はじめに
こんにちは、sonicyannと申します。中国出身で、日本で2年間SESプログラマーとして働いていました。現在は退職して、AIを活用したコーディングで独立開発を行っています。
今回は、最近開発したkanasonic(パナソニックではありません😂)というツールを紹介させていただきます。このツールの主な機能は、日本語のひらがな、カタカナ、ローマ字、漢字の相互変換です。さらに、全角・半角変換機能も実装しました。
開発のきっかけ
このツールを作った理由は、実際の業務でよく遭遇する課題を解決したかったからです。ウェブサイトの登録や銀行口座の開設時に、システムから「ひらがなで入力してください」や「全角で入力してください」といった要求がよく出てきます。しかし、長い住所などを手動で入力すると、ミスが発生しがちです。そんな時に便利な日本語変換ツールが必要でした。
そこで、Google検索で既存のツールを探してみたところ、1位に表示されたサイトがこのような感じでした。
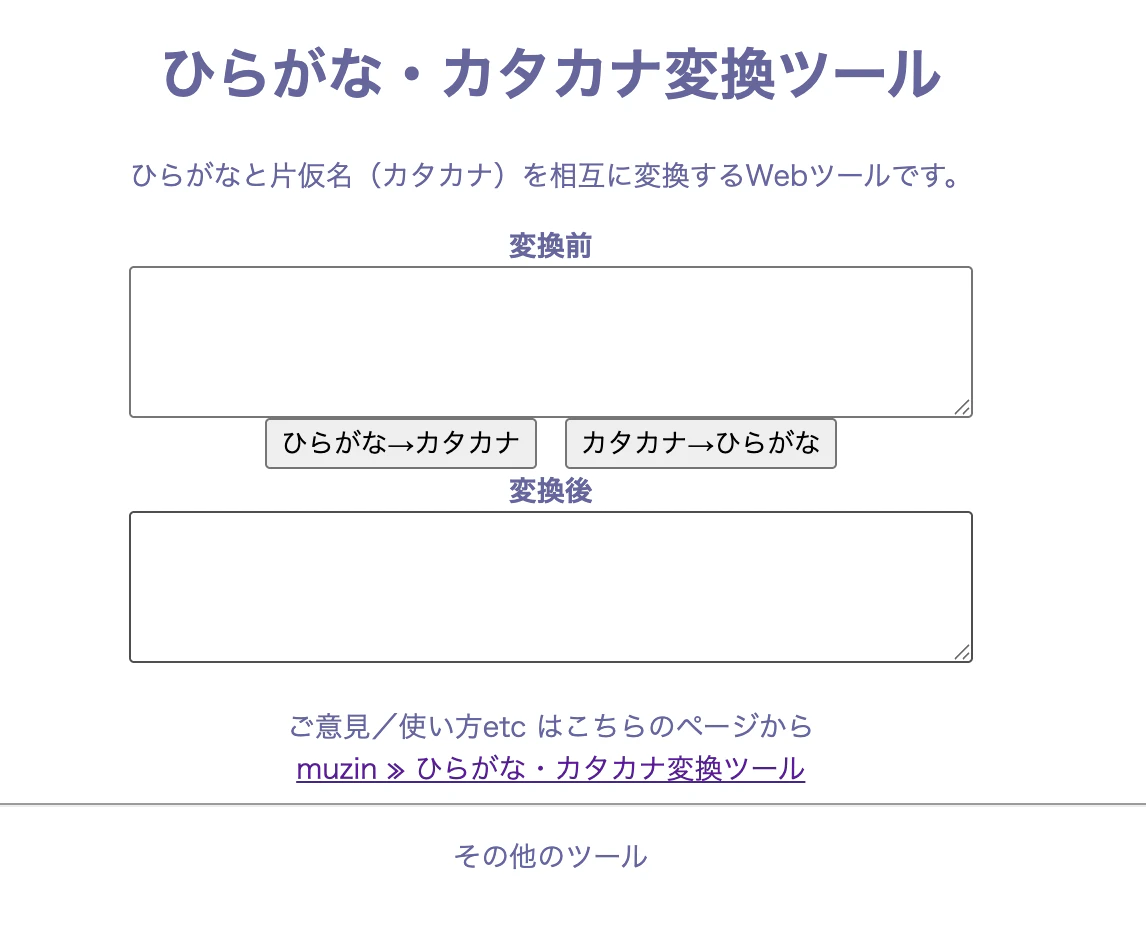
ページの簡素さと使いづらさに衝撃を受け、「このサイトの10倍使いやすいサイトを作ろう」と決意しました。その日のうちに開発を開始し、深夜2時半に完成・公開しました。
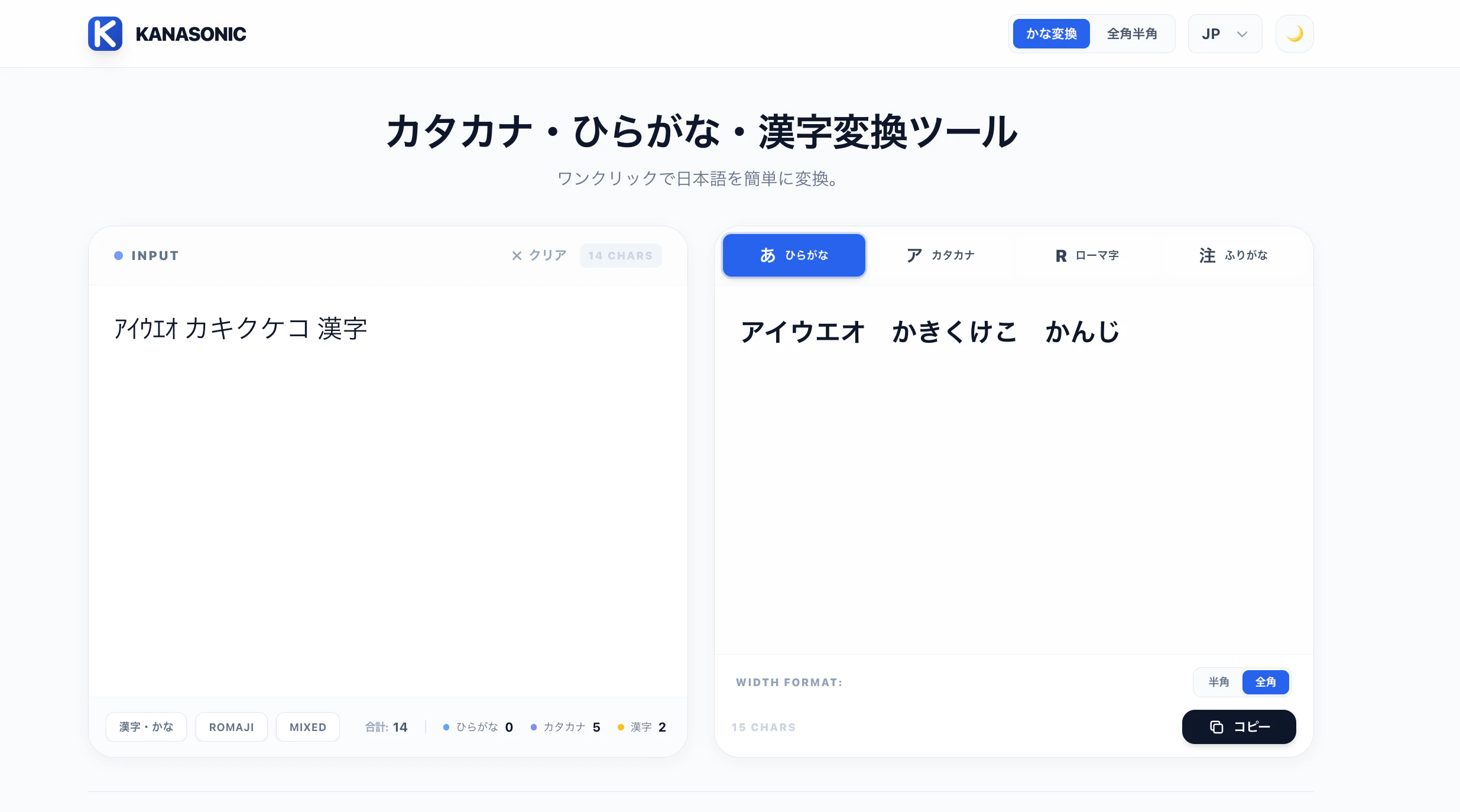
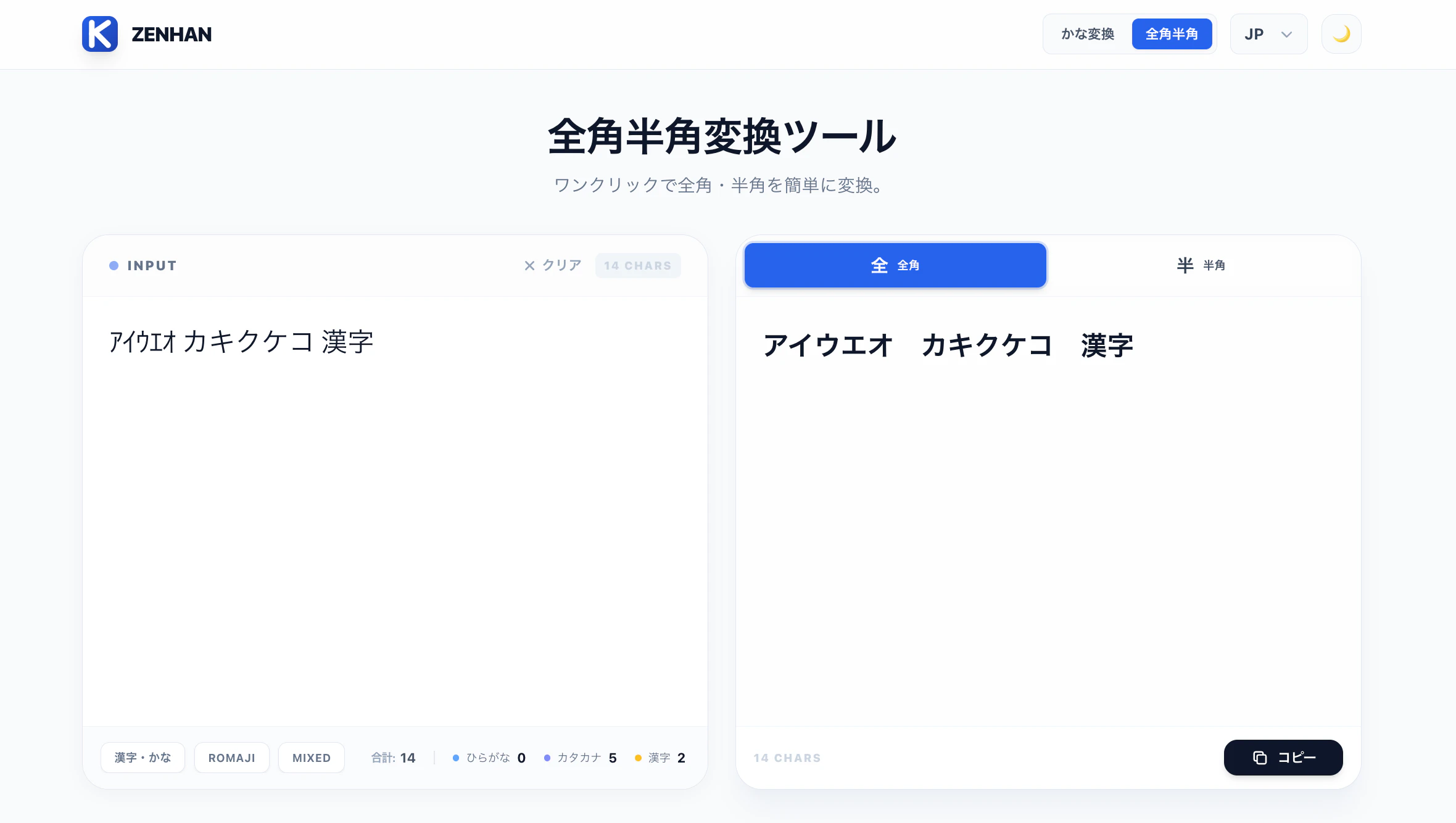
ツール名の「kanasonic」は、ひらがなとカタカナの「kana」と、私の英語名「sonic」を組み合わせたものです。
主な機能
このツールの最大の特徴は、任意の入力形式(ひらがな、カタカナ、漢字など)から、以下の形式への変換が可能なことです:
- ひらがな変換
- カタカナ変換
- ローマ字変換
- ふりがな付き(漢字に読み仮名を追加)
- 全角・半角変換
リアルタイムで変換が行われ、ミリ秒単位の高速なレスポンスを実現しています。また、ダークモードにも対応しており、長時間の使用でも目に優しい設計になっています。
技術実装の詳細
プライバシー保護:すべての処理をブラウザ側で実行
このツールの最大の特徴は、すべての処理をローカル(ブラウザ側)で実行することです。入力されたテキストがサーバーに送信されることは一切ありません。これにより、個人情報や機密情報を安心して入力できます。
形態素解析エンジン:kuromoji.js
日本語の漢字から読み仮名への変換には、kuromoji.jsという形態素解析ライブラリを使用しています。このライブラリは、日本語テキストを単語に分割し、品詞情報や読み方を取得することができます。
辞書ファイルのローカル配置
通常、kuromoji.jsの辞書ファイルはCDNから読み込まれることが多いのですが、このツールでは以下の理由から辞書ファイルをローカルに配置しています:
- プライバシー保護:CDNへのリクエストを最小限に抑える
- パフォーマンス:同一オリジンからの読み込みでHTTP/2の恩恵を受ける
- 信頼性:外部CDNの障害に影響されにくい
辞書ファイル(base.dat.gz、cc.dat.gzなど)は、GZIP形式のままpublic/dict/ディレクトリに配置し、ブラウザ側で自動的に解凍されます。
開発・デプロイの流れ
開発環境:Google AI Studio & Cursor AIの活用
最初はGoogle AI Studioを使って全体のフレームワーク(雛形)を自動生成し、そのコードをGitHubリポジトリにプッシュしました。その後、Cursorで細かな開発やデプロイ作業を進めました。実は全工程で自分では一行もコードを書いていません。AIの力だけで、短時間で高品質なリリースを実現できました。
デプロイ:Cloudflare Pages + Workers
このツールは、Cloudflare PagesとCloudflare Workersを組み合わせたサーバーレスアーキテクチャでデプロイしています。
SEO対策
Qiitaの読者の方々に少しでも多くの人に知ってもらうため、SEO対策も実施しました:
- 多言語対応:日本語、英語、中国語の3言語に対応
- 静的ページ生成:ビルド時に各言語のエントリーページを事前生成
まとめ
kanasonicは、実用的な課題を解決するために、最新の技術スタックを活用して開発したツールです。特に、プライバシー保護と使いやすさを重視した設計になっています。
ぜひ使っていただき、ご意見やフィードバックをいただけると嬉しいです!
お読みいただき、ありがとうございました!🎉