こちらはMoney Forward Kansai Advent Calendar 2025の8日目の記事です。
はじめに
こんにちは。マネーフォワード関西開発拠点で長期インターンをしている中村と申します。
13日目の担当でしたが、急遽代打で書くことになりました。
最近ゼロから作るLLMというシリーズを書いているのですが、その際に使用しているツールに関する解説記事です。
LLMの学習や推論をする際にGPUが欲しくなると思いますが、個人で高価なGPUを買うのはハードルが高いです。そこでクラウドGPUサービスを利用することが選択肢に挙がると思います。さらに欲をいえば無料で使いたいです。
有名どころだとGoogle Colabがありますが、無料プランだとバックグラウンド実行ができなかったり高性能なGPUを使用できなかったりと色々な制限があります。
そこで無料枠が充実していてCLIベースで使い勝手の良いModal.comというサービスを紹介します。
価格
まず一番気になる価格からです。本記事の執筆時点での料金を記載しています。
カテゴリ リソース / モデル 価格 GPU Tasks Nvidia B200 $6.25 / h Nvidia H200 $4.54 / h Nvidia H100 $3.95 / h Nvidia A100, 80 GB $2.50 / h Nvidia A100, 40 GB $2.10 / h Nvidia L40S $1.95 / h Nvidia A10 $1.10 / h Nvidia L4 $0.80 / h Nvidia T4 $0.59 / h CPU Physical core (2 vCPU equivalent)
※minimum of 0.125 cores per container$0.0473 / core / h Memory Memory $0.0080 / GiB / h 出典: Plan Pricing
クラウドGPUサービスとしてはインスタンス料金自体は特段安くないですが、
$30の無料枠が毎月付与されます
最初にクレカ登録が必要ですが、予算を設定できるので無料枠を超過しても不意に課金されることはないはずです(多分)
無料枠を利用することでColabの無料プランで割り当てられるT4だと月あたり約50時間使用できます。
インストール
アカウント作成後、プロジェクトにmodalパッケージをインストールします。
uv add modal
その後認証を通します。
modal setup
使い方
初期設定
まずModal上で実行したいファイルのトップレベルで各種初期設定を行います。
import modal
import numpy as np
import torch
import os
# アプリ名(タスクの名前)を設定
app = modal.App("modal-demo")
# ボリュームの作成
volume = modal.Volume.from_name("demo-volume", create_if_missing=True)
# イメージの作成
image = (
modal.Image.debian_slim(python_version="3.11")
.pip_install("torch", "numpy")
.add_local_dir("utils", remote_path="/root/utils")
)
注意点は、
- 使用する外部パッケージを
pip_install内にすべて書く - 他のローカルファイルを参照したい場合は
add_local_dirに追加する
です。
CPUインスタンスの利用
@app.function(image=image, timeout=300)
def cpu_task() -> dict:
x = 5
result = np.array([x, x**2, x**3])
return {"input": x, "powers": result.tolist()}
CPUインスタンスは@app.functionを付けるだけで利用できます。タイムアウトも秒単位で設定可能です。
CPUインスタンスをメインで使用することはないと思いますが、後述するボリュームへの読み書き用の関数などはCPUインスタンス上で実行するのがよいです。
GPUインスタンスの利用
@app.function(image=image, gpu="L4", timeout=300)
def gpu_task() -> dict:
matrix_size = 10000
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
matrix_a = torch.randn(matrix_size, matrix_size, device=device)
matrix_b = torch.randn(matrix_size, matrix_size, device=device)
result = torch.matmul(matrix_a, matrix_b)
return {
"device": str(device),
"matrix_size": matrix_size,
"result_sum": float(result.sum()),
}
GPUインスタンスを利用するにはgpu引数にGPUのモデル名を指定します。
自分は軽いタスクでL4を、VRAMが多く必要なタスクでは48GBのメモリが使えるL40Sをよく使用しています。
ボリュームへの読み書き
@app.function(image=image, volumes={"/data": volume})
def write_to_volume():
filepath = "/data/demo.txt"
with open(filepath, "w") as f:
f.write("Hello Modal")
volume.commit() # ボリュームへの変更を永続化
return filepath
@app.function(image=image, volumes={"/data": volume})
def read_from_volume() -> str:
filepath = "/data/demo.txt"
with open(filepath, "r") as f:
return f.read()
volumes引数に初期設定で作成したボリュームを指定します。
自分はトークナイザーの訓練や学習後のモデルを用いた推論など、手元の環境で実行可能なものはローカルで行っているので、チェックポイントフォルダの同期に使っています。
公式サイトによると現在はストレージ使用量に対する課金は存在しないですが、2026年からはS3準拠の料金が課金されるようです
We currently do not charge for Volumes, which are our native high-performance file serving objects. This is likely to change in early 2026. When we do start charging for Volumes, you can expect the price to be comparable to Amazon S3 pricing.
環境変数の利用
@app.function(
image=image,
secrets=[modal.Secret.from_name("DEMO_KEY")],
)
def use_secret() -> str:
return os.getenv("DEMO_KEY", "not_found")
よくあるユースケースとしてwandb上で学習の進捗を確認することがあると思います。
その際にsecrets引数を用いることでAPIキーなどの環境変数を読み込むことが出来ます。
環境変数の登録はModalのダッシュボードから行います。
ローカルエントリーポイントの作成
最後にCLIからModal.com上のインスタンスを立てる際に必要となるエントリーポイントを作成します。
@app.local_entrypoint()
def main():
cpu_result = cpu_task.remote()
print(f"CPU: {cpu_result}")
gpu_result = gpu_task.remote()
print(f"GPU: {gpu_result}")
filepath = write_to_volume.remote()
print(f"Written: {filepath}")
content = read_from_volume.remote()
print(f"Read: {content}")
secret = use_secret.remote()
print(f"Secret: {secret}")
実行
modal run modal_demo.py
ローカルエントリーポイントを作成したPythonファイルをmodal runコマンドで実行すると以下のような実行結果が得られます。
✓ Initialized. View run at https://modal.com/apps/{user-name}/main/{run-time-name}
✓ Created objects.
├── 🔨 Created mount ~/llm-from-scratch/modal_demo.py
├── 🔨 Created mount ~/llm-from-scratch/utils
├── 🔨 Created function gpu_task.
├── 🔨 Created function write_to_volume.
├── 🔨 Created function cpu_task.
├── 🔨 Created function use_secret.
└── 🔨 Created function read_from_volume.
CPU: {'input': 5, 'powers': [5, 25, 125]}
GPU: {'device': 'cuda', 'matrix_size': 10000, 'result_sum': -401012.5}
Written: /data/demo.txt
Read: Hello Modal
Secret: demo_api_key
Stopping app - local entrypoint completed.
✓ App completed. View run at https://modal.com/apps/{user-name}/main/{run-time-name}
今回はデモ用のコードを用いて説明しましたが、実際に学習を行う際は-dオプションを渡してあげることでターミナルをデタッチしてバックグラウンドでタスクを実行することが可能です。
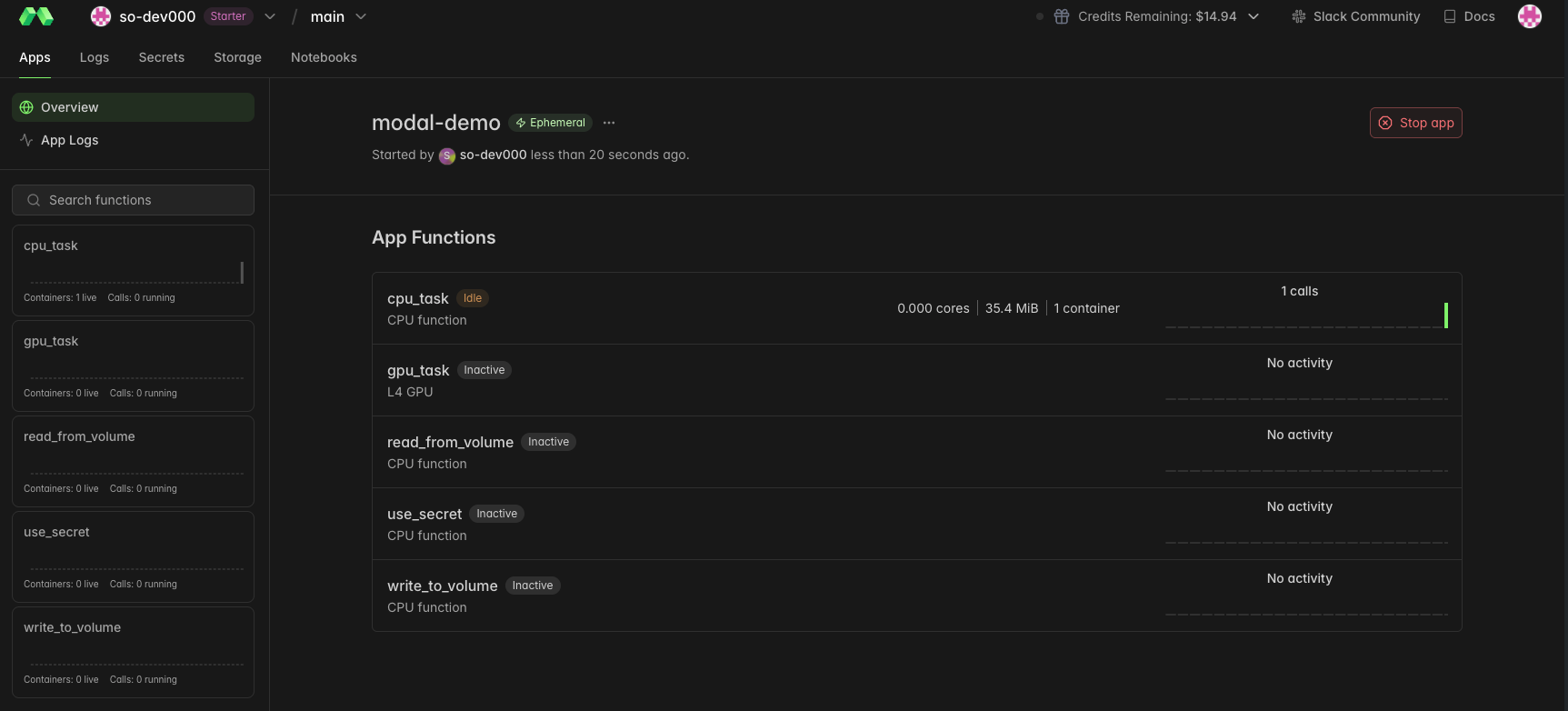
タスクの進捗についてはダッシュボード上で確認できます。
まとめ
クラウドGPUサービスのModal.comの使い方について解説してみました。デコレータをつけたり専用のエントリーポイントを作成する必要があり導入コストはやや高いですが、これから新規でプロジェクトを始める場合は魅力的な選択肢だと思います。