始めに
こんにちは。
シャドウバースポータルが結構スクレイピングしやすいサイトだったので記事にしてみました。
何かおかしなところなどありましたら、ご指摘お願いします![]()
スクレイピングとは
WebサイトのHTMLから必要な情報を引っ張ってくることです。今回で言えば、シャドウバースポータルというWebサイトからデッキのカードリストとそれぞれのカードの枚数をスクレイピングするということになります。
具体的な流れとしては、
- Twiiterからシャドウバースのデッキの情報を収集
- HTLMコードの取得
- BeautifulSoup4を用いて、デッキの情報を抜き出す
- データの可視化
となります。
BeautifulSoup4
https://www.crummy.com/software/BeautifulSoup/bs4/doc/
日本語版
HTMLを渡してそれをタグ単位で扱うことができるので、取得したHTMLから必要な情報のみを素早く抜き出すことができます。
https://github.com/sixohsix/twitter
Twitter APIを簡単に扱えるようにするパッケージです。このパッケージを無理に利用する必要はありませんが、今回は私が使い慣れているこのパッケージを使っていこうと思います。
Twitterから情報を収集する際に、Access Tokenなどを取得する必要があります。ここから取得してください。
https://developer.twitter.com/content/developer-twitter/ja.html
実装
Twitterからデッキを公開しているツイートを収集する。
シャドウバースポータルを用いてデッキをTwitterに共有すると、#どばすぽというタグがついたツイートが投稿されます。このことを利用して、Twitterから#どばすぽとついたツイートを収集します。
その後、各ツイートの中からシャドウバースポータルのURLを探します。
リストの要素である各ツイートはjson形式なっています。
詳しくはこちらをご覧ください。
import twitter
import requests
import bs4
import matplotlib.pyplot as plt
# アクセストークンなどの設定。
auth = twitter.OAuth(consumer_key="XXX",
consumer_secret="XXX",
token="XXX",
token_secret="XXX")
t = twitter.Twitter(auth=auth)
# qは検索ワード、countは取得するツイート数、result_typeはどのように検索するか(recentで時系列順で新しいものから)
# t.search.tweets関数はjson形式で返ってきて、その中の['statuses']に各ツイート情報がリスト形式で入っています。
# countは最大100です。それ以上を指定しても100より多くは取得できません。
tweets = t.search.tweets(q='#どばすぽ', count=100, result_type='recent')['statuses']
# 各クラスの各カードが何回使われたかを保持するDictです。
# 最終的に2重のDictになります。
decks = {}
# 各クラスが何回使われたかを保持するDictです
classes = {}
# 各ツイートを見ていく
for tweet in tweets:
urls = tweet['entities']['urls']
for url in urls:
expanded_url = url['expanded_url']
# 'https://shadowverse-portal.com/deck/'から始まっていれば十中八九デッキリストのコードです
if('https://shadowverse-portal.com/deck/' in expanded_url):
print(expanded_url)
try:
# get_deck関数については後述します。
# シャドウバースポータルのURLを引数にして、dict形式のデッキ情報とクラス(ロイヤル、ビショップなど)の2つからなるtupleが返ってきます。
deck, person = get_deck(expanded_url)
except:
continue
# サイトへのアクセスは1秒以上間を空けて行うようにしましょう。
time.sleep(2)
classes.setdefault(person, 0)
classes[person] += 1
decks.setdefault(person, {})
for card in deck:
decks[person].setdefault(card, 0)
# カードの利用回数を数えていますが、カード枚数を数えることもできます。
# その場合は += deck[card] でできるはずです。
decks[person][card] += 1
スクレイピング
get_deck関数内で、スクレイピングを用いて必要なデータを取得します。
まず、必要なデータにどんなタグが使われているのかを探します。
タグの探し方
例として、GameWithさんの機械ウィッチを使わせていただきます。
- ページに飛んだら開発者ツールを開きます。Ctrl-shift-iやF12で開けるかと思います。
- 下の画像のように、開発者ツールの左上のアイコンをクリックしたあと、取得したい情報にマウスカーソルを合わせてクリックします。
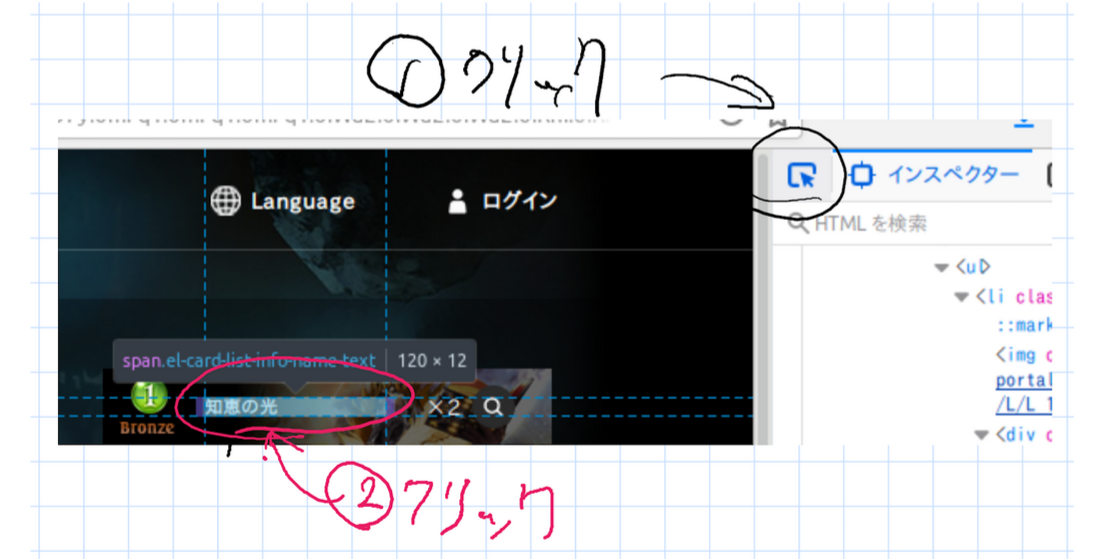
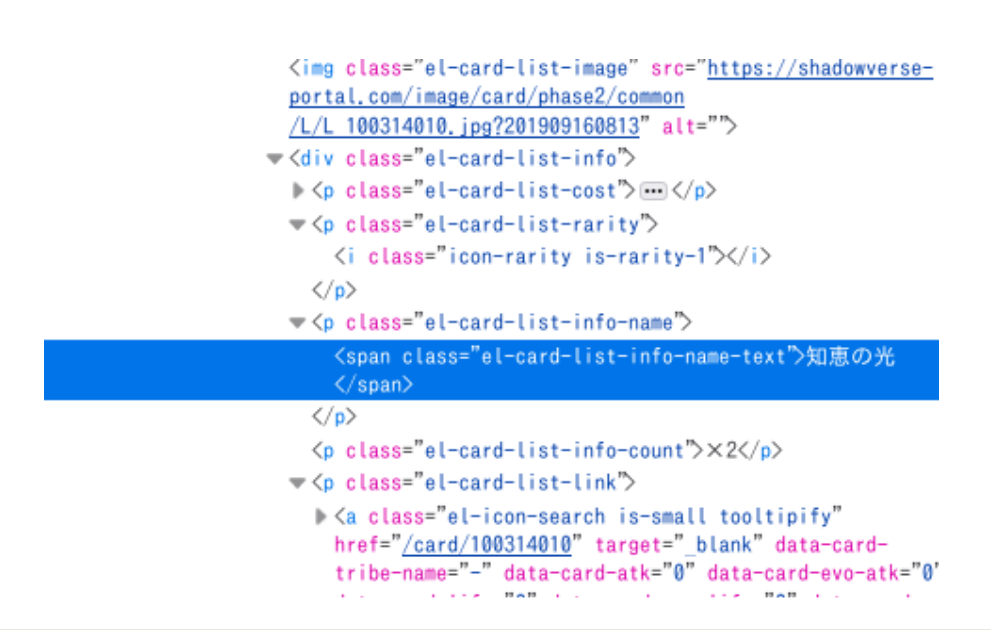
- 取得したい情報の部分を見ます。今回は「el-card-list-info-name-text」というclassの情報を使います。
classの指定方法など、詳しくはこちら
get_deck関数の実装
def get_deck(url):
response = requests.get(url)
response.encoding = response.apparent_encoding
# response.textに、ページのHTMLが入っています。
soup = bs4.BeautifulSoup(response.text, "html.parser")
# soup.select関数が、引数のcssセレクタに一致するタグすべてを取得できます。
# 上述の「タグの探し方」よりel-card-list-info-name-textにカード名があることがわかるので引数にclassを指定します。
names = soup.select('.el-card-list-info-name-text')
# 上述の「タグの探し方」から、el-card-list-info-countにカードの枚数が入っていることがわかります。
counts = soup.select('.el-card-list-info-count')
# 上述の「タグの探し方」から、deck-summary-top-imageのaltにデッキのクラス名が入っていることがわかります。
person = soup.select_one('.deck-summary-top-image')['alt']
# deckの情報を持つdict
deck = {name.text: int(count.text[1:]) for name, count in zip(names, counts)}
return deck, person
取得したデータの可視化
まず各クラスの利用率を棒グラフにして見てみましょう。
plt.bar(classes.keys(), classes.values())
plt.xticks(rotation=-90)
plt.show()
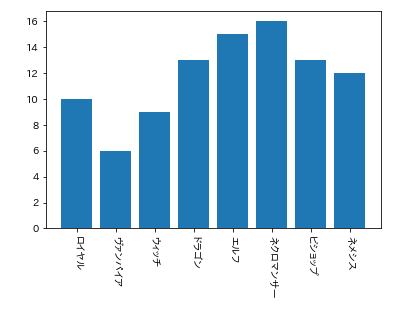
ヴァンパイアが一番利用者が少ないようです。
正確に言うと公開している人が少ないということですが。
次に、各クラスのカードの利用者数を見てます。
for person in decks:
tmp = {k: v for k, v in sorted(decks[person].items(), key=lambda x: -x[1])}
plt.figure(figsize=(10, 5))
plt.title(person)
plt.bar(tmp.keys(), tmp.values())
plt.xticks(rotation=-90)
plt.show()
今回使用者が多かった「ネクロ」と「エルフ」の結果を載せておきます。(9月19日午前1時40分現在)
てかなんて時間にやってんだ…
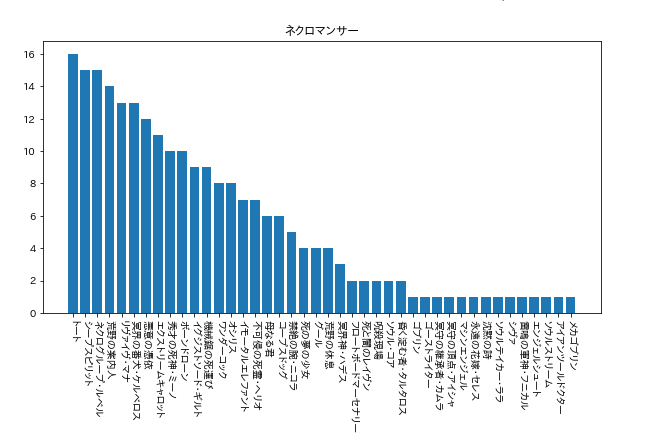
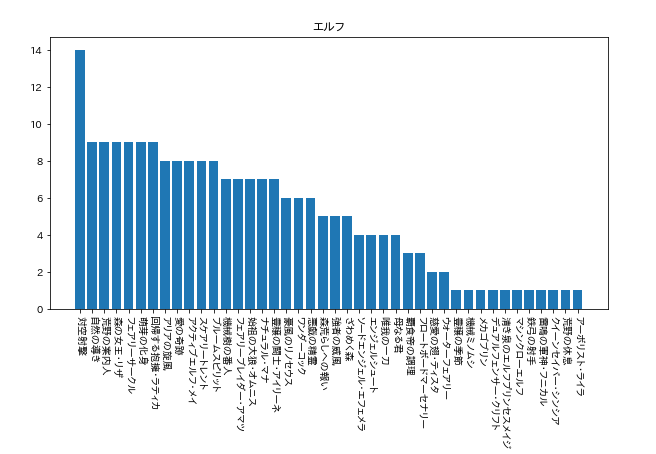
ちなみに、今回のプログラムだとローテーションだけでなく、アンリミテッドや2Pickのデッキも取得してしまいますので、そこは注意してください…。
最後に
今後は、カードの共起度などをみて、どのカードとどのカードが同時に使われることが多いかなどを分析できれば楽しそうたなと考えています。
他にも結構色々できそうですよね。
需要がありそうだったら、続編としてTwitter APIで100件以上のデータの取得する方法や、これらのデータを用いた分析などをやりたいなと考えています。
今回収集したデータの活用するアイデアなどありましたら、ぜひコメントでお願いします![]()