はじめに
業務でAWS S3上にデータレイク開発を行っています。
プロダクトで使用しているDBからS3へのデータの同期は、AWS Glueで、DBからdynamic frameを読み込み、S3に保存するジョブを実行することで実現しています。
今回上記のやり方でDBで使用しているあるテーブル(データサイズが約40GB)を読み込んでS3に保存しようとした場合、膨大な時間がかかったうえ、途中でエラーで落ちてしまいました。
原因をさぐる
Glueのジョブがどのように実行されているかを知るためにまずはSpark UIで確認します。
Spark UIの構築方法は下記の通りです。
リポジトリクローン
git clone https://github.com/aws-samples/aws-glue-samples/
コピーしてきたフォルダのうち./utilities/SparkUI/glue-1_0-2_0以下にDockerfileがあるため適当なフォルダにコピー、フォルダ内でビルドする
docker build -t glue/sparkui:latest .
環境変数(git bash @Win上ではAWSの認証情報を直接入れる方法でうまくいった)を設定します。
LOG_DIR="s3a://バケット名/sparkHistoryLogs/"
AWS_ACCESS_KEY_ID="xxxx"
AWS_SECT_ACCESS_KEY="xxxx"
コンテナ起動、ちなみにWin上ではReadMe通りではうまくいかず、下記のようにコマンドの冒頭にバックスラッシュを入れる必要があります。
docker run -itd -e SPARK_HISTORY_OPTS="$SPARK_HISTORY_OPTS -Dspark.history.fs.logDirectory=$LOG_DIR -Dspark.hadoop.fs.s3a.access.key=$AWS_ACCESS_KEY_ID -Dspark.hadoop.fs.s3a.secret.key=$AWS_SECRET_ACCESS_KEY" -p 18080:18080 glue/sparkui:latest "\/opt/spark/bin/spark-class org.apache.spark.deploy.history.HistoryServer"
以下のような感じで一つのジョブに対して、さらに細かいジョブの一覧や各ジョブの詳細がみることができます。
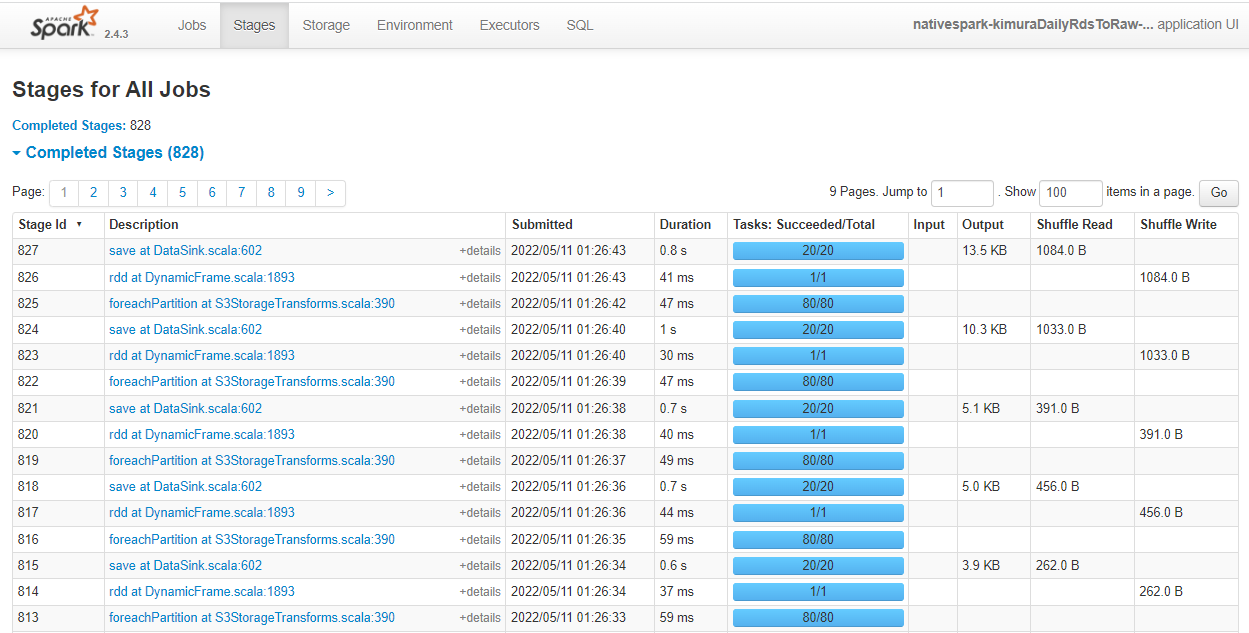
RDSからS3にカタログのあるテーブルをコピーするジョブの場合、
foreachPartition at S3StorageTransforms
rdd at DynamicFrame →読み込み?
save at DataSink →S3に書き込み?
というタスクが実行されているようです。
このうちsave at DataSink以外は一つのExecutorで実施しており、特に読み込み時は非常に時間がかかっていました
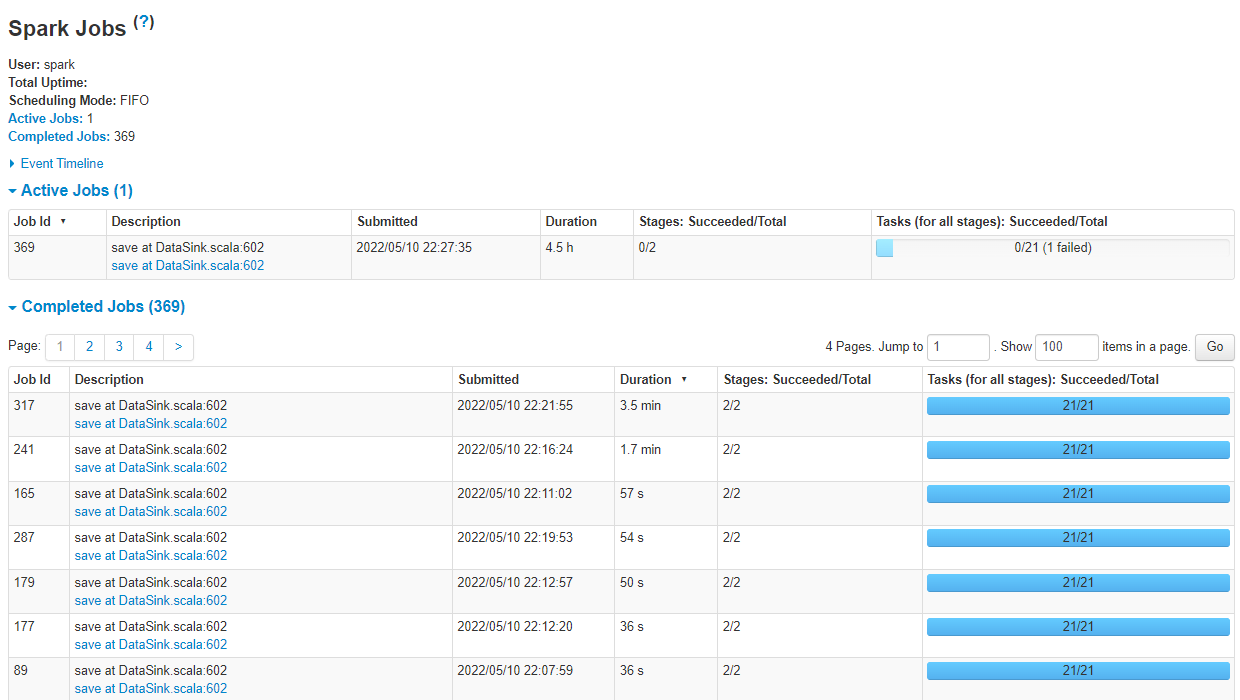
ちなみに失敗したタスクの詳細
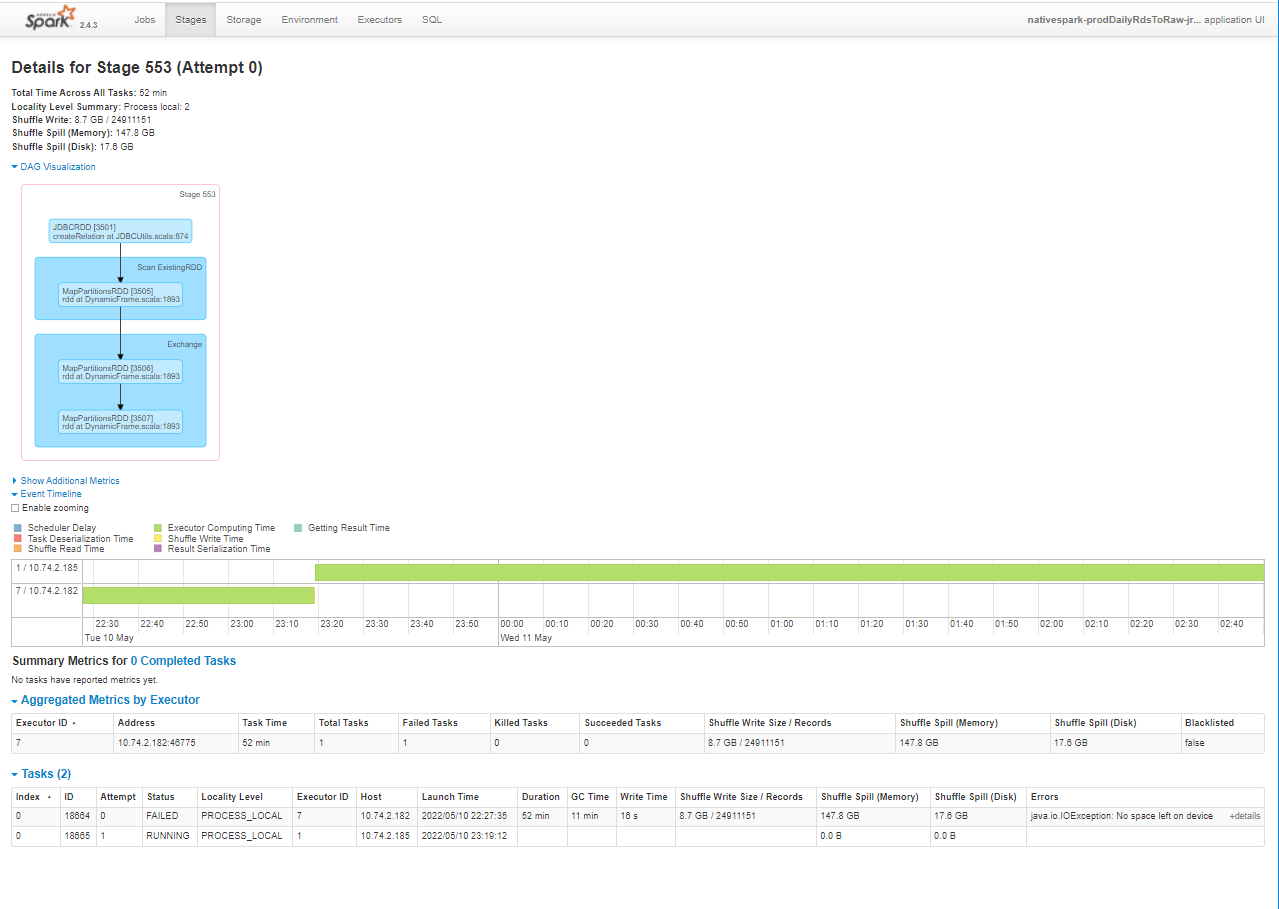
対策1. dynamic_frameの読み込みを並列化する
DBからの読み込みが明らかにボトルネックになっていることがわかったため、並列して読み込むように変更します。
AWSのドキュメントを参考に、下記のようにcreate_dynamic_frame_from_catalogに以下のオプションを設定します。
df = glueContext.create_dynamic_frame.from_catalog(
database=db_name,
table_name=table_name,
additional_options={"hashfield": hashfield},
)
hashfieldには任意の型のカラムが指定できます。(含まれないテーブルは従来通りaddtional_optionsを使わずに読み込み)
その結果、数時間経っても完了しなかったジョブがエラーで落ちることなく、30分程度で完了できました。
対策2. hashfieldで指定するカラムを変更する
ところが、よくよく確認してみると、他のテーブルの読み込み時にエラーは発生していないが、読み込んだdynamic frameが0行(ヘッダのみ)となっているものがありました。
読み込みがうまくいかなった要因を調べた結果、指定したカラムがNULL値を含むカラムとなっているケースで発生していました。(NULL値となっている行は読み込まれないようです)
よって、読み込み並列化時に指定するカラムはNot NULL制約となっているカラムとしたほうがよさそうです。
まとめ
AWS Glueでサイズの大きいデータをカタログ経由で読み込む際には並列化を活用しましょう、またその際にはNULLが含まれないカラムを指定しましょうというお話でした。
参考にさせていただいたページ
https://qiita.com/pioho07/items/c4638504a2b134af88de
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/run-jdbc-parallel-read-job.html