はじめに
NoSQLってなんとなく次世代な響きがあって憧れがあるんですが、実際どういうことなのかまとめたことがなかったので知識整理を兼ねていろいろ調べてみました。
NoSQLに至るモチベーションには最近のインフラ事情が色々入っているので調べてみて面白かったです。
NoSQLって?
NoSQLは一般に Not only SQL の略だと言われます。Yes/NoのNoではないですね(※)。
(※ : ただ、NoSQLに対してある側面で対比する存在を指すために YeSQL という言葉は存在しますので、後ほど説明します)
こんな感じのソフトがあります。
(約1匹NoSQLじゃないやつまじってますけど)

個々の製品の解説はしませんが、ロゴが製品特性なんかを表してるやつとそうでないやつがいます。
Neo4jはグラフっぽいですし、riakはおそらくRINGアーキテクチャを表している感じがします。
HDFSやCouchDBなんかは多分そういう感じではないと思います。多分。
NoSQLについてWikipediaから冒頭の説明文を引用してみましょう。
NoSQL - Wikipedia
NoSQL(一般に "Not only SQL" と解釈される)とは、関係データベース管理システム (RDBMS) 以外 のデータベース管理システムを指す おおまかな分類語 である。関係データベースを杓子定規に適用してきた長い歴史を打破し、それ以外の構造のデータベースの利用・発展を促進させようとする 運動の標語 としての意味合いを持つ。
実はここに大事なところが2点ほどあります。
- 非RDBMSを指すおおまかな分類語
- 非RDBMSの利用・発展を促進する運動の標語
ということを象徴する言葉がまさにNoSQLというわけです。
ではなぜRDBMSではなくて、非RDBMSを担ぐような流れが生まれたのか、おおまかなトレンドを見ていきたいと思います。
RDBMSの登場 ~ ITシステムへの浸透
NoSQLを含め、いわゆる現代において語られるようなデータベースの歴史は、概ね1980年前後にはじまります。
まず、1977年にOracleが世界初の商用リレーショナルデータベース製品であるOracle v2を発売したのを皮切りに、
| 発表年 | 開発元 | 製品名 |
|---|---|---|
| 1977年 | Oracle | Oracle Database |
| 1983年 | IBM | DB2 |
| 1989年 | Microsoft | SQL Server |
| 1989年 | OSS | Postgres |
| 1995年 | OSS | MySQL |
と名だたるIT企業が立て続けにRDBMS製品をリリースし、この時期にリリースされた上記のDBによって現在のRDBMSシェアは9割を超えると言われています。
このように、多数のデータベース製品がリリースされた背景には、1970年~1990年頃においてビジネスフィールドへのITシステム導入が急速に進んだことがありました。
この時代ではまだ世の中はパソコン/インターネット時代には到達していないため、この時代のITの中心は正にこうしたデータベースによる情報管理そのものにあったと言っても過言ではありませんでした。
広義のDBMS(データベース管理システム)としてはリレーショナル型の他にネットワーク型、カード型、階層型などがありますがビジネスモデル(トランザクションの必要性など)に最もよく合致したのがRDBMSでした。RDBMSにおける"リレーショナル"とは
- 個々のデータ(レコード)がいくつか属性(カラム)を持ち、データの集合が表として扱われる
- データやデータの集合に対して関係演算(結合/射影/制限/和など)が行える
ことを指すものでした。
ネットワーク型ほど直感的ではないにせよ、表という具体的なイメージとともに捉えられるRDBMSはSQLという便利なインターフェイスと共にITシステムへと浸透していきました。
ITシステムの成長
そうした、1990年までの企業を中心としたIT導入に続き、1990年以降は個人にもITの導入が進みました。
WindowsやMacをはじめとするパソコンやそこから広がるインターネット、さらにはスマホの普及によりますますITは世の中に広がっていきましたが、そうした個人利用を支える企業のITシステムが扱うべきデータ量、ITシステムに求められる処理性能も飛躍的に増大していきました。
そうしたITシステムへの要求の大きさが、物理的な存在としてのIT部品に対してどのように関係するか、実はこのことが後のNoSQL登場の土壌となる難題を生み出すことになります。
というのも、ITシステムの処理性能とは、物理的なハードウェア視点でみると主に下記の要素性能に依存して、総合的に形成されます。
- CPU
- メモリ
- ストレージ
- ネットワーク
これらのようなITシステムを構成する要素の成長スピードに関して、いくつか興味深い話がありますので、ここでそれぞれを紹介します。
ムーアの法則 [ CPU / メモリ ]
ムーアの法則 を聞いたことがある人は非常に多いかと思います。
CPUで有名なIntelの創業者のひとりであるゴードン・ムーアが 1965年に発表 した半導体の成長に関する 経験則 です。
論文における言及はもう少しわかりづらい形をしていますが、一般的にムーアの法則は下記のように紹介されます。
集積回路上のトランジスタ数は18か月ごとに2倍になる
同じサイズのCPUを比較した場合、物理的に搭載できるトランジスタ数が指数関数的に増大し、結果として性能が向上していくというものです。
また、別な観点としては「 同じ性能であれば18ヶ月で価格が半分になる 」とか「 同じ性能であれば18ヶ月で大きさが半分になる 」などとも表現されます。
1965年に発表され、ムーア自身も「より長期的には、増加率はやや不確実であるとはいえ、 少なくとも今後10年間ほぼ一定の率を保てないと信ずべき理由は無い 。」と述べていましたが、10年どころか50年を過ぎた今でも、幾多の技術的困難を乗り越えて概ねムーアの法則に従った成長をしていると言われます。
(参考) 「ムーアの法則」50周年、CPUを自動車に例えると驚きの性能に!
一方で、半導体の集積密度向上に言及した内容であるため、今後さらなる集積密度向上が起こり、ムーアの法則上は トランジスタサイズ≒原子サイズ にならざるを得なくなってきます。
物理的な壁として存在する以上、ムーアの法則はいよいよ終わりを告げるものと見られています。
(ただし、量子コンピュータや炭素半導体など、トランジスタの枠を超える形での性能向上の道が残されています)
ギルダーの法則/カオの法則 [ ネットワーク ]
ギルダーの法則 はアメリカの経済学者ジョージ・ギルダーによって2000年に発表されました。
ギルダーの法則はネットワーク版のムーアの法則で、通信網の帯域幅について言及します。
通信網の帯域幅は6ヶ月で2倍になる
通信網は銅ケーブルや光ファイバーケーブルなど、半導体でない部品も使われますが、ケーブルによって連結されるスイッチやルータなどが半導体でできている以上、こちらも結局はムーアの法則と同じように18ヶ月で2倍というスピードに落ち着くように思います。
しかし、通信網においては 多重化 による信頼性向上や性能向上のアプローチが盛んであり、個々の性能向上に加えてスケールアウト的な性能向上が起こり、結果としてこのギルダーの法則が導かれます。
こうした「通信網の性能向上には多重化が効果的である」「通信網は半導体よりも早く成長する」ことは別に カオの法則 と呼ばれます。
大量データとボトルネック
さて、ここで再び話を戻しましす。
最初期では業務処理のため、メインフレームと呼ばれる巨大な専用機をITシステムの中核に採用していたものが、現在ではIAサーバと総称される汎用サーバを多数並べ、クラスタシステムを構成することでITシステム全体としての性能向上を図ること自体は難しくなくなりました。
それと同様に、大量データ処理においてもクラスタシステムを構成し、 分散処理 を行うことは自然なアイデアであると言えます。
そうしたクラスタシステムにおいて重要なことは、「クラスタとしてデータを共有し、協調して動作する」ことにありますが、そのためにはデータを読み出し、ネットワークを介して各サーバ間でデータを共有しないなければなりません。
ここで、コンピュータの構成要素ごとのデータ転送レートについて考えてみます。
- CPU
- 数十Gbps
- メモリ
- 数Gbps
- ストレージ
- 数Gbps
- ネットワーク
- 数百Mbps ~ 数Gbps
こうして部品ごとに見た場合、 CPU内で処理が完結することが最も高速 であり、次いでCPU/メモリの処理、サーバで閉じていればCPU/メモリ/ストレージの処理としてある程度の速度が期待できます。
しかし、大量データ処理においては当然データがメモリ上に収まるはずもなく、ストレージも1台ではせいぜい数TBにしかならず、ネットワークを用いた処理がどうしても必要になってきます。
ところが、ネットワークはデータ転送レートとして正に 桁違いに遅く 、スケールアウトなどで好意的に見られがちなネットワークを介した処理は、実はそれ単体としては非常に低速な処理にならざるを得ないことがわかります。
ネットワークやストレージに関してはより高い性能をもつ高級品は確かに存在しますが、大量データ処理という特に大量のサーバを必要とするクラスタシステムに対してそうした高級品をふんだんにつかうことはコスト面で難しいと考えられます。(ここにお金をかけたシステムのことは一般にスパコンと呼ばれます)
ここで疑問に思うかもしれませんが、単体のネットワーク性能はシステム全体としてのネットワーク性能と同じ比率では成長しません。
これはギルダーの法則とカオの法則で述べたように、ネットワーク全体では多重化によって飛躍的に性能が向上するものの、1枚のNICや1本のケーブルに着目すると実はCPUやメモリほど性能は向上していないことに起因します。
そのため、時間を経る毎に マシン間でデータをやりとりするためのネットワーク性能が相対的なボトルネック になってしまいます。
また、ストレージについてもネットワークに次いでボトルネックになる可能性を秘めています。
最近ではようやくSSDなどの高速な半導体ストレージが一般的になってきましたが、少し前まではHDDという磁気ストレージが一般的でした。半導体でない以上、ムーアの法則には従わず、ここもやはりITシステムにおいてはボトルネックになりやすい点とされていました。
Webシステムなどのランダムアクセス用途で用いられるSSDは確かにHDDよりも格段に速いのですが、大量データ処理で重要なシーケンシャルアクセスではまだHDDとそこまで差がなく、コスト面からもまだまだ HDDを使うことが主流 となっています。
大量データ処理では、文字通り大量データをやりとりしなければならないため、この ネットワークとストレージのボトルネック はデータ量の増大に従っていよいよ深刻になっていきました。
分散ファイルシステム / 分散データベース
そうした深刻な問題を受け、注目されるようになったのが、「 データローカリティ 」という考え方です。
言われてみれば簡単な話なのですが、データ処理を抽象的に考えたとき、プログラムとデータの関係性は大きく分けて、
- プログラムのところに データを持っていく
- データのところに プログラムを持っていく
という2つのパターンがあります。
加えて、高速な処理のみを求めていた従来のコンピューティングに加え、その処理結果から得られるログなどのビッグデータを更に分析する昨今を考えると、分析すべきデータと分析プログラムのサイズの比較においては、圧倒的にデータが大きいと考えられること、これをデータローカリティの考え方と合わせることで新しいタイプのソフトウェア群が現れました。
それが Google File System (GFS) や Hadoop Distributed File System (HDFS) の分散ファイルシステム、そしてHadoopと呼ばれる分散処理フレームワークやNoSQLと呼ばれる多くの分散データベースです。
これらはそれぞれ分散の単位(ブロック、ファイルなど)は違いますが、CPUやメモリに比べて低速なストレージ性能を分散でカバーしつつ、データローカリティの実践によってネットワークのボトルネックを極力排することを目指しました。
要するに、分析対象となる巨大なデータの移動を極力抑え、データがあるところにプログラムを持っていき、それぞれの場所で計算を行うようにしたわけです。
一方で、高速化のために犠牲にした面も存在します。そのことを象徴的に表現するのが「 Write once, Read many 」というフレーズです。
これらの分散ファイルシステムや分散データベースでは、分析を主とするユースケース上、書き込みよりも読み込みが多く発生します。そのため、データの更新がユースケース上ほぼ要求されず、そうした特性を踏まえてデータの共有やトランザクションというような機能をある程度諦めることで、性能上の優位性を獲得した側面があります。
NoSQLの種類
最初に触れたようにNoSQLは非RDBMSの総称であり、データベース製品のカテゴリとしては非常に範囲が広いです。
NoSQLの分類方法として、
- どのような形でデータを持つか (データモデル)
- どのように分散してデータを持つか (アーキテクチャ)
に着目することができます。下記の図が分かりやすいです。
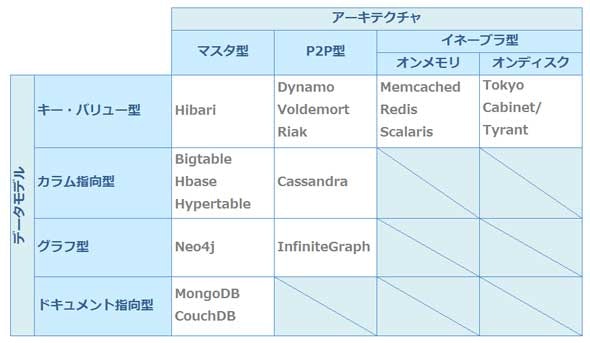
引用 : 知らないなんて言えないNoSQLまとめ ― @IT
データモデル
NoSQLのデータモデルには大別して次の4つがあります。
-
キー・バリュー型
- Key : Valueを単位としてデータを格納する。
- シンプルで応答が早い。
-
カラム指向型
- 一般の行指向型DBと同様に表の構造を持ちつつ、カラム単位でデータを保持する。
- 行指向では苦手な列単位の大量集計、大量更新が得意。
-
グラフ型
- ノード、リレーションシップ、プロパティによって定まるデータを単位とし、全体でグラフを形成する。
- グラフ型の名前の通り、Facebookの知り合い機能等で有効に利用できる。
-
ドキュメント指向型
- JSONやXMLのような構造を持ったドキュメントを単位としてデータを格納する。
- スキーマレスで格納できる。
アーキテクチャ
アーキテクチャは次の3種類。
-
マスタ型
- マスタ型では分散データベースクラスタを形成するノードのうち、メタ情報などを管理するマスタが存在する。
- マスタがクラスタの状態を管理するため、マスタに対する障害耐性が低かったり、マスタの処理性能がクラスタ全体の性能に影響を与えたりする。
-
P2P型
- P2P型ではマスタ型と異なり、クラスタを構成するノードが全て等価な役割を持つ。
- 全ノードで等価なため、障害耐性の偏りがなく、スケールアウトがほぼリニアに実現する場合が多い。
- ただし、ネットワーク分断が発生した場合にはいわゆる スプリットブレイン の危険性がある。
-
イネーブラ型
- 正確にはアーキテクチャではないけれどEnablerということで、他者との組み合わせによって効果を発揮する型。
- オンメモリ型はデータの永続性という点でデータベースと呼ぶには不十分なものの、NoSQLの持つ応答性の遅さを改善することができる。
NoSQL VS YeSQL ?
NoSQLに対して、 YeSQL という言葉を稀に耳にすることがあります。
- From Only-SQL to NoSQL to YeSQL
- YeSQL: An Overview Of The Various Query Semantics In The Post Only-SQL World
- Perspectives on NoSQL
これまで見てきたように、NoSQLという波は増え続けるデータを蓄え、かつ効率的に処理するための手段の探求から考えだされたものでした。
従来のRDBMSでは、大量データや多様なデータ形式に対して実用上の不都合があったため、RDBMSの良さを一部犠牲にすることでその不都合を解決するNoSQLが生まれました。
そうした背景を考えると、データベース問い合わせ言語としてのSQLには何の罪もないわけです。
そうして生まれたNoSQLがサポートするのは不完全な "SQLライクな問い合わせ言語" ですが、それは柔軟なデータ構造や高速な集計処理などに対応するためやむを得ず選択した結果であって、「SQL準拠が不要だから捨てた」ということでは決してありません。
その証拠に、HiveによるHiveQLから始まり、後のSparkに至るようなビッグデータに対するSQL処理のトレンドは「 SQLに準拠した処理で 」「 いかに速く 」というところにシフトしてきたように思います。
HadoopのMapReduceが出た頃には「 大量データ処理にはMapReduce 」のような雰囲気がありましたが、やはり多くのエンジニアにとってSQLというインターフェイスは非常に扱いやすく、またデータ処理に向いているようです。
そういった意味で、
We don't say "No" to SQL. We just say "Yes" to SQL!
という文脈で語られる YeSQL という言葉があるようです。
NewSQL
さて、最後にNewSQLに触れておきます。
YeSQLのところでも述べたように、NoSQLではビジネス上必要な処理性能を獲得するため、やむを得ずSQLへの準拠を崩す選択をしました。
しかし、NoSQLで性能を獲得してしまうと、今度は再度SQLを手に入れる動きが出てきます。
何をどのDBとするかの厳密な線引きはさておき、様々な製品を特性ごとにマッピングしたのが下記の図です。

特に大きく区切られている領域について説明しておきます。
-
Relational
- RDBMS
-
Non-Relational
- 非RDBMS
-
Operational
- ユースケース上、 継続的なデータ投入や更新が行われるもの
- 決済履歴やユーザ情報、他にはセッション情報の保持に用いられる
-
Analytic
- ユースケース上、 大量データの蓄積と分析が行われるもの
- OracleなどメジャーRDBMSもこの分類になっているが、当然対応するスケールの上限にはHadoopなどに比べて大きな差がある
まずこの図は大きく「Relational」「Non-Relational」に区切られ、Non-RelationalでNoSQLが一際目を引くのがわかるかと思います。
一方で、Relationalに見えるNewSQLという領域があります。
このNewSQLに分類される製品がSQLに準拠したインターフェイスを持ちつつ、非リレーショナル的なデータの格納もできるタイプのデータベースです。
ここに分類されるものには、「NoSQLがSQLを獲得したもの」「RDBMSが非リレーショナルデータに対応したもの」の2パターンが存在します。
MySQLやPostgreSQLも最近ではスキーマレスなJSONデータの格納に対応するなど、後者のアプローチでNewSQL化が進んでいると言うことができます。
雑感
色々なソフトウェアカテゴリがある中で、ここまで多くの種類があるのってデータベースくらいなものだと思います。
それだけビジネスの中で重要な位置を占めているということでもあり、それ故に各時代において強いモチベーションをもって、ハードウェア/ソフトウェアを問わない様々な手段でイノベーションが生み出されてきたのだと思いました。
これから先SSDやFlashストレージなどIO性能が格段にいいストレージが価格を今の磁気ディスク並みに下げてきたら、これらの多様性が一気に失われていくのかもしれないですね。また、そろそろ不揮発性メモリが実用に向かってきますので、そもそもの考え方が大きく変わってくるかもしれません。
そうした新しいものに触れるたび、広義のデータベースというものがさらなる発展を見ると思いますが、その流れの元には今回見てきたような課題意識とその解決があったということは、覚えておいて損はないでしょう。
NoSQLのモチベーション、アーキテクチャの種類などに触れて、非常にいい勉強になった気がします。おわり。