はじめに
本エントリーは某社内で実施するSQL勉強会向けの資料となります。
本エントリーで書籍「SQL アンチパターン」をベースに学習を進めます。書籍上でのサンプルコードはMySQLですが、本エントリーでのサンプルコードはSQL Serverに置き換えて解説します。
また本章以外のエントリーおよび利用するSQLリソースなどは、以下のGitHubを参照ください。
EAV(エンティティ・アトリビュート・バリュー)とは
「リレーショナルデータベースはメタデータの柔軟性が低い」という拡張性の問題についての議論は、リレーショナルモデルが提唱されて以来、途切れることなく議論されてきました。
EAVは「可変属性をサポートする」など、柔軟な設計を目指したことに起因するDB設計のアンチパターンです。
EAV(Entity-Atribute-Value)では、次のような項目を持たせたテーブルが設計されます。
| 名称 | 主な役割 |
|---|---|
| Entity | 親テーブルに対応する外部キーを格納する。 |
| Attribute | 列の名前に相当する。行ごとに格納したい属性名を指定する。 |
| Value | 属性の値 |
EAV設計による、期待されるメリットは以下の通りです。
- テーブルの列数削減
- 新規属性をサポートするために、列数増加をする必要がない
- 属性が存在しないエンティティの該当列にNULLが入っている、NULLだらけのテーブルを防げる
EAV設計により、データベース構造は単純化することができますが、処理の複雑化を解消できません。
EAV設計によるデメリットを考えていきます。
アンチパターン:汎用的な属性テーブルを使用する
バグデータベースの例で考えていきます。バグ管理(Bug)と機能要望管理(FeatureRequest)を紐付けて管理します。
バグと機能要望の共通な項目は、Issue(問題)で管理していきたいです。
それぞれに管理していくうえで増加する属性があり、その都度追加していければと考えています。
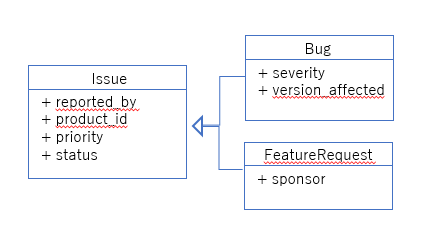
テーブル構成
EAV設計でのテーブル構成です。
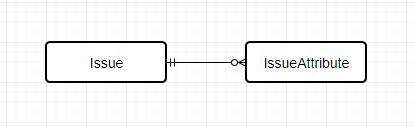
テーブル:Issue
| issue_id |
|---|
| 1234 |
テーブル:IssueAttribute
| issue_id | attr_name | attr_value |
|---|---|---|
| 1234 | product | 1 |
| 1234 | date_reported | 2009-06-01 |
| 1234 | status | NEW |
| 1234 | description | 保存処理に失敗する |
| 1234 | reported_by | Bill |
| 1234 | version_affected | 1.0 |
| 1234 | severity | 機能の損失 |
| 1234 | priority | HIGH |
CREATE TABLE Issue(
issue_id BIGINT identity Primary Key
);
CREATE TABLE IssueAttribute (
issue_id BIGINT NOT NULL,
attr_name VARCHAR(100) NOT NULL,
attr_value VARCHAR(100),
CONSTRAINT PK_IssueAttributes PRIMARY KEY(issue_id, attr_name),
FOREIGN KEY(issue_id) REFERENCES Issues(issue_id)
);
--データ追加
SET IDENTITY_INSERT Issue ON;
INSERT INTO Issue(issue_id) VALUES('1234');
SET IDENTITY_INSERT Issue OFF;
INSERT INTO IssueAttribute (issue_id, attr_name, attr_value) VALUES
(1234, 'product', '1'),
(1234, 'date_reported', '2009-06-01'),
(1234, 'status', 'NEW'),
(1234, 'description', '保存処理に失敗する'),
(1234, 'reported_by', 'Bill'),
(1234, 'version_affected', '1.0'),
(1234, 'severity', '機能の損失'),
(1234, 'priority', 'HIGH');
属性の値を取得するSQLが冗長化する
報告日を取得するというタスクの実行をしたいとき、Issueテーブルにdate_reported(報告日)という項目が存在すれば、SQL1文で取得可能です。
SELECT issue_id, date_reported FROM Issue;
EAV設計では、格納された属性をフェッチしてデータを取得する必要があるため、冗長なクエリとなります。
SELECT issue_id, attr_value AS date_reported
FROM IssueAttribute
WHERE attr_name = 'date_reported';
データ整合性が確保できない
EAV設計では、データベース設計で得られる、いくつもの利点を失ってしまいます。
- 必須属性を設定できない
- 特定の属性(ex. 報告日)に対して、NOT NULL制約を宣言することができません。
- SQLのデータ型を使用できない
- Attributeには複数のデータ値を挿入するため、データ型を文字列とすることが普通であり、DATE型やINT型などのフォーマットを指定できません。
- 個別のデータ型を活用するために、それぞれのデータ型を持ったValue列を定義する拡張したEAV設計とした場合、クエリが煩雑化します。
- 参照整合性を強制できない(外部キー制約が強制できない)
- 1つのattr_valueにBugStatusの外部キー制約をかけると、他の属性でもBugStatusの制限がかかってしまいます。
- 属性名の補完が必要
- 報告日を示す属性名が、date_reported、report_date、...と一貫性のない文字列となる可能性があります。EAV設計では動的に属性が増えることが一般的であるため、「あらかじめ定義した属性名を使用する」といった制限をかけることが難しいです。
行を再構築する必要がある
EAV設計で以下のデータを取得するためには、IssueAttributeテーブルの各属性のJOINを行う必要があります。属性が存在しない場合が想定されるため、内部結合(INNER JOIN)ではなく外部結合(OUTER JOIN)を使用しなければなりません。属性数の増加に伴い結合数が増加するため、クエリの実行コストも指数関数的に増加していきます。
| issue_id | date_reported | status | priority | description |
|---|---|---|---|---|
| 1234 | 2009-06-01 | NEW | HIGH | 保存処理に失敗する |
SELECT i.issue_id,
i1.attr_value AS date_reported,
i2.attr_value AS status,
i3.attr_value AS priority,
i4.attr_value AS description
FROM Issue AS i
LEFT OUTER JOIN IssueAttribute AS i1
ON i.issue_id = i1.issue_id AND i1.attr_name = 'date_reported'
LEFT OUTER JOIN IssueAttribute AS i2
ON i.issue_id = i2.issue_id AND i2.attr_name = 'status'
LEFT OUTER JOIN IssueAttribute AS i3
ON i.issue_id = i3.issue_id AND i3.attr_name = 'priority'
LEFT OUTER JOIN IssueAttribute AS i4
ON i.issue_id = i4.issue_id AND i4.attr_name = 'description'
WHERE i.issue_id = 1234;
アンチパターンの見つけ方
1.「メタデータの変更なしで拡張可能」
RDBでは、拡張性のサポートはされていないはずです。EAV設計を採用しているでしょう。
2.「クエリの最大結合数は、いくつだっけ?」
EAV設計を用いている場合、属性を表示するために多くの外部結合を使用します。クエリの結合数を考慮する必要があるのであれば、EAV設計を使用している可能性があります。
3.導入時に初期設定が不要で、裏でデータベースを使用しているソフトウェアパッケージ。
カスタマイズが容易となるよう、EAV設計を採用していることが多いです。
アンチパターンを用いても良い場合
RDBにおいて、EAV設計を正当化できる理由は簡単には見つかりません。
非リレーショナルなデータ管理であれば、NoSQLに分類される技術を使うべきです。
SQLの代替技術(NoSQL)を使う
非リレーショナルなDB・技術(リレーショナルデータベース以外)がNoSQLです。
EAVの欠点は非リレーショナルなDBにも当てはまります。
NoSQLは、大きく4パターンに分類されます。
書籍「SQL アンチパターン」にも色々なDBが紹介されていますが、次の記事が丁寧に解説されていたため、おすすめです。
NoSQLについて勉強する。
解決策:サブタイプでのモデリングを行う
EAVが扱うようなデータの格納方法はいくつか存在します。4つのモデリング方法を紹介します。
それぞれのモデリング方法で想定するテーブルは、以下の通りとなります。
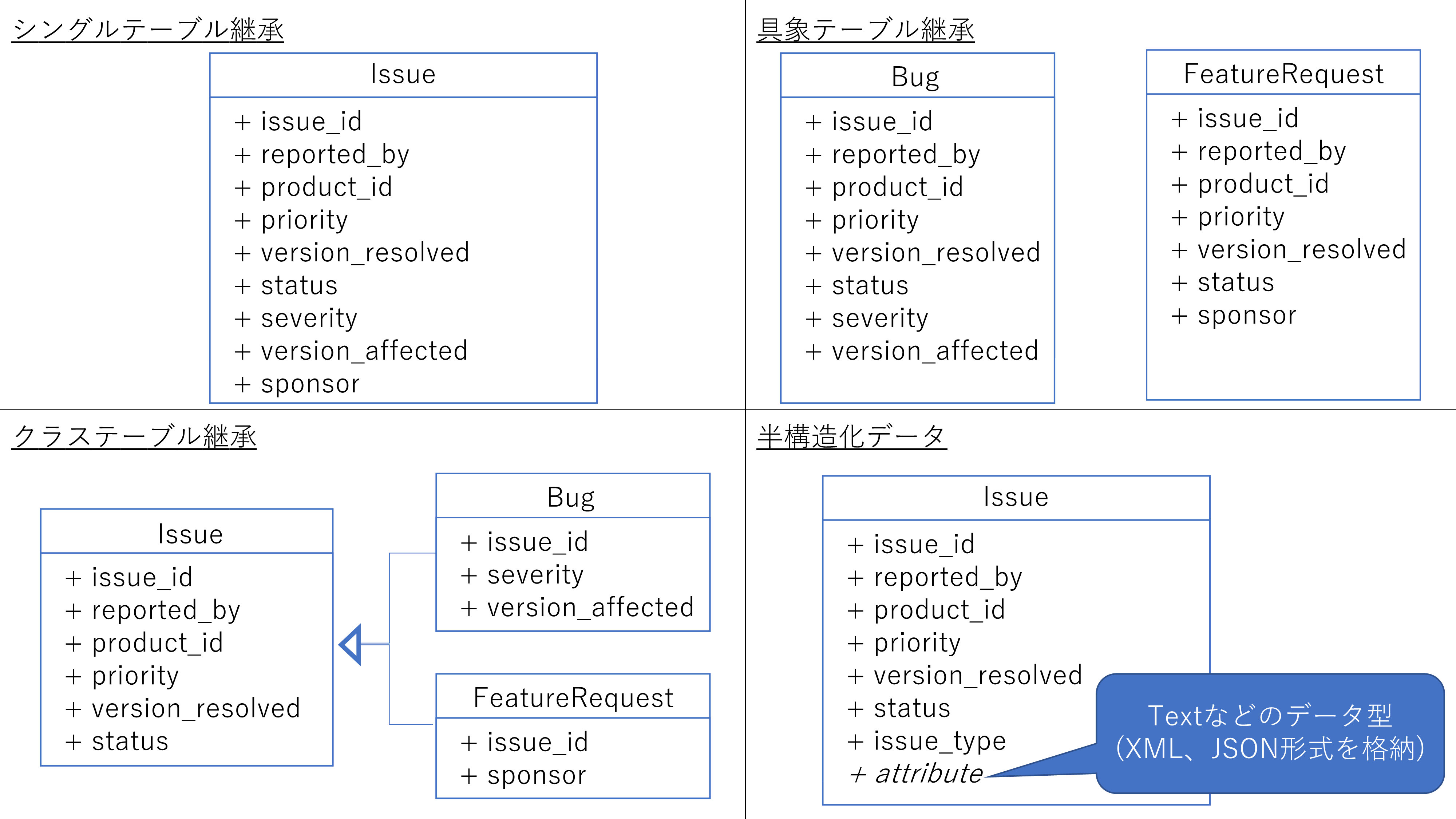
シングルテーブル継承
適切な採用ケース
サブタイプとサブタイプの数が少なく、単一のテーブルに対するデータベースアクセスパターンを使用する必要がある場合
方法
全ての属性を、Issueの個別列として格納します。
具象テーブル継承
適切な採用ケース
すべてのサブタイプをまたいだ検索を実行する頻度が低い場合
方法
BugテーブルとFeatureRequestテーブルをそれぞれ作成します。
シングルテーブル継承と比較した長所は、各テーブルにおいて存在しない属性項目を保持する必要がないことです。
短所は、バグが機能要望かに関わらずデータ取得したい場合等、テーブルをまたいだ情報を取得する際のクエリが煩雑化することです。
(共通属性のみを選択したビューを定義しておく、といった手段をとることもできます。)
CREATE VIEW Issue AS
SELECT b.issue_id, b.reported_by, ... , 'BUG' AS issue_type
FROM Bug AS b
UNION ALL
SELECT f.issue_id, f.reported_by, ... , 'FEATURE' AS issue_type
FROM FeatureRequest AS f;
クラステーブル継承
適切な採用ケース
すべてのサブタイプをまたいだ検索が頻繁に実行される場合
方法
テーブルをオブジェクト指向のクラスであるかのようにみなし、継承を模倣してテーブルを設計します。
共通部でテーブルを作成し、サブタイプごとに固有の項目の項目のみを設定していきます。
共通部とサブタイプが1対1となる構造です。
半構造化データ
適切な採用ケース
サブタイプの数が多い場合、新しい属性を頻繁に追加する場合
方法
共通項目などの明確な項目は個別列を作成し、動的に管理する項目をLOB列と呼ばれる列に対して、JSON・XML等の形式で属性名・値を格納する方法です。
長所は、追加する項目が可能なため、拡張性が極めて高いことです。
短所は、SQLが特定の属性にアクセスする手段をほとんど持っていないことです。
SQLServerではデータ型としてXMLが用意されており、SQLから直接XMLのデータを操作することも可能です。
SQLServerでの、XML型操作の一例を照会します。
CREATE TABLE Issue (
issue_id IDENTITY,
reported_by BIGINT NOT NULL,
product_id BIGINT,
priority VARCHAR(20),
version_resolved VARCHAR(20),
status VARCHAR(20),
issue_type VARCHAR(10), --'BUG'または'FEATURE'を格納
attributes XML NOT NULL, --LOB列:その他の動的属性を格納
FOREIGN KEY (reported_by) REFERENCES Accounts(account_id),
FOREIGN KEY (product_id) REFERENCES Products(product_id)
);
--データ追加
INSERT INTO Issue
VALUES (10, ..., '<Attribute><Name>test1</Name><Suponsor_id>1</Suponsor_id></Attribute>'),
(20, ..., '<Attribute><Name>test2</Name><Suponsor_id>2</Suponsor_id></Attribute>'),
(30, ..., '<Attribute><Name>test3</Name><Suponsor_id>3</Suponsor_id></Attribute>');
--検索
SELECT
*,
attributes.VALUE('(/Attribute/Suponsor_id)[1]', 'int') as SuponsorId
FROM Issue;
さいごに
EAVは「システム内のシステム」です。
EAV設計を採用することによって、SQLが属性を識別しにくくなる可能性があります。
XML型で格納した場合、クエリが若干複雑になったように感じました。
私見
属性の拡張性が絶対に必要になる場面以外、EAVの使用はなるべく避けていきたいです。
データベース設計をするうえで、項目の洗い出しを行い、整理することも重要だと考えています。