「AIエージェント」という言葉を最近よく耳にするようになりました。ChatGPTのような単純な質問応答ではなく、自律的にタスクを計画・実行し、ツールを使いこなし、複数のステップにわたって問題を解決できる——それがAIエージェントです。
本記事では、AIエージェントをゼロから構築するための8つのステップを体系的に解説します。
AIエージェントとは?
AIエージェントとは、LLM(大規模言語モデル)を中核として、外部ツールや記憶システムと連携しながら、自律的にタスクを実行するシステムです。
通常のLLMとの違いは以下の通りです。
| 通常のLLM | AIエージェント | |
|---|---|---|
| 実行 | 1回の推論で完結 | 複数ステップを自律的に実行 |
| ツール | なし | Web検索・コード実行・API呼び出しなど |
| 記憶 | なし(文脈のみ) | 長期・短期メモリを保持 |
| 判断 | ユーザー主導 | エージェント自身が次のアクションを決定 |
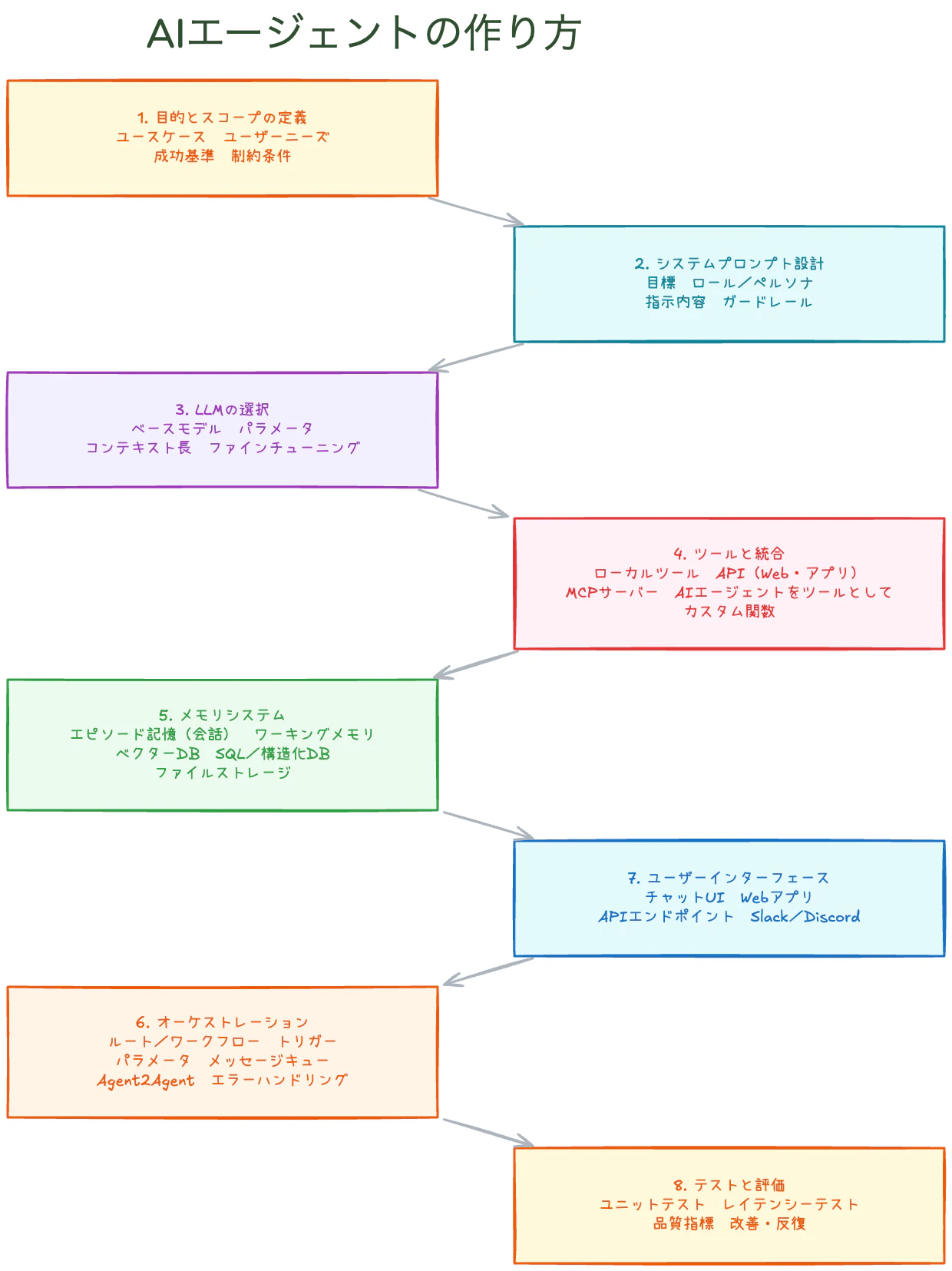
ステップ1:目的とスコープの定義
構築を始める前に、何のためのエージェントかを明確にします。
- ユースケース:何の問題を解決するか
- ユーザーニーズ:誰が使うのか、何を期待しているか
- 成功基準:目標達成をどう測るか
- 制約条件:予算・法規制・技術的限界
ここが曖昧なまま進むと、後工程のすべてがブレます。最も重要なステップです。
ポイント:「汎用エージェント」を作ろうとしない。最初は1つのユースケースに絞ること。
ステップ2:システムプロンプト設計
システムプロンプトはエージェントの行動規範です。以下の4要素を設計します。
- 目標:エージェントのコアタスク
- ロール/ペルソナ:どのような立場で対話するか
- 指示内容:具体的な行動規範と応答スタイル
- ガードレール:有害な出力や逸脱行動を防ぐ制限
設計例
あなたは○○株式会社のカスタマーサポートエージェントです。
ユーザーの問い合わせに対して、親切かつ簡潔に回答してください。
以下のルールを必ず守ること:
- 製品に関係のない話題には答えない
- 個人情報を収集しない
- 回答は3文以内にまとめる
ステップ3:LLMの選択
タスク要件に合ったモデルを選びます。
| 比較項目 | 内容 |
|---|---|
| ベースモデル | 推論・コード生成・多言語など能力の特性 |
| パラメータ規模 | 性能とコストのトレードオフ |
| コンテキスト長 | 長い会話・ドキュメントを扱えるか |
| ファインチューニング | 特定ドメインへの特化が必要か |
主要モデルの例:Claude(Anthropic)、GPT-4o(OpenAI)、Gemini(Google)、Llama(Meta)など。
ステップ4:ツールと統合
エージェントに「手足」を与えます。ツールがなければエージェントはただの会話AIです。
tools = [
{
"name": "web_search",
"description": "インターネットで最新情報を検索する",
"parameters": {"query": "検索クエリ"}
},
{
"name": "run_code",
"description": "Pythonコードを実行して結果を返す",
"parameters": {"code": "実行するコード"}
}
]
統合できるツールの種類
- ローカルツール:ファイル読み書き、計算処理
- API:Web検索、データベース、SaaSアプリ
- MCPサーバー:Model Context Protocolによる標準化されたツール接続
- 他のAIエージェント:マルチエージェント構成でサブタスクを委譲
- カスタム関数:独自ビジネスロジックの実装
ステップ5:メモリシステム
エージェントが文脈を保持し、一貫した対話を実現するためにメモリが必要です。
┌─────────────────────────────────────┐
│ メモリの種類 │
├──────────────┬──────────────────────┤
│ エピソード記憶 │ 会話履歴の保持 │
│ ワーキングメモリ│ 現在タスクの短期文脈 │
│ ベクターDB │ 長期知識のセマンティック検索 │
│ 構造化DB │ SQL等で構造化情報を保存 │
│ ファイルストレージ│ ドキュメント・状態の永続化│
└──────────────┴──────────────────────┘
RAGとの組み合わせ
ベクターDBを活用したRAG(Retrieval-Augmented Generation)により、LLMの知識を大幅に拡張できます。
ステップ6:オーケストレーション
エージェントが「どう考え、どう動くか」を制御する仕組みです。
代表的なパターン
ReAct(Reasoning + Acting)
思考 → ツール呼び出し → 観察 → 思考 → ... → 最終回答
Plan-and-Execute
計画立案 → サブタスクに分解 → 各タスクを実行 → 結果を統合
構成要素
- ルート/ワークフロー:入力に応じた実行経路の決定
- トリガー:イベント駆動の自動起動
- メッセージキュー:非同期タスク処理
- Agent2Agent通信:複数エージェントの協調
- エラーハンドリング:例外の捕捉と復旧
ステップ7:ユーザーインターフェース
エージェントとユーザーをつなぐ接点を選びます。
| UI種別 | 特徴 | 向いているケース |
|---|---|---|
| チャットUI | 直感的な対話形式 | 一般ユーザー向け |
| Webアプリ | 豊富な機能・カスタマイズ可能 | 業務システム組み込み |
| APIエンドポイント | 他システムから呼び出す | 開発者・B2B連携 |
| Slack/Discord | 既存ワークフローに統合 | チーム内自動化 |
ステップ8:テストと評価
リリース前の品質保証と、リリース後の継続的改善が重要です。
評価すべき指標
- 正確率:期待した回答が得られているか
- 幻覚率(Hallucination):誤情報を生成していないか
- レイテンシー:応答速度は許容範囲内か
- ツール呼び出し成功率:適切なツールを選択・実行できているか
- ユーザー満足度:実際の利用者の評価
テストの自動化例
test_cases = [
{
"input": "東京の天気は?",
"expected_tool": "web_search",
"expected_contains": ["東京", "天気"]
}
]
for case in test_cases:
result = agent.run(case["input"])
assert case["expected_tool"] in result.tools_used
全体アーキテクチャの俯瞰
ユーザー入力
↓
[システムプロンプト] ← 設計(ステップ2)
↓
[LLM] ← 選択(ステップ3)
↓
[オーケストレーション] ← 制御(ステップ6)
↓ ↓
[ツール群] [メモリ] ← 統合(ステップ4・5)
↓
[UI] ← 接点(ステップ7)
↓
ユーザー出力
まとめ
AIエージェントの構築は、目標設定から始まり、エンジニアリングで実装し、データで継続的に改善するクローズドループのプロセスです。
各ステップが連鎖しており、一つも省くことはできません。特に最初の「目的とスコープの定義」を丁寧に行うことが、後工程のすべてに影響します。
| ステップ | キーワード |
|---|---|
| 1. 目的とスコープ | ユースケース・成功基準・制約 |
| 2. システムプロンプト | ロール・ガードレール・指示 |
| 3. LLM選択 | 能力・コスト・コンテキスト長 |
| 4. ツール統合 | API・MCP・カスタム関数 |
| 5. メモリ | ベクターDB・RAG・履歴管理 |
| 6. オーケストレーション | ReAct・エラーハンドリング |
| 7. UI | チャット・API・Slack |
| 8. テスト | 正確率・幻覚率・レイテンシー |