はじめに
ネットワークデータ(グラフデータとも呼ばれる)に対し、ノードやエッジ、サブグラフなどの分散表現を得る手法をNetwork Embeddingと言います。2014年にKDDにてDeepWalkという手法が提案されてから、様々な手法が提案されるようになりました。
最近の手法ですと、CNNやLSTMなどの深層学習のモデルを用いる動きや、多様なノード・エッジで構成されるHeterogeneous networkに対して適用するモデルなどが開発されてます。
今回は、それらの手法が開発される契機となったDeepWalk[1]について紹介します。
Deep Walkとは?
Deep Walkはネットワークにおけるノードの分散表現を得る手法であり、Word2vecのSkip-gramモデル[2]のアイディアを基にしています。
Deep Walkでは、あるノードvi を始点として、ノード間のリンクをたどるランダムウォークを行います。そこで得たシーケンスWvi をSkip-gramのインプットとし、隣接関係から適切な分散表現を学習します。
自然言語処理と対比させると、
ボキャブラリV = 全ノード
コーパス = ランダムウォークにより得られたシーケンスWvi
となります。
Deep Walkによって、ネットワークからベクトル表現への変換が以下の図のように行われます。
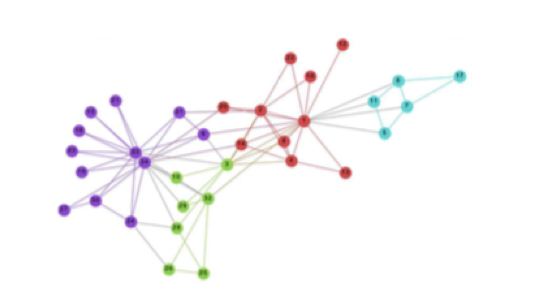
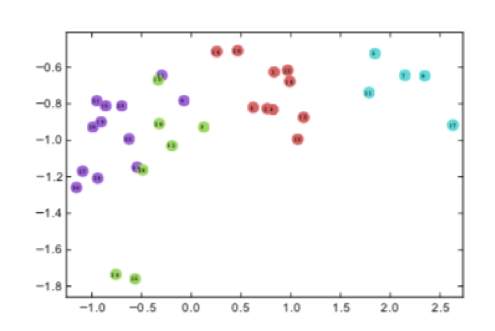
from Karate club
Deep Walkの性能評価
論文では、データセットとしてBLOG CATALOG[3]、FLICKER[4]、YOUTUBE[5]を用いています。各々のデータにはアニメやレスリングなどのような多クラスのラベルが割り当てられています。ここでは、ノードのカテゴリ分類問題をときます。Deep Walkでは、ノードの分散表現を得るだけなので、別途分類ためのアルゴリズムが必要です。
分類のアルゴリズムは一対他のロジスティック回帰を利用しています。
評価指標は、Micro-F1とMacro-F1を使用しております。多クラス問題においてはF値に多数の種類あり、前述の二つの一種です。データセットによる二つの指標の違いは、こちらの記事がわかりやすいです。
https://qiita.com/TaskeHAMANO/items/120cabf01b299b8f35ce
比較手法として、SpectralClustering[6]、Modularity[7]、EdgeCluster[8]、wvRN[9]、Majority(トレーニングデータセットの多数派をそのまま予測に用いる)を用いています(それぞれのアルゴリズムについては参考文献を参照してください)。
DeepWalk以外は、embeddingを利用せず、ネットワークデータからそのまま分類を行う手法です。
個人的興味から、YOUTUBEの結果を紹介します。YOUTUBEのデータセットが大きすぎて、SpectralClustering、Modularityは適用できなかったみたいです。
結果は以下の通りです。
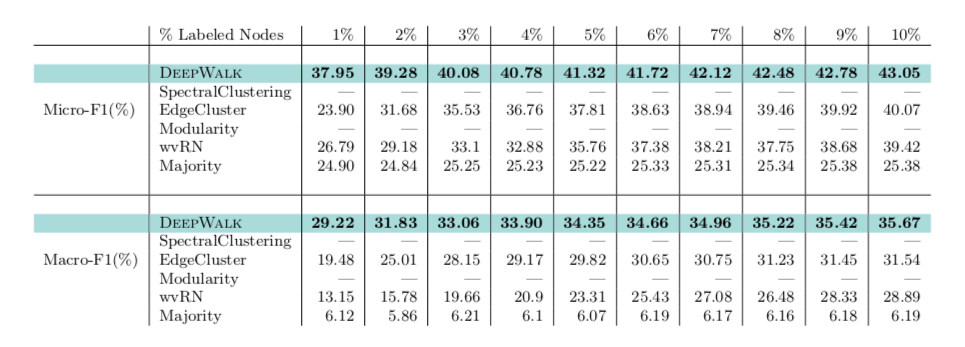
from Deep Walk
Labeled Nodesは、トレーニングデータの割合で、その他をテストデータとしています。
いずれの場合もDeep Walkが最もよい性能を発揮しております。
YOUTUBEのデータが47ラベルあることを考慮すると、トレーニングデータが小さい時も、ある程度の性能が期待されるようです。
まとめ
・ネットワークにおいても埋め込みの手法が使われ、大きなブレイクスルーが起きた。
・ノードを分散表現することで機械学習のタスクを扱うことができる。
・Deep Walkを端緒とし、様々な埋め込み手法が提案されている。
参考文献
[1] PEROZZI, Bryan AL-RFOU, Rami SKIENA, Steven. Deepwalk: Online learning of social representations. Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2014. p. 701-710.
[2] T. Mikolov, I. Sutskever, K. Chen, G. S. Corrado, and J. Dean. Distributed representations of words and phrases and their compositionality. In Advances in Neural Information Processing Systems 26, pages 3111–3119. 2013.
[3] L. Tang and H. Liu. Relational learning via latent social dimensions. In Proceedings of the 15th ACM SIGKDD, KDD ’09, pages 817–826, New York, NY, USA, 2009. ACM.
[4] L. Tang and H. Liu. Relational learning via latent social dimensions. In Proceedings of the 15th ACM SIGKDD, KDD ’09, pages 817–826, New York, NY, USA, 2009. ACM.
[5] L. Tang and H. Liu. Scalable learning of collective behavior based on sparse social dimensions. In Proceedings of the 18th ACM conference on Information and knowledge management, pages 1107–1116. ACM, 2009.
[6] L. Tang and H. Liu. Leveraging social media networks for classification. Data Mining and Knowledge Discovery, 23(3):447–478, 2011.
[7] L. Tang and H. Liu. Relational learning via latent social dimensions. In Proceedings of the 15th ACM SIGKDD, KDD ’09, pages 817–826, New York, NY, USA, 2009. ACM.
[8] L. Tang and H. Liu. Scalable learning of collective behavior based on sparse social dimensions. In Proceedings of the 18th ACM conference on Information and knowledge management, pages 1107–1116. ACM, 2009.
[9] S. A. Macskassy and F. Provost. A simple relational classifier. In Proceedings of the Second Workshop on Multi-Relational Data Mining (MRDM-2003) at KDD-2003, pages 64–76, 2003.