研究室のディープラーニング勉強会で各自何かやってみようということになったので,アイマスの元祖御三家をCNNで識別してみました.
結果はこんな感じです

(http://idolmaster.jp/images/event/9th/goods/img_goods37.jpg よりこの画像は拝借しました.問題があれば削除します.)
思い立って10時間くらいでできました.いろんな方が公開してくださっているコードに感謝です.
環境
・MacOS X El Capitan
・python 3.5.2
・OpenCV 3.1.0
・anaconda3-4.2.0
・Chainer 2.0.0
・PIL
など
OpenCVをcondaで入れ,そこにChainerやらなんやらを入れると楽チンです.
データセット
[python3でgoogleの画像をダウンロード] (http://inmyzakki.hatenablog.com/entry/2017/05/08/231308)
こちらの方のコードを拝借して3人の画像をそれぞれ100枚ほど収集しました.
その他用に他の画像も適当に集めました.
「100枚?少な!」
と思われるかもしれませんが,今回はこれだけでうまくいきました.
特徴がわかりやすいからでしょうか.
顔切り出し
OpenCVを使って誰の顔なのかを推定する(Eigenface, Fisherface, LBPH)
こちらのコードをもとに,切り出し,保存しました.
サイズは32x32です.
変更点はOpenCVによるアニメ顔検出ならlbpcascade_animeface.xml
で配布されている,「lbpcascade_animeface.xml」を特徴量検出器に使用したことと,カラー保存をできるようにしたことです.
# !/usr/bin/python
# -*- coding: utf-8 -*-
import cv2, os
import numpy as np
from PIL import Image
# 元画像
train_path = '元画像フォルダのパス'
# アニメ顔特徴分類器
cascadePath = "lbpcascade_animeface.xml"
faceCascade = cv2.CascadeClassifier(cascadePath)
# 指定されたpath内の画像を取得
def get_images_and_labels(path):
# 画像を格納する配列
images = []
# ラベルを格納する配列
labels = []
# ファイル名を格納する配列
files = []
i = 0
for f in os.listdir(path):
# 画像のパス
image_path = os.path.join(path, f)
# 画像を読み込む
image_pil = Image.open(image_path)
# NumPyの配列に格納
image = np.array(image_pil, 'uint8')
# アニメ顔特徴分類器で顔を検知
faces = faceCascade.detectMultiScale(image)
# 検出した顔画像の処理
for (x, y, w, h) in faces:
# 顔を 32x32 サイズにリサイズ
roi = cv2.resize(image[y: y + h, x: x + w], (32, 32), interpolation=cv2.INTER_LINEAR)
# 画像を配列に格納
images.append(roi)
# ファイル名を配列に格納
files.append(f)
save_path = './書き出しフォルダのパス/' + str(i) + '.jpg'
# そのまま保存すると青みがかる(RGBになっていない)
cv2.imwrite(save_path, roi[:, :, ::-1].copy())
print(i)
i+=1
return images
images = get_images_and_labels(train_path)
# 終了処理
cv2.destroyAllWindows()
データの水増しは行わなくても上手くいきました.
学習
python: chainerを使って化物語キャラを認識させるよ! 〜part5 主要キャラで多値分類(未知データに適用編)〜
この記事をもとに,chainer 2.0.0で走るように書き換えました.
ポイントは
train = tuple_dataset.TupleDataset(X_train, y_train)
test = tuple_dataset.TupleDataset(X_test, y_test)
train_iter = chainer.iterators.SerialIterator(train, args.batchsize)
test_iter = chainer.iterators.SerialIterator(test, args.batchsize,
repeat=False, shuffle=False)
# Set up a trainer
updater = training.StandardUpdater(train_iter, optimizer, device=args.gpu)
trainer = training.Trainer(updater, (args.epoch, 'epoch'), out="output")
# Evaluate the model with the test dataset for each epoch
trainer.extend(extensions.Evaluator(test_iter, model, device=args.gpu))
のように,元コードの「学習とテスト」を置き換えて,trainerとupdaterが走るようにしたことです.
あとは
model = L.Classifier(clf_bake())
としたり,層をL.Convolution2Dに直したり,def forwardをdef __call__に置き換えたくらいです.
モデルは可視化するとこんな感じ
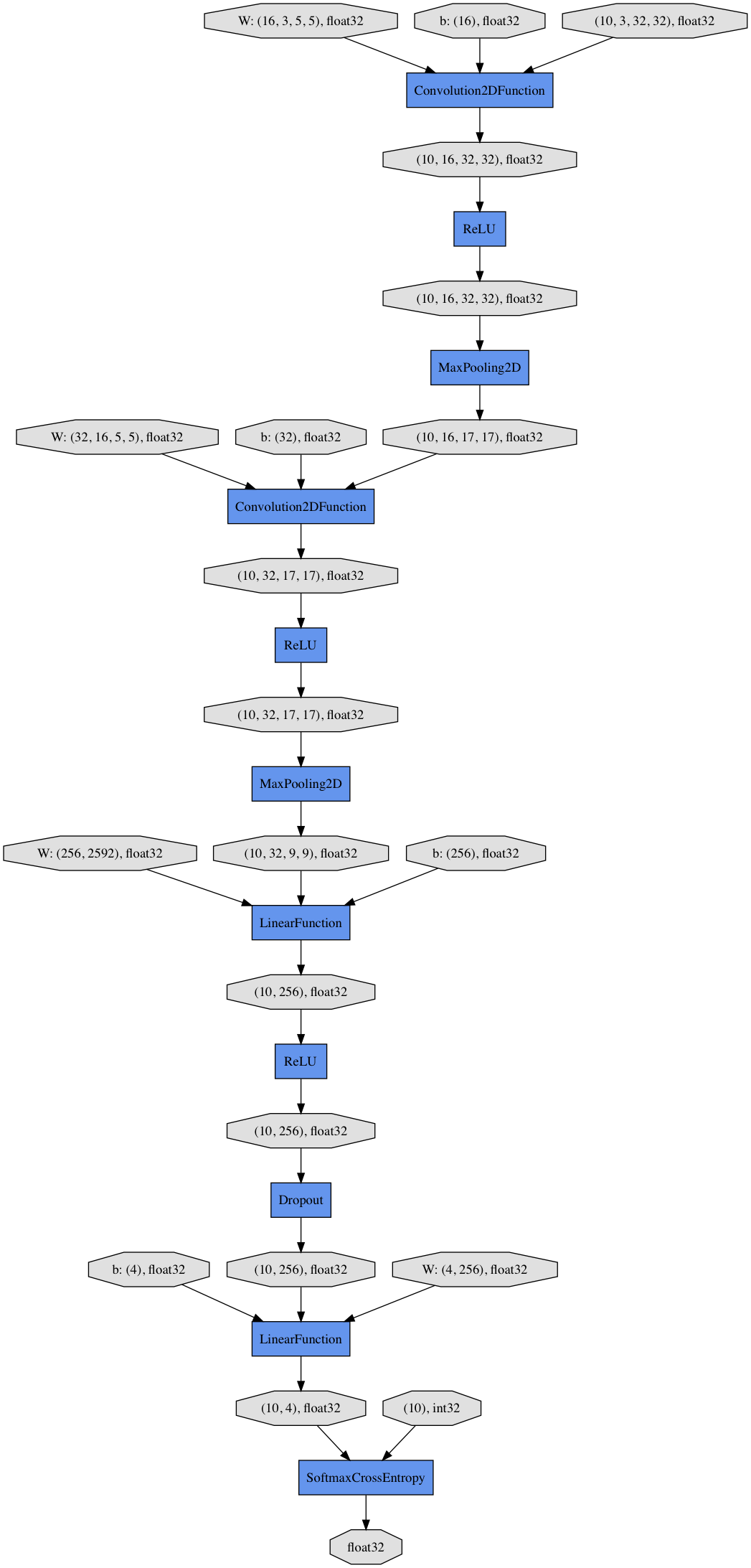
学習結果
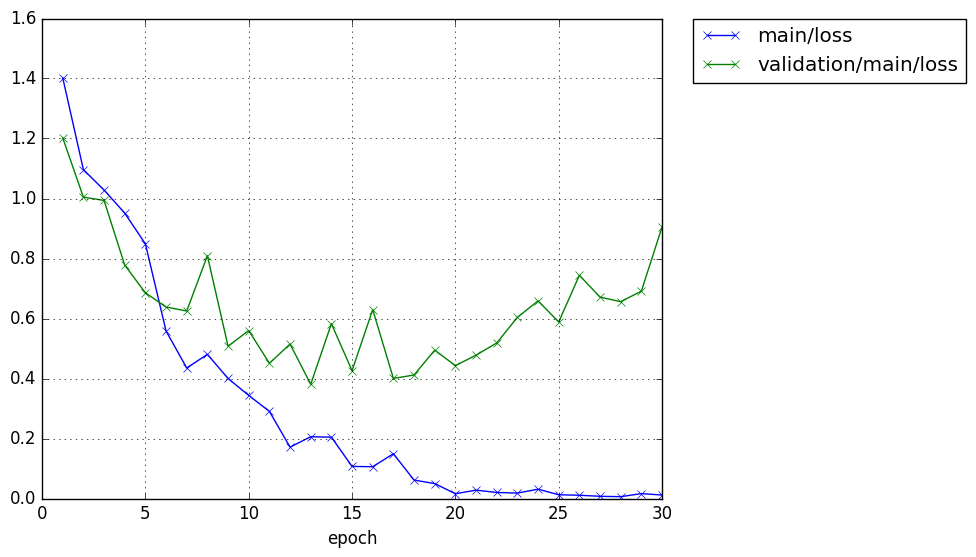
CPUで30epoch回しました.GPU使わなくても4層くらいなら速いです.

loss
accuracy
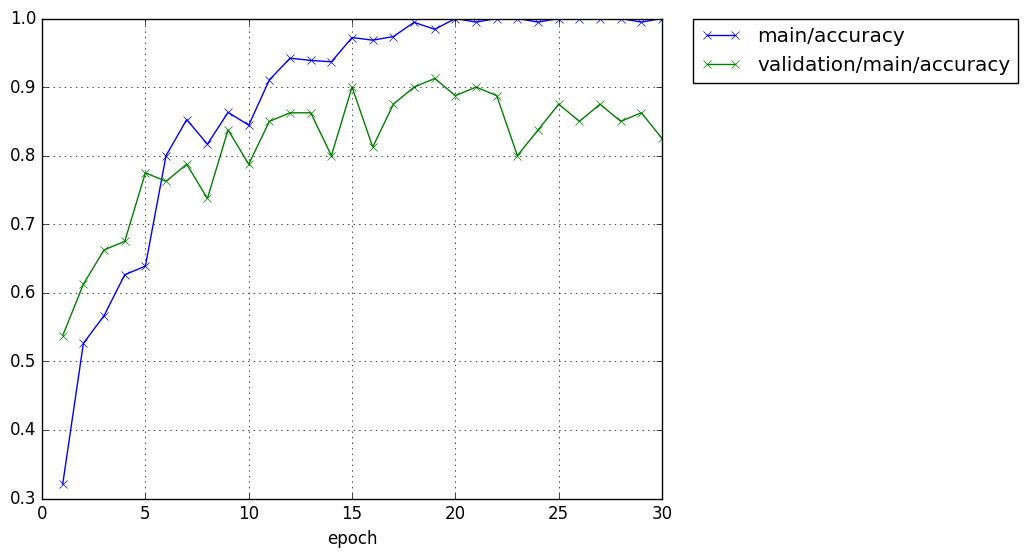
データセットが100枚ほどであるのにも関わらず,val/accuracyが85%はなかなかすごいのではないでしょうか.自分でも初めに回したときはびっくりしました.
CNNすっごーい!
未知データ推定
こちらも大半はpython: chainerを使って化物語キャラを認識させるよ! 〜part5 主要キャラで多値分類(未知データに適用編)〜の記事をもとにしました.
ポイントは,モデルの読み込みを
model = L.Classifier(clf_bake())
chainer.serializers.load_npz("output/model_snapshot_500", model)
のようにしてClassifierを使うことと,
recognition関数の返り値を
def recognition(image, faces):
(中略)
return model.predictor(face_images) , image
とすることです.
感想
すぐに結果が見えるので楽しいですね.
自分でデータセットを用意してやってみると楽しいので是非.
今度はもっと多クラスでやってみようかな.