Colabをエディターとしては使用せず、外部GPU環境としてだけ使う方法について書きます。
#Colabのメリット
Cuda(GPU)が使えないMACの場合、Google Colaboratoryはありがたい選択肢の一つでが、デメリットもあります。
#デメリット
- エディター機能がvs codeなどに比べて貧弱。
- Colab Proで、データーファイルやモジュールファイルで構成されたプロジェクトを実行させるとき、pathを通すのがめんどくさい。
- Colabのクセでフォルダーをマウントしてくれないことがある。
- ランタイムを再起動したらせっかくアップロードしたファイルが消えてしまう。
ソリューション
- そこで、ローカルマシンでコーディングを済ませた上で、ファイルをColabに移しGPUによる実行だけColabでさせてみます。
- 長時間の演算が必要なプロジェクトの場合、ファイルをアップロードする手間自体は相対的日本にそれほどでもないので、効果的だと言えます。
手順
- メインのpythonファイル、モジュールのファイル、データーファイルを一つのフォルダーにまとめます。
- Google Driveにアップロードします。
- Colabから、ランタイムをGPUに設定します。
- Google Driveをマウントします。2020.6現在は、Google Driveのマウントアイコンがあるので、それをクリックすればOK。もしくは、下記のコマンドでもマウントできます。
from google.colab import drive
drive.mount('/content/drive')
下記のようにGoogle Driveのフォルダーが左側のペインに表示されます。
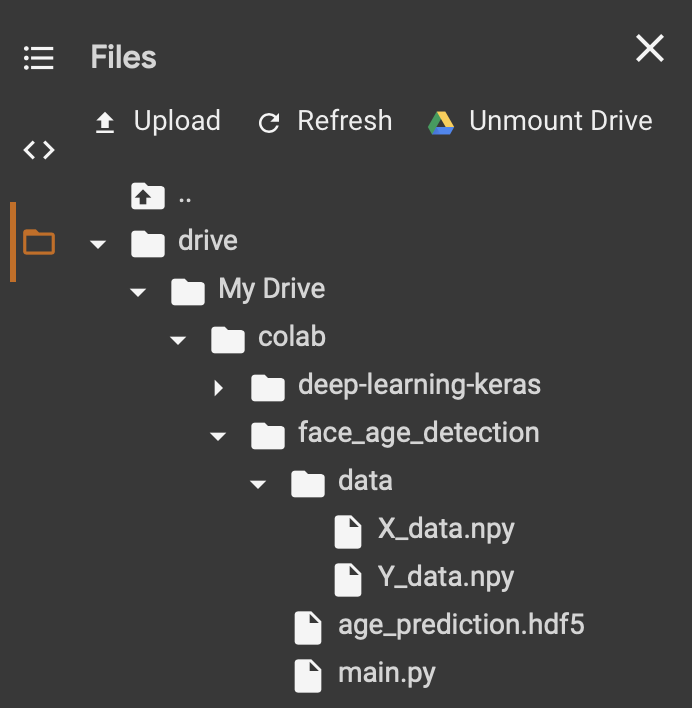
- 今回、google driveのface_age_detectionディレクトリー内にあるmain.pyを実行してみます。
- まずカレントディレクトリーをmain.pyのあるファルダーに移動します。
import os
os.chdir('/content/drive/My Drive/colab/face_detection/')
もしくは、コマンドラインで下記を実行します。(Colabのコマンドラインでcdを使う場合は%をつけ、パスをクオートで囲む必要があるので要注意。)
%cd "content/drive/My drive/colab/face_detection/"
確認すると、きちんと変更されています。
!pwd
/content/drive/My Drive/colab/face_age_detection
Pythonファイルを実行します。
!python main.py
テスト
表情認識をするkerasのプロジェクトで試してみました。(ちなみに、Colab画面で.pyファイルをダブルクリックすると右側にエディター画面が現れるので、直接ソースコードをエディットすることもできます。)
このプロジェクトの場合、100*100の画像が2万枚くらいあり、Convが3層、Denseが2層あり、ちょっと重たい処理になっています。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import os, zipfile, io, re
from PIL import Image
from sklearn.model_selection import train_test_split
import tensorflow.keras
from tensorflow.keras.models import Sequential, Model, load_model
from tensorflow.keras.layers import Conv2D, MaxPooling2D
from tensorflow.keras.layers import Dense, Dropout, Activation, Flatten
from tensorflow.keras.layers import GlobalAveragePooling2D
from tensorflow.keras.callbacks import EarlyStopping, ReduceLROnPlateau
from tensorflow.keras.preprocessing.image import ImageDataGenerator
image_size = 100
X = np.load("data/X_data.npy" )
Y = np.load("data/Y_data.npy")
X_train, X_test, y_train, y_test = train_test_split(
X,
Y,
random_state = 0, #乱数シード。0だと毎回ランダム。整数をシードにすると一定のランダム。
test_size = 0.2
)
X_train = X_train.astype('float32') / 255
X_test = X_test.astype('float32') / 255
X_train, X_val, y_train, y_val = train_test_split(
X_train,
y_train,
random_state = 0, #データーの順番がシャッフルされる。
test_size = 0.2
)
def create_model(X, y):
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same',input_shape=X.shape[1:], activation='relu'))
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3), padding='same', activation='relu'))
model.add(Flatten()) # 1次元ベクトルに変換
model.add(Dense(64, activation='relu'))
model.add(Dense(1))
model.compile(loss='mse',optimizer='Adam',metrics=['mae'])
return model
# 学習過程を可視化するための関数
def plot_history(history):
plt.plot(history.history['loss'],"o-",label="loss",)
plt.plot(history.history['val_loss'],"o-",label="val_loss")
plt.title('model loss')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(loc='upper right')
plt.show()
# Data Augmentation
datagen = ImageDataGenerator(
featurewise_center = False,
samplewise_center = False,
featurewise_std_normalization = False,
samplewise_std_normalization = False,
zca_whitening = False,
rotation_range = 0,
width_shift_range = 0.1,
height_shift_range = 0.1,
horizontal_flip = True,
vertical_flip = False
)
# EarlyStopping
early_stopping = EarlyStopping(
monitor = 'val_loss',
patience = 10,
verbose = 1
)
# reduce learning rate
reduce_lr = ReduceLROnPlateau(
monitor = 'val_loss',
factor = 0.1,
patience = 3,
verbose = 1
)
model = create_model(X_train, y_train)
history = model.fit_generator(
datagen.flow(X_train, y_train, batch_size = 128),
steps_per_epoch = X_train.shape[0] // 128,
epochs = 50,
validation_data = (X_val, y_val),
callbacks = [early_stopping, reduce_lr],
shuffle = True,
verbose = 1)
model.save('age_prediction.hdf5')
plot_history(history)
model = load_model('age_prediction.hdf5')
preds=model.predict(X_test[0:30])
plt.figure(figsize=(16, 6))
for i in range(30):
plt.subplot(3, 10, i+1)
plt.axis("off")
pred = round(preds[i][0],1)
true = y_test[i]
if abs(pred - true) < 3.0:
plt.title(str(true) + '\n' + str(pred))
else:
plt.title(str(true) + '\n' + str(pred), color = "red")
plt.imshow(X_test[i])
plt.show()
実際に実行させてみると、CPU/GPUは約4.2倍のパフォーマンスでした。
ちなみにTPUの場合は、50分。GPUに比べるとそれほど早くないですね。
ローカルマシン(CPU 2.4Ghz 8-Core Core i9) 116分
Colab(GPU) 28分
Colab(TPU) 50分