株式会社RevCommでエンジニアをしている skokado(@_skokado)といいます。
2024年10月27日から28日にかけて行われたPyCon JP 2024で登壇してきました。

発表内容
タイトルは『Rustを活用したPythonライブラリの開発』でした。
https://2024.pycon.jp/ja/talk/7GPRYL
発表資料:
多くの方にお越し頂きありがとうございました。

Rust (PyO3) ベンチマークの追加検証
発表後、質疑応答の時間で多くの質問を頂きました。
特に途中に説明したベンチマーク比較について、詳しい方から質問を頂いたり発表後詳しくお話しすることができ、私自身かなり勉強させて頂けました。
少し追加検証してみたので、それについて記します。
Cython と Rust (PyO3) の性能比較について
「ベンチマーク結果は Python < Rust < Cython」と話しました。
特に "Rust < Cython" の要因として「Cython と PyO3 の成熟度の違い」と説明しました。
後から検証した結果、これはベンチマークに用いたサンプルコードに対してCythonが特に最適化されている可能性が高いことが分かりました。
最適化も "成熟度" の一つに含まれるかもしれませんが、補足しておきます。
対象のベンチマークはこちらの「L2ノルムを計算する関数」です(Link)
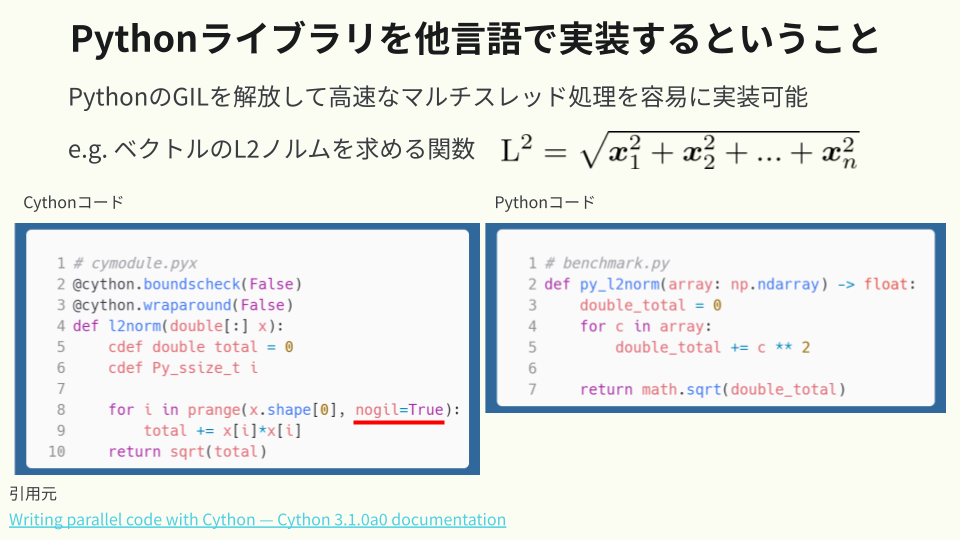
Cython (GIL なし)の関数を追加検証したところ、以下の実行結果を得ました。
| n (配列長) | 所要時間 (sec) |
|---|---|
| 1000 | 0.023 |
| 10000 | 0.0029 |
| 100000 | 0.0148 |
| 1000000 | 0.0009 |
| 10000000 | 0.0036 |
追加検証スクリプト
import random
import timeit
import numpy as np
import cymodule
def init_array(length: int) -> np.ndarray:
return np.array([
round(random.random() * 100, 2)
for _ in range(length)
])
repeat = 4
print("n,duration")
for exp in range(3, 7 + 1):
n = pow(10, exp)
arr = init_array(n)
dur = timeit.timeit(lambda: cymodule.l2norm(arr), number=repeat)
dur = round(dur / repeat, 4)
print(f"{n},{dur}")
つまり所要時間が配列長に依らずほぼ O(1) であり、何らかの最適化が働いている可能性が高いです(SIMDが関係している? とか?)
なお、ビルドのオプションには -O3 が含まれていました。
https://clang.llvm.org/docs/CommandGuide/clang.html#cmdoption-O0
$ cd c_api_cython
$ pip3 install . -v
...
building 'cymodule' extension
clang -pthread -fno-strict-overflow -Wsign-compare -Wunreachable-code -DNDEBUG -g -O3 -Wall -fPIC -fPIC -I/path/to/.venv/include -I/path/to/python/3.12/include/python3.12 -c cymodule.c -o build/temp.linux-x86_64-cpython-312/cymodule.o -fopenmp
また筆者の検証環境ツールのバージョンは以下の通りでした。
- Python: 3.12.6
- clang: 18.1.3
- OpenMP (libomp-dev): 1.18.0
- Cython: 3.0.11
今の私ではこれ以上詳しく調査できなさそうなので、追加検証としてはここまでに留めておきます(詳しい方いたらぜひ教えてください🙏)。
追加ベンチマーク (素数計算)
ベクトル演算における最適化の性能影響を無くすため、素数を計算するアルゴリズムをベンチマーク例にした追加検証を実施してみました。
- エラトステネスの篩
- 愚直方式
それぞれ Python で実装したコードは以下です。
def eratosthenes(limit: int) -> list[int]:
prime_flags: list[bool] = [True for _ in range(limit + 1)]
p = 2
while p ** 2 <= limit:
if prime_flags[p]:
for i in range(p ** 2, limit + 1, p):
prime_flags[i] = False
p += 1
primes: list[int] = [p for p in range(2, limit) if prime_flags[p]]
return primes
def get_primes(max: int) -> list[int]:
# n以下の素数一覧を返す愚直な実装
primes = [2]
for n in range(3, max + 1, 2):
i = 3
while i * i <= n:
if n % i == 0:
break
i += 2
else:
primes.append(n)
return primes
上記と同様のアルゴリズムをCython, Rustでも実装してベンチマークを計測しました。
他のコードはGitHubをご覧ください。
https://github.com/skokado/speak/tree/v2024.10.01/pycon-jp-2024/sample-codes/benchmarks
- エラトステネスの篩
※所要時間は (sec)
| limit | Python | Cython | Rust (PyO3) |
|---|---|---|---|
| 1000 | 0.0 | 0.0 | 0.0 |
| 10000 | 0.0 | 0.0 | 0.0 |
| 100000 | 0.01 | 0.0 | 0.0 |
| 1000000 | 0.09 | 0.05 | 0.01 |
| 10000000 | 1.06 | 0.62 | 0.05 |
| 100000000 | 12.29 | 7.61 | 0.96 |
PyO3 < Cython < Python
- 愚直方式
Cython ≒ PyO3 < Python
| max | Python | Cython | Rust (PyO3) |
|---|---|---|---|
| 1000 | 0.0 | 0.0 | 0.0 |
| 10000 | 0.0 | 0.0 | 0.0 |
| 100000 | 0.06 | 0.01 | 0.01 |
| 1000000 | 1.93 | 0.15 | 0.16 |
| 10000000 | 55.5 | 4.14 | 4.18 |
上記の例なら総じて Rust (PyO3) が高速であることが分かりました!🦀
終わりに
嬉しいことに昨年のPyCon APAC 2023に引き続きの登壇でした
PyCon APAC 2023に参加&登壇してきました
発表の中でベンチマークに触れたことで多くの質問、コメントを頂けて私自身の勉強につながりました。
ベンチマークネタには知見が集まる。
— skokado (@_skokado) September 28, 2024
みんなもベンチマーク測ってPyConで話すんだよ?いいね?#pyconjp2024
こちらこそ興味深い話ありがとうございます。Rust+Pythonやってみようかなという気になりました。最後コメントしようとしてできなかったんですが、処理速度の話は、バインディングシステムの速度の話と言語特有の速度の話が混ざっているような気がしたのでうまく分離できるといいかなと思いました。
— 加藤公一(はむかず) (@hamukazu) September 30, 2024
RustのPyO3とCythonでCythonのほうが速いと登壇でお話がでていて、どういうバイナリコードが吐かれているのか見てみようと思いました。
— 小清水さん Recustomer CTO (@curekoshimizu) September 28, 2024
スポンサー、参加者、運営スタッフの皆さん、そして会場で話してくださった方々に改めて感謝申し上げます。
終わりに (2)
今月の PyCon APAC 2024 でも登壇してきます!🦀
