Pepperの音声認識は、任意の日本語テキストを取得できるか、をSpeech Reco.ボックスとQiChat scriptの2つの方法で試しました。QiChat scriptのWild card「*」を利用して任意の言葉を取得可能ですが、認識の精度はあんまり良くない結果になりました。
はじめに
Pepperチュートリアル (4):会話をする、音を鳴らすでは、Pepperが人間から喋った特定の言葉対して返事をする会話の作り方を紹介しました。主に「ボックスを使った音声認識 + 音声出力」と「QiChat scriptの活用」の2つの方法があります。
この記事で紹介された会話の作り方として、音声認識で認識したい言葉を事前に登録しておく必要が有ります。しかし、人間からどういう内容を喋ってくれるかを予想するのは大変ですし、現実的に無理の場合も有ります。例えば、以下のシーンを想定しましょう。
Pepper:こんにちは、お名前は?
人間:___と申します。
Pepper:___さんですね。よろしく。
「___」という人の名前を予知できなければ、認識したい言葉として事前に登録できません。そして、Pepperが任意の人を名前で呼ぶことも困難です。世の中のすべての人の名前を事前に登録しておけば、実現可能ですが、大変な作業になるでしょう。
Pepperは人間が喋った任意の言葉を認識できるかについて、Speech Reco.ボックスとQiChat scriptを調査しました。
Speech Reco.ボックスの調査
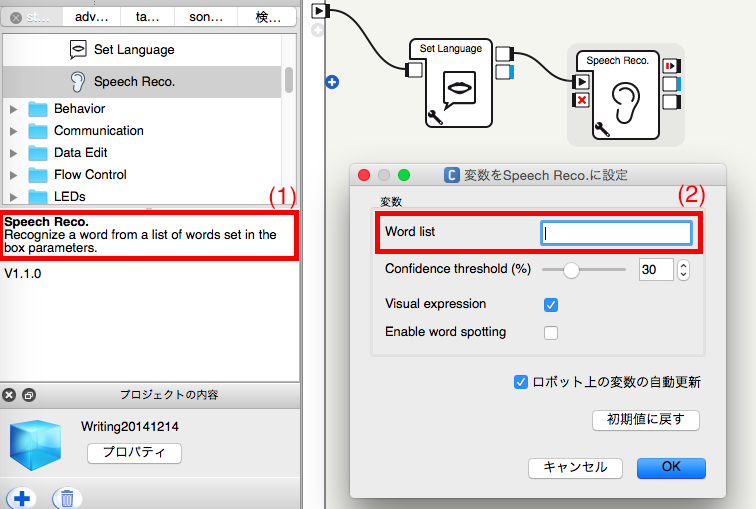
音声認識として最初に思いついたのはSpeech Reco.ボックスでした。しかし、Speech Reco.ボックスの説明に「パラメーターのWorld listに登録された言葉から1つ認識する」(1)と書かれていますので、おそらく任意の言葉は認識できないと思います。
下記のように、Speech Reco.ボックスのWord list(2)に言葉を登録せずに実行すると、何も認識できませんでした。
Pythonのコードを確認しますと、Speech Reco.ボックスではALSpeechRecognition APIを使っています。
ALSpeechRecognition APIは人間の声を認識したら、あらかじめ認識したい言葉のリストに登録された言葉から、**信頼度(confidence)**の高い言葉を抽出して出力するように作られています。Speech Reco.ボックスはALSpeechRecognition APIを利用している限り、それ以上のことはできないでしょう。
QiChat scriptでの実験
次に、QiChat scriptを利用して、人間が喋った任意の言葉を認識できるかを試します。
QiChatのドキュメントを確認したところ、人間が喋った任意の言葉を認識できる**Wildcard「*」**記号がありました。
Wildcard: *
Syntax
u:(sentence * sentence) answer
Usage
Matches any word or phrase.
http://doc.aldebaran.com/2-1/naoqi/audio/dialog/dialog-syntax_full.html#wildcard
**Wildcard「*」に合わせて、認識された言葉を変数に保存するInput storing「_」記号、および変数から保存された言葉を取得するVariable「$」**記号を併用すれば、人間が喋った任意の言葉をPepperから繰り返すことを実現できるではないかと考えました。
そして、下記のように単純なDialogボックスとQiChat scriptを作成して実験しました。
Pepperが人間が喋った名前を認識して、人を名前で呼ぶことと、その他の任意の言葉を聞いたら、末尾に「〜ですか?」と追加して返事することを試します。
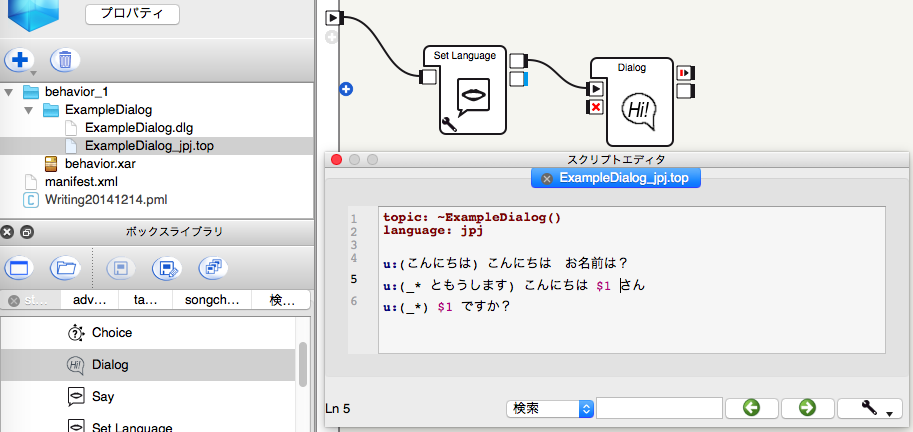
記号「_*」は人間が喋った任意の言葉を認識して、認識されたテキストを変数に保存します。
記号「$1」は保存されたテキストを変数から取り出します。
Dialogボックスの作り方は会話入門 (Pepper TechFes技術セッション)を参照してください。
QiChatの記号の詳細はQiChat Syntaxのドキュメントを参照してください。
バーチャルロボットで確認した結果(期待通りの動作)は以下のイメージです。
人間:こんにちは (100%)
ロボット:こんにちはお名前は ?
人間:田中ともうします (100%)
ロボット:こんにちは田中さん
人間:今日は暑い (100%)
ロボット:今日は暑いですか ?
実機でも期待通りの動作になればいいですが、しかし、現実世界はそううまくいきません。
アトリエ秋葉原のPepper実機で実験した結果(実際の動作)、下記結果になってしまいました。
人間:こんにちは
ロボット:こんにちは お名前は ?
人間:田中ともうします
ロボット:<...>ですか ?
人間:今日は暑い
ロボット:キョウジですか ?
なぜか、Pepper君は「田中」という人の名前を認識できなかったし、「今日は暑い」という言葉もぜんぜん違う言葉として認識してしまいました。
音声認識の精度
Pepperの日本語認識精度を確認したく、下記のQiChat scriptを使って簡単な実験をしました。
topic: ~RepeatJapanese()
language: jpj
u:(_*) $1 ですか?
実験はアトリエ秋葉原のPepper実機を利用して、マイクに向けて日本語の言葉を喋った後、ChoregrahpのダイアログパネルからPepperが実際に認識した言葉とその信頼度を取得しました。結果は下記となります。(正しく認識された言葉をハイライトしています)
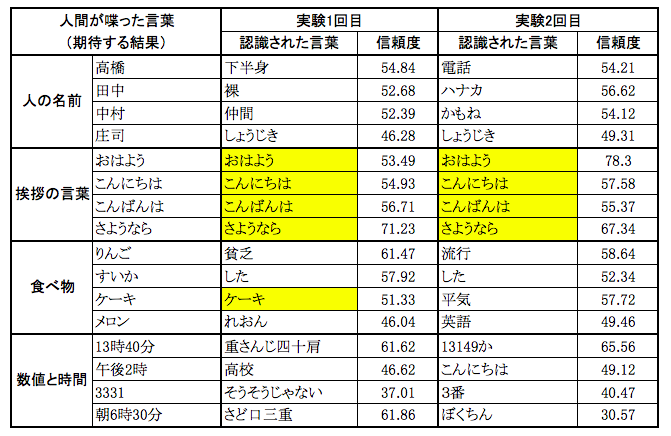
結果を見ますと、Pepperはあいさつの言葉をちゃんと認識できますが、人の名前や数値はとても苦手のようです。それから、ぜんぜん間違う言葉として認識したとしても、信頼度を高くつく場合もありますので、信頼度だけでは音声認識の正確性を判断するのは難しいですね。
ちょっと残念な結果になりました。でも、食べ物の中にPepperはケーキ好きのことが分かりました^_^
Winldcard「*」の性能問題
**Wildcard「*」**のドキュメントに、下記の注意事項が書かれています。
Use wildcards sparingly
Wildcardを慎重に使用する
Too many wildcards can degrade performance of the automatic speech recognition.
大量にWildcardを使うと音声認識性能が低下する可能性もあります。
http://doc.aldebaran.com/2-1/naoqi/audio/dialog/dialog-syntax_full.html#wildcard
おそらく**Wildcard「」**を使った場合、Pepperが覚えたすべての言葉からマッチングする言葉を検索します。そのような検索処理は計算量が多いですので、頻繁に実行すると性能が低下してしまいます。
そのため、u:(_*) $1 ですか?のような使い方はお勧めできなく、本当に必要な時だけ、**Wildcard「」**を入れて実行するのは無難だと思います。
おわりに
Pepperの音声認識は、Wildcard「*」を使って任意の日本語テキストを取得でますが、認識の精度はあんまり期待できません。当面では、任意の言葉をPepperに認識させるよりは、認識したい言葉をSpeech Reco.ボックスのWord list、もしくはQiChat scriptのconceptに登録した方が、はるかに認識の精度が上がると思います。
でも、今後Pepperはニュアンスコミュニケーションズ社のクラウド音声認識エンジンと繋がって、どんどん認識の精度も上がっていくと思いますので、大変楽しみにしています。