、19世紀における商業鉄道の発展・安全性向上とのアナロジーで語った以下の講演も、Rustの標榜するものを見る際の興味深い視点を提供していて、面白かったです。
Rust: A Language for the Next 40 Years - Carol Nichols - YouTube
実装のあれこれ
Rustを始めた誰もが言うことでしょうが、なかなかコンパイルできない。コンパイラによって、自分がちゃんと分かってないことが露わにされていき、通すために調べ、直し、また調べ、... ということの繰り返しで、すこしづつ進んでいきました。
CLIとして利用する際のコマンドラインのオプションは、structoptというクレート(Rustでのライブラリ)を使っています。これは公式ドキュメントでのCLIをつくるチュートリアルで紹介されて知りました。便利で、不満がありません。
上で述べた辞書バイナリのパースですが、最初はbyteorderという、数値をエンディアン指定して読み込めるクレートを使い、ちまちまとひとつずつ書いていました。それから、nomというパーサーコンビネーターのクレートを知り、こちらを今は使っています最初はパーサーコンビネーターというものが分かっておらず、なにが起こっているのか分からなかったのですが、ドキュメントをゆっくり読み進めていくと徐々に視界が開けて、便利なものだなあと思うようになりました。
辞書バイナリをどう管理するかについては、まだ悩んでいます。辞書ファイルをユーザーが別途ダウンロードして任意の場所に置く、というようなやり方でなく、上手く管理したいのです。例えばPythonであれば、辞書はそれ自体をPyPIにライブラリとして登録し、$ pip install sudachipy sudachidict-small というようにインストールすることですぐに使い始めることができます。$ cargo installコマンドでは、バイナリのみがインストールされます。現状のsudachi.rsでは、include_bytes!というマクロで辞書をsudachiバイナリ自体に内包しています。バイナリ以外にもリソースファイルをインストールできるようにしようという話は挙がってはいるので(Add support for resource files · Issue #5305 · rust-lang/cargo)、実現されればまたそれに沿った対応ができるのですが。
一番悩んだのは、「Nodeが他のNodeへの参照を保持するべきか」というところでした。ラティスのend_listsには、Nodeの一覧が入っています。そして各Nodeは、best_previous_node(ラティスで、そこまでで一番良いパスの最後尾)を持っていてそれは別のNodeを参照したいが ... 回避策として、Nodeへの参照ではなく、 そのNodeのend_lists内でのインデックスを保持するようにしています。この例ではそれでいいと思っていますが、もしそのような回避策がない場合には、どうすればいいのかが未だに明確に分かっていません。
どうすればいいか分からずしかたなくコピーしているところがあったり、パフォーマンス最適化という点では、現状のsudachi.rsはまだまだ無駄が多いです。エラー処理も雑です。このあたりは、他のクレートの中身を参考にしたりして、改良していくことができるのではないかと思います。
終わりに
Rustは難しいですが、ちゃんと物事の裏側とその理由を把握できて、納得感があり、また楽しいものです。少しずつ理解が深まっていくことが、楽しみに繋がっています。しかし、まだまだ分からないことは山のようにある。丁寧に書かれている公式ドキュメントなどを一度読んでも、深い理解は得られない、何が問題かが分からない。実際に作りはじめて、問題に直面し、色々と調べて書き直す中で、学んでいくことが多かったです。そしてその過程で、様々な気づきがありました。難しいからこそ、面白い、楽しい。
「難しいと聞いたし、自分の分野とは関係ないから ...」という皆さんも、ご興味を持たれたらぜひ、Rustに触れその奥深い世界を覗いてみてください ![]() → rust-lang.org
→ rust-lang.org