はじめに
初学者です。最近WebAPIについて学んでいて
「QittaAPIを使って面白いこと∧簡単にできそうなこと∧自分もあって嬉しいもの」
ということで、
1週間前に投稿されたQittaの記事のうち、最もいいねがついた記事(=この一週間で最も注目度が高いと思われる記事とする)を毎日投稿するBotを作りました。
作ったBot
以下Xアカウントで毎日朝7時に投稿しています。
Xアカウント(よければフォロー頂けると励みになります)
こんな感じです。
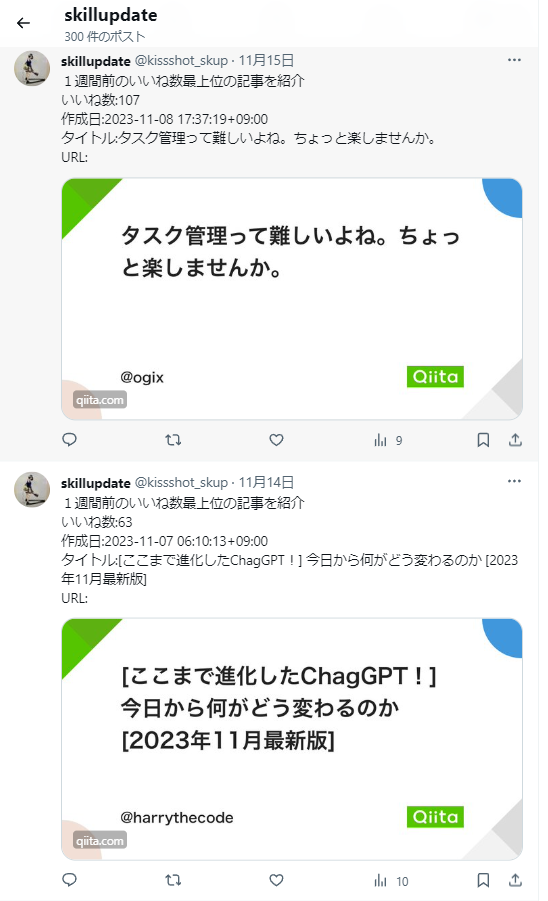
とりあえず見てみるかという気持ちになりませんか?
自分では検索して意図的に探さないような、面白い記事が自動的に目に入るので、
アンテナが広がる気がしています。
もうちょっと長期的に使っていきながら使い勝手とかを高めて行く予定です。
仕組み
以下構成です(AWSの説明アイコンを拝借しています)。
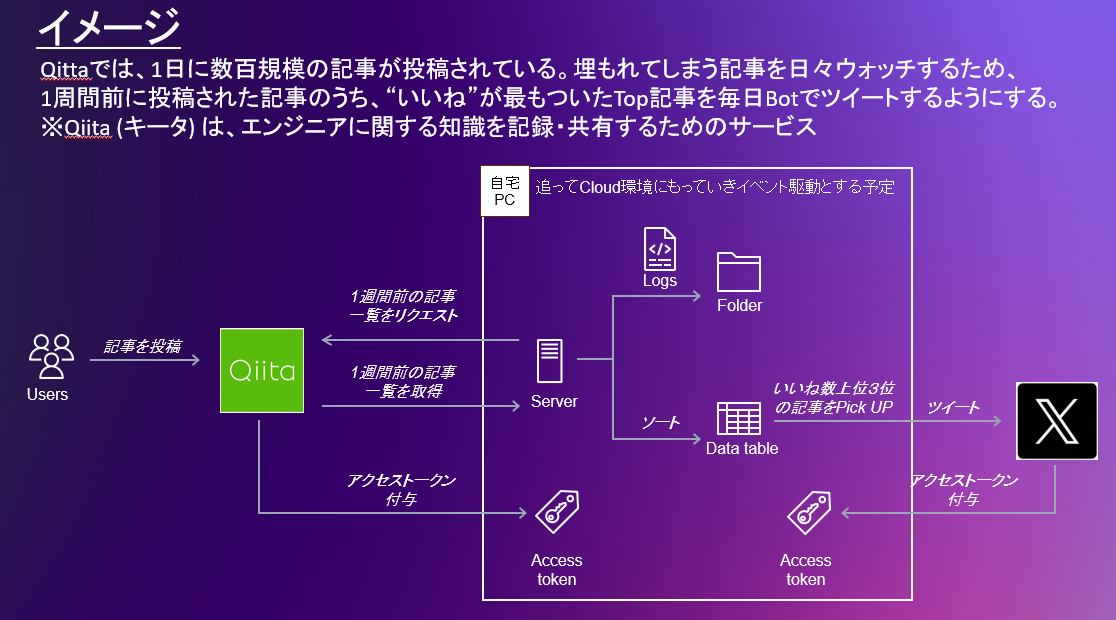
今は自宅PC上で、タスクスケジューラを設定して以下で示すソースコードを叩いていますが、最終的にはクラウドに持っていく予定です。
各モジュールの詳細については、過去記事を参照のこと。
<参考:過去の記事>
過去記事の組み合わせで作りました↓
- Web APIについて
- 【情報処理】AWSでwebhookの受信&メール通知を実装する(API Gateway+Lambda)
- Web APIでbotを作ろう!
- Qiita API を使って、特定の日の記事データを取得する方法
本体のソースコード
先に謝っておきますが、Python初心者です。コードの作りは全く美しくないです(初心者でもわかる程度に美しくない。。。色々と過去製作物の作りが残っていて不要な部分多いです)。 とりあえず動くものを作ったんだなという理解でお願いします。
# Qitta用
import http.client
import json
import pandas as pd
import math
import datetime
# Twitter用
import os
import tweepy
import settings
#設定した値をとる
CONSUMER_KEY = settings.consumer_key
CONSUMER_SECRET = settings.consumer_secret
ACCESS_TOKEN = settings.access_token
ACCESS_SECRET = settings.access_token_secret
#オブジェクト作成
client = tweepy.Client(consumer_key=CONSUMER_KEY,
consumer_secret=CONSUMER_SECRET,
access_token=ACCESS_TOKEN,
access_token_secret=ACCESS_SECRET)
# Twitter用‐ここまで‐
h = {'Authorization': 'Bearer xxxここにアクセストークンを記入xxx'}
conn = http.client.HTTPSConnection("qiita.com")
url = "/api/v2/items?"
# 本日から7日前の日付を取得して文字列に変換して
# 指定したフォーマットに整形
today = datetime.date.today()
ago7days = today - datetime.timedelta(days=7)
ago7days_str = ago7days.strftime("%Y-%m-%d")
print(ago7days_str)
# 取得するQiitaの記事情報の日付を指定
start = ago7days_str
end = ago7days_str
# 日付をリスト化
date_list = [d.strftime('%Y-%m-%d')
for d in pd.date_range(start, end, freq='D')]
print(date_list)
# カウント用変数
num = 0
p = 0
# start_listの配列の数だけ繰り返し処理
for i in date_list:
num += 1
# 日付のリストから検索の開始日と終了日を取り出す
search_date = date_list
query = "&query=created:>=" + search_date[0] + "+created:<=" + search_date[0] + "&per_page=100"
# 検索で指定した期間内に作成された記事数を取得
conn.request("GET", url + query, headers=h)
res = conn.getresponse()
res.read()
print(res.status, res.reason)
print(res.headers['Total-Count'])
total_count = int(res.headers['Total-Count'])
# 取得した記事数をもとにリクエスト回数を算出
page_count = math.ceil(total_count / 100)
print(search_date[0] + "のデータを取得します...")
print("この日に作成されたデータを取得するのに必要なリクエスト回数は" + str(page_count) + "回です")
# すべてのページのデータをまとめるための空のDataFrameを作成
all_data = pd.DataFrame()
all_data_page = pd.DataFrame()
#データを取得
for p in range(page_count):
p += 1
page = "page=" + str(p)
conn.request("GET", url + page + query, headers=h)
res = conn.getresponse()
print(res.status, res.reason)
data = res.read().decode("utf-8")
df = pd.read_json(data)
print(df)
# 'likes_count' 列で降順にソート
df.sort_values(by='likes_count', ascending=False, inplace=True)
# すべてのページのデータをまとめる
all_data_page = pd.concat([all_data_page, df], ignore_index=True)
print(f"{p}/{page_count}完了")
# すべての日付のデータをまとめる
all_data = pd.concat([all_data, all_data_page], ignore_index=True)
# すべてのデータを 'likes_count' 列で降順にソート
all_data.sort_values(by='likes_count', ascending=False, inplace=True)
#テキストに吐き出すやり方↓
filename = "./page" + str(ago7days_str) + "-" + str(page_count) + "-" + str(p) + ".txt"
all_data.to_csv(filename, encoding="utf-8", columns=[
'likes_count',
'created_at',
'title',
'url'
], mode='a', header=False, index=False)
print(str(p) + "/" + str(page_count) + "完了")
# 上位1位の記事をツイートする
top_data = all_data.head(1)
top_data_like = top_data['likes_count'].reset_index(drop=True)
top_data_cr = top_data['created_at'].reset_index(drop=True)
top_data_title = top_data['title'].reset_index(drop=True)
top_data_url = top_data['url'].reset_index(drop=True)
print(top_data_like)
# 余計なインデックスNoなどを削る
top_data_like_value = top_data_like.iloc[0]
top_data_cr_value = top_data_cr.iloc[0]
top_data_title_value = top_data_title.iloc[0]
top_data_url_value = top_data_url.iloc[0]
print(top_data_like_value)
try:
tweet_message = (
"1週間前のいいね数最上位の記事を紹介\n"
"いいね数:" + str(top_data_like_value) + "\n"
"作成日:" + str(top_data_cr_value) + "\n"
"タイトル:" + str(top_data_title_value) + "\n"
"URL:" + str(top_data_url_value) + "\n"
)
client.create_tweet(text=tweet_message)
print("ツイートしました:", tweet_message)
except Exception as e:
print("ツイートに失敗しました:", str(e))
最後に
色々と引っかかりながら作りました。。。以下ブログにはもう少し詳しく書いています。ご参考までに。
-
ブログ
Chat-GPTには大変お世話になりました。
追記 -23/12/14-
自宅PC上でタスクスケジューラを使って定期実行していましたが、ソフトウェアアップデートなどで止まることもありました。現在はGoogle Cloud上にデプロイして定期的に実行するように変更しています。
そちらに関しては、ちょっと細かい内容なので以下記事@個人ブログでまとめでいます。