はじめに
使っていないラズパイ(3b+)が家にあったため、これを使って何か役立つIoT機器でも作ってみようとかと思い、『ラズパイを使って通知機能付き防犯カメラ』を作成してみようと試みたが、ラズパイへのOpenCVのインストールで手こずっている。
インストール不具合は現在調査中なのだが、ラズパイはすぐにCPUが熱くなってしまい、インストールのし直しなどに時間がかかりそうなので、先にOpenCVとYOLOv5を使い通知機能のプログラムを別のPCで作成してみることにした。
実施環境
■ OS
Windows 10 Pro
■ 各種SW&パッケージのバージョン(今回インストールするもの含む)
python 3.9.5
pip 21.3.1
opencv-python 4.5.4.60
YOLOv5
line-bot-sdk 2.0.1 ※通知はLINEより行うため
■ その他
Webカメラ
メモ内容
###① まずは環境準備
色々なパッケージが必要となりローカル環境が散らかりそうだったため、自分は仮想環境上で環境を構築している。(手順は下記を参照)
パッケージのインストールの前にYoLov5のインストールに必要なソースをダウンロードする
※clone先は仮想環境(venv)で作成した場所を指定
git clone https://github.com/ultralytics/yolov5
必要パッケージのインストール
pip install --upgrade pip
# パッケージのインストールコマンド
pip install
pip install datetime
pip install numpy pandas
pip install opencv-python
# 物体検出のための学習済みモデル利用に使うパッケージ一覧
pip install -r ./yolov5/requirements.txt
# PythonプログラムでLINEからプッシュ通知するために必要なパッケージ。
pip install line-bot-sdk
Pythonコマンドでimport cv2 や import torchが実行できれば、一旦インストール完了と考えてOK
(opencv) C:\Users\*******\*******>python ## opencvという名前の仮想環境を作っているため(opencv)となっている。
Python 3.9.5 (tags/v3.9.5:0a7dcbd, May 3 2021, 17:27:52) [MSC v.1928 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import cv2
>>> import torch
YOLOv5の動作確認
以下のコマンドを実行する。
cd yolov5
python detect.py --source ./data/images/ --weights yolov5s.pt --conf 0.4
上記コマンドの引数の説明。
・ source:画像のフォルダ、または画像のパスを指定。
・ conf:指定した値以下の確率値は表示しない。
・ weights:物体検出時に利用する事前学習済みモデルの重みファイルを指定。
※上記コマンドの場合、モデルが存在しない初回時はyolov5s.ptがダウンロードされ、それ以降はダウンロードの処理は実施されない。
実行後にフレームとラベル付きの画像ファイルがruns/detect/exp(デフォルト)に保存される。
② 実現するための各機能の Python サンプルコードを紹介
基本的には下図の様な流れで実現しようと考えている。
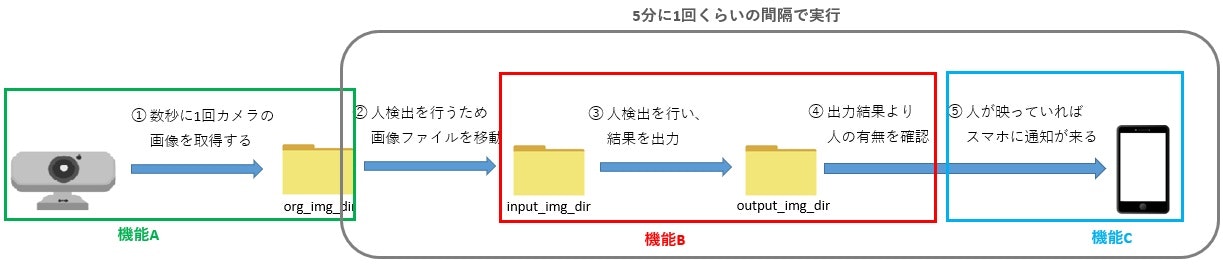
主機能は以下になる。
[機能A] リアルタイム or 数秒置きにカメラから画像を取得する。
[機能B] 取得した画像に人が映っているか判定する。
[機能C] 人が映っていたら通知する
[機能A] リアルタイム or 数秒置きにカメラから画像を取得する。
接続してあるカメラをリアルタイムでディスプレイに表示して、キーボード入力に従い静止画を撮影するコードを参考に、数秒間隔でカメラの画像を取得して保存する [機能A] のサンプルコードを書いてみた。
# パッケージインポート
import cv2
import datetime
# VideoCapture オブジェクトを取得 ※内臓カメラがある状態でWebカメラを使いたい場合などは、番号は0ではなくなる。
capture = cv2.VideoCapture(0)
while(True):
ret, frame = capture.read()
# 表示ウィンドウサイズを指定
windowsize = (800, 600)
frame = cv2.resize(frame, windowsize)
# 表示コマンド
cv2.imshow('タイトル名', frame)
# cv2.waiKeyは引数の数値だけ処理(キー入力)を待つという関数(単位はミリ秒)。
k = cv2.waitKey(1) & 0xff
# 『p』キーで画像を保存
if k == ord('p'):
# 画像の格納場所を指定
date = datetime.datetime.now().strftime("%Y%m%d_%H%M%S")
path = './' + date + '.jpg'
# 画像ファイルの保存
cv2.imwrite(path, frame)
# 『q』を押すと抜ける
elif k == ord('q'):
break
capture.release()
cv2.destroyAllWindows()
# パッケージインポート
import cv2
import datetime
# 取得する画像のサイズ
img_width = 400
img_height = 300
# 取得した画像の格納先
org_img_dir = '.'
# 画像の取得間隔(秒)
interval_sec = 5
# VideoCapture オブジェクトを取得 ※内臓カメラがある状態でWebカメラを使いたい場合などは、番号は0ではなくなる。
capture = cv2.VideoCapture(0)
while(True):
ret, frame = capture.read()
# 取得する画像サイズを指定
image_size = (img_width, img_height)
frame = cv2.resize(frame, image_size)
# 表示コマンド
cv2.imshow('タイトル名', frame)
# 画像の格納場所を指定
date = datetime.datetime.now().strftime("%Y%m%d_%H%M%S")
filename = date + '.jpg'
org_img_path = org_img_dir + '/' + filename
# 画像ファイルの保存
cv2.imwrite(org_img_path, frame)
# cv2.waiKeyは引数の数値だけ処理(キー入力)を待つという関数(単位はミリ秒)。
k = cv2.waitKey(interval_sec * 1000) & 0xff
# 『q』を押すと抜ける
if k == ord('q'):
break
capture.release()
cv2.destroyAllWindows()
[機能B] 取得した画像に人が映っているか判定する。
画像ファイルから物体検出を行い、人が映っているか判定するプログラムは以下のコード。
(一応1つの画像の判定にどのくらいの秒数がかかるか測定する様にした。)
import os
import subprocess
import time
# 処理時間を測るために処理前時刻を取得
start_time = time.time()
# 必要パッケージを仮想環境に入れているため、仮想環境をアクティブにするためのコマンド
venv_activate_cmd = 'C:/Users/*******************************/activate'
# detect.py までのパス
detect_py_path = 'C:/Users/*******************************/yolov5/detect.py'
# インプット用(推論対象)画像が格納されているディレクトリパス ※画像ファイルのパスでも良い
input_img_dir = 'C:/Users/*******************************/images'
# アウトプット(推論結果)を保存するディレクトリパス
output_img_dir = 'C:/Users/*******************************/result'
# 使うモデル[=学習済みの重み]のファイルパス ※初回時にダウンロードしたファイルパスを引かないと、プログラム実行時のカレントディレクトにまたダウンロードされてしまう。
model_weights = 'C:/Users/*******************************/yolov5s.pt'
# 判定するための閾値(設定の値以上の%の物体を検出する)
conf_value = '0.4'
# 特定のクラス(物体)のみ検出するために設定 ※ [0] = person
filter_class = '0 '
# 【--exist-ok】は推論結果を上書きする場合に追加する
# 【--save-txt】は推論結果の検出した座標とクラス番号をテキストで出力したい場合に追加する
# ※ [output_image_path]内にlabelsフォルダが作成され、その中に画像ファイルと同名のtxtファイルが出力される。物体が何も検出されなかった場合はテキストは表示されない。
# 【--save-conf】--save-txtで出力したテキストにクラス確立を追加する。
# ターミナルで実行できるコマンドを作成する。
cmd = 'call ' + venv_activate_cmd + \
'& python ' + detect_py_path + \
' --source ' + input_img_dir + \
' --name ' + output_img_dir + \
' --weights ' + model_weights + \
' --exist-ok ' + \
' --save-txt ' + \
' --save-conf ' + \
' --classes ' + filter_class + \
' --conf ' + conf_value
# subprocess.run によりcmdコマンドを実行する
result = subprocess.run(cmd, shell=True)
print(result)
# 処理時間を測るために処理完了時刻を取得
end_time = time.time()
print(end_time - start_time)
# 人が検出された画像ファイルの数
include_person_img = sum(os.path.isfile(os.path.join(output_img_dir + '/labels', name)) for name in os.listdir(output_img_dir + '/labels'))
※ [機能A]で取得した画像(800×600)で試しに上記プログラムを実行してみたところ、比較的計算コストの低いyolov5s.pt だが5秒くらいの時間がかかった。
人が映っているかの判定は、labelsフォルダにファイルが存在するかどうかで判定する。
[機能C] 人が映っていたら通知する。
通知する機能については、今回LINEのボットからプッシュ通知してもらう方法で実装するが、LINEの公式アカウントの作成や事前にボットを準備しておく必要がある。LINEボットからのプッシュ通知の詳細はこちらを参考に。
from linebot import LineBotApi
from linebot.models import TextSendMessage #テキストメッセージを送る時に使うモジュール
from linebot.models import ImageSendMessage #画像を送る時に使うモジュール
from linebot.exceptions import LineBotApiError
# 通知させたいボットのチャンネルアクセストークン
channel_access_token = ''
# 通知させたいUSERID
user_id = ''
# 通知時に送るメッセージ
push_text = '誰かが家に入ってきました。'
# 画像ファイルのURL(httpsで始まるURLを設定しなければいけない)
url = ''
# テキストメッセージによるプッシュ通知をする関数
def linebot_push_message_text(token, uid, message_text):
line_bot_api = LineBotApi(token)
try:
# 特定の1ユーザーに送る時はこちら。その他にも、マルチキャスト、ナローキャストがある。
line_bot_api.push_message(uid, TextSendMessage(text = push_text))
except LineBotApiError as e:
print(e)
# 画像を送ったプッシュ通知をする関数
def linebot_push_message_image(token, uid, image_url):
line_bot_api = LineBotApi(token)
try:
# 特定の1ユーザーに送る。
line_bot_api.push_message(uid, ImageSendMessage(original_content_url = image_url, preview_image_url = image_url))
except LineBotApiError as e:
print(e)
# テキストメッセージによる通知をする
linebot_push_message_text(channel_access_token, user_id, push_text)
# 画像を送って通知をする
linebot_push_message_image(channel_access_token, user_id, url)
③ 各機能を組み合わせた最終的なコードを紹介
本当は人物の映った画像を送って通知をしたかったが、[httpsで始まるURL]の画像を送るためには、画像のアップロードや送る画像の選別の処理が必要になるので、一旦はテキストメッセージで通知する処理にした。
# 機能Aに使うパッケージ
import cv2
import datetime
# 機能Bに使うパッケージ
import os
import shutil # ディレクトリの初期化に追加
import subprocess
import time
# 機能Cに使うパッケージ
from linebot import LineBotApi
from linebot.models import TextSendMessage #テキストメッセージを送る時に使うモジュール
from linebot.models import ImageSendMessage #画像を送る時に使うモジュール
from linebot.exceptions import LineBotApiError
#################################
# 機能Aに関わる変数設定 #
#################################
# 取得する画像のサイズ
img_width = 400
img_height = 300
# 取得した画像の格納先
org_img_dir = '.'
# 画像の取得間隔(秒)
interval_sec = 3
#################################
# 機能Bに関わる変数設定 #
#################################
# 必要パッケージを仮想環境に入れているため、仮想環境をアクティブにするためのコマンド
venv_activate_cmd = 'C:/Users/*******************************/activate'
# detect.py までのパス
detect_py_path = 'C:/Users/*******************************/yolov5/detect.py'
# インプット用(推論対象)画像が格納されているディレクトリパス ※画像ファイルのパスでも良い
input_img_dir = 'C:/Users/*******************************/images'
# アウトプット(推論結果)を保存するディレクトリパス
output_img_dir = 'C:/Users/*******************************/result'
# 使うモデル[=学習済みの重み]のファイルパス ※初回時にダウンロードしたファイルパスを引かないと、プログラム実行時のカレントディレクトにまたダウンロードされてしまう。
model_weights = 'C:/Users/*******************************/yolov5s.pt'
# 判定するための閾値(設定の値以上の%の物体を検出する)
conf_value = '0.4'
# 特定のクラス(物体)のみ検出するために設定 ※ [0] = person
filter_class = '0 '
#################################
# 機能Cに関わる変数設定 #
#################################
# 通知させたいボットのチャンネルアクセストークン
channel_access_token = ''
# 通知させたいUSERID
user_id = ''
# 通知時に送るメッセージ
push_text = '誰かが家に入ってきました。'
# 画像ファイルのURL(httpsで始まるURLを設定しなければいけない)
url = ''
#########################################
# 機能Bで使用するcmdコマンド作成 #
#########################################
# 【--exist-ok】は推論結果を上書きする場合に追加する
# 【--save-txt】は推論結果の検出した座標とクラス番号をテキストで出力したい場合に追加する
# ※ [output_image_path]内にlabelsフォルダが作成され、その中に画像ファイルと同名のtxtファイルが出力される。物体が何も検出されなかった場合はテキストは表示されない。
# 【--save-conf】--save-txtで出力したテキストにクラス確立を追加する。
# ターミナルで実行できるコマンドを作成する。
cmd = 'call ' + venv_activate_cmd + \
'& python ' + detect_py_path + \
' --source ' + input_img_dir + \
' --name ' + output_img_dir + \
' --weights ' + model_weights + \
' --exist-ok ' + \
' --save-txt ' + \
' --save-conf ' + \
' --classes ' + filter_class + \
' --conf ' + conf_value
###########################
# 機能Cの実行関数 #
###########################
# テキストメッセージによるプッシュ通知をする関数
def linebot_push_message_text(token, uid, message_text):
line_bot_api = LineBotApi(token)
try:
# 特定の1ユーザーに送る時はこちら。その他にも、マルチキャスト、ナローキャストがある。
line_bot_api.push_message(uid, TextSendMessage(text = push_text))
except LineBotApiError as e:
print(e)
# 画像を送ったプッシュ通知をする関数
def linebot_push_message_image(token, uid, image_url):
line_bot_api = LineBotApi(token)
try:
# 特定の1ユーザーに送る。
line_bot_api.push_message(uid, ImageSendMessage(original_content_url = image_url, preview_image_url = image_url))
except LineBotApiError as e:
print(e)
################
# Main処理 #
################
# 人検出&通知 の処理タイミングは、溜まった画像の枚数で決定。
excute_num = 20
# VideoCapture オブジェクトを取得 ※内臓カメラがある状態でWebカメラを使いたい場合などは、番号は0ではなくなる。
capture = cv2.VideoCapture(0)
while(True):
ret, frame = capture.read()
# 取得する画像サイズを指定
image_size = (img_width, img_height)
frame = cv2.resize(frame, image_size)
# 表示コマンド
cv2.imshow('タイトル名', frame)
# 画像の格納場所を指定
date = datetime.datetime.now().strftime("%Y%m%d_%H%M%S")
filename = date + '.jpg'
org_img_path = org_img_dir + '/' + filename
# 画像ファイルの保存
cv2.imwrite(org_img_path, frame)
# 決まった枚数が溜まったら、人物研修を行い、必要に応じて通知を行う。
current_org_img_num = sum(os.path.isfile(os.path.join(org_img_dir, name)) for name in os.listdir(org_img_dir))
if (current_org_img_num % excute_num) = 0:
### 初期化
# [input_img_dir]の中身削除 と [output_img_dir] のフォルダ削除
shutil.rmtree(input_img_dir)
shutil.rmtree(output_img_dir)
os.mkdir(output_img_dir)
include_person_img = 0
# ファイルの移動([org_img_dir] ⇒ [input_img_dir])
os.rename(org_img_dir, input_img_dir)
os.mkdir(org_img_dir)
### 機能B 以降の処理
# subprocess.run によりcmdコマンドを実行する(取得画像の人検出を実行)
subprocess.run(cmd, shell=True)
# 人が検出された画像ファイルの数
include_person_img = sum(os.path.isfile(os.path.join(output_img_dir + '/labels', name)) for name in os.listdir(output_img_dir + '/labels'))
if include_person_img > 0:
# テキストメッセージによる通知をする
linebot_push_message_text(channel_access_token, user_id, push_text)
# cv2.waiKeyは引数の数値だけ処理(キー入力)を待つという関数(単位はミリ秒)。
k = cv2.waitKey(interval_sec * 1000) & 0xff
# 『q』を押すと抜ける
if k == ord('q'):
break
capture.release()
cv2.destroyAllWindows()
※ 画像付きの通知は後日記事を更新する。
最後に
作りながら色々と気付いたが、ラズパイで果たして処理できるのかという疑問や、リモートで止める方法、LINEボットのプッシュ通知数の上限(フリープランのため)など実用を考えるとまだまだいくつか課題がありそう。