これは何?
最近、社内で Elasticsearch/Lucene 勉強会を毎週ガヤガヤとやっています。
今週の私の担当は、Luceneの検索メソッド IndexSearcher.search の処理の流れを追っていきます。
準備
まずは、手元でデバッグするために、Luceneインデックスの作成と簡単な動作確認をしておきます。
インデックスの作成
インデックスの作成には、 IndexWriter を用いますが、詳細は、 @po3rin さんの ブログ に譲ります。
Directory directory = FSDirectory.open(Paths.get("./data/index"));
StandardAnalyzer analyzer = new StandardAnalyzer();
IndexWriterConfig config = new IndexWriterConfig(analyzer);
var writer = new IndexWriter(directory, config);
File[] files = new File("./data/doc").listFiles();
for (File file : files) {
if(!file.isDirectory() && file.exists() && file.canRead()){
Document document = new Document();
TextField contentField = new TextField("body", new FileReader(file));
TextField fileNameField = new TextField("filename", file.getName(), TextField.Store.YES);
TextField filePathField = new TextField("filepath", file.getCanonicalPath(), TextField.Store.YES);
document.add(contentField);
document.add(fileNameField);
document.add(filePathField);
writer.addDocument(document);
}
}
writer.numRamDocs();
writer.close();
インデックスの読み取りと検索
検索を行うには、 IndexReader にインデックスを読み込ませて、 IndexSearcher にクエリを渡します。
Term term = new Term("body", "You");
TermQuery q = new TermQuery(term);
Directory indexDirectory = FSDirectory.open(Paths.get("./data/index"));
DirectoryReader reader = DirectoryReader.open(indexDirectory);
IndexSearcher searcher = new IndexSearcher(reader);
TopDocs docs = searcher.search(q, 10);
for (ScoreDoc scoreDoc: docs.scoreDocs) {
System.out.println(scoreDoc);
}
これでインデックスの作成と基本的な読み取りはできましたが、searchの流れを追う前に、IndexReader の構造を見ておきます。
IndexReader
IndexReader はその名の通り Lucene のインデックスを読み取るための抽象クラスです。インデックスは複数のセグメントに分割されて管理されています。
各セグメントを読み込む IndexReader は SegmentReader に対応し、
今回ディレクトリからセグメントを読み込む IndexReader は DirectoryReader に対応します。

検索の流れを追う
検索に必要なものは、インデックスとクエリに2点です。インデックスは複数のセグメントに構成されているので、次の2ステップに分かれて検索が実行されます。
- 各セグメントごとにクエリを適用
- 各セグメントの結果を集計
各セグメントごとにクエリを適用
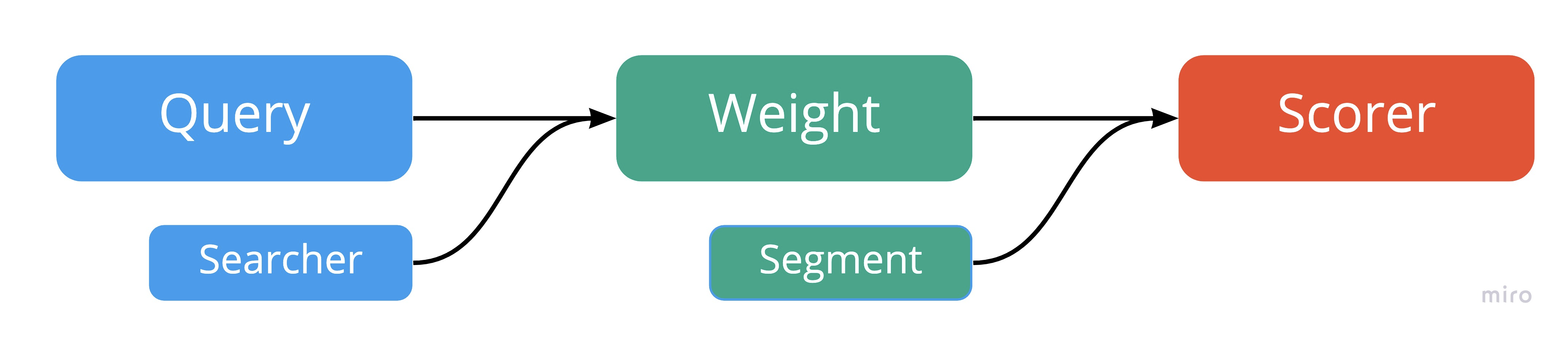
Query は createWeight メソッドに IndexSearcher を渡すことで、Index全体の情報を用いて Weight を生成します。
Weight は Segment の情報を当たることで Scorer を生成します。この時、クエリがヒットしなかった場合は、 Scorer は null になります。
Query 自体は抽象クラスなので、どのような Weight Scorer を生成するかは実装に依存します。今回は、一番簡単な TermQuery に注目して中身を見てみます。
TermQueryの場合
TermQuery は最も基本的なクエリの一つで、インデックスに入力トークンがドキュメントに含まれているかの問い合わせを直接しています。
1 . createWeight 内で TermStates.build を呼ぶ。
https://github.com/apache/lucene-solr/blob/releases/lucene-solr/8.6.3/lucene/core/src/java/org/apache/lucene/search/TermQuery.java#L194-L206
2 . TermStates.build 内で loadTermsEnum を呼ぶ。
https://github.com/apache/lucene-solr/blob/releases/lucene-solr/8.6.3/lucene/core/src/java/org/apache/lucene/index/TermStates.java#L102-L118
3 . loadTermsEnum 内で termsEnum.seekExact でトークンの存在を判定
https://github.com/apache/lucene-solr/blob/releases/lucene-solr/8.6.3/lucene/core/src/java/org/apache/lucene/index/TermStates.java#L120-L129
private static TermsEnum loadTermsEnum(LeafReaderContext ctx, Term term) throws IOException {
final Terms terms = ctx.reader().terms(term.field());
if (terms != null) {
final TermsEnum termsEnum = terms.iterator();
if (termsEnum.seekExact(term.bytes())) {
return termsEnum;
}
}
return null;
}
ctx.reader().terms() の実体は、Codecに依存しています。
https://github.com/apache/lucene-solr/blob/releases/lucene-solr/8.6.3/lucene/core/src/java/org/apache/lucene/index/CodecReader.java#L102-L107
public final Terms terms(String field) throws IOException {
//ensureOpen(); no; getPostingsReader calls this
// We could check the FieldInfo IndexOptions but there's no point since
// PostingsReader will simply return null for fields that don't exist or that have no terms index.
return getPostingsReader().terms(field);
}
public Scorer scorer(LeafReaderContext context) throws IOException {
assert termStates == null || termStates.wasBuiltFor(ReaderUtil.getTopLevelContext(context)) : "The top-reader used to create Weight is not the same as the current reader's top-reader (" + ReaderUtil.getTopLevelContext(context);;
final TermsEnum termsEnum = getTermsEnum(context);
if (termsEnum == null) {
return null;
}
LeafSimScorer scorer = new LeafSimScorer(simScorer, context.reader(), term.field(), scoreMode.needsScores());
if (scoreMode == ScoreMode.TOP_SCORES) {
return new TermScorer(this, termsEnum.impacts(PostingsEnum.FREQS), scorer);
} else {
return new TermScorer(this, termsEnum.postings(null, scoreMode.needsScores() ? PostingsEnum.FREQS : PostingsEnum.NONE), scorer);
}
}
トークンの無い場合は、 termsEnum が null になり、Scorer が null になることがわかります。
Demo
void TermQuery(String text) throws IOException {
System.out.println("----" + text + "----");
TermQuery q = new TermQuery(new Term("body", text));
System.out.println(q);
Weight weight = q.createWeight(searcher, ScoreMode.COMPLETE, 1f);
for (LeafReaderContext leaf: reader.leaves()) {
var scorer = weight.scorer(leaf);
if (scorer == null) {
System.out.println("No hit");
} else {
var it = scorer.iterator();
while(it.nextDoc() != DocIdSetIterator.NO_MORE_DOCS) {
System.out.println("Hit: " + scorer.score());
}
}
}
var topdocs = searcher.search(q, 10);
for (ScoreDoc scoreDoc : topdocs.scoreDocs) {
System.out.println("Search: " + scoreDoc.score);
}
}
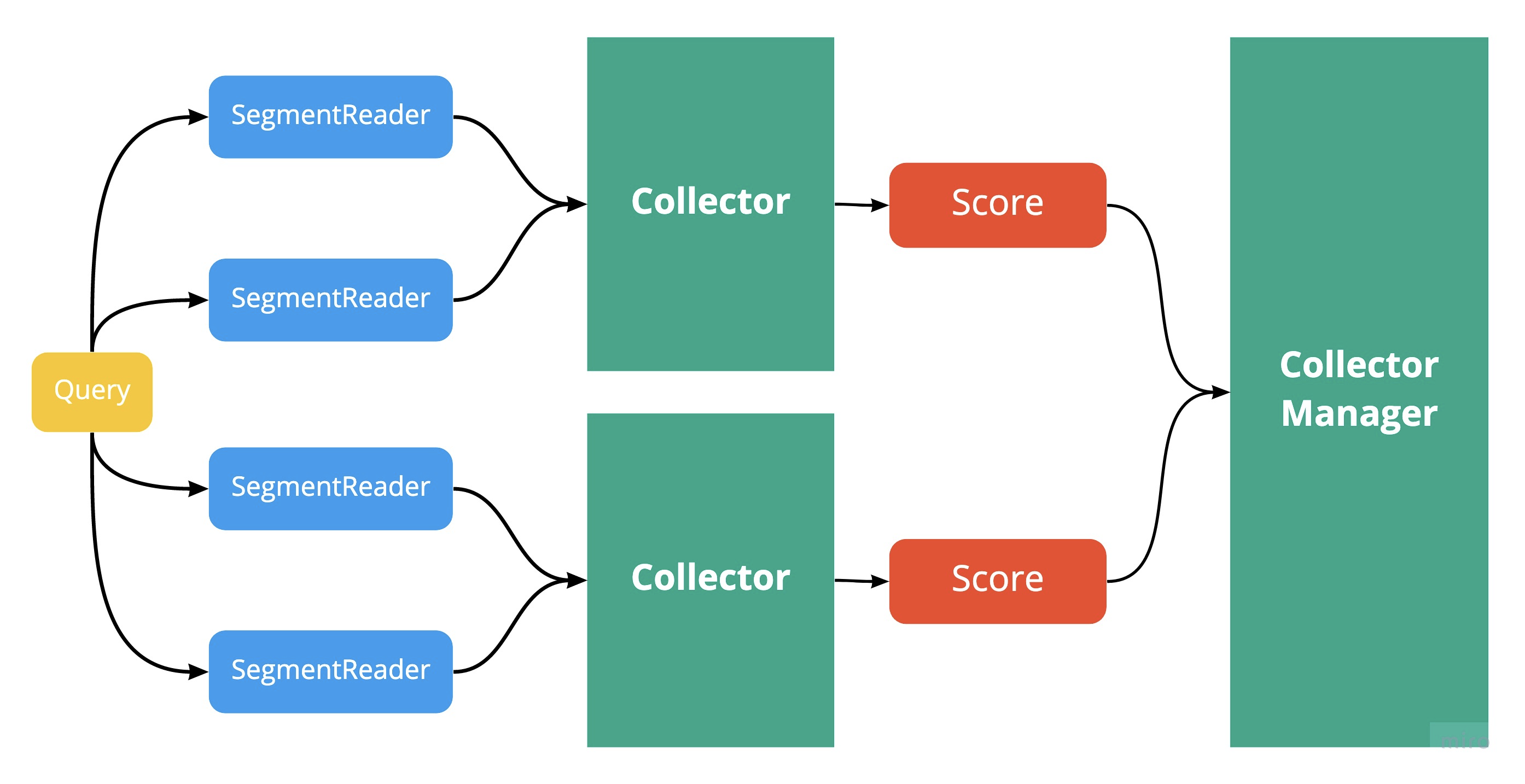
各セグメントの結果を集計
各セグメントの結果を集計する際には、Collector というクラスが用いられます。 Scorer を SegmentReader で生成し、 Collector が集計します。
最終的には、 CollectorManager で再度集計が行われます。ここで行われる計算は search や count といった、 IndexSearcher 内のどのメソッドを用いるかによって異なります。
count の場合
public Integer reduce(Collection<TotalHitCountCollector> collectors) throws IOException {
int total = 0;
for (TotalHitCountCollector collector : collectors) {
total += collector.getTotalHits();
}
return total;
searchの場合
public TopDocs reduce(Collection<TopScoreDocCollector> collectors) throws IOException {
final TopDocs[] topDocs = new TopDocs[collectors.size()];
int i = 0;
for (TopScoreDocCollector collector : collectors) {
topDocs[i++] = collector.topDocs();
}
return TopDocs.merge(0, cappedNumHits, topDocs, true);
}
Next
-
TermQuery以外には主にBooleanQueryとPhraseQueryがあるので、この辺りの実装について理解を深めていきたいです。