 はじめに
はじめに
生成AIを業務で活用する上で、避けて通れないのが「ガバナンス」と「監査可能性」
特に企業環境では、「誰が・いつ・どんなプロンプトを入力し、どんな応答を得たのか」を後から追跡できる構成が求められます。
本記事では、個人的な学習の一環として、AWSのマネージドサービスだけで“監査可能なAIエージェント”を構築できるか試してみた結果をまとめます。
1. 概要:なぜ“監査可能なAI”が必要か
生成AIは便利な一方で、
- 社内情報の誤入力(プロンプトリーク)
- 不適切な出力や幻覚(ハルシネーション)
- 誰が何をしたのか追えない不透明性
といったリスクが常に存在します。
これをAWS環境内でどう抑止し、「安全に使える+監査できるAIシステム」 を実現できるかを考えました。
2. 全体アーキテクチャ構成
AWS上での設計方針は、以下の3層構造です。
| レイヤー | 主な役割 | 主なサービス |
|---|---|---|
| Control Layer(制御層) | 入力受付・制御 | API Gateway / Lambda / Step Functions |
| Safety Layer(安全層) | 入出力の安全検査 | Comprehend / Bedrock / Guardrails |
| Audit Layer(監査層) | ログ・可視化・監査 | CloudTrail / S3 / Athena / QuickSight |
図1:AWS上で“監査可能なAIエージェント”を設計する(全体構成)
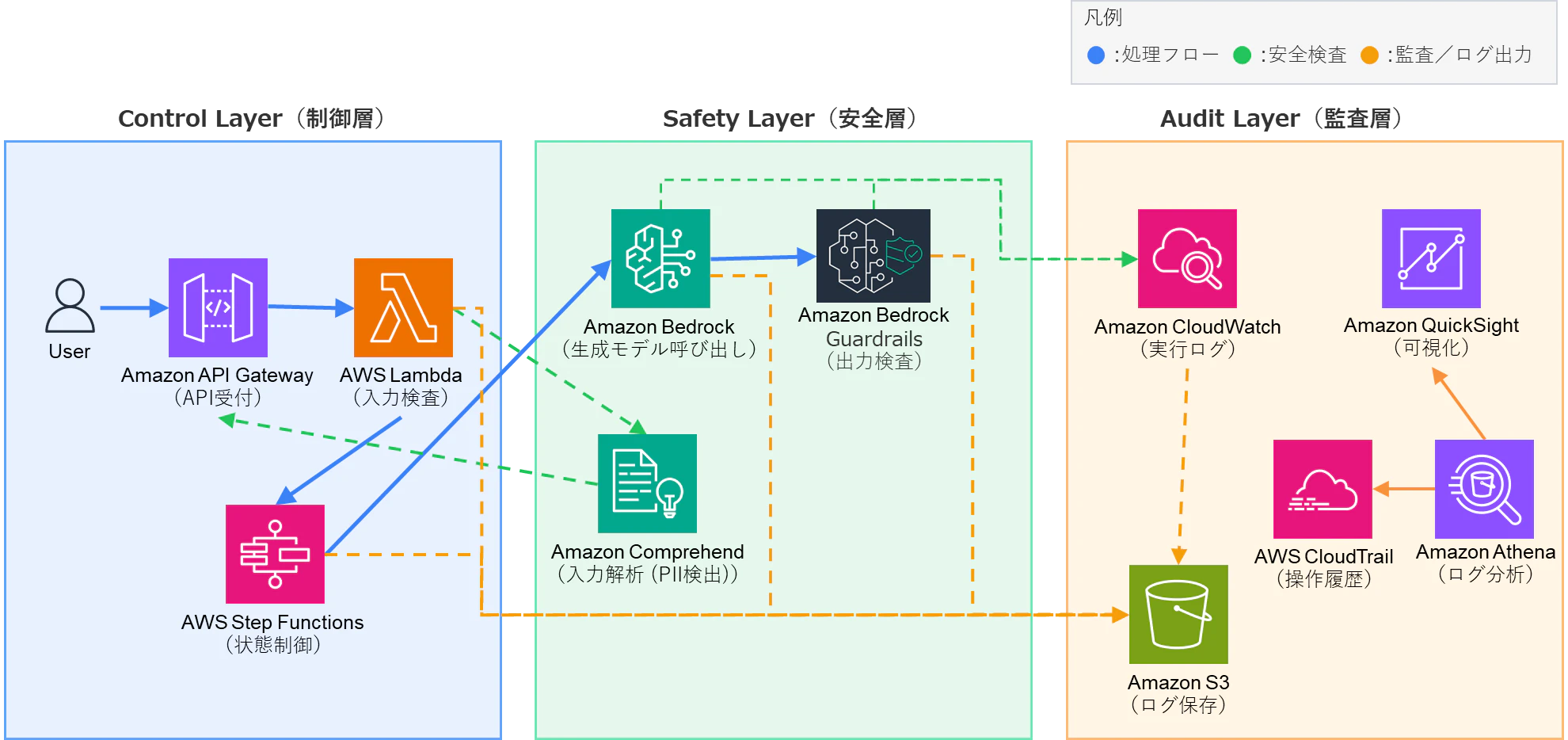
各レイヤーは疎結合に設計しており、安全制御や監査基盤を独立してスケールさせられる構成になっています。
3. Safety Layer(安全層):Comprehend+Guardrailsによる入出力検査フロー
生成AIの安全設計の中核を担うのが Safety Layer です。
Amazon Bedrockが生成を担い、入力・出力の前後で検査を行います。
 入力検査(Pre-check)
入力検査(Pre-check)
- Lambdaが入力を受け取ると、Amazon Comprehend の detect_pii_entities API で文中のPII(個人情報)を検出
- 該当箇所をマスクしてからBedrockに渡す
 出力検査(Post-check)
出力検査(Post-check)
- Bedrockの生成結果を Guardrails で評価
- 不適切な語彙やセンシティブコンテンツを自動遮断
- フィルタ結果はCloudWatch LogsおよびS3に送信
図2:Comprehend+Guardrailsによる入力・出力検査フロー
(入力前にComprehendで文脈解析し、出力後にGuardrailsで検証する)
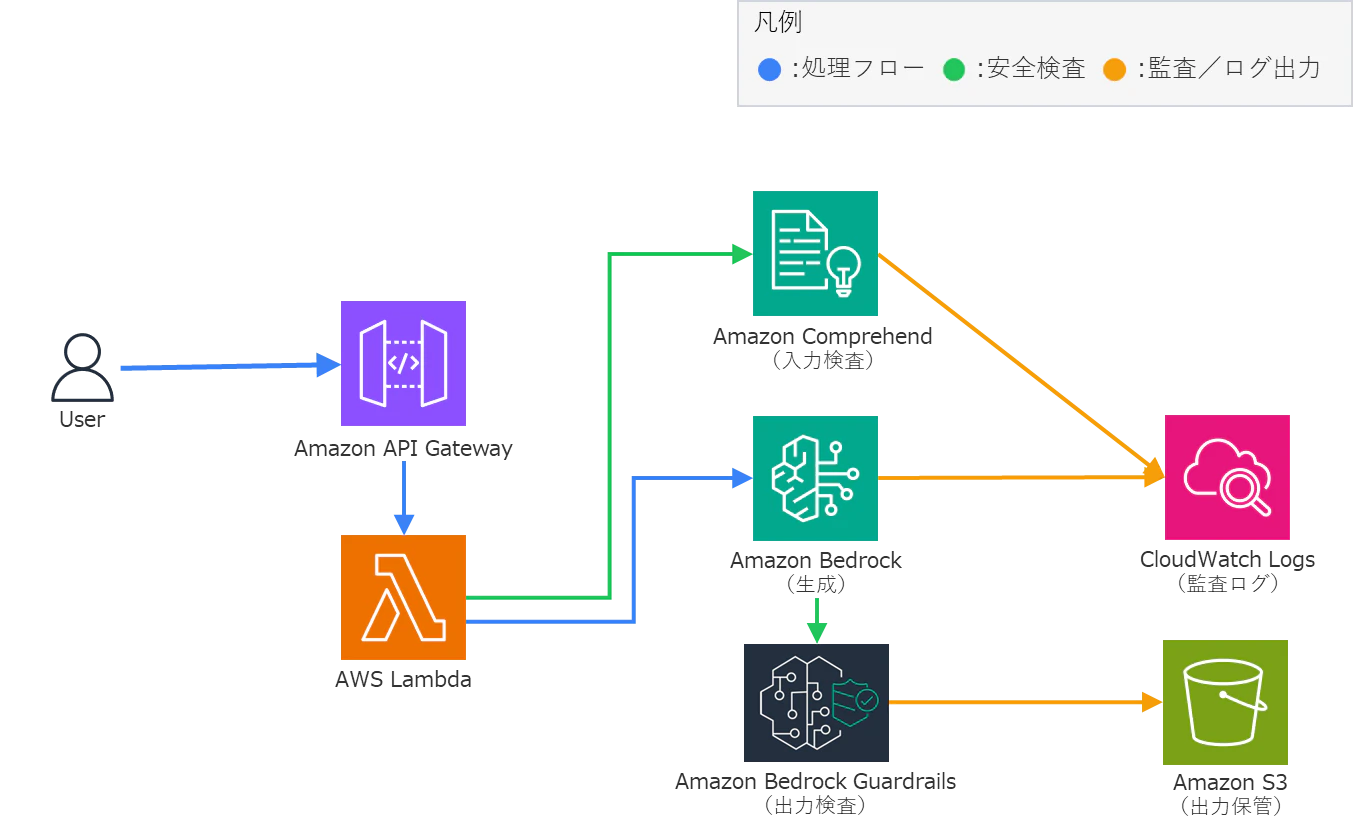
この構成により、プロンプト入力時点での漏えいリスクを低減し、出力時点では組織ルールに反する応答を自動制御できます。
 簡易検証:入力/出力フィルタリングの動作確認
簡易検証:入力/出力フィルタリングの動作確認
動作を確かめるために、テスト用の短文をいくつか通して挙動を比較してみました。
入力側では Amazon Comprehend の detect_pii_entities API を使用し、
以下のような文を検出対象に設定しています。
| 入力文 | 検出対象 | 検出結果 |
|---|---|---|
| “田中太郎の電話番号は090-xxxx-xxxxです” | 電話番号/人名 |
|
| “This is internal project X info” | 機密語句 |
|
| “Sample text without PII.” | — |
|
出力側では Bedrock Guardrails に独自ルールを設定し、特定の単語(例:「password」「secret」「internal」など)を含む応答をブロックするポリシーを適用。
試行の結果、Guardrailsがブロックログを返すケースを CloudWatch で確認できました。
※定量的な精度検証までは行っていませんが、PIIとポリシーベース検知の基本動作は問題なく確認できました。
 設計上の意図とトレードオフ
設計上の意図とトレードオフ
構成を検討する際、Comprehendを入力検査(Pre-check) 、 Guardrailsを出力検査(Post-check) に分離した理由は次の通りです。
| 要素 | 検討対象 | 採用判断 |
|---|---|---|
| Comprehendの位置付け | Bedrock呼び出し前に実行し、個人情報や社外秘ワードを遮断 | 入力前に動作させることで“情報漏えい防止”を優先 |
| Guardrailsの位置付け | 生成後の出力をポリシーで検査 | 出力の一貫性よりも“外部発信リスクの低減”を優先 |
| トレードオフ | 処理遅延が平均 +150〜250ms 発生 | 低遅延よりも安全性重視で妥協 |
結果としてトータルレイテンシは若干増えましたが、安全検査を両方向に分離することで、「前段:入力の守り」と「後段:出力の守り」を明確に定義しました。
4. Audit Layer(監査層):Athena+QuickSightによる監査ログ可視化
Safety Layerで得た検査結果や生成履歴を可視化・監査するのが Audit Layer です。
生成ログやプロンプト履歴はCloudTrail/CloudWatch経由でS3に集約し、Athena+QuickSight で分析・可視化します。
手順イメージ:
- CloudTrail/CloudWatch Logs を S3 バケットへエクスポート
- AWS Glue Crawlerでテーブルスキーマを自動生成
- AthenaでSQLクエリを発行し、プロンプト単位で分析
- QuickSightで可視化・ダッシュボード化
図3:Athena + QuickSight による監査ログ可視化の分析フロー
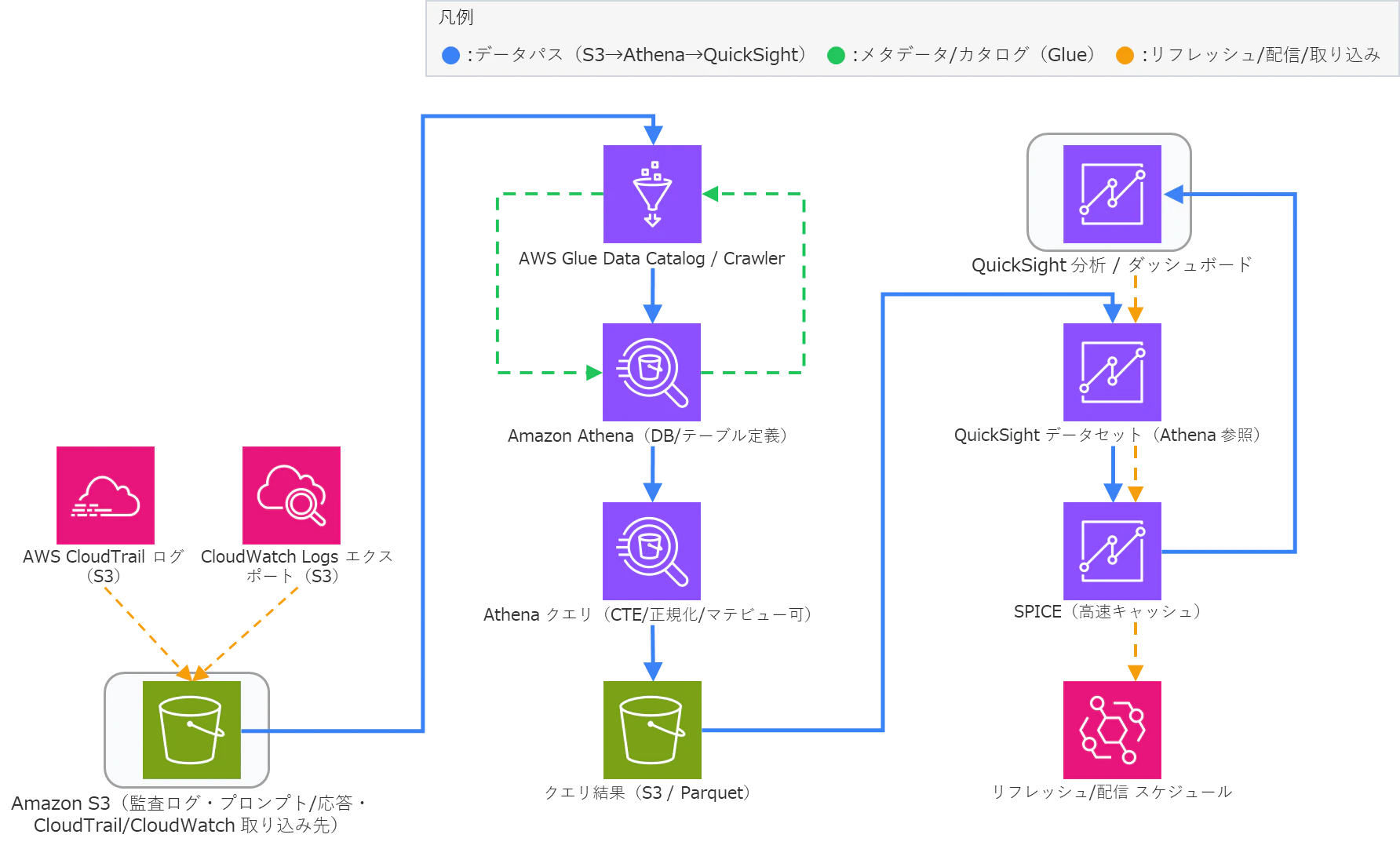
この構成により、「誰が・いつ・どんな入力を行い、どのような出力が得られたか」を可視化できます。
Athenaでのクエリ定義を工夫すれば、例えば「NGワード検知回数」や「Guardrails発動率」なども追跡可能です。
5. Control Layer(制御層):リクエスト制御の最小構成
Control Layerでは、ユーザーからの入力を安全に受け取り、検査・生成・記録の一連フローをオーケストレーションします。
構成要素:
- API Gateway:HTTPSエントリーポイント
- Lambda:Comprehend・Bedrock呼び出し処理
- Step Functions:各処理を順序制御
この設計により、Bedrockの呼び出し前に安全チェックを挟めるだけでなく、異常検知時にログのみ記録して出力を遮断する、といった分岐も簡単に組み込めます。
6. 今回の検証を通じて感じたこと
実際にAWSサービスを組み合わせてみると、ガバナンス・安全性・可視化 の3点を「全マネージドで実現できる」ことが分かりました。
一方で、ComprehendやGuardrailsの検出ポリシーはカスタマイズの余地があり、今後は社内用語や業界固有語 を学習させる仕組み(カスタム辞書など)を検討したいところです。
7. まとめ
- Comprehend:入力前の文脈検査で情報漏えいを防止
- Guardrails:出力後の応答検査で不適切表現を抑止
- CloudTrail × Athena × QuickSight:生成ログを監査可能に可視化
AWS上のマネージドサービスだけでも、ここまで“監査可能なAIエージェント”に近い構成を実現できました。
AWSのサービス設計を工夫すれば、個人レベルでも安心して試せる実装が可能だと感じました。