1. はじめに
本記事はResNetに関する論文Identity Mappings in Deep Residual Networksを読んでみたのでそのレビュー記事になります。
内容をざっくり言うと「ResNetの残差ブロックにおいてIdentity Mappingという手法を用いればブロック間の順伝播や逆伝播が直接行えて、CNNを深層化しても性能が頭打ちになる問題を解決できますよ」というもの。
RenNetの勉強中に参照していた記事が本論文を引用している中で気になる部分があったので、改めて自分でレビューしてみた、という内容の記事です。
注目するレビューポイント
改めて本論文をレビューしようと思ったのは、RenNetの勉強中に以下の記事を参照させていただいたのがきっかけです。
本記事ではPost Activation vs Pre Activationという項目が紹介されており、従来では下図左(a)のように畳み込み層の出力に対してBatch Normalizationや活性化関数(ReLU)を適用していたブロックの構造を下図左(b)のようにBatch Normalizationや活性化関数を畳み込み層の前に持ってくる構造にした方が下図右に示すように性能が良くなりますよ、とのこと。
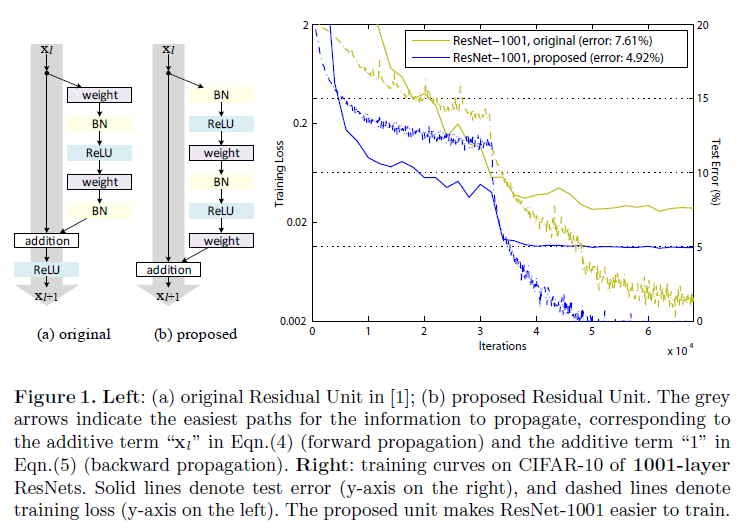
私の浅学故かもしれませんが、なんとなくこれが直感に反していたので、この記事では論文で述べられている内容を自分なりにかみ砕いた上で、独自の実験で確かめてみたいなと思います。
2. 章立て
章立てとしては以下のような構成となっています。
結構シンプルな構成で読みやすかったです。
- Introduction
- Analysis of Deep Residual Networks
- On the Importance of Identity Skip Connections
3.1. Experiments on Skip Connections
3.2. Discussions - On the Usage of Activation Functions
4.1. Experiments on Activation
4.2. Analysis - Results
- Conclusions
3. 章ごとのレビュー
ここで簡単に論文全体の概要を章ごとにレビューしようと思います。
1. Introduction
イントロではResidual Networks、通称ResNetについての簡単な解説がなされています。
一般にResNetの特徴として、入力をそのまま後段に接続するShortcut Connectionを用いた残差ユニットを採用していることが挙げられます。この残差ユニットによって恒等写像の学習がスムーズになり、深層学習の性能向上に寄与しているわけですが、本論文ではより学習性能を向上させるために、ショートカットさせる入力をより直接的に伝播させるような残差ユニットの構成、Identity Mappingsを提案しています。
2. Analysis of Deep Residual Networks
この章ではイントロで述べた深層ResNetの構造について情報伝播の観点から数理的に解析しています。複雑な式ではないのですが、ここで述べるには少々長いので、式を用いた説明の詳細はこちらで別途述べさせてください。
ざっくりと説明すると、Shortcut Connectionと活性化関数をそれぞれ恒等関数とであるとすると、順伝播においては任意の浅層から任意の深層へ直接情報の伝播が可能になり、逆伝播においては任意の深層から任意の浅層へ直接情報の伝播が可能になり、なおかつ勾配消失が起こりにくくなる、ということが述べられています。
式を見ないとなかなかに納得しがたいくらい贅沢な恩恵ですね…。
3. On the Importance of Identity Skip Connections
前章ではShortcut Connectionが恒等関数であるという条件下で解析を行いました。それではShortcut Connectionが恒等関数でなかったらどうでしょうか、というのが本章の内容です。
こちらも数理的な解析を行っているのですが、同様に式の説明はこちらで別途行います。
またまたざっくりと説明すると、Shortcut Connectionをあるスカラー$λ$を用いて$h(x) = λx$とすると任意の深層と任意の浅層との関係式に$λ$の累積積が入ってきます。仮に$λ$が1未満だとすると、先ほど層の間の直接伝播に寄与していた項が$λ$の累積積によって非常に小さくなり、情報の伝播はパラメータを通して伝わっていくことになります。これは先ほどと比較して最適化が困難になることは容易に想像がつきますね。
単純なスカラーの積でも最適化に支障が出てしまう訳ですが、これが畳み込み層などのより複雑な処理になってくるとどうなるのでしょうか、といった実験も本章で行っています。
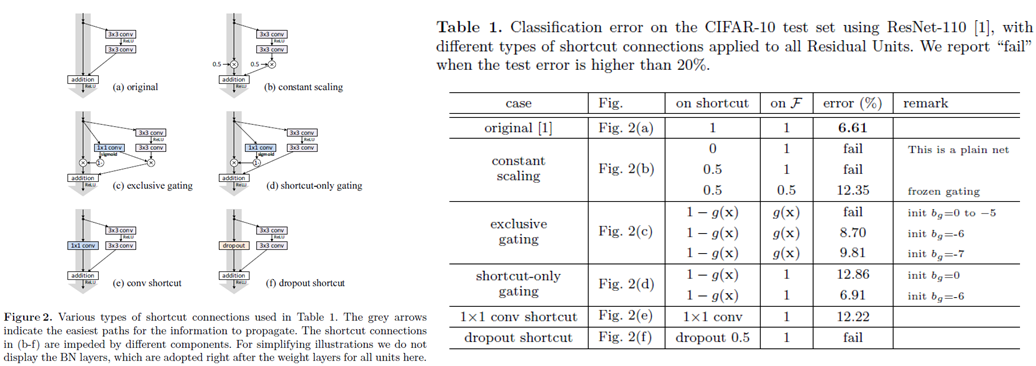
先ほどのスカラー積や畳み込み層、ドロップアウト層などを用いて実験を行っています。
結果としては全ての条件でオリジナルと比較して劣化しているか収束しないという結果が得られていますが、ここで注目すべきは1x1の畳み込み層を用いたケースです。畳み込み層の方がパラメータを用いている分表現力が高いのですが、オリジナルよりもかなり劣化してしまっています。
これは深層化に伴う性能劣化、いわゆる劣化問題の原因が、モデルの表現力ではなく最適化の問題に起因していることを同時に示していると本論文では述べています。
4. On the Usage of Activation Functions
改めて第2章ではShortcut Connectionと活性化関数をそれぞれ恒等関数であるという条件で深層と浅層の関係を導きましたが、オリジナルでは活性化関数にReLU関数が用いられています。本論文では活性化関数の配置を変えることで第2章の解析結果と同様の形にできないかと考えています。本章ではその活性化関数の配置の影響について述べています。
ここは冒頭で注目レビューポイントに挙げた項目ですので少し丁寧に見ていきます。
まずどういうことをしたいかというのを数式から考えてみたいと思います。
オリジナルのモデルでは残差ユニットは層$l$における入力$x_l$、残差関数$F$、$F$のパラメータ$W_l$、活性化関数$f$を用いてこのような定義になっていました。
y_l = x_l + F(x_l, W_l) \quad...(1)\\
x_{l+1} = f(y_l) \quad...(2)
これを$l+1$の時に考えてみると、(2)を用いて(1)はこのように変形できますね。
y_{l+1} = f(y_l) + F(f(y_l), W_{l+1}) \quad...(3)\\
つまり後段に伝播させるにあたってショートカット部分と残差関数の部分の両方に活性化関数$f$が作用していることになります。本論文ではこの活性化関数$f$を残差関数にだけ作用させたいと考えているわけです。
そのような活性化関数$\hat{f}$を用いて(3)を書き換えると(4)のようになります。
x_{l+1} = x_l + F(\hat{f}(x_l), W_{l+1}) \quad...(4)\\
そもそも残差関数にだけ活性化関数を作用させるのでクッションとしておいていた$y$が不要になるんですね。
これは第2章で説明されていたような順伝播や逆伝播を行う際に直接情報の伝播が可能な形となっていて先述したように非常に都合のいい形です。
これをもう少し概念的にとらえるとどうなるかというのを論文中のFigure4にて説明しています。
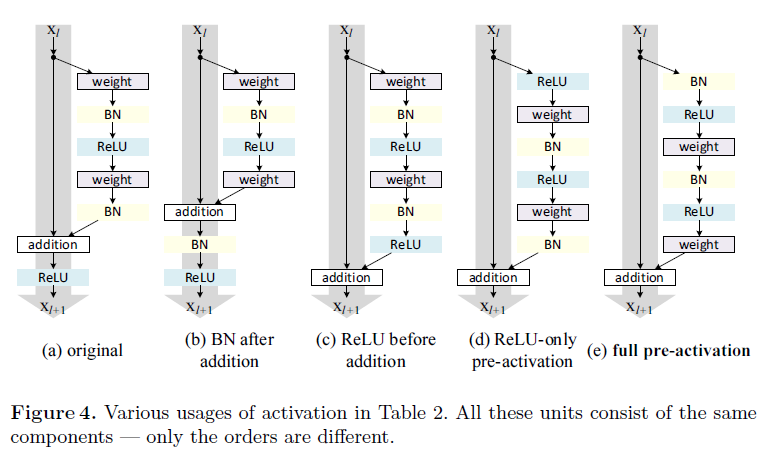
Figure4(a)がオリジナルでまさに式(1)~(3)で示したような形となっています。式(4)でやりたいことというのはFigure4(c),(d),(e)のようにグレーの矢印の部分をまっさらにしてあげる、ということです。
ということでそれぞれの条件でオリジナルとの比較実験を行っており、結果が論文中Table2で示されています。
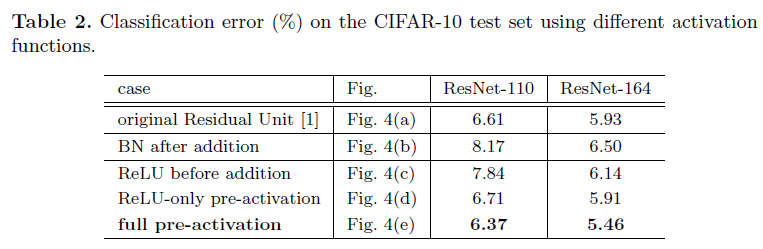
Batch Normalizationと活性化関数を残差関数の前に持ってきたpre-activationがかなり好成績を修めていることがわかります。
その要因について本論文では2点挙げられています。1点はこれまでも度々述べられていた通り、オリジナルと比較して最適化が容易になるという点、もう1点はBatch Normalizationによる正則化の効果が良化し、過学習を抑制するという点です。
後者の正則化の効果が良化し過学習を抑制する、ということについては論文中Figure6にて説明されています。
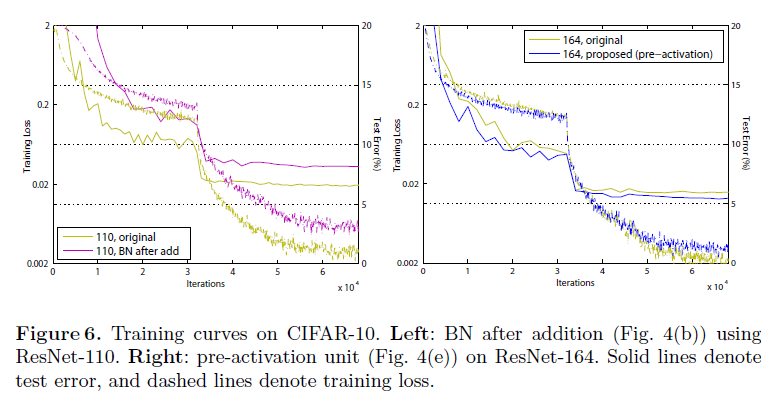
Figure6の左図ではpre-activationを用いたResNet-164による比較がされていますが、オリジナルと比較して学習時の損失は大きくなっていますが、テスト時の損失はオリジナルよりも改善されていて、正則化による過学習の抑制効果が高まっていると述べられています。
これはショートカットと残差関数の出力を加算した際に、オリジナルではショートカットに対してはそのまま後段の入力となっていたものが、pre-activationでは入力後すぐに正則化が行われることで、層の入力全体の正則化が可能になったためであると述べられています。
第5章と第6章はまとめの部分で、これまでの内容の繰り返しになるのでここでは省略します。
4. 実際に確かめてみよう
まず、ここまでレビューを見ていただいてありがとうございます。ここからは実際にPreActivationとPostActivationを実装してみて論文通りの効果がみられるのか検証してみたいと思います。
4-1. 実装環境
以下の通りの環境で今回はTensorFlowでResNetを実装しようと思います。
- OS : Windows11
- Python : 3.10
- TensorFlow : 2.10
- GPU : NVIDIA GeForrce RTX 3060
なお、本実験に使用したスクリプト等はこちらのGithubにアップロードしております。
※ 実装、実行にあたってはjupyter labを用いて行っています。
環境構築にあたっての参考ページ:
4-2. 使用データ/実験設定
今回使用したのはFashion-MNISTです。
採用理由はせっかくなのでMNISTよりは少しレベルを上げたいなといった感じです。
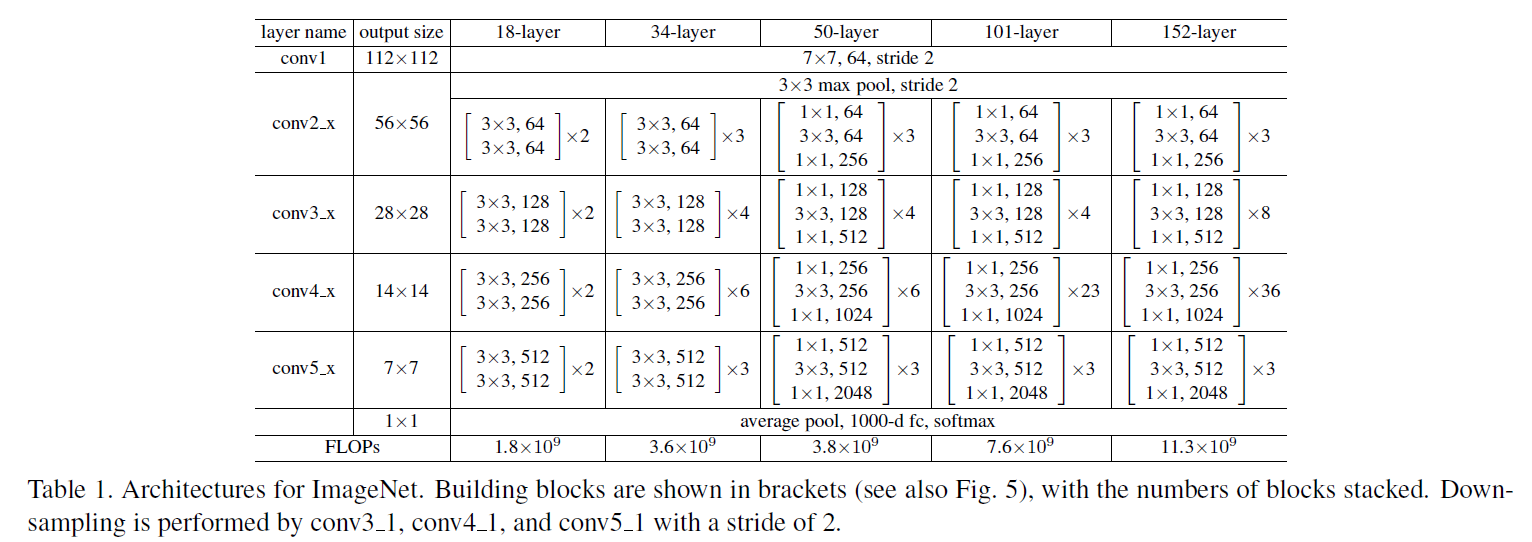
Deep Residual Learning for Image Recognitionで紹介されているResNet50の残差ユニットをPostActivation、PreActivationそれぞれで実装して正解率と損失の推移を見ていきます。
4-3. 実装コード
本コードにあたって以下の記事の内容を参考にさせていただきました。
まずは必要なモジュールのインポートです。ここは特に補足はないです。
# モジュールインポート
import tensorflow as tf
import tensorflow.keras.layers as kl
import os
import numpy as np
import matplotlib.pyplot as plt
# 環境変数の上書き(INFOとWARNINGが出なくなる)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
まずはPreActivationの条件で実装してみます。
残差ユニットから実装していきます。Bottleneckアーキテクチャを採用することで計算コストを抑えています。
# 残差ユニット(PreActivation)の定義
class Res_Block_Pre(tf.keras.Model):
def __init__(self, in_channels, out_channels):
super().__init__()
bneck_channels = out_channels // 4
self.bn1 = kl.BatchNormalization() #BatchNormalization
self.av1 = kl.Activation(tf.nn.relu) #活性化関数の設定(ReLU)
self.conv1 = kl.Conv2D(bneck_channels, kernel_size=1,
strides=1, padding='valid', use_bias=False) #1x1畳み込み層
self.bn2 = kl.BatchNormalization() #BatchNormalization
self.av2 = kl.Activation(tf.nn.relu) #活性化関数の設定(ReLU)
self.conv2 = kl.Conv2D(bneck_channels, kernel_size=3,
strides=1, padding='same', use_bias=False) #3x3畳み込み層
self.bn3 = kl.BatchNormalization() #BatchNormalization
self.av3 = kl.Activation(tf.nn.relu) #活性化関数の設定(ReLU)
self.conv3 = kl.Conv2D(out_channels, kernel_size=1,
strides=1, padding='valid', use_bias=False) #1x1畳み込み層
self.shortcut = self._scblock(in_channels, out_channels) #shortcut connectionの設定
self.add = kl.Add()
# Shortcut Connection
def _scblock(self, in_channels, out_channels):
if in_channels != out_channels:
self.bn_sc1 = kl.BatchNormalization()
self.conv_sc1 = kl.Conv2D(out_channels, kernel_size=1,
strides=1, padding='same', use_bias=False)
return self.conv_sc1
else:
return lambda x: x #恒等写像を返す
# 一連の残差ユニットの実行
def call(self, x):
out_1 = self.conv1(self.av1(self.bn1(x)))
out_2 = self.conv2(self.av2(self.bn2(out_1)))
out_3 = self.conv3(self.av3(self.bn3(out_2)))
shortcut = self.shortcut(x)
out_4 = self.add([out_3, shortcut])
return out_4
続いてResNet50本体の実装です。
こちらもまずはPreActivation方式での実装です。
# ResNet50(PreActivation)クラスの定義
class ResNet_Pre(tf.keras.Model):
def __init__(self, input_shape, output_dim):
super().__init__()
self._layers = [
kl.BatchNormalization(),
kl.Activation(tf.nn.relu),
kl.Conv2D(64, kernel_size=7, strides=2, padding="same",
use_bias=False, input_shape=input_shape),
kl.MaxPool2D(pool_size=3, strides=2, padding="same"),
Res_Block_Pre(64, 256),
[
Res_Block_Pre(256, 256) for _ in range(2)
],
kl.Conv2D(512, kernel_size=1, strides=2),
[
Res_Block_Pre(512, 512) for _ in range(4)
],
kl.Conv2D(1024, kernel_size=1, strides=2, use_bias=False),
[
Res_Block_Pre(1024, 1024) for _ in range(6)
],
kl.Conv2D(2048, kernel_size=1, strides=2, use_bias=False),
[
Res_Block_Pre(2048, 2048) for _ in range(3)
],
kl.GlobalAveragePooling2D(),
kl.Dense(1000, activation="relu"),
kl.Dense(output_dim, activation="softmax")
]
def call(self, x):
for layer in self._layers:
if isinstance(layer, list):
for _layer in layer:
x = _layer(x)
else:
x = layer(x)
return x
続いてPostActivation方式で残差ユニットを実装してみます。
# 残差ユニット(PostActivation)の定義
class Res_Block_Post(tf.keras.Model):
def __init__(self, in_channels, out_channels):
super().__init__()
bneck_channels = out_channels // 4
self.bn1 = kl.BatchNormalization() #BatchNormalization
self.av1 = kl.Activation(tf.nn.relu) #活性化関数の設定(ReLU)
self.conv1 = kl.Conv2D(bneck_channels, kernel_size=1,
strides=1, padding='valid', use_bias=False) #1x1畳み込み層
self.bn2 = kl.BatchNormalization() #BatchNormalization
self.av2 = kl.Activation(tf.nn.relu) #活性化関数の設定(ReLU)
self.conv2 = kl.Conv2D(bneck_channels, kernel_size=3,
strides=1, padding='same', use_bias=False) #3x3畳み込み層
self.bn3 = kl.BatchNormalization() #BatchNormalization
self.av3 = kl.Activation(tf.nn.relu) #活性化関数の設定(ReLU)
self.conv3 = kl.Conv2D(out_channels, kernel_size=1,
strides=1, padding='valid', use_bias=False) #1x1畳み込み層
self.shortcut = self._scblock(in_channels, out_channels) #shortcut connectionの設定
self.add = kl.Add()
# Shortcut Connection
def _scblock(self, in_channels, out_channels):
if in_channels != out_channels:
self.bn_sc1 = kl.BatchNormalization()
self.conv_sc1 = kl.Conv2D(out_channels, kernel_size=1,
strides=1, padding='same', use_bias=False)
return self.conv_sc1
else:
return lambda x: x #恒等写像を返す
# 一連の残差ユニットの実行(PreActivationとの相違点はここ)
def call(self, x):
out_1 = self.av1(self.bn1(self.conv1(x)))
out_2 = self.av2(self.bn2(self.conv2(out_1)))
out_3 = self.bn3(self.conv3(out_2))
shortcut = self.shortcut(x)
out_4 = self.av3(self.add([out_3, shortcut]))
return out_4
同じくPostActivation方式でResNet本体の実装です。
# ResNet50(PostActivation)クラスの定義
class ResNet_Post(tf.keras.Model):
def __init__(self, input_shape, output_dim):
super().__init__()
self._layers = [
kl.Conv2D(64, kernel_size=7, strides=2, padding="same",
use_bias=False, input_shape=input_shape),
kl.BatchNormalization(),
kl.Activation(tf.nn.relu),
kl.MaxPool2D(pool_size=3, strides=2, padding="same"),
Res_Block_Post(64, 256),
[
Res_Block_Post(256, 256) for _ in range(2)
],
kl.Conv2D(512, kernel_size=1, strides=2),
[
Res_Block_Post(512, 512) for _ in range(4)
],
kl.Conv2D(1024, kernel_size=1, strides=2, use_bias=False),
[
Res_Block_Post(1024, 1024) for _ in range(6)
],
kl.Conv2D(2048, kernel_size=1, strides=2, use_bias=False),
[
Res_Block_Post(2048, 2048) for _ in range(3)
],
kl.GlobalAveragePooling2D(),
kl.Dense(1000, activation="relu"),
kl.Dense(output_dim, activation="softmax")
]
def call(self, x):
for layer in self._layers:
if isinstance(layer, list):
for _layer in layer:
x = _layer(x)
else:
x = layer(x)
return x
ここからは共通で学習器クラスの定義です。PreActivation、PostActivationそれぞれのモデルに同じデータを入力して学習させます。
optimizerはSGD-momentunを採用しています。
描画部分の関数もここで定義してしまっています。
# 学習器クラスの定義
class trainer(object):
def __init__(self):
# PreActivation
self.resnet_pre = ResNet_Pre((28, 28, 1), 10)
self.resnet_pre.build(input_shape=(None, 28, 28, 1))
self.resnet_pre.compile(optimizer=tf.keras.optimizers.SGD(momentum=0.9),
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy'])
# PostActivation
self.resnet_post = ResNet_Post((28, 28, 1), 10)
self.resnet_post.build(input_shape=(None, 28, 28, 1))
self.resnet_post.compile(optimizer=tf.keras.optimizers.SGD(momentum=0.9),
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy'])
def train(self, train_img, train_lab, test_img, test_lab, out_dir, batch_size, epochs):
print("\n\n___Start training...")
pre_his = self.resnet_pre.fit(train_img, train_lab,
validation_data=(test_img, test_lab), batch_size=batch_size, epochs=epochs)
post_his = self.resnet_post.fit(train_img, train_lab,
validation_data=(test_img, test_lab), batch_size=batch_size, epochs=epochs)
graph_output(pre_his,post_his,out_dir) #グラフ出力
print("___Training finished\n\n")
print("\n___Saving parameter...")
self.resnet_pre.save_weights(os.path.join(out_dir,"resnet_pre.h5")) #パラメータの保存
self.resnet_post.save_weights(os.path.join(out_dir,"resnet_post.h5")) #パラメータの保存
print("___Successfully completed\n\n")
最後に実行用のメイン部分です。エポック数やミニバッチサイズの設定もここで行っています。
# 学習設定
outdir = os.getcwd()
batch_size = 256
epoch = 10
# 設定情報出力
print("=== Setting information ===")
print("# Output folder: {}".format(outdir))
print("# Minibatch-size: {}".format(batch_size))
print("# Epoch: {}".format(epoch))
print("===========================")
os.makedirs(outdir, exist_ok=True)
# 使用データ読み込み(Fashion-MNIST)
f_mnist = tf.keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = f_mnist.load_data()
# 画像データの前処理
train_imgs = train_images / 255.0
train_imgs = train_imgs[:, :, :, np.newaxis]
test_imgs = test_images / 255.0
test_imgs = test_imgs[:, :, :, np.newaxis]
# 学習の実行
Trainer = trainer()
Trainer.train(train_imgs, train_labels, test_imgs, test_labels, outdir, batch_size, epoch)
4-4. 結果
それぞれのモデルの正解率と損失の推移を以下に示します。
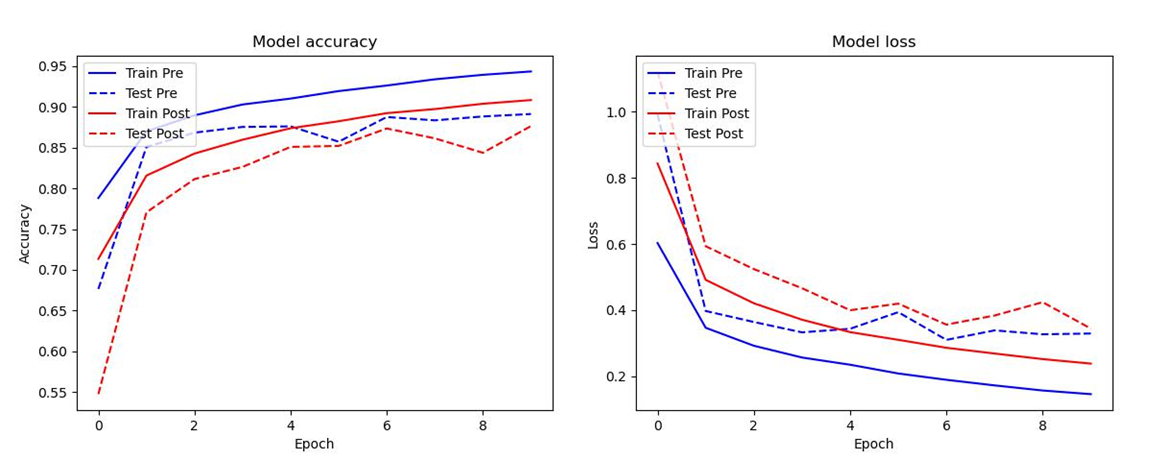
パッと見でPreActivation方式の方が圧倒的に収束が速いのが分かると思います。論文にて述べられていたIdentity Mappingsの効果でモデルの最適化が容易になった結果と言えるのではないでしょうか。私は正直ここまでの違いが出るとは思いませんでした。
今回は10エポックで回してみたのですが、PreActivationの収束の速さ故か、PostActivationは最後まで学習を進めていっているのに対してPreActivationの方は3~4エポックぐらいからオーバーフィットの兆候が見られています。
5. まとめ
今回は勉強の一環としてResNetに関する論文Identity Mappings in Deep Residual Networksを読んでのレビュー記事を書いてみました。
最初はただ他の方の記事を参考にResNetの実装コードを参考に組んでいただけだったのですが、その中で疑問に思ったことを突き詰めた結果、本論文のレビューに至りました。些細なきっかけではあったのですが、複数パターンのモデル実装まで行えたのでResNetの理解が深まった非常にいい機会だったと思います。
自身の備忘録のために書いたものではありますが、この記事がどなたかの助けになれば幸いです。
冗長な記事ではありますが、ここまで読んでいただいてありがとうございました。
6. 参考
- Identity Mappings in Deep Residual Networks:メイン論文
- Deep Residual Learning for Image Recognition:ResNet論文
- Residual Network(ResNet)の理解とチューニングのベストプラクティス:RenNetの勉強中に参照していた記事
- Fashion-MNIST:Fashion-MNIST
- 金子邦彦研究室:TensorFlow2.0の環境構築
- ResNetを実装してみただけ (TF2.0):TensorFlow2.0のResNet実装