目次
クエリが実行される流れ
クエリ実行の基本的な流れ
クエリがデータベースに送信されると、以下のようなステップで処理が行われます。
-
パーサー (Parser)
- クエリの構文解析を行います。クエリが正しく記述されているか、どのようなデータを要求しているかを理解します。
-
リライタ (Rewriter)
- クエリを最適化するために書き換えるステップです。特定のビューやサブクエリが含まれている場合、それらを展開して実行効率を高めます。
-
プランナー (Planner/Optimizer)
- クエリを実行するための最適な計画を作成します。テーブルの統計情報をもとに、どのインデックスを使用するかや、どの結合方法が最適かを判断します。
-
エグゼキュータ (Executor)
- プランナーで決定された実行計画に基づいて、実際にデータベースからデータを取得し、結果を返します。
実行計画と統計情報
-
クエリの実行計画は、データベースが効率的にクエリを処理するための「手順書」です。統計情報が最新であれば、より正確で効率的な実行計画が作成され、クエリのパフォーマンスが向上します。
-
統計情報とは、実行計画を作成するための「材料」です。データの量や分布に関するメタ情報を保持しています。
-
もし統計情報が古い場合、不正確な実行計画が選ばれ、処理速度が低下する可能性があります。
図: クエリ実行の流れ

クエリの実行計画
クエリの実行計画とは?
クエリの実行計画は、データベースがクエリを効率的に実行するための「手順書」です。この計画は、どのようにデータをアクセスし、処理するかを決定します。EXPLAINコマンドを使用して、クエリの実行計画を確認することができます。
実行計画の重要性
実行計画は、クエリのパフォーマンスのボトルネックを特定したり、どのインデックスが使用されているかを確認するために重要です。正確な統計情報があれば、最適な実行計画を作成し、効率的なデータアクセスを行うことができます。
主なポイント
スキャン方法
- Seq Scan(シーケンシャルスキャン): テーブルのすべての行を順番に読み込む方法。小さなテーブルやフィルタリングが難しい場合に使用されます。
- Index Scan(インデックススキャン): インデックスを使用して、特定のデータを効率的に取得します。少量のデータ(テーブルの数%)を取得する際に効果的です。
- Bitmap Index Scan: 大量のデータを効率的にフィルタリングするために、ビットマップ形式で行の位置を取得し、インデックスからデータを取得する方法です。
結合方法
- Nested Loop: 一つのテーブル(外側のテーブル)の各行に対して、もう一つのテーブル(内側のテーブル)をループして比較し、条件に一致する行を探す方法です。小規模なデータセットに有効ですが、大規模なテーブル間の結合では遅くなります。
- Hash Join: ハッシュ関数を使って、データを効率的に結合する方法です。特に大量のデータを処理する際に有効です。
- Merge Join: 事前にソートされたデータを結合する方法で、大規模データの結合に適しています。
ソートとフィルタリング
- 結果をソートして並べ替えたり、
WHERE句を使用してフィルタリングすることで、条件に合うデータを絞り込むプロセスを含みます。
索引の効率利用
適切な列にインデックスを作成
-
目的: フィルタリングや結合のパフォーマンスを向上させるために、一意性のあるカラムやよく使用されるカラムにインデックスを作成します。
例: 社員IDやメールアドレスなど、ユニークな値が多いカラム。
複合インデックスの活用
-
複数条件に対して、関連するカラムをまとめて指定することで、複数の条件に基づいたクエリを高速化できます。特に、
WHERE句やJOINでよく使用される列を優先してインデックスに含めると効果的です。
クエリ最適化のポイント
- フィルタリングや結合の際、インデックスが設定されているカラムを使用することでクエリを最適化します。これにより、フルテーブルスキャンを避け、より効率的なデータアクセスが可能です。
カバリングインデックス
- インデックスに条件に必要なすべてのカラムが含まれている場合、テーブルを直接参照する必要がなく、インデックスのみでクエリを処理できるため、さらなるパフォーマンス向上が期待できます。
インデックスのメンテナンス
- インデックスの断片化や効率低下を防ぐため、定期的にインデックスを再構築することが重要です。特に物理削除や頻繁な更新があるテーブルでは、再構築がパフォーマンス改善に繋がります。
TIPS: 複合インデックスのコツ
-
頻繁に使用する列を優先
-
WHERE句やJOINでよく使われる列を含めることで、クエリの高速化が期待できます。
-
-
条件の順序に合わせる
- 複合インデックスの列順は、クエリでの条件の適用順に合わせることで最も効果を発揮します。
TIPS: インデックス再構築と統計情報更新
-
インデックス再構築のタイミング
- 物理削除が頻繁に行われる場合や、インデックスの断片化が進んでいる場合には、インデックスの再構築を行うことでパフォーマンスを回復させます。
-
統計情報の更新
- データ分布が変化した場合、統計情報を更新することで、データベースが最適な実行計画を選べるようになり、インデックス利用がより効率的になります。
データの選択性とフィルタリング
選択性とは?
- 選択性は、クエリ条件に一致するデータの割合を表します。選択性が高いほど、フィルタリング後に残るデータは少なくなり、データベースのパフォーマンスが向上します。
選択性の例:
- 高い選択性: ユニークな列(例: 社員IDやメールアドレス)→ インデックスが効果的に利用され、クエリの処理が高速化されます。
- 低い選択性: 繰り返しの多い列(例: 性別など)→ フルテーブルスキャンが行われやすく、インデックスはあまり効果を発揮しません。
フィルタリング
-
フィルタリングとは、
WHERE句などを用いて、条件に合致するデータのみを抽出する処理です。適切なインデックスが設定されていると、フィルタリングが高速に行われます。
最適化のポイント
- 選択性の高い列にインデックスを作成することで、効率的なフィルタリングが可能となり、クエリのパフォーマンスが大幅に向上します。選択性が低い列にはインデックスを付けないか、他の列と組み合わせて複合インデックスを利用することが推奨されます。
インデックス使用の具体例
- 等価条件(=) に基づいたクエリでは、選択性の高い列にインデックスが設定されていると、インデックススキャンが使用され、フルテーブルスキャンを避けることができます。
- 範囲検索(>、<、BETWEEN)では、選択性が低い場合やインデックスが適切でない場合、フルテーブルスキャンが実行されることがあります。
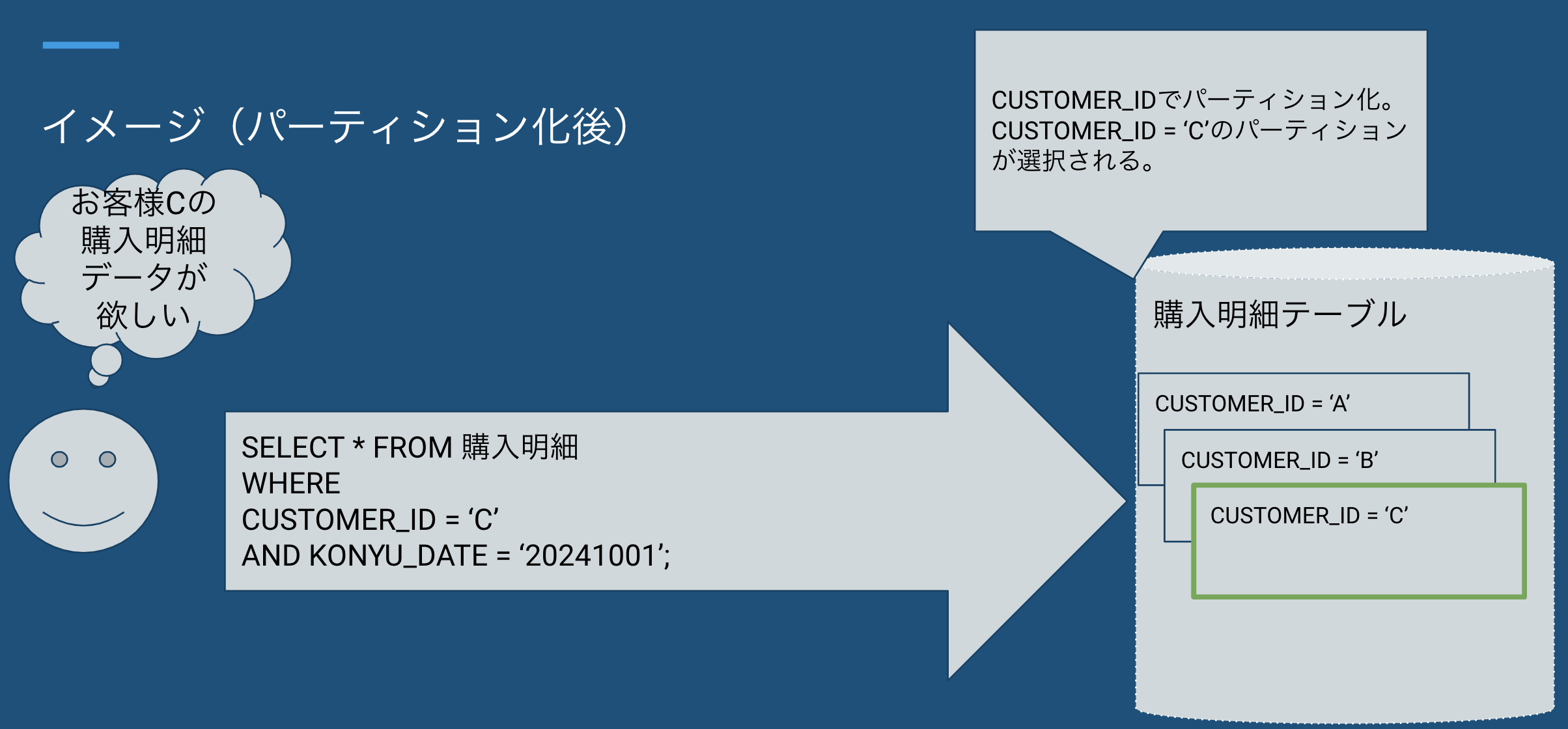
パーティショニングの最適化
パーティショニングの概要
- パーティショニングとは、大量のデータを持つテーブルを複数の小さなパーティションに分割し、クエリのパフォーマンスや管理の効率を向上させる技術です。データを物理的に分割することで、処理の高速化やI/O負荷の軽減が期待されます。
パーティショニングのメリット
- クエリのスキャン範囲が限定され、パフォーマンスが向上。
- データの追加や削除が効率的に行われ、管理が簡単になる。
- パーティション単位でのアーカイブやバックアップが容易になる。


パーティショニングの方法
範囲パーティショニング(Range Partitioning)
- 特定の範囲でデータを分割します。
- 例: 年ごとにデータを分割する。たとえば、2023年のデータはPartition1、2024年のデータはPartition2に格納する。
- 使用シーン: 大量の履歴データを管理し、特定の期間に対してクエリを実行する場合に最適。
リストパーティショニング(List Partitioning)
- 特定の値リストでデータを分割します。
- 例: 地域ごとにデータを分割する。地域AはPartition1、地域BはPartition2に格納する。
- 使用シーン: 特定のカテゴリやラベル(地域、部署など)ごとにデータを管理する場合に最適。
ハッシュパーティショニング(Hash Partitioning)
- ハッシュ関数を使ってデータを均等に分散させます。
- 例: ID値を基にデータを均等に複数のパーティションに振り分ける。
- 使用シーン: データの偏りを防ぎ、アクセス負荷を均等化したい場合に適しています。
パーティションプルーニング
- パーティションプルーニングは、クエリ実行時に不要なパーティションをスキップすることで、検索効率を最大化する技術です。これにより、不要なデータに対するスキャンを回避し、処理時間を短縮できます。
パーティショニングの最適化方法
- クエリ条件に合ったパーティションキーを選ぶことで、スキャン対象を限定し、クエリが高速化されます。
- パーティション数は適切に設定し、パフォーマンスと管理のバランスを取ります。
- メンテナンスの自動化(パーティションのアーカイブや追加)を行うことで、運用効率を向上させます。
実例
- Q: Aカラムでパーティショニングし、クエリでBカラムをフィルタリングした場合どうなるか?
- A: パーティション化されていないカラムをフィルタリングすると、すべての子テーブルに対してスキャンが実行されます。これにより、パフォーマンスが低下する可能性があります。
キャッシュ利用の最適化
キャッシュの概要
- キャッシュとは、データベースがよく利用するデータをメモリ上に保持し、ディスクアクセスを減らしてクエリの応答速度を向上させる仕組みです。これにより、ディスクI/Oの負担が軽減され、特定のデータに対するクエリが高速化されます。
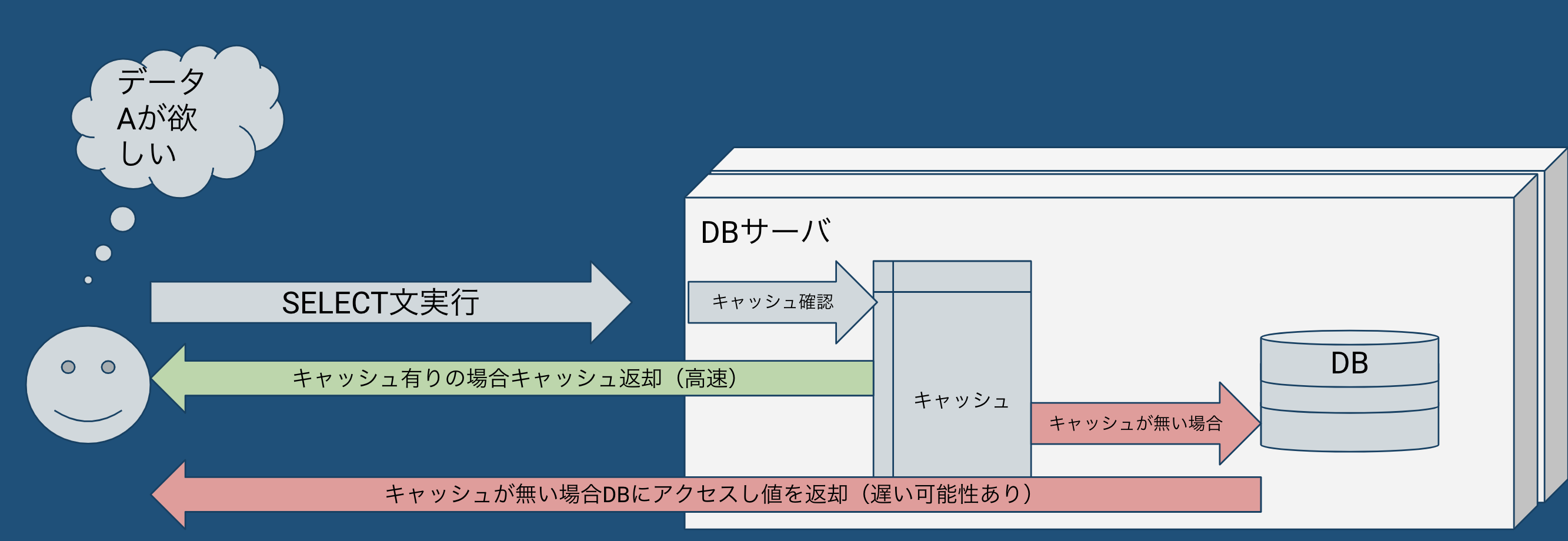
キャッシュの種類
- バッファキャッシュ: データベースが最近アクセスしたテーブルやインデックスページをメモリに保持します。クエリが同じデータにアクセスするたびに、ディスクからデータを再度読み込む必要がなくなります。
- プランキャッシュ: クエリの実行計画をメモリに保持し、同じクエリが再度実行された際に、再度実行計画を立てずに迅速に処理できるようにします。
キャッシュのメリット
- 応答速度の向上: よく利用されるデータをキャッシュに保持することで、クエリの処理時間が大幅に短縮されます。
- ディスクI/Oの削減: キャッシュを使用することで、ディスクアクセス回数が減少し、ディスクの負荷が軽減されます。
キャッシュ最適化のポイント
- キャッシュサイズの適切な設定: メモリを効率的に使うために、データベースのサイズに応じて適切なキャッシュサイズを設定します。メモリが足りない場合、キャッシュが効果的に機能しません。
- 頻繁にアクセスされるデータのキャッシュを優先: アクセス頻度の高いテーブルやインデックスをキャッシュすることで、応答速度を最大化します。
- クエリのキャッシュ活用: 同じクエリが繰り返し実行される場合、プランキャッシュを有効にして、クエリの再計画にかかる時間を節約します。
キャッシュのクリア
- キャッシュが効率的に機能していない場合や、最新のデータを確実に取得したい場合には、キャッシュをクリアすることができます。PostgreSQLでは、OSのキャッシュやデータベースの再起動を行うことでキャッシュをリセットできます。
キャッシュとクエリパフォーマンスの関係
- キャッシュヒット率が高いほど、クエリが迅速に処理されるため、キャッシュを活用することがパフォーマンスの最適化に直結します。
- キャッシュを効果的に利用することで、特定のクエリの処理速度が大幅に向上するため、大量データに対するクエリで特に有効です。

検証
検証内容
- 索引の有無による実行計画の変化
- データの選択性とフィルタリングによる実行計画の変化
- パーティションの有無による実行計画の変化
- キャッシュの有無による実行計画の変化
データベース環境
データベース
- 種類: PostgreSQL
テーブル名
- PEOPLE
統計情報
- 状態: 最新の状態
データ数
- 総件数: 400万件
インデックス
-
Idx_people_person_id
- 指定カラム:
person_id
- 指定カラム:
-
Idx_people_duplication_many
- 指定カラム:
duplication_many
- 指定カラム:
-
Idx_people_duplication_forty_type
- 指定カラム:
duplication_forty_type
- 指定カラム:
カラム構成
- person_id: INTEGER型
- duplication_few: INTEGER型(一意なデータ)
-
duplication_many: INTEGER型(重複のあるデータ)
-
0: 40万件 -
1: 40万件 -
2: 40万件 -
3: 40万件 -
4: 280万件
-
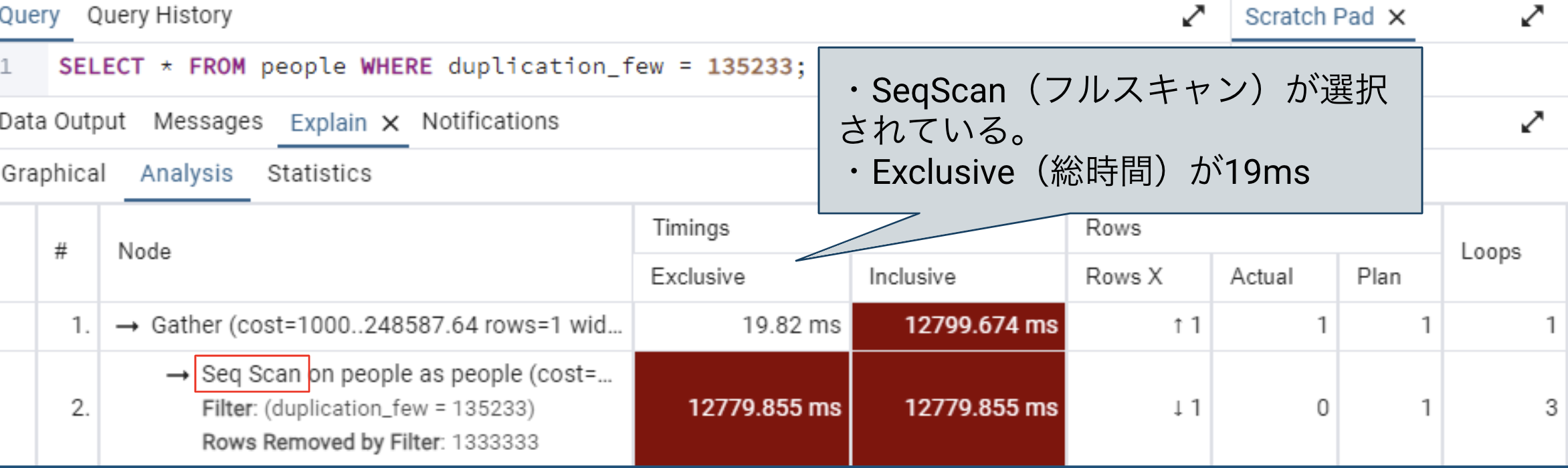
索引の有無による実行計画の変化
-
適切なINDEXが存在しない場合
-
適切なINDEXが存在する場合

データの選択性とフィルタリングによる実行計画の変化
-
ユニーク度:一意なデータをフィルタリングした場合

-
ユニーク度:重複のあるデータをフィルタリングした場合

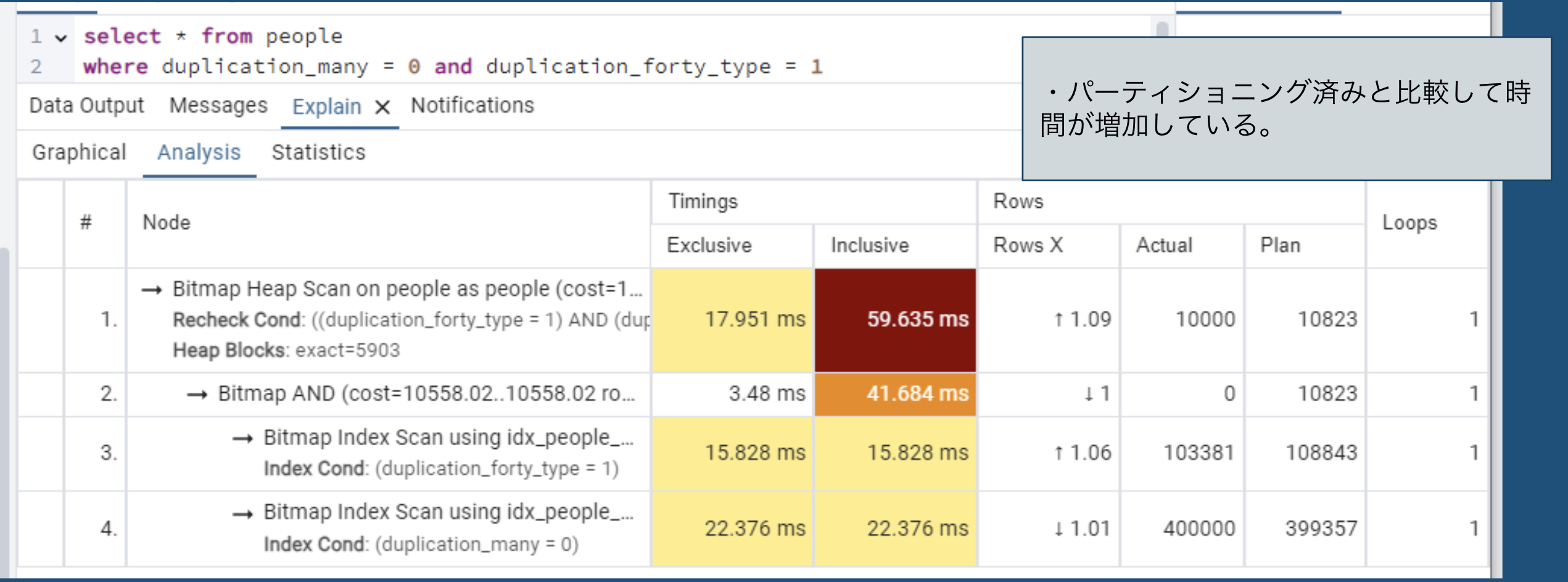
パーティションの有無による実行計画の変化

-
パーティショニング済み

-
非パーティショニング
キャッシュの有無による実行計画の変化
以下の通り4回クエリを実行し検証を行う。
1回目:キャッシュを使用しない
2回目;キャッシュを使用する
3回目;キャッシュを使用する
4回目;キャッシュを使用する
-
1回目:キャッシュを使用しない
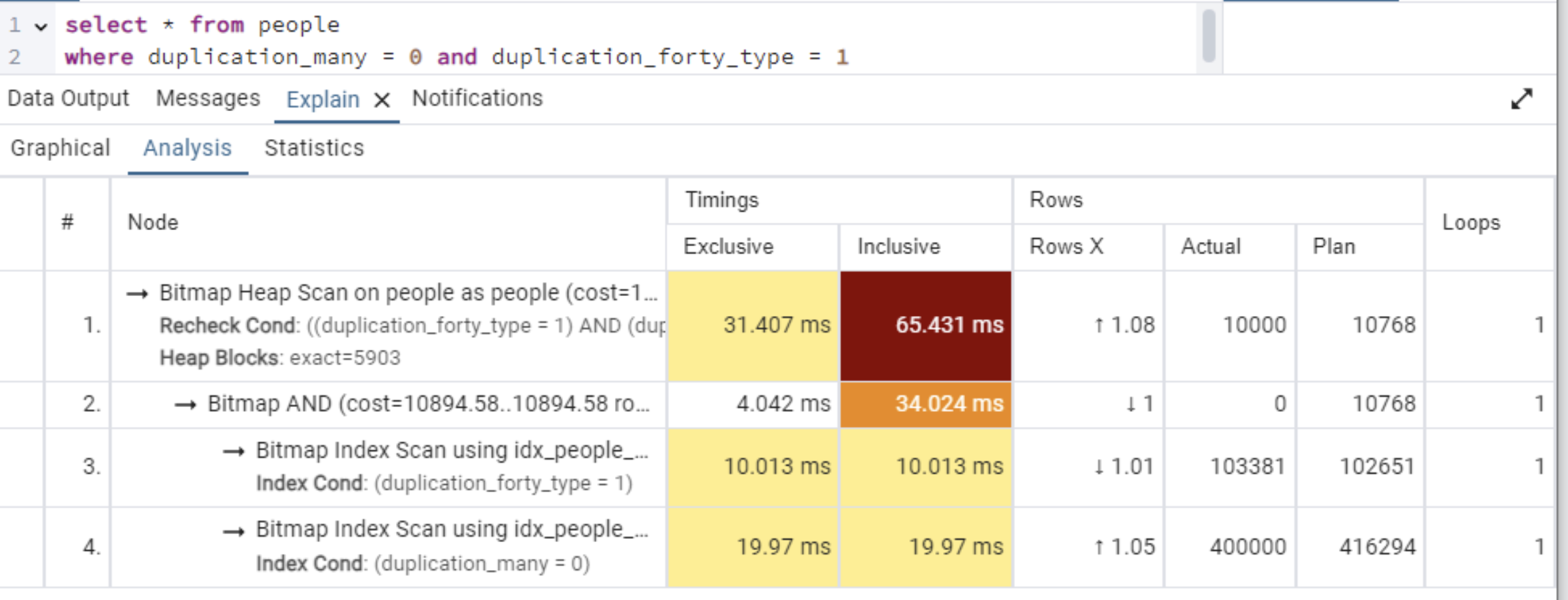
-
2回目;キャッシュを使用する
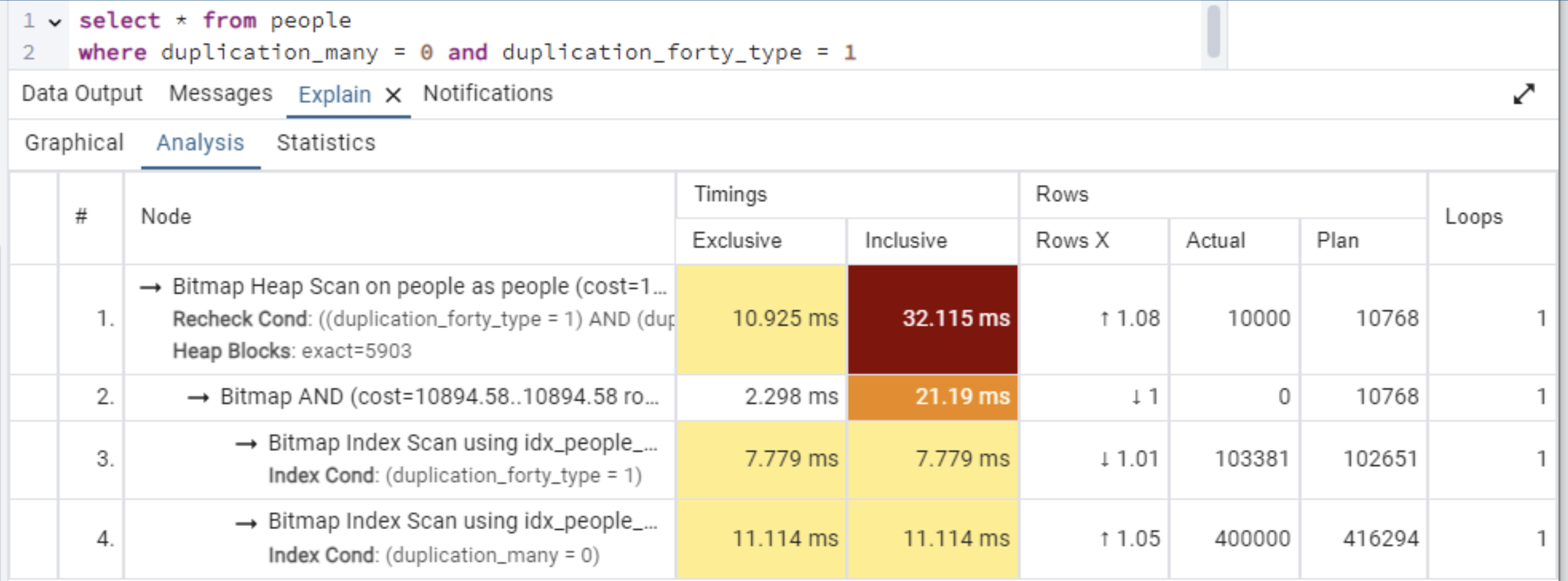
-
3回目;キャッシュを使用する

-
4回目;キャッシュを使用する

-
結果
キャッシュが適用されることで各実行時間が短縮されている。
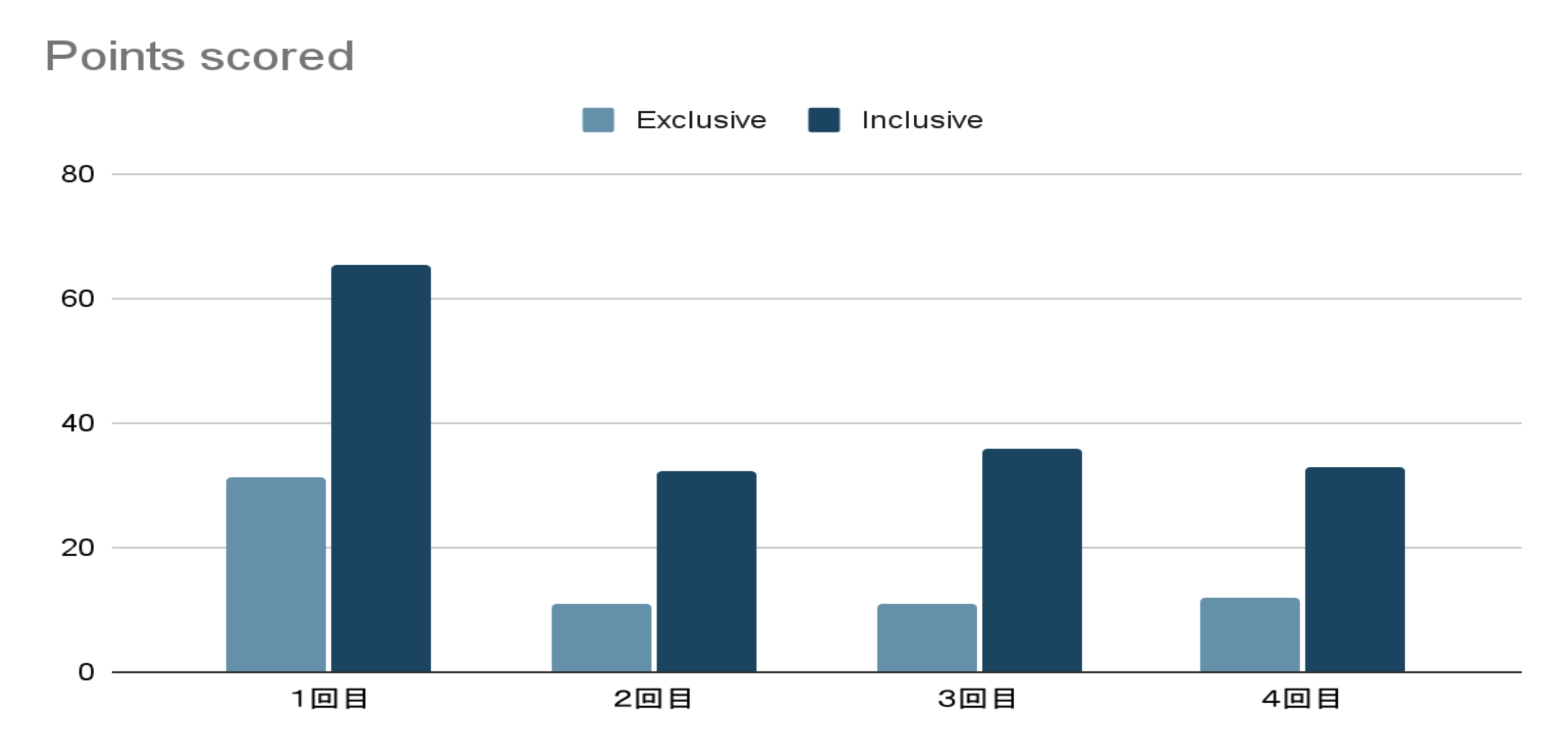
まとめ
本資料では、PostgreSQLデータベースにおけるパフォーマンス最適化のための重要な要素について解説しました。クエリの実行計画、統計情報の重要性、インデックスの効率的な利用、パーティショニングの適用など、それぞれの技術がどのようにデータベースのパフォーマンス向上に寄与するかを説明しました。
主なポイント
-
統計情報の重要性
最新の統計情報を保持することで、クエリ実行計画が正確に作成され、最適なインデックスやスキャン方法が選択されます。定期的な統計情報の更新は、パフォーマンス向上のために不可欠です。 -
インデックスの最適化
選択性の高いカラムにインデックスを作成し、クエリの処理速度を大幅に改善します。また、複合インデックスを活用することで、複数の条件に基づいたクエリの高速化が可能です。 -
パーティショニングのメリット
大量データを持つテーブルをパーティションに分割することで、特定のパーティションのみをスキャンし、クエリの処理を効率化できます。特に時系列データや地域別データの管理に有効です。 -
キャッシュ利用の最適化
よく使用するデータをキャッシュに保持することで、ディスクI/Oを削減し、クエリの応答速度を向上させることができます。適切なキャッシュサイズの設定や頻繁にアクセスされるデータのキャッシュが、パフォーマンス向上に貢献します。
今後の展望
今後、データベースの規模が増大するにつれて、統計情報の更新やインデックスの再構築、さらにパーティショニングやキャッシュの効果的な利用がますます重要となります。適切なメンテナンスと最適化手法を実施することで、クエリパフォーマンスの向上と安定した運用が可能になります。