はじめに
※本記事は前回の記事「PythonでJCGのデッキ分布を自動集計する」の続編になります。
前回の記事で用いた解析手法やコードを再利用している部分があるため、合わせてご覧下さい。
また、本記事では下記の知識を前提としています。
・ Pythonの基礎文法
・ Webスクレイピング
・ Pandasでの表作成
・ matplotlibによるデータの可視化
前半は解析の概要説明に焦点を当てているため、Pythonの知識がなくともある程度のイメージは掴めるかと思います。
後半はPythonでの実際のコーディングが中心となります。
本記事にはプログラミングコードが含まれるため、PCブラウザでの閲覧を推奨します。
目的
JCG決勝トーナメントに進出したデッキを集計し、採用されているカード・枚数の比較分析を行います。
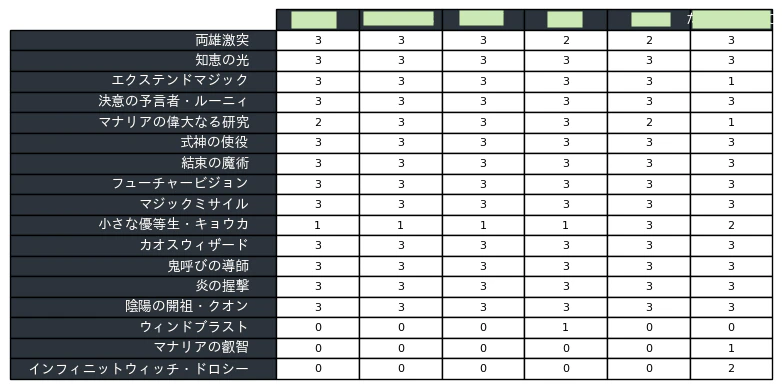
前回の記事ではJCGのデッキ分布分析を行いましたが、本記事ではデッキリストに関する詳細な分析を行うため、下記のような表を自動作成します。
例:JCG Shadowverse 8月28日(金) ローテーション大会 決勝トーナメント
前回の内容:アーキタイプ分布の分析
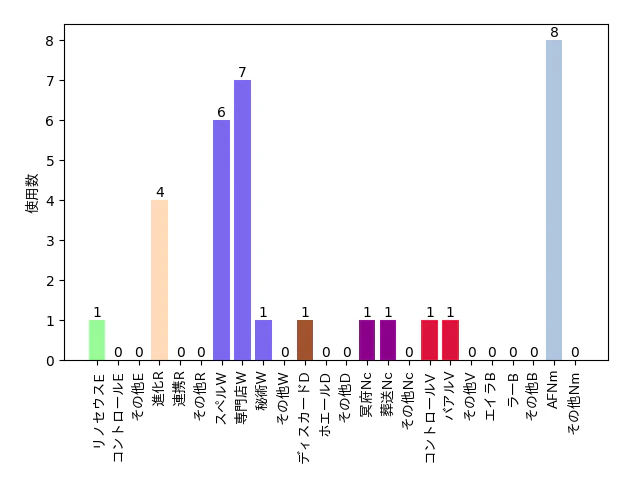
今回の内容:採用カードの比較分析
例:スペルW
アプローチ
下記のステップで解析を進めます。
- JCGのJSONファイルを取得
- アーキタイプ判定
- Shadowverse ポータル(以下ポータル)からデッキリストを取得
- 集計データをグラフ化
ステップ1,2に関しては前回の内容と重複する部分が多いので、より詳細な解説についてはこちらを参照して下さい。
JSONファイルの取得
前回の記事と同様に、JCGのサイトからJSONファイルを取得します。
取得したJSONファイルの例を下記に示します。
{
"result": "success",
"participants": [
{
"id": "42155",
"chk": 1, #チェックイン状況
"nm": "somey", #登録名
"dk": [ #デッキの情報
{
"cl": 3, #クラス1
"hs": "3.3.6so2A.6so2A.6so2A.5-gkQ.5-gkQ.5-gkQ.6_X7Q.6_X7Q.6_X7Q.6_djc.6_djc.6_djc.5-gka.5-gka.5-gka.6turQ.6turQ.6turQ.6xnsw.6xnsw.6xnsw.6_ZZg.6_ZZg.6_ZZg.gPWp2.gPWp2.gPWp2.6q8sC.6q8sC.6q8sC.6twYy.6twYy.6twYy.6xpaI.5-glM.5-glM.5-glM.6t_RI.6t_RI.6t_RI"
}, #デッキ1のカードリスト(正確には、ポータルのURLの一部)
{
"cl": 8, #クラス2
"hs": "3.8.71TeA.71TeA.71TeA.6zemS.6zemS.6zemS.71QTC.71QTC.71QTC.6zd2w.6zd2w.6zd2w.6s2wi.6zcK2.6zcK2.6zcK2.6s65g.6zcKC.6zcKC.6zcKC.6s5My.6s5My.6s5My.6zhCY.6zhxQ.6zhxQ.6zhxQ.6-UTo.6-UTo.71Xo6.71Xo6.71Xo6.6oEnY.6oEnY.6oEnY.6oHDo.6oHDo.6vvW6.6vvW6.6vvW6"
} #デッキ2のカードリスト(正確には、ポータルのURLの一部)
],
"en": 1527921725,
"te": 1, #当落情報
"pr": 1,
"cu": 0
},
この中で、"hs":以下の英数字の羅列(例:"3.3.6so2A.‥中略‥.6t_RI")が40枚のカードリストおよび、ポータルのURLの一部を表しています。
この情報を利用し、アーキタイプ判定およびポータルからデッキ情報の取得を行います。
アーキタイプ判定
JSONファイルから取得した40枚のカードリストを用い、アーキタイプの判定を行います。
判定に用いるロジックは前回の記事と同様に、キーとなるカードが含まれているかで判定を行います。
例:魔道具専門店が3枚含まれる→専門店ウィッチ
ポータルのURLを取得
Webスクレイピングを行い、ポータルからカード名と枚数の情報を収集します。
ポータルのURLは次のような構成になっています。
JSONファイルの"hs"に格納されている値と比較してみると、ポータルのURLのhash=以下を表していることがわかります。
これを利用し、ポータルのURLを生成します。
ポータルからデッキ情報を取得
生成したURLからポータルのHTMLファイルをリクエストし、Beautiful SoupでHTMLの構造解析を行います。
Beautiful Soupとは、HTMLファイルから情報抽出を行うライブラリです。
ポータルのWebスクレイピングに関してはこちらの記事を参考にさせて頂きました。
それでは、ポータルのHTMLファイルを詳しく見てみましょう。
こちらのデッキを例に説明します。
まずはブラウザの機能でHTMLのソースコードを表示します(Chormeの場合は右クリック→ページのソースを表示)
ページをスクロールしていくと、カード名と枚数の情報が見つかります。
<p class="el-card-list-info-name">
<span class="el-card-list-info-name-text">知恵の光</span>
</p>
<p class="el-card-list-info-count">×3</p>
<p class="el-card-list-link">
<a
class="el-icon-search is-small tooltipify"
href="/card/100314010"
target="_blank"
data-card-tribe-name="-"
data-card-atk="0"
data-card-evo-atk="0"
data-card-life="0"
data-card-evo-life="0"
data-card-name="知恵の光"
data-card-skill-disc="カードを1枚引く。"
同様に他のカードも見てみると、カード名にはel-card-list-info-name-text、枚数にはel-card-list-info-countというクラス属性が与えられていることがわかります。
Beautiful soupのselect関数を用いることで、指定したクラス属性やタグの要素をまとめて抽出することができます。
集計データのグラフ化
最後に集計したデータをPandasで表形式にまとめ、matplotlibでグラフ化します。
コーディング
ライブラリのインポート
最初に必要なライブラリをインポートします。
import requests
import bs4
import json
import pandas as pd
import sys
アーキタイプの判定関数
アーキタイプの判定を行う関数を定義します。
引数としてクラス情報(sv_class)と40枚のカードリスト(sv_deck)を渡し、定義した判定ロジックに従ってアーキタイプの振り分けを行います。
戻り値として、判定結果のアーキタイプ名を返します。
# アーキタイプのリスト
arche_dict = {"E":["リノセウスE", "アマツE", "その他E"],"R": ["進化R", "連携R", "その他R"],"W": ["スペルW", "専門店W", "秘術W", "その他W"],"D": ["ディスカードD", "ホエールD", "その他D"],"Nc": ["冥府Nc", "葬送Nc", "その他Nc"],"V": ["コントロールV", "狂乱V", "その他V"],"B": ["エイラB", "コントロールB", "その他B"],"Nm": ["AFNm", "その他Nm"]}
# クラス、デッキタイプ分析
def deck_arche_analysis(sv_deck, sv_class):
if sv_class == 1: #エルフ
if sv_deck.count("6lZu2") == 3:
return arche_dict["E"][0]
elif sv_deck.count("6pQTI") == 3:
return arche_dict["E"][1]
else:
return arche_dict["E"][2]
elif sv_class == 2: #ロイヤル
if sv_deck.count("6td16") > 1:
return arche_dict["R"][0]
elif sv_deck.count("6_B9A") == 3:
return arche_dict["R"][1]
else:
return arche_dict["R"][2]
elif sv_class == 3: #ウィッチ
if sv_deck.count("6_djc") == 3:
return arche_dict["W"][0]
elif sv_deck.count("6q95g") == 3:
return arche_dict["W"][1]
elif sv_deck.count("6t_Rc") == 3:
return arche_dict["W"][2]
else:
return arche_dict["W"][3]
elif sv_class == 4: #ドラゴン
if sv_deck.count("6yB-y") == 3:
return arche_dict["D"][0]
elif sv_deck.count("6_zhY") == 3:
return arche_dict["D"][1]
else:
return arche_dict["D"][2]
elif sv_class == 5: #ネクロマンサー
if sv_deck.count("6n7-I") > 1:
return arche_dict["Nc"][0]
elif sv_deck.count("70OYI") == 3:
return arche_dict["Nc"][1]
else:
return arche_dict["Nc"][2]
elif sv_class == 6: #ヴァンパイア
if sv_deck.count("6rGOA") == 3:
return arche_dict["V"][0]
elif sv_deck.count("6v1MC") ==3:
return arche_dict["V"][1]
else:
return arche_dict["V"][2]
elif sv_class == 7: #ビショップ
if sv_deck.count("6nupS") == 3:
return arche_dict["B"][0]
elif sv_deck.count("6nsN2") == 3:
return arche_dict["B"][1]
else:
return arche_dict["B"][2]
elif sv_class == 8: #ネメシス
if sv_deck.count("6zcK2") == 3:
return arche_dict["Nm"][0]
else:
return arche_dict["Nm"][1]
ポータルからカード名と枚数を取得
ポータルのURLから、採用されているカードの名前と枚数の組み合わせを出力する関数を作成します。
戻り値として、カード名と枚数の全ての組を辞書型変数で返します。
# ポータルからデッキを取得
def get_deck(url):
#htmlファイルをリクエスト
response = requests.get(url)
#エンコーディング
response.encoding = response.apparent_encoding
#htmlの解析
soup = bs4.BeautifulSoup(response.text, "html.parser")
#カード名のリストを取得
names = soup.select(r".el-card-list-info-name-text")
#枚数のリストを取得
counts = soup.select(r".el-card-list-info-count")
#{カード名:枚数}の辞書を作成
deck = {name.text: int(count.text[1:]) for name, count in zip(names, counts)}
return deck
ポータルからデッキリストを取得する関数に関してはこちらの記事を参考にさせて頂きました。
JSONファイルを取得
調べたいJCG大会を指定し、JSONファイルを取得します。
また、調べたいアーキタイプ名としてarche_searchを定義します。
これはアーキタイプの判定関数の結果と比較し、目的のアーキタイプであるかのチェックに用います。
# JCGの大会番号を入力
compe_num = input("調べたいJCGの大会番号を入力して下さい")
# 調べたいアーキタイプを入力
arche_search = input("調べたいアーキタイプを入力して下さい")
# 大会のjsonファイルのURL
jcg_url = "https://sv.j-cg.com/compe/view/entrylist/" + str(compe_num) + "/json"
# jsonファイルをリクエスト
res_jcg = requests.get(jcg_url)
# json形式のテキストとして保存
j_txt = json.loads(res_jcg.text)
# 決勝トーナメントでない場合、プログラムを終了
if not len(j_txt["participants"]) == 32:
sys.exit()
最後の部分では入力した大会番号が決勝トーナメントであるかを判定しています。
グループ予選であった場合はプログラムを中断します。
カード名と枚数の収集
# ユーザー名、カード名、枚数を保存する辞書型変数
arche_summary = {}
# ポータルのヘッダー部分
dbsp_header = "https://shadowverse-portal.com/deck/"
# クラス数の取得
for i in range(len(j_txt["participants"])):
#当落情報の確認
if j_txt["participants"][i]["te"] == 0: #落選
continue
elif j_txt["participants"][i]["te"] == 1: #当選
for j in range(2):
#クラス情報の取得
class_ij = j_txt["participants"][i]["dk"][j]["cl"]
#カード情報の取得
deck_ij = j_txt["participants"][i]["dk"][j]["hs"]
#クラス・カード情報からアーキタイプを判定
archetype = deck_arche_analysis(deck_ij, class_ij)
#判定結果が調べたいアーキタイプと一致した場合
if archetype == arche_search:
#ポータルのURLを生成
dbsp_url = dbsp_header+deck_ij
#ポータルからカード名と枚数の組み合わせを取得
deck_dict = get_deck(dbsp_url)
#arche_summaryに情報を書き込み
arche_summary[j_txt["participants"][i]["nm"]] = deck_dict
else:
continue
else:
continue
グラフ化
最後に集計結果をPandasのDataFrame形式に変換し、matplotlibでグラフ化します。
※下記のコードをそのまま実行する場合はmatplotlibにて日本語フォントの設定が必要です。
そのまま実行する場合は下記の記事を参考にフォントをダウンロードし、このpythonファイルと同じディレクトリに配置してください。
# matplotlibのインポート
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
# 下記の2行は日本語設定用、事前にフォントのダウンロードが必要
from matplotlib.font_manager import FontProperties
fontprop = FontProperties(fname="ipaexg.ttf")
# 集計結果をDataFrame形式に変換
df_arche_summary = pd.DataFrame(arche_summary)
df_arche_summary = df_arche_summary.fillna(0).astype("int")
# 表の詳細設定
fig, ax = plt.subplots()
ax.axis("off")
ax.axis("tight")
tb = ax.table(cellText=df_arche_summary.values,colLabels=df_arche_summary.columns,rowLabels=df_arche_summary.index,colWidths=[0.15]*len(df_arche_summary.columns),loc='center',bbox=[0,0,1,1], cellLoc="center", rowLoc="right")
tb.auto_set_font_size(False)
tb.set_fontsize(8)
for i in range(len(df_arche_summary.columns)):
tb[0,i].set_text_props(font_properties=fontprop, weight='bold', color="w")
tb[0,i].set_facecolor('#2b333b')
for k in range(1,len(df_arche_summary.index)+1):
tb[k,-1].set_text_props(font_properties=fontprop,weight='bold', color="w")
tb[k,-1].set_facecolor('#2b333b')
plt.savefig(arche_search + "_" + compe_num + ".png",bbox_inches="tight")
実行結果
コマンドライン
$ python JCG_decklist.py
調べたいJCGの大会番号を入力して下さい:2389
調べたいアーキタイプを入力して下さい:スペルW
実行結果
おわりに
本記事ではWebスクレイピングでJCG決勝トーナメントのカードリストを取得する方法を紹介しました。
前回の記事のコードと今回のコードは共通する部分が多いので、両方の機能を1つのプログラムに集約することもできます。
余談になりますが、コーディングで一番時間のかかった部分は表のレイアウトです。
列数や行数が都度変わる上、調整パラメータが多く苦労しました。
コードや解析手法に関する修正案、間違いなどありましたら、コメント等で連絡頂ければ幸いです。