TL;DR
- Webページをスクレイピングしてデータを収集し、時系列データとして保持したものをgrafana でグラフ化してみました。
- Amazonギフト券を安く購入できるサービスがあり、そのギフト券のチケットレートを蓄積したら面白いなと思ったのがモチベーションです。
- できあがった構成こんな感じ
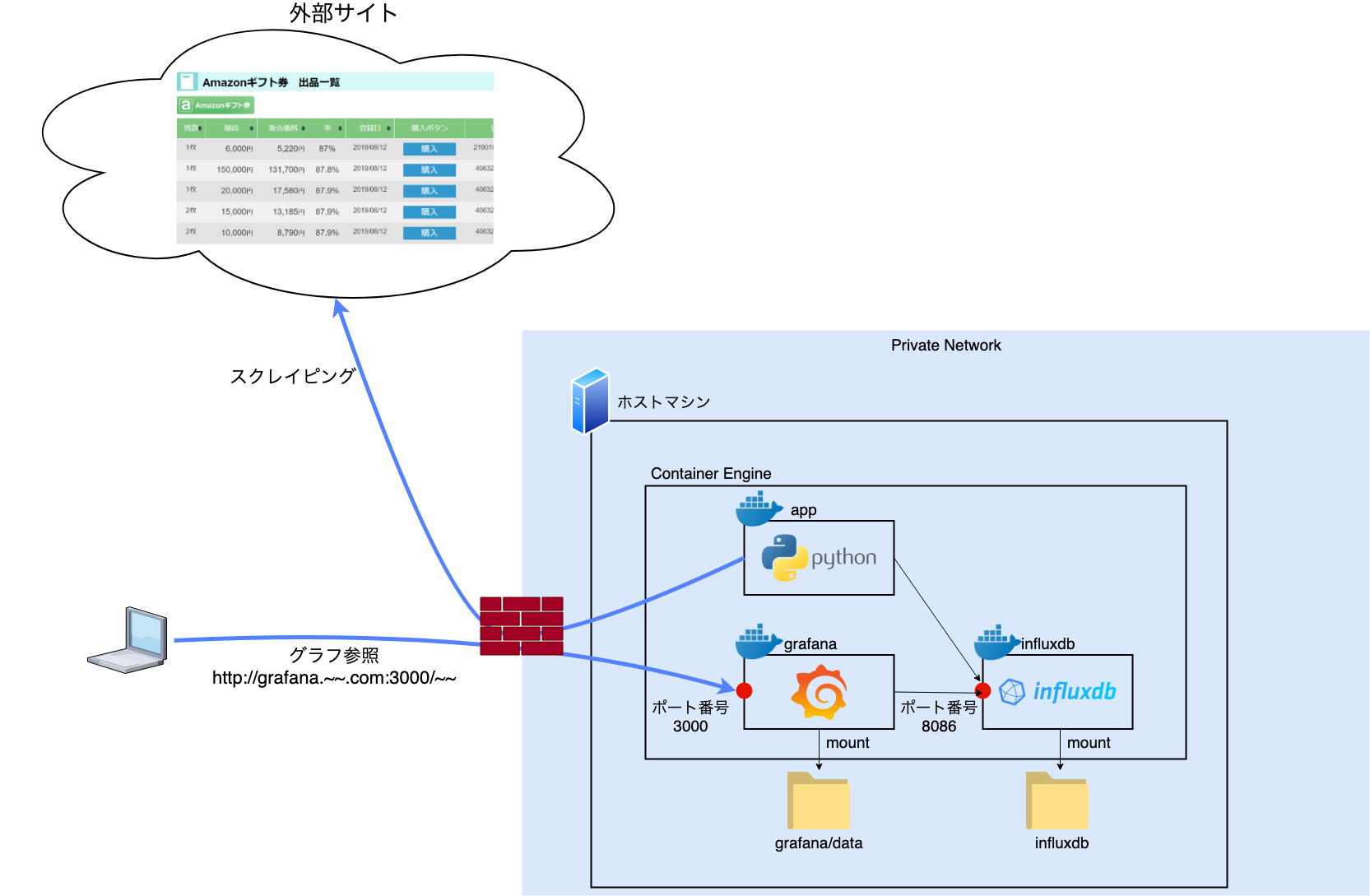
※だいたいの構成検討とかは通勤中に(頭の中だけで)練っていたので、手を動かし始めたら1日で作れました。
各コンテナの役割
- app: 30秒間隔でWebサイトをスクレイピングする。取得したデータを加工し、時系列DB(Influxdb)に格納する
- influxdb: OSSの時系列データベース(time series database)
- grafana: グラフ表示を担当
実現するにあたる検討

アイデアの着想から実現方式を考えてたことは以下のような感じ
- APIが無いサービスなので、スクレイピングは必須 → Pythonで(スクレイピングの実装経験もあった)。
- グラフ表示/可視化 はスクラッチ開発せずに得意なツールで行おう → grafanaで。
- スクレイピングで取得したデータはどう扱おう
- Amazon Cloudwatch?
- Amazon S3?
- 独自でリレーショナルDB?
データ保管方式について少し検討の期間を置こうと考えました。
grafana の豊富なプラグインに迷う
grafana はオフィシャルビルトイン、コミュニティ開発ともにプラグインが充実しており、やりたいことの実現はできるものの、数ある選択肢から何を選ぼうか迷いました

Cloudwatch カスタムメトリクスを本格利用するのは意外と高い
定期的(30秒毎 or 1分毎)に取得したメトリクスを時系列データとしてグラフ化したい場合、Cloudwatch ならとても簡単に実現できます。
データ保管とグラフ表示機能をCloudwatch で実現できるからです。
ここで、Cloudwatch の月額料金を試算してみます。
収集するメトリクス数
- 前提条件
- 30秒間隔でスクレイピングを実行して加工した結果、4つの値をメトリクスとして保持する
- サービスは6ヶ月以上継続するものとする
上記条件の場合、1ヶ月間で保存するメトリクス数は
4(メトリクス数) * 2(60秒 / 30秒) * 60(分) * 24(h) * 30(days) = 345,600
1ヶ月に34万以上の値を保持する必要があります。スクレイピングの間隔を倍にしても17万以上です。
Cloudwatch カスタムメトリクスの料金
2019/8 現在、東京リージョンの料金は以下
範囲 コスト (メトリクス/月)
最初の 10,000 メトリクス 0.30USD
次の 240,000 メトリクス 0.10USD
次の 750,000 メトリクス 0.05USD
1,000,000 を超えるメトリクス 0.02USD
上記より、
最初の10,000個のメトリクス: 0.3ドル * 10,000個 = 3,000 ドル
10,001 〜 240,000個 のメトリクス: 0.1ドル * 230,000個 = 23,000 ドル
240,001 〜 345,600個のメトリクス: 0.05ドル * 105,600個 = 5,280 ドル
計: 31,280ドル/月
!?!?!?!?!?!?
_人人人人人人人人人人人人人人人人人人人人人_
> 1ヶ月あたり3万ドル也 (しかも増額分が) <
 ̄Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y ̄
えぇ... (これ計算合ってる...? というか絶対違うような...)
Cloudwatch カスタムメトリクスは元データを長期間保持しない
衝撃的な金額を受け、「これ 自分の検討プランがおかしいんじゃないか」という発想にいたりAmazon CloudWatch の概念を読み込みました。
するとこんな記述が。
メトリクスの保持
CloudWatch には、メトリクスデータが次のように保持されます。・期間が 60 秒未満のデータポイントは、3 時間使用できます。これらのデータポイントは高解像度カスタムメトリクスです。
・期間が 60 秒 (1 分) のデータポイントは、15 日間使用できます。
・期間が 300 秒 (5 分) のデータポイントは、63 日間使用できます。
・期間が 3600 秒 (1 時間) のデータポイントは、455 日 (15 か月) 間使用できます。最初は短い期間で発行されるデータポイントは、長期的なストレージのため一緒に集計されます。
たとえば、1 分の期間でデータを収集する場合、データは 1 分の解像度で 15 日にわたり利用可能になります。
15 日を過ぎてもこのデータはまだ利用できますが、集計され、5 分の解像度のみで取得可能になります。63 日を過ぎるとこのデータはさらに集計され、1 時間の解像度のみで利用できます。
つまり、最初はこまめにデータを取得して保存していてもいずれデータが丸められ、保管しているメトリクス数が減っていくわけです。
とはいえ、毎月トータルで数十万のメトリクスを収集する費用は個人開発にはちと厳しいなと思いCloudwatch の利用はボツとしました。
また、期間が経過してもメトリクスを丸めないようにもしたいなと。
grafana のS3プラグインは用途が違う
grafana にプラグインが用意されているCloudwatch は不採用となりましたが、第2候補であったS3についてはプラグインが用意されてはいるものの、これは「S3サービス自体のメトリクス」に関するプラグインでした。
AWS S3 dashboardData for Grafana | Grafana Labs
Visualize AWS S3 metrics
またS3案の場合、オブジェクトキーやフォルダ階層の設計に加えWebアプリケーションの実装やライブラリを探す必要も出てくるため、ここはgrafana にプラグインのある他の選択肢を検討することとしました。
時系列DB、Influxdb

grafana のData Sourceプラグインの一覧を上位の方から調べていったところ、割と上位にあったInfluxdb が良さそうでした。公式のビルトインプラグインであったのもGood でした。
これは時系列DBという位置づけのツールで、メトリクス値の格納時に自動でタイムスタンプを付与してくれます。
Cloudwatch メトリクスのように、サーバリソースの収集や日々の気温/湿度など、まさに「時系列データ」の保管にピッタリでした。
grafana 同様、Dockerコンテナイメージも用意されており、もうこれで構成の検討は完了。
まとめ
というわけで、今回は全てオンプレ(自宅の仮想サーバ)で実現しました。
もう少しAWSマネージド機能やDBコンテナのデータ永続化については勉強がてら色々試行錯誤したいですね。
後編記事にて続きの細かいことを記載していこうと思います~~(忘れなければ)~~。
⇒書きました:②構築編
※Github
skokado / scraping_and_grafana