こんにちは。みっきーです。
この記事は Voicy Advent Calendar 2020 の 6 日目の記事です。
先日は, @miyukiaizawa さんの 外部ライブラリのMockの実装例Tips でした。
もうすぐ、忘年会の季節ですね。年末となると今年の振り返りをする機会も多いのではないでしょうか?
そこでオススメなのが、Slackの絵文字スタンプを集めて、どれくらい絵文字スタンプが押されているのか収集してランキングすると、忘年会の余興に使えます!今回は、Slack絵文字の集め方を解説したいと思います。
記事の内容について
これは自分が技術書典9のVoicy Tech Story Vol.2の「chapter 9. Slack 絵文字リアクションを活用した組織カルチャー作り」を忘年会用に書き直して、さらに参考実装プログラム(slack-reaction-collector α版)を追記した記事です。このプログラムをForkして、カスタマイズして使うと良いでしょう。
はじめに
Slackのスタンプを収集するために使う道具です。
- Slack SDK: slackapi/python-slack-sdk
- MySQL
今回は、プログラミング言語にPythonとデータベースにMySQLを使います。Pythonを使っている理由はSlackのSDKがよく出来ているからです。MySQLを使っている理由は、SlackAPIで取得したリアクションのJSONデータをそのままJSON型で格納したほうが、集計とランキングが簡単だからです。
動作確認
Python: 3.8.3
MySQL : 8.0.18 Homebrew
(JSON型を利用しているため、MySQL 5.7以上であれば動くと思います。)
ライブラリのインストール
pip install slack_sdk
pip install SQLAlchemy
pip install mysql-connector-python-rf
slack-sdk==3.1.0
mysql-connector-python-rf==2.2.2
SQLAlchemy==1.3.20
SLACK API TOKENの取得
APIへのアクセスにはxoxp-で始まるアクセストークンが必要です。
Build a Slack app in less than 10 minutes!のTable of contentsに取得方法が記載されていますので、手順にしたがって取得してください。
補足:Create a Slack app
初めは、OAuth & PermissionsのOAuth Tokens & Redirect URLsの、Install to Workspaceボタンは押せません。Scopesにある、Add an Oauth Scopeを追加していくことで、Install to Workspaceを押せるようになります。デフォルトで何もAPIを実行できず、Scopeを追加していくことで、操作できるAPIが増えます。
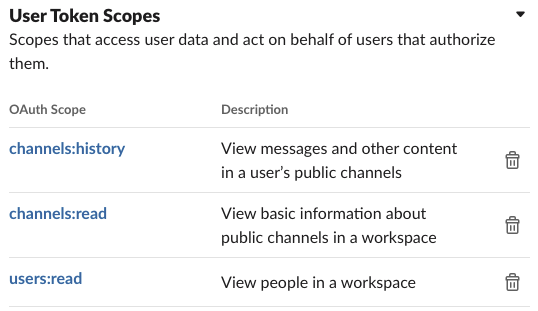
User Token Scopesに、下記の3つを有効にしてください。
今回はBOTを作るわけではないため、Bot Token Scopesは使いません。xoxbで始まるアクセストークンを利用してしまうと、channels:historyで会話を取得するとき、各チャンネルごとにBOTのインストールが必要になります。チャンネルがあるのにエラーでnot_in_channelが出てしまった場合は、使っているアクセストークンの確認が必要です。ハマりました・・
取得したアクセストークンをslack_tokenに記載し、xoxpで始まる、xoxp-xxxxの部分を書き換えてご利用ください。Botのxoxbではありません。
SLACK_TOKEN = xoxp-xxxxxx
クライアント
Slackのクライアントを使います。これ以降は、clientを使っていきます。
簡単に利用する場合は、環境変数でSLACK_TOKENを渡すと良いでしょう。
import os
from slack_sdk import WebClient
client = WebClient(token=os.environ['SLACK_TOKEN'])
チャンネル一覧の取得
主にチャンネルの会話履歴を取得するために使います。
チャンネル一覧は、conversations.list APIで取得できます。SDKからは、conversations_list関数を呼び出すことで利用できます。limitオプションで一度に取得できるチャンネル数を変更できます。何も指定しない場合は100です。チャンネル数は1000以下が多いと思いますので、ページネーションを考慮しない場合は、最大値を指定する取得が楽です。
channels = client.conversations_list(
limit=1000,
exclude_archived=1
)['channels']
参考プログラムはこちらです。
主に使うのは、idとnameです。
for channel in channels:
print(channel['id'],channel['name'])
ユーザ一覧の取得
主に、誰が多くスタンプを押してたかなどに使います。スタンプ統計だけであれば不要です。
ユーザーリストは、users.listで取得できます。SDKからは、users_list関数を呼び出すことで利用できます。exclude_archivedオプションを指定するとアーカイブされたユーザーを除くことができます。
users = client.users_list(exclude_archived=1)
主に使うのは、idとプロフィールにあるrealnameとdisplay_nameです。
プロフィールに入力していない人もいるので、どちらか一方を取得すると良いでしょう。
for user in users['members']:
print(user['id'], user['profile']['real_name'], user['profile']['display_name'])
参考プログラムはこちら
会話履歴の取得
会話の履歴を取得するには、conversations.history APIを利用します。SDKからは、conversations_history関数を呼び出すことで利用できます。必須パラメーターにはchannelを指定します。この値は、conversions.listで取得したchannnelのid属性に記載されているID(例:C1234567890)になります。この属性の正式名称は、Conversation IDなのですが互換性のためなのか変わらず残っています。例では2つの引数を指定します。1つ目の引数はoldestです。これは、指定した日付から最新の会話まで取得します。日付はタイムスタンプ形式(例:1234567890.123456)です。strptime関数で年月日をタイムスタンプに変換すると使いやすいです。2つ目の引数はcountで、取得件数を指定します。
from datetime import datetime
oldest = datetime.strptime("2020-09-01", "%Y-%m-%d").timestamp()
histories = client.conversations_history(
channel="C1234567890",
oldest=oldest,
count=1
)
参考プログラムはこちら
レスポンス結果は下記の通りです。
{'channel_actions_count': 0,
'channel_actions_ts': None,
'has_more': False,
'messages': [{'blocks': [{'block_id': 'ZiwA',
'elements': [{'elements': [{'text': 'これはテストです。',
'type': 'text'}],
'type': 'rich_text_section'}],
'type': 'rich_text'}],
'client_msg_id': 'xxxxx',
'last_read': '1599436735.030600',
'latest_reply': '1599436735.030600',
'reactions': [{'count': 1,
'name': 'makevalue',
'users': ['UQ2UTCBKM']},
{'count': 1,
'name': 'givefirst',
'users': ['UQ2UTCBKM']},
{'count': 1,
'name': 'towardthegoal',
'users': ['UQ2UTCBKM']},
{'count': 1,
'name': 'beprofessional',
'users': ['UQ2UTCBKM']}],
'reply_count': 1,
'reply_users': ['UQ2UTCBKM'],
'reply_users_count': 1,
'subscribed': True,
'team': 'T0APX46NS',
'text': 'これはテストです。',
'thread_ts': '1599436053.030100',
'ts': '1599436053.030100',
'type': 'message',
'user': 'UQ2UTCBKM'}],
'ok': True,
'oldest': '1599404400.000000',
'pin_count': 0}
conversations.history APIは、会話の取得のみで、会話に対する返信は、conversations.replies APIを利用します。
SDKからは、conversations_replies関数を呼び出すことで利用できます。conversations.history APIとの違いでは、引数にtsを指定することで、会話の履歴を取得できます。タイムスタンプはメッセージを一意に識別します。
このタイムスタンプの値は、先程のconversations.history APIのレスポンス結果で取得できるmessagesのtsの値を利用します。
oldest = datetime.strptime("2020-09-07", "%Y-%m-%d").timestamp()
replies = client.conversations_replies(
channel="C1234567890",
oldest=oldest,
count=1,
ts="1599436053.030100",
)
レスポンス結果は下記の通りです。
{'has_more': False,
'messages': [{'blocks': [{'block_id': 'ZiwA',
'elements': [{'elements': [{'text': 'これはテストです。',
'type': 'text'}],
'type': 'rich_text_section'}],
'type': 'rich_text'}],
'client_msg_id': 'xxxxx',
'last_read': '1599436735.030600',
'latest_reply': '1599436735.030600',
'reactions': [{'count': 1,
'name': 'makevalue',
'users': ['UQ2UTCBKM']},
{'count': 1,
'name': 'givefirst',
'users': ['UQ2UTCBKM']},
{'count': 1,
'name': 'towardthegoal',
'users': ['UQ2UTCBKM']},
{'count': 1,
'name': 'beprofessional',
'users': ['UQ2UTCBKM']}],
'reply_count': 1,
'reply_users': ['UQ2UTCBKM'],
'reply_users_count': 1,
'subscribed': True,
'team': 'T0APX46NS',
'text': 'これはテストです。',
'thread_ts': '1599436053.030100',
'ts': '1599436053.030100',
'type': 'message',
'user': 'UQ2UTCBKM'},
{'blocks': [{'block_id': 'zUpes',
'elements': [{'elements': [{'text': 'これは返信のテストです。',
'type': 'text'}],
'type': 'rich_text_section'}],
'type': 'rich_text'}],
'client_msg_id': '66c5e0f7-38b2-4923-a572-9174be856f8f',
'parent_user_id': 'UQ2UTCBKM',
'reactions': [{'count': 1,
'name': 'makevalue',
'users': ['UQ2UTCBKM']},
{'count': 1,
'name': 'givefirst',
'users': ['UQ2UTCBKM']},
{'count': 1,
'name': 'towardthegoal',
'users': ['UQ2UTCBKM']},
{'count': 1,
'name': 'beprofessional',
'users': ['UQ2UTCBKM']}],
'team': 'T0APX46NS',
'text': 'これは返信のテストです。',
'thread_ts': '1599436053.030100',
'ts': '1599436735.030600',
'type': 'message',
'user': 'UQ2UTCBKM'}],
'ok': True}
おそらく、conversations.repliesが一番API呼び出しが多く、RateLimitにひっかります。Rate Limitは、Tier 3で、50回/分です。一番簡単なのは、1リクエストごとに、1~2秒sleepをいれておけば、制限にひかからないので気長に待ちましょう。
絵文字リアクションの取得
APIから取得したリアクションを集計しやすくするために、関連する値をデータベースに保存します。
MySQLのJSON型で保存しておくと、集計が楽になります。
下記がスキーマの例です。
CREATE TABLE reactions (
`id` int(11) NOT NULL AUTO_INCREMENT,
`channel` varchar(255),
`ts` varchar(255),
`user` varchar(255),
`reactions` json DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
conversations.historyのレスポンス結果のreactionsを取得します。
'reactions': [{'count': 1,
'name': 'makevalue',
'users': ['UQ2UTCBKM']},
{'count': 1,
'name': 'givefirst',
'users': ['UQ2UTCBKM']},
{'count': 1,
'name': 'towardthegoal',
'users': ['UQ2UTCBKM']},
{'count': 1,
'name': 'beprofessional',
'users': ['UQ2UTCBKM']}]
JSONの値のまま保存します。
import json
sql = "INSERT INTO reactions(channel, user, ts, reactions) VALUES(%s, %s, %s, %s)"
channel = "C1234567890"
user = "UQ2UTCBKM"
ts = "1599436735.030600"
con.execute(
sql,
channel,
user,
ts,
json.dumps(reactions)
)
参考プログラムはこちらです。
ユーザー別に会話へのリアクションが押された回数を集計する
MySQLに格納したデータは、SQLの集計関数で計算します。特定のスタンプを取得したい場合は、MySQLのJSON_CONTAINS関数を利用することでリアクション対象を絞ることができます。
会話に対してどれだけリアクションが押されたかは、JSONの中のcountに格納されています。すべての会話のcountを合計することで、ユーザー別のリアクションランキングを作成できます。
下記がリアクションランキングのSQLの例です。
SELECT
t2.cnt,
users.display_name
FROM
(
SELECT
t.user,
SUM(count) as cnt
FROM
(
SELECT
user,
JSON_EXTRACT(reactions, '$.count') as count
FROM
reactions
ORDER BY
count DESC
) AS t
GROUP BY user
) AS t2 INNER JOIN users ON (t2.user = users.user_id)
ORDER BY cnt DESC
参考プログラムはこちら
スタンプ別のリアクションランキング
こちらは、
下記がリアクションランキングのSQLの例です。
SELECT
JSON_UNQUOTE(JSON_EXTRACT(reactions, '$.name')) as reaction_name,
SUM(JSON_EXTRACT(reactions, '$.count')) as count
FROM
reactions
GROUP BY
JSON_UNQUOTE(JSON_EXTRACT(reactions, '$.name'))
ORDER BY
count desc
LIMIT
100
参考プログラムはこちらです。
出力例
╒═════════════════╤═════════╕
│ reaction_name │ count │
╞═════════════════╪═════════╡
│ eyes │ 2 │
├─────────────────┼─────────┤
│ blush │ 1 │
├─────────────────┼─────────┤
│ urayama │ 1 │
╘═════════════════╧═════════╛
特定のスタンプがついたメッセージが知りたい
リアクションのランキングが出来上がり1位が誰なのかがわかるようになりました。そうすると次に、実際にどの会話が一番リアクションを獲得できたのか知りたいと思います。Slackでは会話ごとにパーマリンクがあり、chat.getPermalink APIで取得できます。SDKからは、chat_getPermalink関数を呼び出すことで利用できます。必須パラメータは、チャンネルID(channel)と、会話のタイムスタンプ(message_ts)です。
parma_link = client.chat_getPermalink(
channel="C1234567890",
message_ts="1598353527.019300"
)
レスポンス結果は下記の通りです。一部、ダミーの値に書き換えています。
{
'ok': True,
'permalink': 'https://example.slack.com/archives/C1234567890/p1598353527019300?thread_ts=1598002394.002300&cid=C1234567890',
'channel': 'C1234567890'
}
プログラムはまだ書いていません・・・
参考プログラムについて
- Dockerファイルがなかったりちょっと不便
- 1回のAPI最大1000件のメッセージしか取得できません。年間を通すと1000件超えるので、has_moreを駆使して取得できます。
- トランザクションいれてません。いれます。
- APIのRateLimitは考慮していません。いれます。
- Python3の型に対応していません。今時のPythonはこう書く2020を見てアップデートします。
近いうちに更新したいと思います。
最後に
いかがだったでしょうか? 忘年会イベントまであともう少し。1年間どれだけSlackで絵文字スタンプで
コミュニケーションしたのか見てみて、皆さんで祝うと、良い年越しを迎えると思います。
実際に絵文字スタンプを集めてどんな余興になったのかコメント欄にご報告いただけると幸いです。
では、よい落としを〜。