はじまり
IBMのHadoopソリューションのBigInsightsはSparkを含んでいるが、プログラミングの負荷を下げるための開発環境は別途用意する必要がある。
Spyderは簡単に言うと、オープンソースの統合開発環境。
詳しくは以下を参照:
https://ja.wikipedia.org/wiki/Spyder_(%E3%82%BD%E3%83%95%E3%83%88%E3%82%A6%E3%82%A7%E3%82%A2)
今回は、Redhat7.2で構築したBigInsightsを対象に、Spyderを導入してSparkのプログラミングをする環境設定を行う。
Spyderのインストール
Redhat7系の場合インストールは非常に簡単。
まずは安心と信頼のEPELリポジトリの導入。追加パッケージはだいたいこのリポジトリ。
$ yum install epel-release
spyder実行に必要となる依存ソフトウェアのインストールを実施しておく。
$ yum install qt qt-devel qt-doc PyQt4 PyQt4-devel qtwebkit PyQt4-webkit
pipのインストール
$ wget https://bootstrap.pypa.io/get-pip.py
$ python get-pip.py
Spyderのインストール
$ pip install spyder
確認
$ spyder -help
Usage: spyder [options] files
Options:
-h, --help show this help message and exit
--new-instance Run a new instance of Spyder, even if the single
instance mode has been turned on (default)
--defaults Reset configuration settings to defaults
--reset Remove all configuration files!
--optimize Optimize Spyder bytecode (this may require
administrative privileges)
-w WORKING_DIRECTORY, --workdir=WORKING_DIRECTORY
Default working directory
--show-console Do not hide parent console window (Windows)
--multithread Internal console is executed in another thread
(separate from main application thread)
--profile Profile mode (internal test, not related with Python
profiling)
--window-title=WINDOW_TITLE
String to show in the main window title
-p OPEN_PROJECT, --project=OPEN_PROJECT
Path that contains an Spyder project
実際に起動する
$ spyder
便利な世の中になったね
Sparkプログラミングをしてみる
Sparkを動かすのも特に考える必要はない。普通にimportして使うだけ。
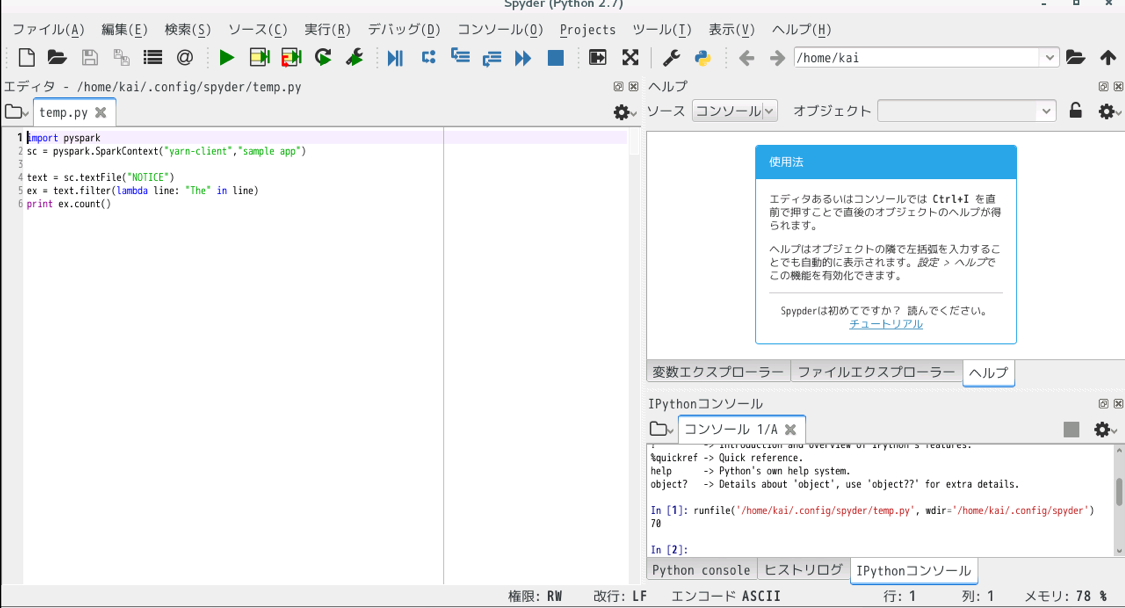
Spark Historyで確認

エラーがでたら
- import pysparkでno such module エラー
環境変数をセットする必要がある。今後のために.bashrcに追加しておく。
export SPARK_HOME=/usr/iop/current/spark-client
export PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.9-src.zip:$PYTHONPATH
- HDFSファイルパーミッションエラー
HDFSを見に行っているので/user/username/ ディレクトリがあるか確認。あればパーミッションが正しくセットされているかを確認。
お疲れ様でした。