アイカツ!のCD売上分析で使用したPythonコードをメモとして記載しておく。
分析自体についてはアイカツ!シリーズのCD売上から見えてくるものを参照ください。
分析データについて
分析データは以下の3サイトから取得した。
今回の分析で使用するデータは、データ量も大したことなかったので、わざわざクローラを使用するよりも手とエクセルを使って加工したほうが早いかなと思い、手動でデータをcsvに加工して作業をした。
とはいえ、JINの投稿データは収集に1時間かかって不精した俺マジクソと思ったんだが、クローラ作るほど何度もJINは利用しないので頑張って手運用。
データの加工はPandasで簡単にやりつつ、描画はbokehにしてPandasのDataframeをそのまま取り込むことにした。
実装
ロード部
import pandas as pd
import numpy as np
import math
# bokeh系のライブラリ
from bokeh.plotting import figure, output_file, show
from bokeh.io import output_notebook
from bokeh.models import ColumnDataSource, Range1d, LinearAxis
output_notebook()
# csvファイルのロード
# アイカツ!のCD売上
df_aikatsu_cd = pd.read_csv('C:/xxxx/cd_sales.csv', parse_dates=[2], engine='python', encoding="utf-8")
# googleTrends
df_trend = pd.read_csv('C:/xxxx/multiTimeline.csv', parse_dates=[0], engine='python', encoding="utf-8")
# JINのアイカツでヒットした投稿数
df_jin = pd.read_csv('C:/xxxx/jin.csv', parse_dates=[0], engine='python', encoding="utf-8")
sales_day_all = df_aikatsu_cd.fillna('0')
#### 加工部
# 発売月単位でサマリする
df = pd.DataFrame({'発売月' : sales_day_all["発売日"].dt.strftime('%Y-%m'),
'初動枚数' : sales_day_all.fillna('0')["初動枚数"].str.replace(',','').astype('int'),
'累計枚数' : sales_day_all.fillna('0')["累計枚数"].str.replace(',','').astype('int'),
'売上高' : (sales_day_all.fillna('0')["セールス(円)"].str.replace(',','').astype('int') /10000).round(0) # 売上高(万円)単位で出すため除算
})
df_groupby = df.groupby("発売月",as_index=False).sum()
# 発売年単位でサマリする
df_groupby_year = pd.DataFrame({'発売年' : sales_day_all["発売日"].dt.strftime('%Y'),
'初動枚数' : sales_day_all.fillna('0')["初動枚数"].str.replace(',','').astype('int'),
'累計枚数' : sales_day_all.fillna('0')["累計枚数"].str.replace(',','').astype('int'),
'売上高' : (sales_day_all.fillna('0')["セールス(円)"].str.replace(',','').astype('int')/100000000).round(4) # 売上高(億円)単位で出すため除算
})
df_groupby_year = df_groupby_year.groupby("発売年",as_index=False).sum()
# googleTrendsを月単位でサマリ
df_trend_month = pd.DataFrame({'月' : df_trend["週"].dt.strftime('%Y-%m'),
'トレンド数' : df_trend.fillna('0')["トレンド数"].astype('int')
})
df_groupby_trend = df_trend_month.groupby("月",as_index=False).sum()
# googleTrendsを年単位でサマリ
df_trend_year = pd.DataFrame({'年' : df_trend["週"].dt.strftime('%Y'),
'トレンド数' : df_trend.fillna('0')["トレンド数"].astype('int')
})
df_groupby_trend_year = df_trend_year.groupby("年",as_index=False).sum()
# JINのアイカツでヒットした投稿数のサマリ
df_jin = pd.DataFrame({'投稿月' : df_jin["投稿日"].dt.strftime('%Y-%m'),
'count' : df_jin.fillna('0')["count"].astype('int')
})
df_groupby_jin = df_jin.groupby("投稿月",as_index=False).sum()
年単位、月単位のサマリはDataframeでやるのが一番簡単かなということで、PandasのDataframeのgroupbyとsum()で一気に集計している。
bokehの表示上の都合で、売上高の桁調整をここでやる。
0が多すぎるとうまく表示されない。
PandasのDataframeの一部カラムだけ表示したいなーと思って調べたので、今回は特に使うことないがメモだけしておく。
# PandasのDataframeの一部のカラムだけ表示する
print(df.loc[:,['発売月','初動枚数','累計枚数']])
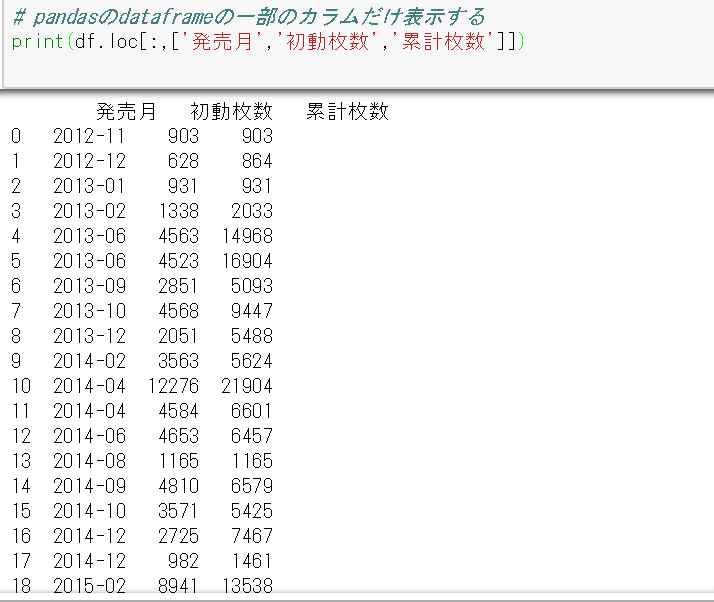
こんな感じで表示される。
#### 曲線近似の算出
# 曲線近似の算出
# 累計枚数
regression = np.polyfit(df_groupby.index, df_groupby['累計枚数'], 1)
print(df_groupby.index*regression[0] + regression[1])
# 売上高
regression_sales_amount = np.polyfit(df_groupby.index, df_groupby['売上高'], 1)
print(df_groupby.index*regression_sales_amount[0] + regression_sales_amount[1])
曲線近似の算出はnumpyとscipyがあるようだけど、今回はnumpyで実装。
最小二乗法でカーブフィッティング。関数3つを使い比べ-python
[Python]多項式によるカーブフィッティング
CD売上が向上している場合も考慮して曲線近似にしたつもりだが、データ上はほぼ直線。
グラフのプロットはprint文のとおり、CD売上月とCDの累計売上数or売上高で1次関数で算出している。
今回は曲線近似にしたが、そもそもこの分析で曲線近似を使うのか、本当に上の実装で問題ないのかは単純に俺の知見・技術不足でよく分からん。
グラフのplot
時系列データを使ったCD売上推移
「アニソンCD売り上げデータ保管庫」のCD売上データを使用。
# CD売上推移のグラフplot
df_groupby["発売月"] = pd.to_datetime(df_groupby["発売月"])
# CD売上のplot
p = figure(plot_width=800, plot_height=400, x_axis_type="datetime", title="CD売上推移")
p.line(df_groupby["発売月"], df_groupby['累計枚数'], line_width=3.5, color="red", alpha=0.5)
p.circle(df_groupby["発売月"], df_groupby['累計枚数'], fill_color="white", line_color="red", size=10)
# 曲線近似のplot
p.extra_y_ranges = {"graph2": Range1d(start=0, end=11200)}
p.line(df_groupby["発売月"], df_groupby.index*regression[0] + regression[1], line_width=1,color="blue", alpha=0.5, y_range_name="graph2")
show(p)
X軸を時系列にして、同一グラフ上に折れ線グラフと曲線近似をplotしている。
グラフのX軸と、y軸の説明、グラフの凡例は見た目上加工しているが、以下のような感じで出力される。
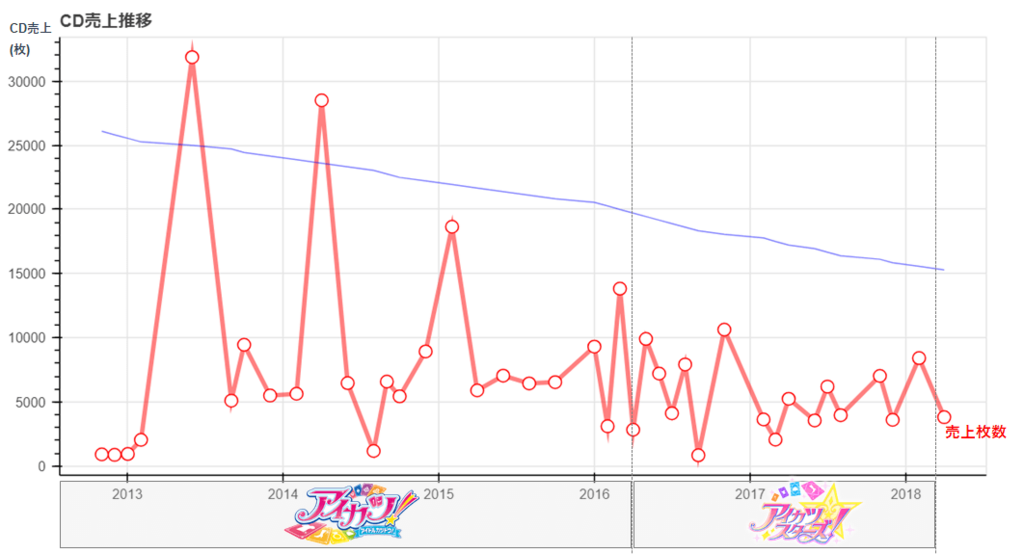
今回描画に当たってbokehを選んだのも時系列データであったという点と、pandasを使用するので、Dataframeをそのままグラフしたかったという点だったりする。
苦戦したのはX軸をうまく読んでくれない点。
というのも時系列データにする場合、型をちゃんと日付型にする必要があったんだけど、Dataframeでは文字列型だったので、日付型にto_datetimeしてから再度入れなおすという対応をした。
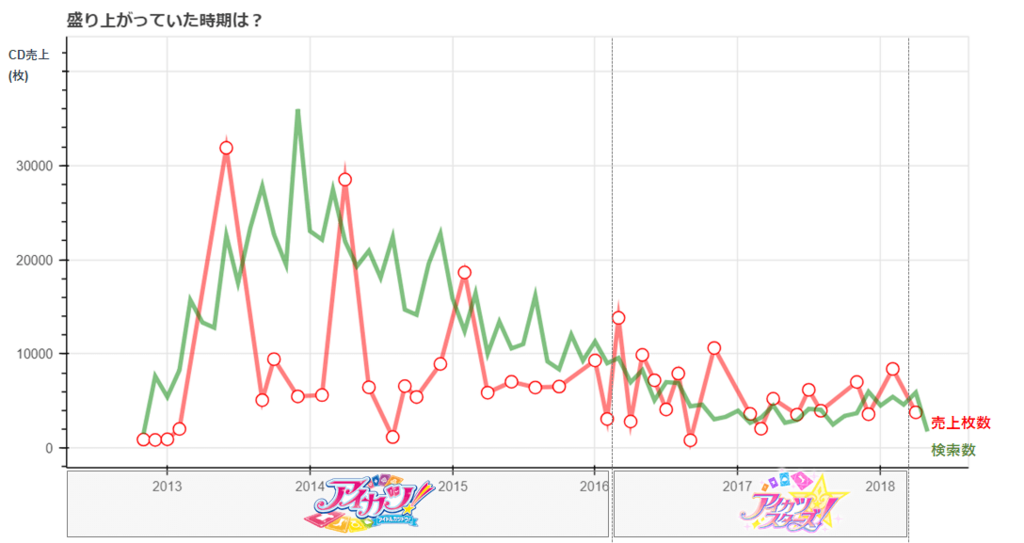
盛り上がっていた時期を調べるグラフ
「アニソンCD売り上げデータ保管庫」のCD売上データと「Google Trends」のトレンド数を使用。
df_groupby_trend["月"] = pd.to_datetime(df_groupby_trend["月"])
p = figure(plot_width=800, plot_height=400, x_axis_type="datetime", title="盛り上がっていた時期は?")
# CD売上のplot
p.line(df_groupby["発売月"], df_groupby['累計枚数'], line_width=3.5, color="red", alpha=0.5)
p.circle(df_groupby["発売月"], df_groupby['累計枚数'], fill_color="white", line_color="red", size=10)
# googletrendsのplot
p.extra_y_ranges = {"graph2": Range1d(start=1, end=500)}
p.line(df_groupby_trend["月"], df_groupby_trend['トレンド数'], line_width=3.5, color="green", alpha=0.5, y_range_name="graph2")
show(p)
これもグラフのX軸と、y軸の説明、グラフの凡例は多少加工しているが以下のような感じで出力される。
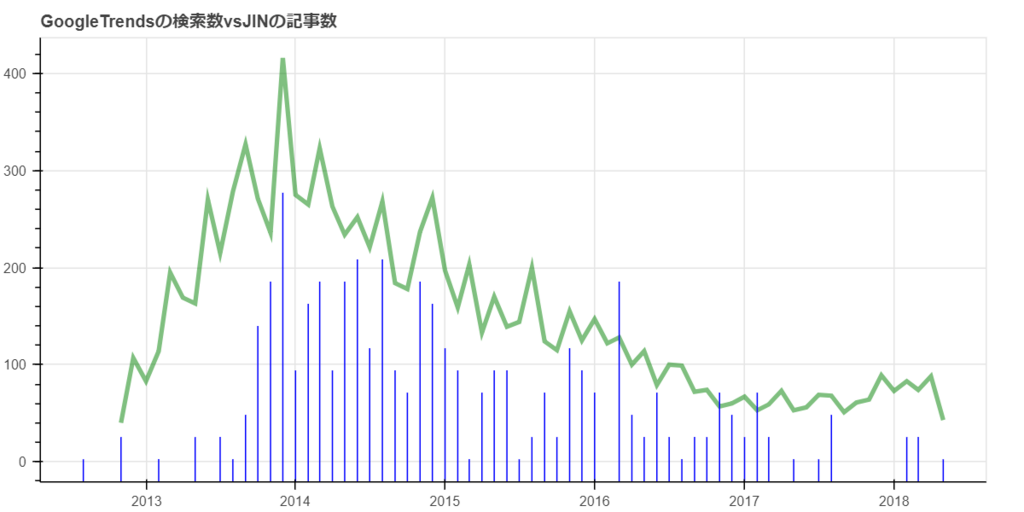
JINとの比較グラフ
「Google Trends」のトレンド数とJINのアイカツ!で検索した記事数を使用。
df_groupby_jin["投稿月"] = pd.to_datetime(df_groupby_jin["投稿月"])
p = figure(plot_width=800, plot_height=400, x_axis_type="datetime", title="GoogleTrendsの検索数vsJINの記事数")
# googletrendsのplot
df_groupby_trend["月"] = pd.to_datetime(df_groupby_trend["月"])
p.line(df_groupby_trend["月"], df_groupby_trend['トレンド数'], line_width=3.5, color="green", alpha=0.5)
# JINの投稿数のplot
p.extra_y_ranges = {"graph2": Range1d(start=0, end=20)}
p.line(df_groupby_jin["投稿月"], df_groupby_jin['count'], line_width=3.5, color="blue", alpha=0.5, y_range_name="graph2")
p.add_layout(LinearAxis(y_range_name="graph2"), 'right')
show(p)
基本は前のものと同じなんだけど、このグラフはグラフの右側にメモリを表示するようにした。メモリがあったほうが分かりやすいかなという判断。
p.add_layout(LinearAxis(y_range_name="graph2"), 'right')
折れ線グラフを棒グラフにしたパターンも試してみているので、メモしておく。
df_groupby_trend["月"] = pd.to_datetime(df_groupby_trend["月"])
df_groupby_jin["投稿月"] = pd.to_datetime(df_groupby_jin["投稿月"])
p = figure(plot_width=800, plot_height=400, x_axis_type="datetime", title="GoogleTrendsの検索数vsJINの記事数")
# googletrendsのplot
p.line(df_groupby_trend["月"], df_groupby_trend['トレンド数'], line_width=3.5, color="green", alpha=0.5)
# JINの投稿数のplot
p.extra_y_ranges = {"graph2": Range1d(start=0, end=20)}
p.vbar(x=df_groupby_jin["投稿月"], width=1, bottom=0,
top=df_groupby_jin['count'], color="blue", y_range_name="graph2")
show(p)
その場合はこのようにplotされる。
相関係数の算出
# 相関係数の算出
correlation = np.corrcoef(df_groupby_trend_year["トレンド数"].values.tolist(), df_groupby_year["累計枚数"].values.tolist())
print(correlation[0,1])
相関係数を出すために各Dataframeをarrayにしている。月単位も年単位も結果同じやろってことで年単位にしてる。
https://docs.scipy.org/doc/numpy-1.14.0/reference/generated/numpy.corrcoef.html

相関係数0.75はまあまあ相関しているのかなーっと。
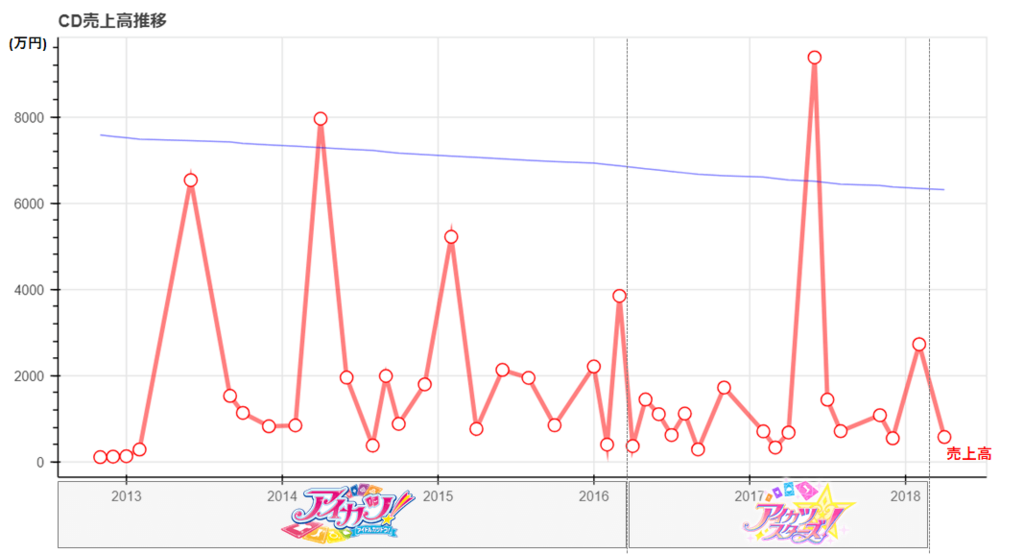
売上高の算出
「アニソンCD売り上げデータ保管庫」のCD売上データを使用。
p = figure(plot_width=800, plot_height=400, x_axis_type="datetime", title="CD売上高推移")
# 売上高のplot
p.line(df_groupby["発売月"], df_groupby['売上高'], line_width=3.5, color="red", alpha=0.5)
p.circle(df_groupby["発売月"], df_groupby['売上高'], fill_color="white", line_color="red", size=10)
# 曲線近似のplot
p.extra_y_ranges = {"graph2": Range1d(start=1000, end=2000)}
p.line(df_groupby["発売月"], df_groupby.index*regression_sales_amount[0] + regression_sales_amount[1], line_width=1,color="graph2", alpha=0.5, y_range_name="foo")
show(p)
グラフの実装はCD売上と同じなので、言うことは特にない。
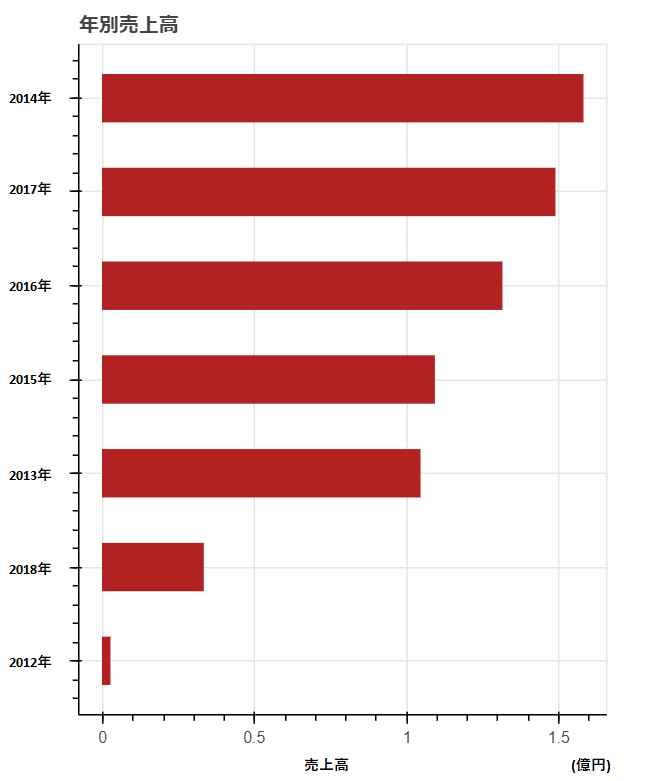
棒グラフを使用した売上高の算出
# 年別売上高
# 売上高でソートしてdataframeのindex振り直し
df_groupby_year_tmp = df_groupby_year.sort_values('売上高').reset_index(drop=True)
# 売上高のplot
p = figure(plot_width=400, plot_height=500, title="年別売上高")
p.hbar(y=df_groupby_year_tmp.index, height=0.5, left=0,
right=df_groupby_year_tmp['売上高'], color="firebrick")
show(p)
plot時にソートはさすがにできそうになかったので、事前にソートを実施。
その時にDataframeのindexを振りなおさないと、結局plotしたときにソートが意味なくなってしまうので、Dataframeのindexを振りなおして、y軸にindexを設定している。
ただこれをやるとy軸のメモリのラベルが0~6になるという問題があって、じゃあDataframeで用意していたラベルにすりゃいいじゃんって設定しようとしたけど、それをすると年でソートされてしまうという。
どうにもこうにもいかず結局グラフの加工でカバーすることにしたんだけど、何か方法ないのかなー。シンプルにラベルわざわざ加工するの面倒くせえ