この記事は Voicy Advent Calendar 2020 の 7 日目の記事です。
先日は, @saicologic さんの 忘年会の余興に使えるSlackスタンプ活用術 でした。明日は, @tamo_hory さんの あなたが明日からKotlinを書くなら
です。
はじめに
去年, 一昨年それ以前ぐらいだと k8s を立てるといえば GKE みたいな感じでした。(少なくとも個人的には)
しかし, EKS さん負けてない。今年辺りから料金が下がったり, EKS の採用事例も表に出てきていて盛り上がってますね。
僕も業務の一環で EKS に触れることが多い 1 年でした。実際触れてみると, 潤沢な AWS リソースとの紐付けが容易みたいなところがあって直感的なところも多いのがメリットだな〜と感じます。そんな EKS に対して僕が今年できたことを振り返ります。
まとめ
- マネージド型ノードグループの冗長化
- Service NodePort に対する NLB の IaC
- アプリケーションデプロイパイプラインの GitOps 化
- 既存の eks マニフェストファイルの GitOps 統一
- EKS クラスターの kuberntes バージョン更新
- ALB+envoy+EKS 技術検証
- private Aurora に対して接続するためのプロキシを立てる
細かいところ
マネージド型ノードグループの冗長化
EKS のノードグループについて詳細はこちら。k8s node を AWS の Auto Scaling Group (EC2) などで実現しているものです。
EKS の場合, 仕様として単一のノードグループの中で 3AZ 冗長化対応済みのため, 単純に耐障害性を高めるだけならノードグループ内でインスタンス数を増やせば大丈夫です。
課題になってくるのが, 「ノードグループ単位でインスタンスクラスが決定される。」とか「インスタンスクラスをスケールさせる場合, ダウンタイムが発生する。」と言った辺りで, この辺りを解決するためにはノードグループ自体を冗長化させる必要があります。
IaC する場合, terraform eks_node_group resource 。しない場合は単純にコンソールなり eksctl なりから追加可能です。
参考リンク: マネージド型ノードグループの作成
Service NodePort に対する NLB の IaC
k8s は Service に Type: LoadBalancer を指定できる仕様があって, そこから AWS の場合 NodePort 用の NLB を作成できます。
apiVersion: v1
kind: Service
metadata:
name: ***
namespace: ***
labels:
app: ***
annotations:
service.beta.kubernetes.io/aws-load-balancer-type: "nlb"
spec:
externalTrafficPolicy: Local
ports:
- name: http
port: 80
protocol: TCP
targetPort: 80
selector:
app: ***
type: LoadBalancer
コレ自体はめちゃめちゃ便利で(後々削除予定とかの)一時的な接続先が欲しいとかの場合は十分だと思います。が terraform 管理のインフラとコンフリクトして問題になったことがあって, 「AWSにおけるLBは明確にインフラ」と定義して IaC することにという経緯です。
terraform で IaC するとなったとき, マネージド型ノードグループの場合, Auto Scaling Group として実装されている都合, そちらに対する追加の記述が必要になります。また, IaC する際に terraform 側に nodePort を記す必要がある都合上, マニフェストの方に nodePort を明示する必要があります。
+ nodePort: 32323 # memo: nodePort の指定しない場合, 30000〜32767 からランダムな port で待機するようになる -> tg 作成をコーディングする都合上指定は必須
- resource aws_lb で LB を作る
-
resource aws_lb_target_group で TG を作る
- ここで指定する port を nodePort のポートにする必要がある
- resource aws_autoscaling_attachment で node group の Auto Scaling Group と TG を結びつける
- resource aws_lb_listener で LB→TG 転送設定を作る
- (ついでに) aws_route53_record から LB に対する DNS をつける
この辺りは, nodePort に対する LB を立てようとなるたびにセットで必要になる部分になります(private, public を分けたい。とか色々都合で別の窓口が欲しいとなったとき)。なので, まとめてモジュール管理しておくのが無難なのかなと思います。
アプリケーションデプロイパイプラインの GitOps 化
EKS へのアプリケーションデプロイです。 skaffold を使って build → deploy したり, 単に docker cli, kubectl, などから反映など色々手法としてはありそうです。
k8s のマニフェストは統一して管理されてる方が責務の都合上良いなどの理由から GitOps を採用しました。
GitOps 自体については, 解説してる記事は Qiita 上でもたくさんあったので割愛します。
簡易で説明しておくと
GCP 流にいうと, git 管理されたインフラコードをパブリッククラウドにデプロイすることが自動化されている状態, みたいなものを総じて GitOps と表現してたりします。
が, ここでの GitOps は, Weaveworks が提唱した kuberntes のデプロイマネージメントのことを指してます。
k8sマニフェスト管理用の repository があり, EKS へのアプリケーション反映が常にそのマニフェストと同期されている状態。という感じです。
コレを実現するためのツールは色々あります。
それこと単に CI ツールを使っても実現可能です。
有名所は上述した Weaveworks の Flux とか ArgoCD があります。
日本での採用事例を見てみると, ArgoCD の方が好まれる傾向にあるっぽいです(GUIから操作できたりなど)
今回はとりあえず公式感のある所から GitOps という考えに触れるところからスタートみたいな所があったため Flux を採用してみました。
こんな感じで運用してます。
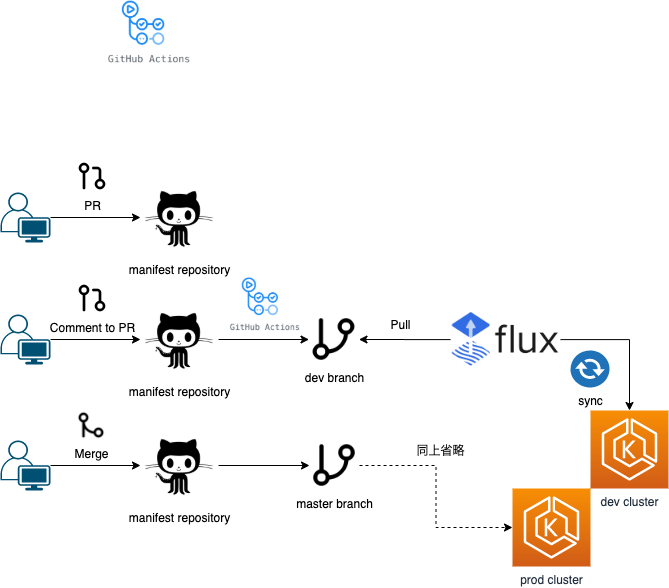
GitHub Actions で, Atlantis terraform のような CD フロー(PR のコメント発火) を実現させるには, issue_comment を使います。
on:
issue_comment:
types: [created]
肝心のコメント内容については, issue_comment 時の context に含まれていて取得できます。
echo ::set-output name=cmd::${{ github.event.comment.body }}
ちなみに, この辺りの context については現状 ${{ toJson(github) }} などで各自ダンプして確認することになってそうです。
dev, stage 環境の反映のみコメントで対応みたいなのは, こんな感じで if 分岐を Actions に記述できます。発火させたい内容が完全に 1 スクリプトで完結する(他 Actions の利用を挟まない)なら, 単にスクリプトの引数として渡すというのも良さそうだなと思ったりしました。
if: ${{ steps.trigger.outputs.cmd == 'dev' || steps.trigger.outputs.cmd == 'stage' }}
PR 上のコメントから発火した Actions の結果を PR に反映させたい。みたいな所は GitHub の特性を利用して, 「 commit に PR 番号を載せる。」と簡単に実現できます。
git commit -m "#${pr_number} Update ${target} from ${pr_label}"
こういう形でコミットを残して置くと, 「dev コメント→ dev 反映内容」 みたいなのをセットで PR 上で確認できます。
コレで現時点の規模ならなんとかなってるんですが,
- もっと細かくデプロイを制御したい(負荷分散とか)
- 反映状況とかは GUI で確認したい
とかとかがやっぱり出てくるので, ArgoCD とか比較したいですね。
既存の eks マニフェストファイルの GitOps 統一
「既に EKS 上に立っている Pod について, 上記 Flux にマージするには?」という点についてです。
コレについては簡単で, 「マニフェストレポジトリ上に対象ファイルを反映してく。」でいけました。
「Flux が repository を監視してタグの自動更新を行う。」辺りは, metadata の annotations から指定できます。
metadata:
...
...
annotations:
# Container Image Automated Updates
flux.weave.works/automated: "true"
この指定をなくせば, とりあえずマニフェスト結合みたいな所は実現できます。
EKS クラスターの kuberntes バージョン更新
k8s を扱う上で避けて通れないのがバージョン更新です。EKS の場合, 4 世代程度のバージョンをサポートしているんですが, k8s は 1 年辺り 4 世代更新となっているため, 最低でも 1 年に一度は起きるイベントとなっているためここに対する考慮は必須です。
アップデート戦略としては大きく分けて二つあると言われてます。
- ライブアップグレード
- ブルーグリーンアップグレード
ライブアップデートは, コンソールとか CLI とか API 経由でポチポチで更新していく方向です。
ブルーグリーンアップデートは, バージョン更新された別クラスタを立ててそちらに乗り換える。という戦略です。
現時点の AWS コンソール API 経由からのインプレースな更新にはダウンタイムが発生します。
なら, ブルーグリーンだとなってるのが一般論です。
ただ, EKS で純粋にブルーグリーンをやると「クラスタ名を後々変更できない。」などの制約から若干都合の悪い部分が出てきます。(特に色々な CI でクラスタ名に依存してたりする箇所とかあったりすると)
というのもあって戦略としては, 「ブルーグリーンで一時的にグリーンにトラフィックを流した状態で, 元のクラスタについてライブアップデートする。」という複合戦略で実施しました。現時点の EKS でのアップデート戦略としては一番安全な戦略かなと自負してます。
この変は, 僕ともう一人と協力で進めていきました。
グリーンクラスタの準備, Route53 の加重ルーティング設定みたいな IaC の担当と上記の GitOps 化辺りです。
この辺の対応を終えたおかげで, 「グリーンクラスタを既存クラスタから置き換える。」みたいなところまでは比較的楽に行うことができました。チームだいじ。
あとは何もなかったか?というともちろんそんなことはなく,
公式リンク: Amazon EKS クラスターの Kubernetes バージョンの更新
こちらにある通り, インプレースな更新を行った場合, 「手動での API 更新」が必要になります。
ここの手順を見逃してて, かつこの時のエラーがめちゃめちゃ分かりづらく( node の準備が終わってない。みたいな)かなり苦労させられた思い出があります。
なんとか一度戦略を立てたので, 「さぁメジャーアップデートどんとこい!」...とは現状思えなく, EKS 自体にも継続的に改善が加わってるので, 「絶対次のアップデートも大変だろうな。。。」という気持ちでいっぱいです。
ここは避けて通れないのでしょうがない。
ALB+envoy+EKS (gRPC) 技術検証
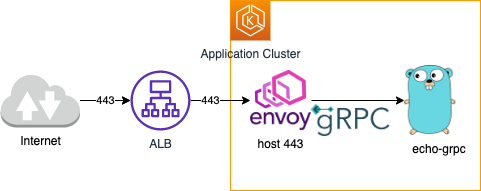
上述の通り基本的には NLB を利用していて, プロキシとしては envoy が使われます。一部 gRPC アプリケーションがあり, その都合 NLB+envoy の技術スタックが利用されていた。という背景です。
そんな中, ALB が gRPC に対応した。というニュースが上がりました。朗報![]()
https://aws.amazon.com/jp/blogs/aws/new-application-load-balancer-support-for-end-to-end-http-2-and-grpc/
こちらの検証にあたって便利だったのが以下の記事です。
こちらは, GKE+envoy+gRPC という技術スタックになります。
https://cloud.google.com/solutions/exposing-grpc-services-on-gke-using-envoy-proxy?hl=ja
k8s の利点として, インターフェースが共通化されているのでプラットフォームが移っても大体同じことができる。があります。ここはかなり強力です。
上記についてもほぼほぼなんの苦労もなく, GKE→EKS への置き換えが可能でした。
一部差分としては, 以下辺りでした。
- ALB は自前で (IaC するなり) 立てた方がいい
- オレオレ証明書に渡す EXTERNAL_IP は ALB DNS でいい
- envoy が 443 待機することになる(サンプルの envoy 構成だと)ので, Target Group としても 443 に飛ばせばいい
このニュースの本質は, HTTP2→ALB→HTTP1 となっていた点が HTTP2→ALB→HTTP2 に対応した。点にあります。他にも ALB の場合, セキュリティグループでの IP 制限も容易みたいなところもあります。ので, gRPC に限らず ALB を採用する。という選択肢もありなんじゃないでしょうか!?
private Aurora に対して接続するためのプロキシを立てる
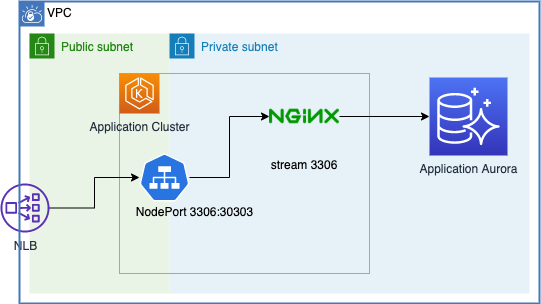
public endpoint を持つ Aurora に対してセキュリティグループで IP 制限よりは, private endpoint しか持たず, 前段で通信制御が行える。という方がセキュリティ的にも良かろう。みたいな背景から EKS 上にプロキシを立てるにはみたいなところを実現するための手法の一つです。
ここには色々と案があって, NLB で直接 Aurora の IP を指定して接続だったり, EC2 インスタンスを踏み台としたり, EKS 上の Service で IP を指定したり ... etc です。
IP 直接指定だと, クラスタのフェイルオーバーへの追従が行えないというデメリットが大きく, 今回は nginx をプロキシとして採用してる感じです。
nginx → mysql な proxy はググると色々出てきます。
https://tech-lab.sios.jp/archives/10761
nginx のもつ stream block の機能でお手軽に実現できて良いです。
実際の config は ConfigMap として, EKS に持って, Deployment でマウントするイメージです。
apiVersion: v1
kind: ConfigMap
metadata:
name: proxy-conf
namespace: entry-point
data:
nginx.conf: |
user nginx;
worker_processes 1;
error_log /dev/stderr warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
stream {
log_format basic '$remote_addr [$time_local] '
'$protocol $status $bytes_sent $bytes_received '
'$session_time';
access_log /dev/stdout basic;
include /etc/nginx/whitelist.conf;
deny all;
upstream db {
include /etc/nginx/upstream.conf;
}
server {
listen 3306;
proxy_pass db;
}
}
環境毎に異なる設定(許可IPリストとか接続先DNSとか)は別ファイルとして設定できるように。
apiVersion: v1
kind: ConfigMap
metadata:
name: proxy-add-conf
namespace: entry-point
data:
upstream.conf: |
server {dns}:3306;
whitelist.conf: |
allow *.*.*.*;
allow *.*.*.*;
...
volumeMount 辺り以外は普通の Deployment と共通です。
apiVersion: apps/v1
kind: Deployment
metadata:
name: proxy
namespace: entry-point
spec:
selector:
matchLabels:
app: proxy
replicas: 1
template:
metadata:
labels:
app: proxy
spec:
containers:
- name: proxy
image: nginx:1.18.0 # 2020.11.20 時点の stable
ports:
- containerPort: 3306
volumeMounts:
- name: config
mountPath: /etc/nginx/nginx.conf
subPath: nginx.conf
readOnly: true
- name: add-config
mountPath: /etc/nginx/upstream.conf
subPath: upstream.conf
readOnly: true
- name: add-config
mountPath: /etc/nginx/whitelist.conf
subPath: whitelist.conf
readOnly: true
volumes:
- name: config
configMap:
name: proxy-conf
- name: add-config
configMap:
name: proxy-add-conf
ちょっと運用を見てみないと掴めない部分もあるんですが, このプロキシ自体は一時的なものになるんじゃないかなと思います。
一時的なリソースもサッと他に影響なく追加できるというのは, k8s のいいところですね!
おわり
振り返ってみると色々とやったな〜と思います。ここに書かれていない部分でも色々と変化(改修)を見たりしました。
他にも, 社内では k8s コードリーディングやったり と一気に k8s に強くなれた一年でした。今後もしばらく k8s と戯れる日々になりそうだなと思います。また, これからやりたいこともたくさんあります。
- 一部リソースを喰いがちな CronJob 処理で Fargate を使ってみたり → コレ のイメージ
- IaC 整理, モジュール化(アップデート, 冗長構成に対して柔軟に)
- イベント通知(Pod 立ったよみたいな)周り
- 都度バージョン更新で出る機能あれば
- サービスメッシュ検討
- GitOps 比較
- ...... etc
変化の多い k8s 周り来年にどうなってるか楽しみです!