embulk-output-bigquery の Partitioned Table 対応で調べてたので、その時に調べたものを雑にまとめておく。APIを直接叩いて実装しているので、bq コマンドでの使い方については調べていない。
EDIT: 現在は DATE もしくは TIMESTAMP カラムを指定した partitioning が可能ですが、本ドキュメント記載時にはまだ BigQuery がサポートしていなかったため、その記述が抜けています。
TL; DR
- 基本的に tableId に partition decorator (
$YYYYMMDD) を指定して操作する - DAYパーティションしか(今のところ)切れない。
- 特定パーティションのデータを置き換えたい場合は、パーティションを指定して、
writeDisposition: 'WRITE_TRUNCATE'として load (または copy)ジョブを発行する - Tables: delete API で partition decorator を指定すれば partition だけを消せる
- スキーマ変更はカラム追加、既存カラムをNULLABLEにすることによる擬似的な削除、ぐらいしかできない
- 追記: DML (update, delete, insert) は(今のところ)できない
Partitioned Table の作り方
See https://cloud.google.com/bigquery/docs/creating-partitioned-tables
Tables: insert API を使って、テーブルを作成する時に
{
"tableReference": {
"projectId": "myProject",
"tableId": "table2",
"datasetId": "mydataset"
},
"timePartitioning": {
"type": "DAY",
"expirationMs": 259200000
}
}
のように timePartitioning パラメータを設定すれば良い。
特記事項: 現在、type は DAY しか選択できない。HOUR や MONTH や時間以外のパーティションを切ることはできない。
スキーマ指定
以下のいずれか
- Partitioned Tableを作る際に schema を指定する
- 最初のデータ投入時に schema を指定する
- 最初のデータ投入時に BigQuery の持つ自動スキーマ推定機能にまかせる
「Partitioned Tableを作る際に BigQuery の持つ自動スキーマ推定機能にまかせる」はできない(データがないので)。
一度決めると、パーティションのデータを置き換えてもテーブルのスキーマは置き換えられない。
データのスキーマがテーブルのスキーマに合わない場合はエラーとなる。
スキーマ変更
NULLABLEなカラム追加と、既存カラムのNULLABLEへの変更のみサポートされている。
Tables: patch もしくは Tables: update を利用する.
または load job、 copy job、query job に schemaUpdateOptions というパラメータが増えており、job の副作用として、カラムの追加(ALLOW_FIELD_ADDITION)、もしくは既存カラムをNULLABLEにすることによる擬似的なカラムの削除(ALLOW_FIELD_RELAXATION)を行うことができる。
{
"configuration": {
"load": {
"destinationTable": {
"tableId": "table$20160929"
},
"writeDisposition": "WRITE_TRUNCATE",
"schemaUpdateOptions": ["ALLOW_FIELD_ADDITION", "ALLOW_FIELD_RELAXATION"]
}
}
}
追記: 残念なことに copy job には schemaUpdateOptions オプションがなかった…!
Partitioned Table (から|へ)の copy
Jobs: insert APIを使って、copy する際に table にパーティションデコレータ($YYYYMMDD)を指定すればよい。
{
"configuration": {
"copy": {
"sourceTable": {
"tableId": "from_table$20160929"
},
"destinationTable": {
"tableId": "to_table$20160929"
},
"writeDisposition": "WRITE_TRUNCATE"
}
}
}
試した所、以下のいずれのパターンも動作した。
- table から partition
- partition から table
- partition から partition
- table から table (partition 構成もコピーされる)
特記事項: table へのコピーの場合は table が自動で作られるが、partition へのコピーの場合は自動では作られないので、あらかじめ create table しておかないといけない。embulk-output-bigquery では auto_create_tableオプションが有効な場合は、自動で作るようにしておいた。
Partitioned Table への load
こちらも Jobs: insert APIを使って、load する際に table にパーティションデコレータ($YYYYMMDD)を指定すればよい。
{
"configuration": {
"load": {
"destinationTable": {
"tableId": "table$20160929"
},
"writeDisposition": "WRITE_TRUNCATE"
}
}
}
write_disposition: 'WRITE_TRUNCATE' とすれば、指定パーティションを atomic に置き換えできる。
Drop Partition
Tables: delete API で partition decorator を指定すれば partition だけ消せる
Partitioned Table への変換
bq コマンドでできる。See https://cloud.google.com/bigquery/docs/creating-partitioned-tables
bq partition mydataset.sharded_ mydataset.partitioned
内部的には table 一覧を取って、copy job で日付 suffix と対応する日付 partition にデータをコピーする処理を繰り返している。
パーティション一覧および作成、更新時間の取得
Legacy SQL で
SELECT partition_id,creation_time,last_modified_time from [mydataset.table1$__PARTITIONS_SUMMARY__];
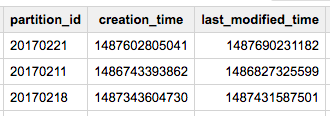
Hint: TIMESTAMP型に変更したければ MSEC_TO_TIMESTAMP(creation_time) のようにすればよい
クエリ対象のパーティションを絞る
See https://cloud.google.com/bigquery/docs/querying-partitioned-tables
_PARTITIONTIME疑似カラムに対してWHERE条件を書く
SELECT
field1
FROM
table2
WHERE
_PARTITIONTIME BETWEEN TIMESTAMP('2016-01-01')
AND TIMESTAMP('2016-01-21');
TABLE_DATE_RANGEによるテーブル検索(けっこう遅い)の時間がかからなくなるため、結果が返ってくるのが速くなるようだ。
custom quota 残量について
EDIT: 2017/03/27の更新で_PARTITIONTIMEで絞り込んだ場合でもquotaが絞られるようになったようです ![]() ref. issues/35950907
ref. issues/35950907
_PARTITIONTIME で絞り込んだ場合でも、テーブル全体の容量が custom quota から差し引かれる。例えば、テーブルの容量が1TBで、絞り込んだパーティションが100GBでも、1TB差し引かれてしまう。 ref. https://cloud.google.com/bigquery/cost-controls "it currently ignores any _PARTITIONTIME or _TABLE_SUFFIX filters in the query"
これを防ぐには、table_name$YYYYMMDD のように partition decorator で特定のパーティションを指定してスキャンする。この場合は、そのパーティションのデータ量だけquota残量が減る(テーブル全体のスキャン量ではなく)。ただし、Legacy SQL でしかこの手法は使えず、Standard SQL ではエラーとなる。ref. http://stackoverflow.com/questions/40638564/is-it-possible-to-access-a-bigquery-partition-in-standard-sql-using-the-deco
Partitioned Table への DML (update, delete, insert)
cf. https://cloud.google.com/bigquery/docs/reference/standard-sql/data-manipulation-language
DML statements that modify partitioned tables are not yet supported.
とのことでまだ利用できない(2017/03/09調べ)