概要
SELECTの結果を配列として集約する際、ARRAY_AGG関数を使用する方法が挙げられます。ARRAY_AGGについてはPostgreSQLで配列を扱うの記事を参照ください。
ARRAY_AGGで集約した結果について重複がありうる場合、どのように重複排除するのかというのを今回メモ書きします。
前提
- 今回使用したPostgreSQLのバージョンは16.1です。
対応方法
How to remove duplicates, which are generated with array_agg postgres functionのstackoverflowの記事で紹介されている通り、ARRAY_AGGの中でDISTINCTを指定できるようですので、この対応を今回は試してみました。
実装サンプル
<前準備>
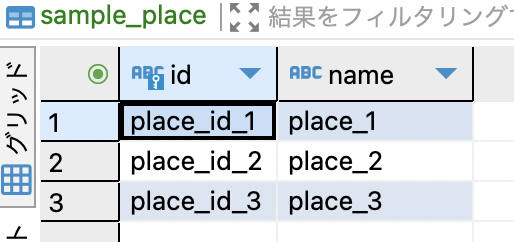
以下の3テーブルを用意します。
CREATE TABLE public.sample_place (
id varchar(100) NOT NULL,
"name" varchar(100) NOT NULL,
CONSTRAINT sample_place_pkey PRIMARY KEY (id)
);
CREATE TABLE public.sample_users (
id varchar(100) NOT NULL,
"name" varchar(100) NOT NULL,
CONSTRAINT sample_users_pkey PRIMARY KEY (id)
);
CREATE TABLE public.sample_visit_log (
user_id varchar(100) NOT NULL,
place_id varchar(100) NOT NULL,
visited_at timestamp NOT NULL
);
以下の通りテストデータを登録します。


<クエリ>
取得する内容としてはsample_visit_logに対して、user毎にplace_idの配列を取得します。
まずはDISTINCTを指定しなかった時の結果です。重複排除されずにSELECTそのままの結果が配列になります。

DISTINCTを指定した時の結果です。重複排除された結果が配列になっています。
