前回の記事で Python(スクレイピング) + Influxdb + Grafana で作る、データの可視化について本記事で詳しく解説します。
なお、本記事は解説を目的とします。
"手順に"興味がある方はリポジトリのREADMEをご参照ください。
おさらい
前回記事の再掲。
- できあがった構成こんな感じ
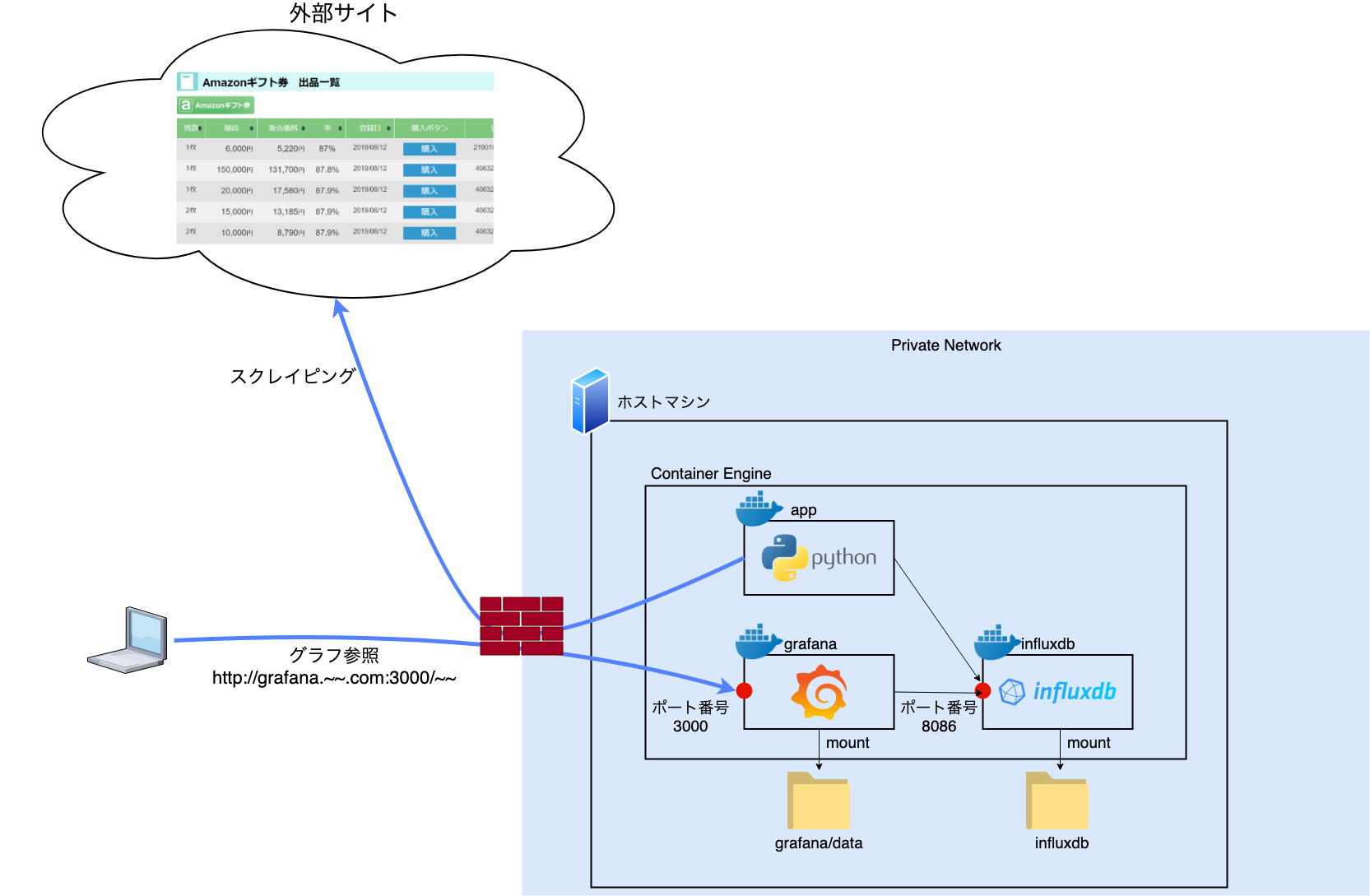
※だいたいの構成検討とかは通勤中に(頭の中だけで)練っていたので、手を動かし始めたら1日で作れました。
各コンテナの役割
- app: 30秒間隔でWebサイトをスクレイピングする。取得したデータを加工し、時系列DB(Influxdb)に格納する
- influxdb: OSSの時系列データベース(time series database)
- grafana: グラフ表示を担当
そもそも何を可視化するの?
Amazonギフト券を割安で買い付けられるサービスが存在します。
ギフト券を現金化したい売り手と、安く購入したい買い手とのマッチングサービスで、一種の市場を形成しているわけです。
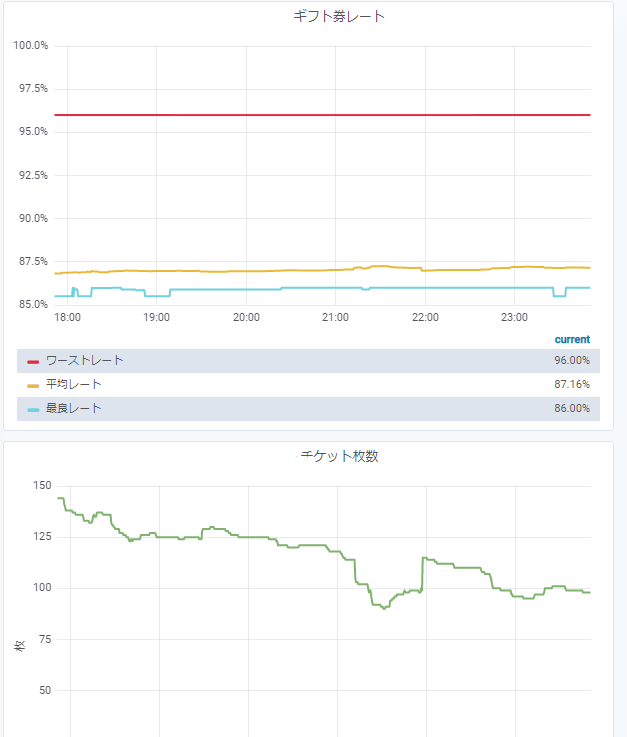
この市場を、株式市場や為替市場と同じようにチャート表示してみたい というのがモチベーションです。
実際に作ったのは以下のようなチャート描画です(グラフ表示はGrafana ですが)。
スクレイピング
前置き
こんな記事書いといてアレですが、スクレイピングという手法はあまり胸を張って良いものではないと考えてます(※個人の意見です)。
数十秒~数分間隔のスクレイピングならまだしも、ミリ秒レベルの間隔でなんか実行してしまうと「それDoSじゃん」と思ってしまいます。
したがって、本記事および成果物(Github)では 私が実際に実装したスクレイピングツールの宛先URLおよびサービスは晒しませんのでご理解お願いします。
スクレイピング実装
Pythonのurllib3とBeautifulSoup4を利用。これらを利用したスクレイピング自体については詳しく解説しませんのでググってください。
ここでは、本ケースで取得したいデータの前提を記載します。
まず、Webページ内に以下のような表(テーブル)があるとします。
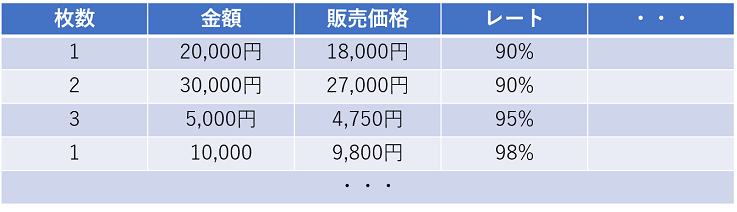
そして、このページ要素から以下のデータを集めることを考えます
- 最も安い販売レート(最良レート): best_rate
- レートの平均値: avg
- ワーストレート: worst_rate
- 総枚数: amount_sum
さて、htmlのテーブル要素の場合大抵以下のような構成になっていると思います。

ここでポイントとなるのは、HTMLにはタグとその階層構造があるということです。
表の行要素(黄色の部分)とセル要素(緑の部分)がそれぞれtrタグとtdタグにあたり、セル要素をforループで取得していきます。
今回取得したいのはギフト券のレートと枚数なので、for ループで全ての要素をした後 必要なデータを抜き出していく流れです。
以下がコードの抜粋です。
import urllib3
import certifi
from bs4 import BeautifulSoup
def scrape(url):
# HTTPリクエストを生成
http = urllib3.PoolManager(
cert_reqs='CERT_REQUIRED',
ca_certs=certifi.where()
)
# 対象URLをHTTP GETして保持
res = http.request('GET', url)
soup = BeautifulSoup(res.data, 'html.parser')
table_body = soup.select_one('#tbody1')
amounts = []
rates = []
for tr in table_body.find_all('tr'):
temp_list = []
for td in tr.find_all('td'):
temp_list.append(td.string)
amounts.append(int(temp_list[0].replace('枚', ''))) # "チケット枚数"リストに追加
rates.append(float(temp_list[3].replace('%', ''))) # "レート"リストに追加
# 最良レート、ワーストレート
best_rate = min(rates) ; worst_rate = max(rates)
# レート平均(重みつき)
avg = ...
return {'best_rate': best_rate, 'worst_rate': worst_rate, 'avg': avg, 'amount_sum': sum(amounts)} # チケット枚数の総量: sum(amounts)

「全ての要素をした後 必要なデータを抜き出して」いるのが以下の部分です。
amounts.append(int(temp_list[0].replace('枚', ''))) # "チケット枚数"リストに追加
rates.append(float(temp_list[3].replace('%', ''))) # "レート"リストに追加
取得データの書き込み
ここまででスクレイピングの実行およびデータ加工が完了しました。
続いて取得データをInfluxdbに書き込みすれば良いのですが、Pythonのライブラリが準備されています。
したがって何も難しいことなく実装できます。
なお、ここで書き込みを行う際にJSON形式のリクエストボディを生成するため、上述のスクレイピングの関数では辞書型オブジェクトを返すようにしています。
return {'best_rate': best_rate, 'worst_rate': worst_rate, 'avg': avg, 'amount_sum': sum(amounts)} # チケット枚数の総量: sum(amounts)
impoert os
from influxdb import InfluxDBClient
# influxdbへ書き込み処理を行う
def insert(measurement, values):
client = InfluxDBClient(
host=os.environ['INFLUXDB_HOST'],
port=os.environ['INFLUXDB_PORT'],
database=os.environ['INFLUXDB_DATABASE']
)
json_payload = [
{
"measurement": measurement,
"fields": values
}
]
client.write_points(json_payload)
書き込み先DBの情報は環境変数から取得します。
pythonが実行されるDocker コンテナの起動時に環境変数を定義するようDockerfile に記述します。
FROM docker.io/python:3.7.4-alpine3.10
RUN apk add --no-cache bash && \
pip3 --no-cache-dir install influxdb urllib3 beautifulsoup4 certifi
COPY ./main.py /app/main.py
ENV INFLUXDB_HOST="scraping_and_grafana_influxdb_1" \
INFLUXDB_PORT="8086" \
INFLUXDB_DATABASE="mydb"
コンテナ名や起動ポート番号を変更する場合は適宜変更してください。あとデータベース名("mydb")も同様。
Influxdbのススメ
Influxdbは時系列データベースです。
簡単なクエリ実行を例に動きを見てみましょう。
コンテナデータベース起動~データベース作成まで。
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
docker.io/influxdb 1.7 d1e103e42e17 4 weeks ago 258 MB
$ docker run -d --rm --name influxdb -p 8086:8086 docker.io/influxdb:1.7
7a554***
$ docker exec -it influxdb influx -precision rfc3339
Connected to http://localhost:8086 version 1.7.7
InfluxDB shell version: 1.7.7
> show databases
name: databases
name
----
_internal
> CREATE DATABASE sample_db
> SHOW DATABASES
name: databases
name
----
_internal
sample_db
> USE sample_db
Using database sample_db
テーブル作成~レコード挿入
ここで、Influxdbの用法について。
Influxdb では一般のRDBMSでいう所のTABLEをMEASUREMENTと呼称します。正にメトリクスと位置付けているんですね。
そして、挿入クエリの書式は以下。

(引用元: Influxdb and time series data - Slideshare)
面白いのは、レコードにおいてタグと値を分けています(「値」はVALUEと言うべきか、measurement と言うべきか...)。
タグは省略可能です。
テーブル名とタグはカンマ区切り、VALUEはスペースの後記述します。
また、InfluxdbではCREATE TABLE文も省略可能です(正しくはCREATE MEASUREMENT ですが)
> SHOW MEASUREMENTS
>
> INSERT cpu,host=A,region=tokyo usage=0.6,LA=0.3
>
> SHOW MEASUREMENTS # "CREATE MEASUREMENT"文は不要
name: measurements
name
----
cpu
> SELECT * FROM cpu
name: cpu
time LA host region usage
---- -- ---- ------ -----
2019-08-13T16:05:25.964591986Z 0.3 A tokyo 0.6
INSERT文で指定したVALUEはusage=0.6,LA=0.3のみでしたが、自動的にタイムスタンプが付与されているのが分かります。
Influxdbでは、基本的にこのtimeカラムをがキーの1つとなるように設計するとGoodだと思います。
データが取得出来たらGrafanaで可視化
割愛します。
プラグインを選択して進んでいくだけです。
まとめ
とりあえず今回は自宅の仮想サーバで実現しました。
今後の展望としては、お勉強として以下のことにも少しずつ挑戦できたら楽しいなと思ってます。
- 自動テストを組み込んでみる
- DBに書き込みしたデータの信頼性担保(EFSを利用?)
- コンテナオーケストレーションツールを組み合わせてみる