要点
- OpenAI CLIPの日本語モデルを作り、公開しました。ご活用ください。
-
CLIPとは画像とテキストの埋め込みモデル(意味を表す固定長のベクトルに変換するモデル)であり、意味が近い画像とテキスト同士が近いベクトルになるという性質を持っています。4億枚の多様な画像とテキストのペアを用いて学習されており、高いゼロショット性能を備えています。
- 応用例:テキストによる画像の検索、類似画像検索、画像 and/or テキストの分類、クラスタリング、画像やテキストの特徴量生成など
- 日本語CLIPモデルはHugging Face Model Hubからダウンロードできます。
- 応用方法を理解するためのサンプルコードとその解説を、4つの記事にして順次公開する予定です。進捗状況: 1/4。
日本語CLIPモデルの使い方、サンプルコード(鋭意作成中)
長くなるので使い方の解説は別の記事にしました。
すぐに試してみたいという方は、これらのリンク先にお進みください。
日本語CLIPモデルを用いたマルチモーダル処理の例として、類似度計算、画像やテキストの埋め込み計算、類似検索(ゼロショットとファインチューニングの両方)、画像+テキストの分類タスクのサンプルコードと解説を別記事として順次公開していきます。
- 基礎: 画像とテキストの類似度計算、画像やテキストの埋め込み計算、類似画像検索
- (公開準備中) 応用: いらすとや画像のマルチモーダル検索(ゼロショット編)
- (公開準備中) 応用: いらすとや画像のマルチモーダル検索(ファインチューニング編)
- (公開準備中) 応用: 画像とテキストの両方を用いたマルチモーダル分類
OpenAI CLIP
OpenAI CLIPは非常に有名ですし、日本語での論文解説記事や実験報告記事も多くありますので解説不要ですよね。
- 本家:
- 日本語記事の例:
CLIPは、次のような実用上嬉しい特徴を備えています。使わない手はないですね。
- 従来のモデルに比べて、非常に広いクラスのオブジェクトを認識できる。
例えばImageNetデータセットを用いて学習したモデルではデータセットにある1000クラスから外れたオブジェクトを扱おうとすると精度が出ないケースがある。CLIPはインターネット上にある4億枚の多様な画像を用いて学習していることが効いている。 - 画像とテキストの両方の埋め込みができる。画像から類似画像を探したり、テキストから類義テキストを探したりできるだけでなく、テキストから類義画像を探したり、その逆もできる。
- ゼロショット(個別タスク用にファインチューニングしない)でも精度が高いケースがある。ファインチューニング用のデータセット構築が大変になるタスクの場合はとても嬉しい。
CLIPの日本語化方法の概要、精度評価
CLIPの日本語化の方法について説明します。
一言で言えば、英語用CLIPテキストエンコーダーを教師モデルに、日本語用CLIPテキストエンコーダーを生徒モデルにした一種の蒸留をしました。
CLIPは下図(CLIPのリポジトリから引用)のように、テキストエンコーダーと画像エンコーダーで構成されます。

本家のCLIPの作り方にならい、日本語キャプションが付いた4億画像を収集してゼロから画像とテキストのエンコーダーを作れたら素敵なのですが、それは大変大掛かりなことになります。そこで今回はCLIPの画像エンコーダーは本家のものをそのまま利用し、テキストエンコーダーのみ一種の蒸留を用いて日本語化しました。
具体的には、CLIPの日本語化はMultilingual-CLIPを参考にして、以下のステップで行いました。
- CLIPのデータセット(WebImageText)に近い統計的性質を持った、英語と日本語の対訳ペアを作る。既存の画像キャプション(英語)データセットであるConceptual Captions、COCO train/val 2014、VizWizを日本語に機械翻訳することで作成。訓練データは382万件、テストデータは26万件。
- OpenAIにより公開されている英語用CLIP-ViT-B/32モデルのテキストエンコーダーを用いて、1のデータセットの英語文の埋め込みベクトル(512次元のベクトル)を作成。これが教師データになる。
-
日本語Sentence-BERTモデルを、1のデータセットの日本語文(と英語文)を入力したときに2の教師データを出力するように(教師データとの平均二乗誤差が小さくなるように)転移学習する。今回、転移学習は Fine-Tuning can Distort Pretrained Features and Underperform Out-of-Distribution で提案されている2段階で学習する方法に従い、まず全結合層のみ更新し、次に全ての重みを更新するようにしました。
- ネットワーク構造: テキスト → Sentence-BERTのCLSトークンの埋め込み(最終6層分) → 全結合層 → 埋め込みベクトル
- 主なハイパーパラメータ:
- 最適化アルゴリズム: AdamW
- 前半4エポック
- 更新する重み: 全結合層のみ
- 学習率: 1e-3
- スケジューラー: 線形(warmup: 0.05エポック)
- バッチサイズ: 2560
- 後半4エポック
- 更新する重み: 全ての重み
- 学習率: 4e-4
- スケジューラー: 線形(warmup: 0.05エポック)
- バッチサイズ: 256x4
日本語CLIPテキストエンコーダーの精度を見てみましょう。
まずはマクロな評価です。ステップ1で作ったテストデータ(26万件)に関する平均二乗誤差は 0.00947 でした。
次にミクロな評価です。ランダムにサンプリングした16文(下表参照)を用いて、テキスト同士の類似度(埋め込みベクトル間のコサイン)がどの程度再現されるか確認します。
| ID | 英語 | 日本語 |
|---|---|---|
| 0 | Two little bears sitting on a weathered wood chair. | 風化した木の椅子に座っている2匹の小さなクマ。 |
| 1 | A young boy in a backyard standing with one foot on a skateboard. | スケートボードに片足で立っている裏庭の少年。 |
| 2 | A modern style wooden kitchen with multi layered counters. | 多層カウンターを備えたモダンなスタイルの木製キッチン。 |
| 3 | A giraffe standing next to a covered structure. | 覆われた構造物の隣に立っているキリン。 |
| 4 | An old man is trying to use his cell phone. | 老人が自分の携帯電話を使おうとしています。 |
| 5 | A traffic sign of some sort at a street corner. | 街角にあるある種の交通標識。 |
| 6 | A large mural on a building at an intersection. | 交差点の建物の大きな壁画。 |
| 7 | A double parking meter is decorated with a picture of a girl with wings on her feet. | ダブルパーキングメーターは、足に翼を持った少女の写真で飾られています。 |
| 8 | Small potted tree next to bench on a porch. | ベランダのベンチの横にある小さな鉢植えの木。 |
| 9 | People sitting at tables inside a large clock tower. | 大きな時計台の中のテーブルに座っている人。 |
| 10 | A brown bear standing up that almost looks fake. | ほぼ偽物に見えるヒグマが立っています。 |
| 11 | White boat navigating on waterway near populated area. | 人口密集地域の近くの水路を航行する白いボート。 |
| 12 | A small boy is running through a kitchen. | 小さな男の子が台所を駆け抜けています。 |
| 13 | A street lined with parked cars and trees | 駐車中の車や木々が立ち並ぶ通り |
| 14 | a motor bike parked on the side of the road by the bushes | 茂みのそばの道路脇に駐車したバイク |
| 15 | A group of cows are standing in the grass together. | 牛のグループが一緒に草の中に立っています。 |
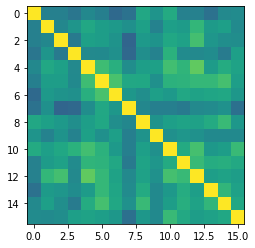
まずは英語版のCLIPモデルを用いて埋め込んだ英語テキスト同士の類似度行列を可視化してみます。類似度行列の i 行 j 列の値は、IDが i の文とIDが j の文の類似度(2つの埋め込みベクトルがなす角のコサイン)です。明るい色ほど類似性が高い(値が大きい)ことを表しています。
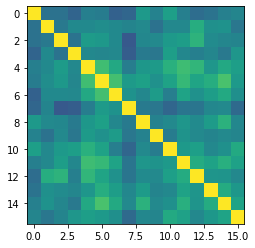
次に、日本語版のCLIPモデルを用いて埋め込んだ日本語テキスト同士の類似度行列を可視化します。
やや白んでいますが、英語版のものと傾向は似ており、悪くはなさそうであることが分かります。
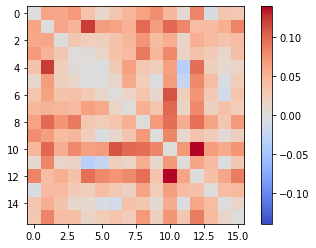
もう少し精密にみるために、日本語と英語の類似度行列の差分(誤差)を可視化してみます。
全体的に赤みがかっており、日本語モデルでは英語モデルより、ややプラス側にシフトしている(より似ていると判定する)傾向があることが分かります。シフトの量は平均 0.042、プラス方向に最大 0.138 程度、マイナス方向に最大 0.035 程度ですので概ね許容できるレベルであることが分かります。
最後に、英語の埋め込みベクトルと日本語の埋め込みベクトルの類似度行列を可視化します。
理想としては、対角要素は1.0になり、非対角要素は対称になってほしいものです。

概ね理想形になっていることが分かりますね!
本記事ではテキストエンコーダー部分の精度評価を行いました。
画像とテキストの両方を用いた場合の精度については続編の画像とテキストの類似度計算、画像やテキストの埋め込み計算、類似画像検索をご参考にしてください。
実際に日本語CLIPモデルを応用する方法については、サンプルコードと解説記事を順次追加していきますので、そちらをご参照ください。
免責事項
本モデルの作者は本モデルを作成するにあたって、その内容、機能等について細心の注意を払っておりますが、モデルの出力が正確であるかどうか、安全なものであるか等について保証をするものではなく、何らの責任を負うものではありません。本モデルの利用により、万一、利用者に何らかの不都合や損害が発生したとしても、モデルやデータセットの作者や作者の所属組織は何らの責任を負うものではありません。利用者は本モデルやデータセットの作者や所属組織が責任を負わないことを明確にする義務があります。
CLIPモデルはインターネットで公開されている画像とテキストを用いて学習されており、その偏り(国、社会、人種、性別、年齢、抽象度、粒度など)に由来した様々な問題が生じ得ます(詳細)。 問題が発生しうることを想定した上で、被害が発生しない用途にのみ利用するよう気をつけてください。
つづく
CLIPの日本語モデルを作り、公開しました。どうぞ、ご活用ください。
日本語CLIPモデルの応用方法について解説する記事(サンプルコード、サンプルアプリ付き)を鋭意作成中です。少々お待ちください。