「ゼロから作るDeep Learning」(斎藤 康毅 著 オライリー・ジャパン刊)を読んでいる時に、参照したサイト等をメモしていきます。 その10 ← →その11
MNIST データセットによる更新手法の比較 で使っているソースコードch06/optimizer_compare_mnist.py を少し変えて、初期値の設定方法を何通りかためしてみた。
# coding: utf-8
import os
import sys
sys.path.append(os.pardir) # 親ディレクトリのファイルをインポートするための設定
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from common.util import smooth_curve
from common.multi_layer_net import MultiLayerNet
from common.optimizer import *
# 0:MNISTデータの読み込み==========
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)
train_size = x_train.shape[0]
batch_size = 128
max_iterations = 2000
# 1:実験の設定==========
optimizers = {}
optimizers['SGD'] = SGD()
optimizers['Momentum'] = Momentum()
optimizers['AdaGrad'] = AdaGrad()
optimizers['Adam'] = Adam()
# optimizers['RMSprop'] = RMSprop()
networks = {}
train_loss = {}
for key in optimizers.keys():
networks[key] = MultiLayerNet(
input_size=784, hidden_size_list=[100, 100, 100, 100],
output_size=10,
activation='relu',weight_init_std='relu',
weight_decay_lambda=0)
train_loss[key] = []
# 2:訓練の開始==========
for i in range(max_iterations):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
for key in optimizers.keys():
grads = networks[key].gradient(x_batch, t_batch)
optimizers[key].update(networks[key].params, grads)
loss = networks[key].loss(x_batch, t_batch)
train_loss[key].append(loss)
# テストデータで評価
x = x_test
t = t_test
for key in optimizers.keys():
network = networks[key]
y = network.predict(x)
accuracy_cnt = 0
for i in range(len(x)):
p= np.argmax(y[i])
if p == t[i]:
accuracy_cnt += 1
print(key + " Accuracy:" + str(float(accuracy_cnt) / len(x)))
活性化関数に'relu'を指定、「Heの初期値」を設定
activation='relu', weight_init_std='he',
テストデータを処理した結果
SGD Accuracy:0.9325
Momentum Accuracy:0.966
AdaGrad Accuracy:0.9707
Adam Accuracy:0.972
活性化関数に'sigmoid'を指定、「Xavierの初期値」を設定
activation='sigmoid', weight_init_std='xavier',
テストデータを処理した結果
SGD Accuracy:0.1135
Momentum Accuracy:0.1028
AdaGrad Accuracy:0.9326
Adam Accuracy:0.9558
SGDとMomentumが、ひどく認識率が落ちたので、バッチの回数を10000にしてみた。
SGD Accuracy:0.1135
Momentum Accuracy:0.9262
AdaGrad Accuracy:0.9617
Adam Accuracy:0.9673
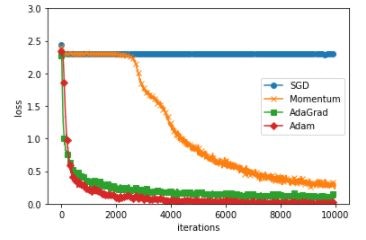
Momentumの認識率はそこそこまで上がったが、SGDはまったくダメ。
活性化関数に'relu'を指定、標準偏差が0.01 の正規分布を初期値に設定
activation='relu', weight_init_std=0.01,
テストデータを処理した結果
SGD Accuracy:0.1135
Momentum Accuracy:0.1135
AdaGrad Accuracy:0.9631
Adam Accuracy:0.9713
SGDとMomentumは、まったく学習できていないようだ。