あー、不労所得で食っていきてぇ
そう思い競馬予想システムを作りました。
私は身近に競馬が好きな祖父がいて毎週競馬の情報を新聞やテレビで入手している。でも自分は競馬の知識がほとんどない。
そこで「競馬素人でもベテラン並みの予想をできたら面白いのでは?」と思い立ちました。
この記事では、Claude Code を使って競馬予想システムを作った過程と、技術的なポイントを共有します。
🔸 リポジトリ
何を作ったか
JRA 公式サイトからデータを自動収集し、10 要素でスコアリングして予想を出すシステムです。
主な機能:
- JRA 公式サイトからデータを自動収集
- 10 要素でスコアリング(直近成績、コース適性、距離適性など)
- 機械学習でアンサンブル予測
- SQLite でローカル完結
- Claude Code のスキル(
/データ取得、/スコア計算など)で対話的に操作
技術スタック:
- TypeScript 5.9.3
- SQLite (better-sqlite3)
- ml-logistic-regression, ml-random-forest
- Commander.js (CLI)
- Vitest (テスト)
システム全体のフロー
JRA の HTML を取得 → データ抽出 →SQLite に保存 → スコアリングと ML の両方で予測 → 最終予想、という流れです。
分析指標の検証 - 10 要素はどう決めたか
競馬予想で何を重視すべきか、全然わからなかったですw
競馬新聞を見ても「調教 ◎」「上がり最速」「鉄板」みたいな情報が並んでいて、どれが本当に重要なのか全くわからない。
そこで Claude Code に「3 人の専門家」を召喚して議論させてみました。
3 人の専門家による議論
ベテラン調教師(50 代)
「数字だけじゃ馬はわからんよ。ローテーションが大事。中 2 週で使い詰めの馬は本番で力を出せん。あと調教師の腕も見ないと」

データ派馬券買いおじさん(40 代)
「いやいや、直近成績が一番大事でしょ。コース適性のデータ見れば一目瞭然。感覚じゃなくて数字で語ろうよ」

機械学習専門家青年(20 代)
「どちらの意見もわかりますが、数値化できないと特徴量として使えません。あと要素を増やしすぎると過学習のリスクが...」

まあこんな感じで何重も議論させた結果、以下の 10 要素に決定しました:
| # | 要素 | 重み | 誰が推した? |
|---|---|---|---|
| 1 | 直近成績 | 22% | データ派おじさん |
| 2 | コース適性 | 15% | データ派おじさん |
| 3 | 距離適性 | 12% | 調教師 |
| 4 | 上がり 3F 能力 | 10% | ML 専門家 |
| 5 | G1 実績 | 5% | 調教師 |
| 6 | ローテ適性 | 10% | 調教師 |
| 7 | 馬場適性 | 5% | 調教師 |
| 8 | 騎手能力 | 8% | データ派おじさん |
| 9 | 調教師 | 8% | 調教師 |
| 10 | 枠順効果 | 5% | ML 専門家 |
興味深いスコア計算の詳細
会話を聞いていて面白かったポイントをいくつか紹介します。
直近成績は「新しいほど重要」
直近 5 戦の成績を評価するとき、単純平均ではなく新しいレースほど重視しています。
| 順番 | 重み |
|---|---|
| 直近 1 戦目 | 35% |
| 直近 2 戦目 | 25% |
| 直近 3 戦目 | 20% |
| 直近 4 戦目 | 12% |
| 直近 5 戦目 | 8% |
半年前の好走より、先月の好走のほうが価値がある。馬のコンディションは常に変化するからです。
枠順効果は「内枠有利」
中山 2500m(有馬記念のコース)は内枠が有利とされています。過去 20 年のデータで内枠(1〜4 枠)の勝率は外枠の約 1.5 倍。
| 枠番 | スコア |
|---|---|
| 1 枠 | 100 |
| 2 枠 | 95 |
| 3 枠 | 90 |
| 4 枠 | 85 |
| 5 枠 | 70 |
| 6 枠 | 65 |
| 7 枠 | 60 |
| 8 枠 | 55 |
8 枠は 1 枠の約半分のスコア。これだけで勝敗が決まるわけではないですが、5%の重みで補正しています。
お金欲しいがあんましお金かけたくねぇなぁ(強欲)
10 要素が決まったのはいいけど、次の問題はどうやってデータを収集するか。
競馬データを提供しているサービスはあるけど、有料のものが多い。趣味で作るシステムにお金はかけたくない。
私の条件:
- お金がかからない
- 簡単にデータ収集できる
- 手入力は面倒くさい(16 頭 ×5 戦=80 レース分のデータを手で入力とか無理)
- でも精度は欲しい
わがままな条件ですが、結論としてJRA 公式サイトの出馬表 HTML をスクレイピングすることにしました。出馬表には馬の情報、前走 5 戦のデータ、騎手、調教師など必要な情報が全部載っている。これを DOM 解析で構造化データとして抽出します。
なぜHTML を最初に保存しなければいけなかったのか
Claude Code の WebFetch は、大きな HTML を直接解析すると途中でコンテンツを省略してしまいます。JRA の出馬表は情報量が多いので、これでは情報が欠落します。
解決策:2 段階アプローチ
# Step 1: HTML取得してローカルに保存
yarn start fetch-jra "https://www.jra.go.jp/..."
# Step 2: 保存したHTMLをローカルで解析
yarn start extract-html data/jra-page.html
まず HTML をローカルに保存してから、それを解析する。この 2 段階アプローチで精度を確保しました。
データ取得フロー
データ構造化とストレージ
HTML から抽出したデータは、正規表現などを駆使して JSON で自動構造化させました。
馬情報、血統、騎手、前走データを階層的に整理。手動でスキーマを設計する手間が省けて楽でした。
{
"horseName": "ドウデュース",
"jockey": "武豊",
"trainer": "友道康夫",
"previousRaces": [
{ "raceName": "天皇賞(秋)", "position": 1, "time": "1:56.0" },
...
]
}
ストレージはSQLiteを選択。ローカルで完結するシステムにはぴったりです。
SQLite を選んだ理由:
- ローカルで完結(サーバー不要)
- ファイル 1 つで管理可能
- SQL の柔軟なクエリが使える
- 無料
スキーマ概要:
- マスタテーブル(7): venues, sires, mares, trainers, owners, breeders, jockeys
- コアテーブル(4): horses, races, race_entries, race_results
- 分析テーブル(5): bloodline_stats, horse_course_stats など
Claude Code 、お前がNo.1だ
なぜ Claude Code を選んだか?ChatGPT でも Gemini でもなく Claude Code。
1. 仕事で使っている
普段の仕事で Claude Code を使っているので、操作に慣れています。単純に新しいツールを覚える必要がなかった(怠惰)
2. 従量課金制の API にしなくても良い
これが一番大きい。Claude のサブスクリプション(Max)内で使えるので、API 利用料を気にせず試行錯誤できます。
競馬予想システムなんて「やっぱりこの要素追加しよう」「重みを変えてみよう」と何回も作り直すことになる。従量課金だと気軽に試せないけど、Claude Code なら遠慮なく回せる。
3. スキル機能が便利
ここが1番便利なところでClaude Code のスキル機能で、対話的にシステムを操作できるってところが良いんです
指定されたレースのスコア計算を実行します。
yarn start score --race <id>
/データ取得、/スコア計算、/レース一覧などのコマンドを定義して、自然言語で操作できます。
2025 年有馬記念での失敗談
結論。6000 円スりました。
有馬記念の予想は、このリポジトリのファーストコミットの内容で行いました。基本的なスコアリングと機械学習モデルだけのシンプルな状態です。
結果として、本命馬の予想はそこそこ当たっていたんです。予想上位の馬は 3 位以内に入ることが多かった。
でも問題は穴馬の予想精度が低いこと。
馬券買ってて気付いたことなんですが馬券で稼ぐにはどの人気が無い馬が勝つかを当てないといけないんすよね…
本命ばかり当てても、オッズが低いから儲からない。穴馬を拾えないと回収率が上がらないんや…
この失敗がきっかけで、以下の改善を追加しました:
- 人気差補正の双方向化: 人気馬だけでなく人気薄への補正も追加
- 重みづけ最適化の自動実行: 過去データを使って重みを自動調整
- バックテストの追加: 過去レースで精度を検証できるように
今はこれらの改善で精度がどう変わるか検証中です。次の G1 で試してみたい。
リポジトリ紹介
ソースコードは公開しています。興味があれば触ってみてください。
GitHub: https://github.com/sogengineer/arima-analy
クイックスタート
# 依存パッケージのインストール
yarn install
# ビルド
yarn build
# JRAからデータを取得して抽出
yarn fetch-and-extract https://www.jra.go.jp/JRADB/accessD.html?CNAME=pw01sde1012024122206
# データベースにインポート
yarn start import-url data/horse-extracted-data.json
# スコアリング分析
yarn start score
# 機械学習予測
yarn start ml
Claude Code スキル(カスタムコマンド)
Claude Code にはスキル機能があり、よく使う操作をコマンド化できます。
.claude/commands/ ディレクトリに Markdown ファイルを置くと、/コマンド名 で呼び出せるようになります。
定義済みスキル
| スキル | 説明 |
|---|---|
/データ取得 |
JRA 出馬表 URL からデータを取得・抽出 |
/レース一覧 |
登録済みレースを一覧表示し、予想を実行 |
/スコア計算 |
指定レースのスコアリングを実行 |
/馬一覧 |
登録済み馬の一覧を表示 |
実際の使用例
Claude Code のチャットで /レース一覧 と入力するだけ:
ユーザー: /レース一覧
Claude: 登録済みのレースを表示します。
| ID | レース名 | 開催日 | 会場 |
|----|----------|--------|------|
| 1 | 有馬記念 | 2025-12-28 | 中山 |
| 2 | 天皇賞(秋) | 2025-11-02 | 東京 |
予想を実行するレースを選んでください。
スキルの定義方法
.claude/commands/レース一覧.md の中身はこんな感じ:
登録済みレースを一覧表示し、ユーザーが選択したレースの予想を実行します。
1. `yarn start races` でレース一覧を取得
2. ユーザーにレースを選択させる
3. 選択されたレースで `/スコア計算` を実行
プロンプトを書いておくだけで、Claude が手順通りに実行してくれます。CLI コマンドを覚えなくても自然言語で操作できるのが便利。
予想出力例
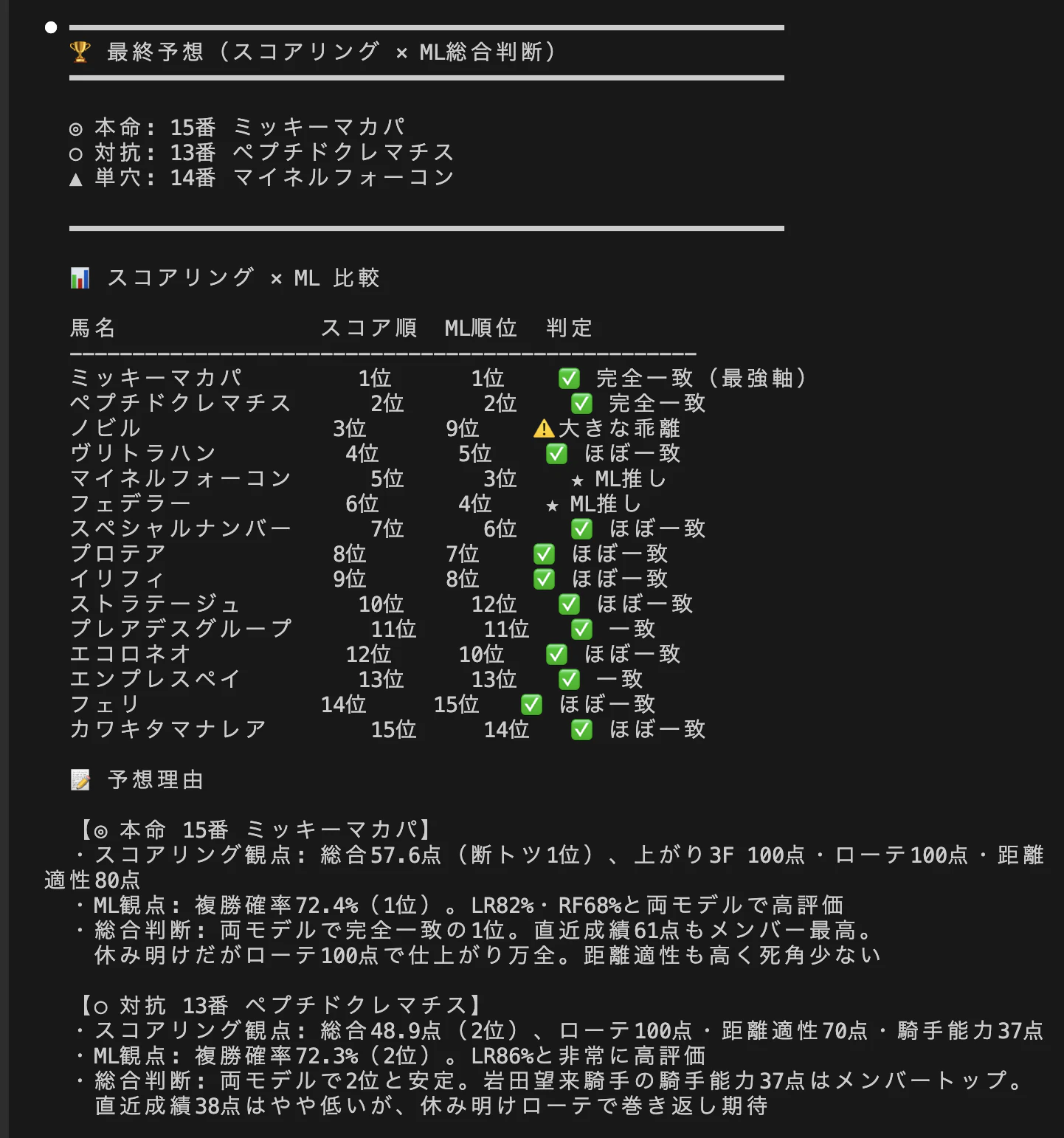

詳細な使い方はリポジトリの README を参照してください。
機械学習のアプローチ
正直、私も機械学習は詳しくないです。Claude Code に教えてもらいながら実装しました。わからないなりに説明してみます。
ざっくり言うと何をしているか
「過去のレース結果から、どの馬が勝ちやすいかのパターンを学習する」 ということをやっています。
料理で例えると:
- 過去のレシピ(データ) を大量に読み込んで
- 「この材料の組み合わせだと美味しくなる」 というパターンを見つけて
- 新しい料理(レース) でも美味しくなりそうな組み合わせを予測する
2 つの手法を組み合わせている
ロジスティック回帰(30%)
- シンプルな手法
- 「直近成績が良いほど勝ちやすい」みたいな単純な傾向を見つけるのが得意
- 人間にも理解しやすい
ランダムフォレスト(70%)
- 複雑な手法
- 「中山の 2500m で、前走から中 3 週で、騎手が ○○ だと勝ちやすい」みたいな複雑な条件の組み合わせを見つけるのが得意
- なぜその予測になったかは人間にはわかりにくい
この 2 つを組み合わせて(アンサンブルと呼ぶらしい)、お互いの弱点を補い合っています。
バックテストで精度を確認
過去のレースで「このシステムを使っていたら当たっていたか?」を検証しています。
━━━━ バックテスト結果サマリ ━━━━
検証レース数: 15
Top1的中率: 26.7%(4/15)
Top3的中率: 66.7%
Top5的中率: 86.7%
順位相関: 0.42
回収率シミュレーション
単勝: 78% | 複勝: 92% | 3連複: 145%
Top3 的中率 66.7% は悪くない数字。3 回に 2 回は、予想上位 3 頭に勝ち馬が入っている。
ただし単勝回収率 78%...。つまり 100 円賭けると 78 円になって返ってくる。やっぱり競馬は難しい。
おわりに
賭けには負けましたが祖父に開発途中のシステムを見せたら面白がってくれました。
「へぇ、こんなことできるんか」
「この馬が 1 位なんか、ほう」
祖父がニヤニヤしながら画面を覗き込んでいたのが印象的でした。次の大きな G1 レースでは、一緒に予想を突き合わせて楽しみたいと思っています。
今後の展望:
- 祖父と一緒に予想を楽しむ
- リアルタイム予測の強化
- 他の G1 レースへの展開
- ゆくゆくは不労所得生成スキーマの獲得
本システムは教育・研究目的で作成しています。実際の馬券購入は自己責任でお願いします。予測結果の正確性は保証されません。
最後まで読んでいただきありがとうございました。