📚 目次
- はじめに
- 統計情報とは何か?
- 物理順序と論理順序
- 物理順序と論理順序のギャップが生む罠
- 検証:カーディナリティ × 物理順序の違いによる実行速度の変化
- どう直す?統計情報と物理順序のズレ対策
- 【おまけ】Oracleで実行計画を固定することの落とし穴
- まとめ
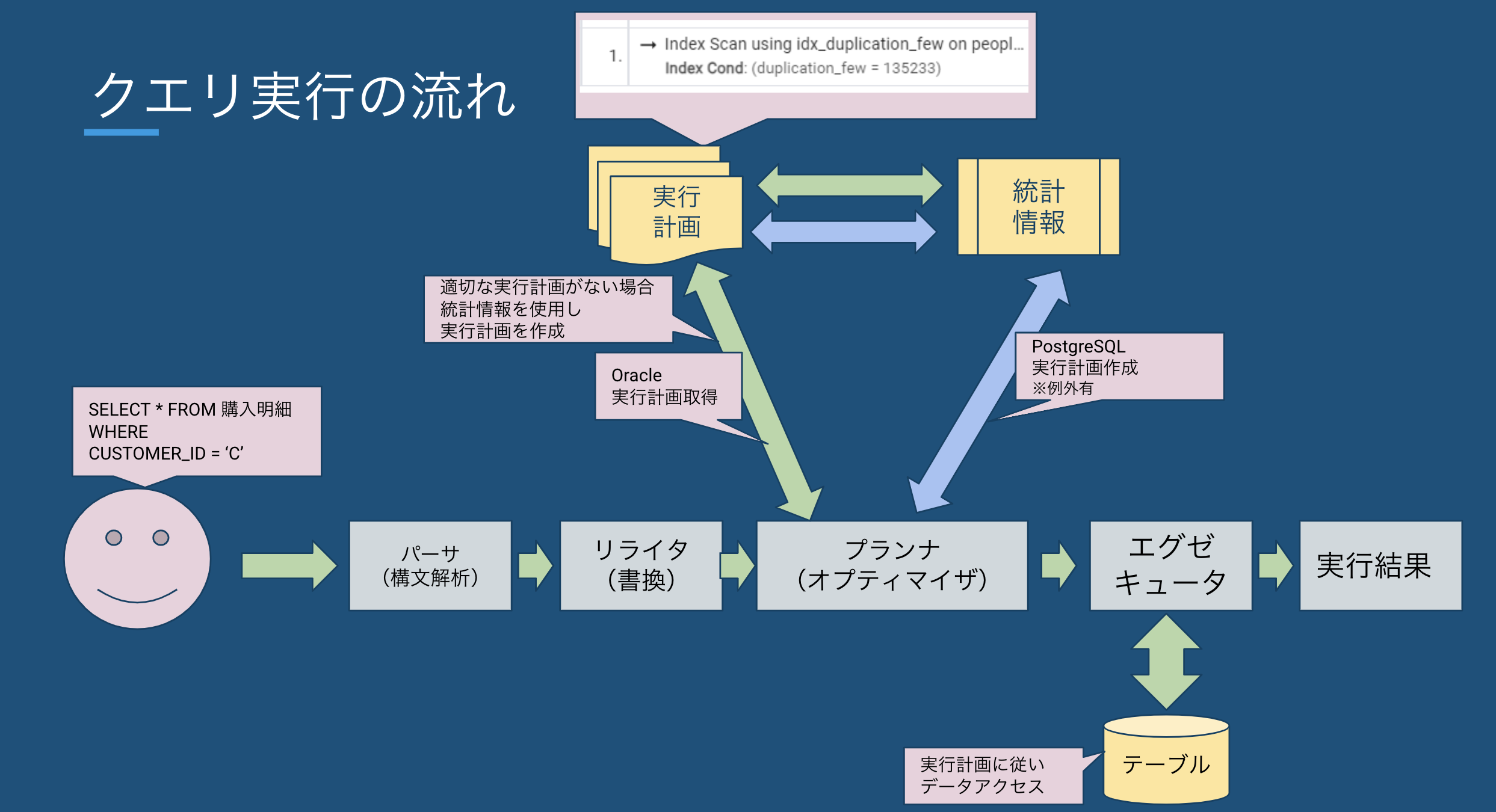
1. はじめに
統計情報は正しいのに、なぜかSQLが遅い…
実行計画も問題なさそうなのに、処理が重い…
👉 その原因、物理順序の影響かもしれません。
SQLのパフォーマンスチューニングでは、まず「統計情報を更新する」ことが基本とされています。
しかし統計情報が最新であっても、実行計画の選択が想定外だったり、処理時間が長くなるケースがあります。
本記事では、統計情報と物理順序(correlation)の違いや、
それらのギャップがスキャン方式の選択や処理速度にどのような影響を与えるかを検証とともに解説します。
📌 本資料の目的
統計情報が正しくてもSQLが遅い場合の “もう一つの原因” として、
物理順序の重要性を再発見することを目的としています。
2. 統計情報とは何か?
統計情報とは、データベースが実行計画を最適化するために参照する「データの概要情報」です。
📌 代表的な統計情報の例:
- 件数(カーディナリティ)
- 値の分布(ヒストグラム)
- NULLの割合
- よく出現する値(Most Common Values)
- カラムと物理順序の相関(correlation) ← 後ほど登場
🧠 統計情報は何に使われる?
データベースは統計情報をもとに、実行計画を最適化します。具体的には:
- どの インデックス を使うか?
- テーブルの 結合順序 はどうするか?
- インデックススキャン or シーケンシャルスキャン?
などの判断材料になります。
⚠️ 古い統計情報が引き起こす問題
統計情報が 古い または 不正確 な場合、
→ 実行計画の見積もりがズレ、非効率なスキャン方法が選ばれることがあります。
💬 補足:実行計画とは?
実行計画とは、DBMSがクエリを実行するための“最適な手順書”のこと。
具体的には:
- どのインデックスを使うか
- どのテーブルをどの順番で結合するか
- テーブル全体を読むか(Seq Scan) or インデックスから読むか(Index Scan)
などを定めます。
3. 物理順序と論理順序
📌 物理順序とは?
- データが 実際にテーブル内に格納されている順番
- PostgreSQLでは ヒープ構造(Heap)で格納されており、INSERTやUPDATEのたびに順序は乱れやすい
- テーブルの並び順には原則意味がない
- 統計情報はこの物理順序の影響を受ける場合がある(特に
correlation)
💬 ヒープ構造とは?
PostgreSQLにおけるデフォルトのテーブル構造。
各行がランダムに格納され、物理順序の自動整列は行われない。
並び順を最適化するには CLUSTER が必要。
※VACUUM FULL でも物理順序は再構成されるが、インデックス順にはならない点に注意。
📌 論理順序とは?
- インデックスによって管理される「検索用の並び順」
- インデックスは指定したカラム(単一 or 複合)ごとに作られ、
値の 昇順・降順 などにソートされた構造(例:B-tree) - 検索性能を高めるための論理的な整列であり、物理配置とは無関係
❗ 物理順序と論理順序の違いと影響
- 両者は必ずしも一致しない
- INSERT / UPDATE / DELETE によって物理順序は変化する
- 一致している場合は、ディスクI/Oが最適化され処理が高速化される
- 特に大量の行を読み込む際、物理順序の整合性(correlation)が重要
🔍 イメージ図:同じ「id」でも順序はバラバラ?
論理順序(インデックス順): id = 1 → 2 → 3 → 4 → 5
物理順序(実格納順): id = 3 → 1 → 5 → 2 → 4
→ 同じ値でも、実データの配置順は バラバラ なことがある
→ この差が、実行計画の選択や処理時間に大きな影響を与える
4. 物理順序と論理順序のギャップが生む罠
💡 まずはスキャン方式の整理
| スキャン方式 | 概要 | ヒープへのアクセス方法 |
|---|---|---|
| Seq Scan | テーブル全体を順に読む | ブロックを先頭から順番に読み込む(シーケンシャルI/O) |
| Index Scan | インデックスで一致行を探す | TID(Tuple ID)を使って行ごとにアクセス(ランダムI/O傾向) |
|
Bitmap Index Scan (Bitmap Heap Scan) |
条件に合うTIDをビットマップ化してまとめて取得 | TIDを並び替えて一括でアクセス(I/O効率改善) |
📝 補足
- TID(Tuple ID):ヒープ(テーブル本体)上の行の物理的な位置を示す識別子(ブロック番号 + 行番号)
- Bitmap Index Scan:ヒット件数が中~多の場合に選ばれ、ランダムI/Oを抑制する
📍 論理順序と物理順序の影響
少数件の検索では Index Scan が最も効率的です。
しかし、検索対象が多くなる(重複が多い・範囲が広い等)場合、物理順序が処理効率に大きな影響を与えるようになります。
🧭 物理順序とスキャン方式の関係
🔸物理順序が整っている場合(correlation ≈ 1)
→ ヒープのデータも TID 順(≒物理順)に近いため、Index Scanでも連続的なI/Oで効率的に処理されます。
🔸物理順序が乱れている場合(correlation ≈ 0)
→ ランダムI/Oが頻発し、Index Scanは非効率。
→ Bitmap Index ScanやSeq Scanが選ばれることもある
PostgreSQLは
pg_stats.correlationを参考に、
統計情報から最適なスキャン方式をプランナーが自動選択します。
📘 各スキャン方式の特徴とイメージ
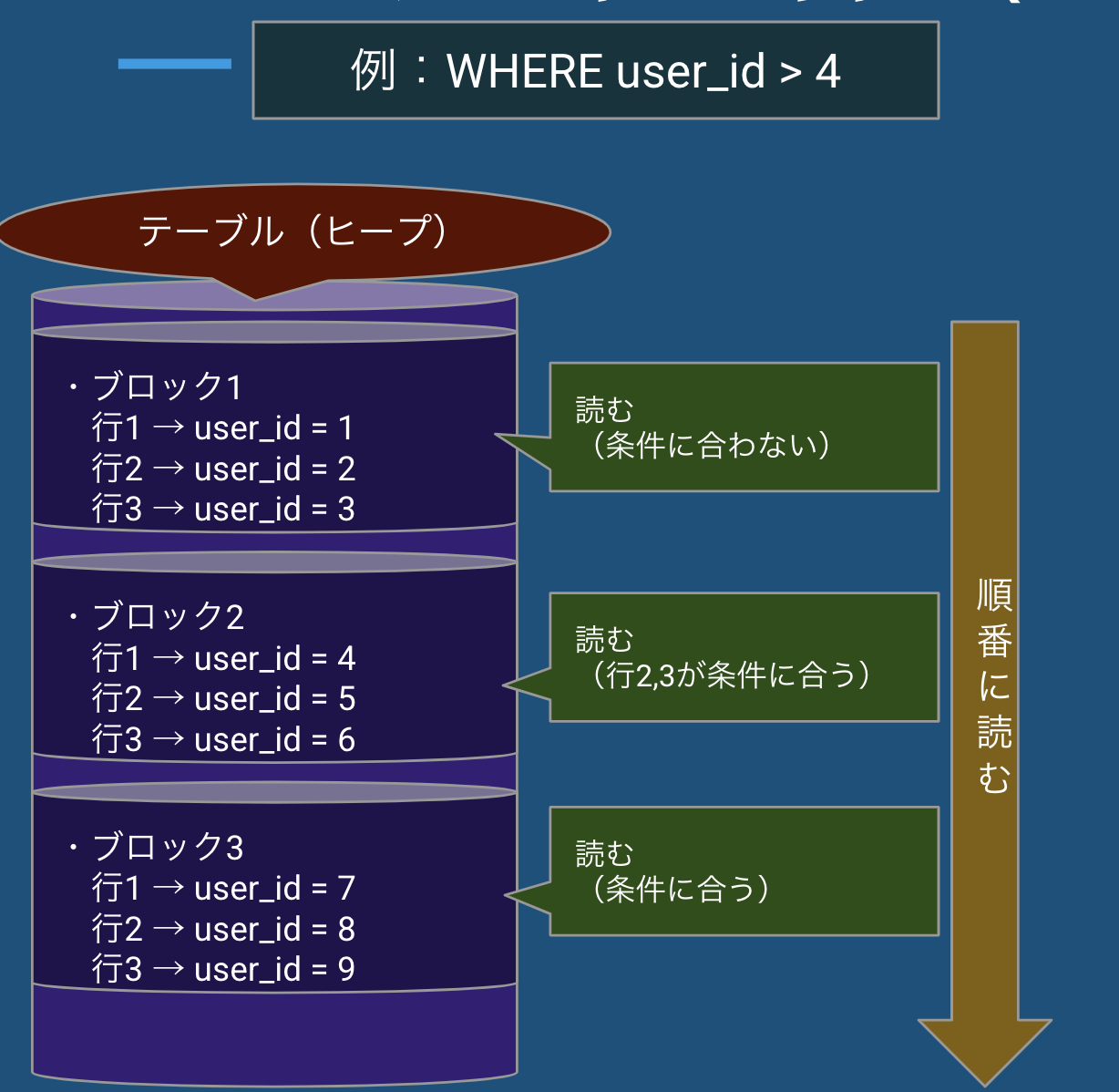
▫️シーケンシャルスキャン(Seq Scan)
- 全ブロックを順番に走査(シーケンシャルI/O)
- 条件に関係なく、テーブル全体を読み込む
- 対象件数が多いときに選ばれやすい
💡 ブロックとは?
PostgreSQLの読み取り単位であり、複数の行を含む。
💡 ヒープとは?
テーブル本体の格納構造であり、行の順序は保証されない。
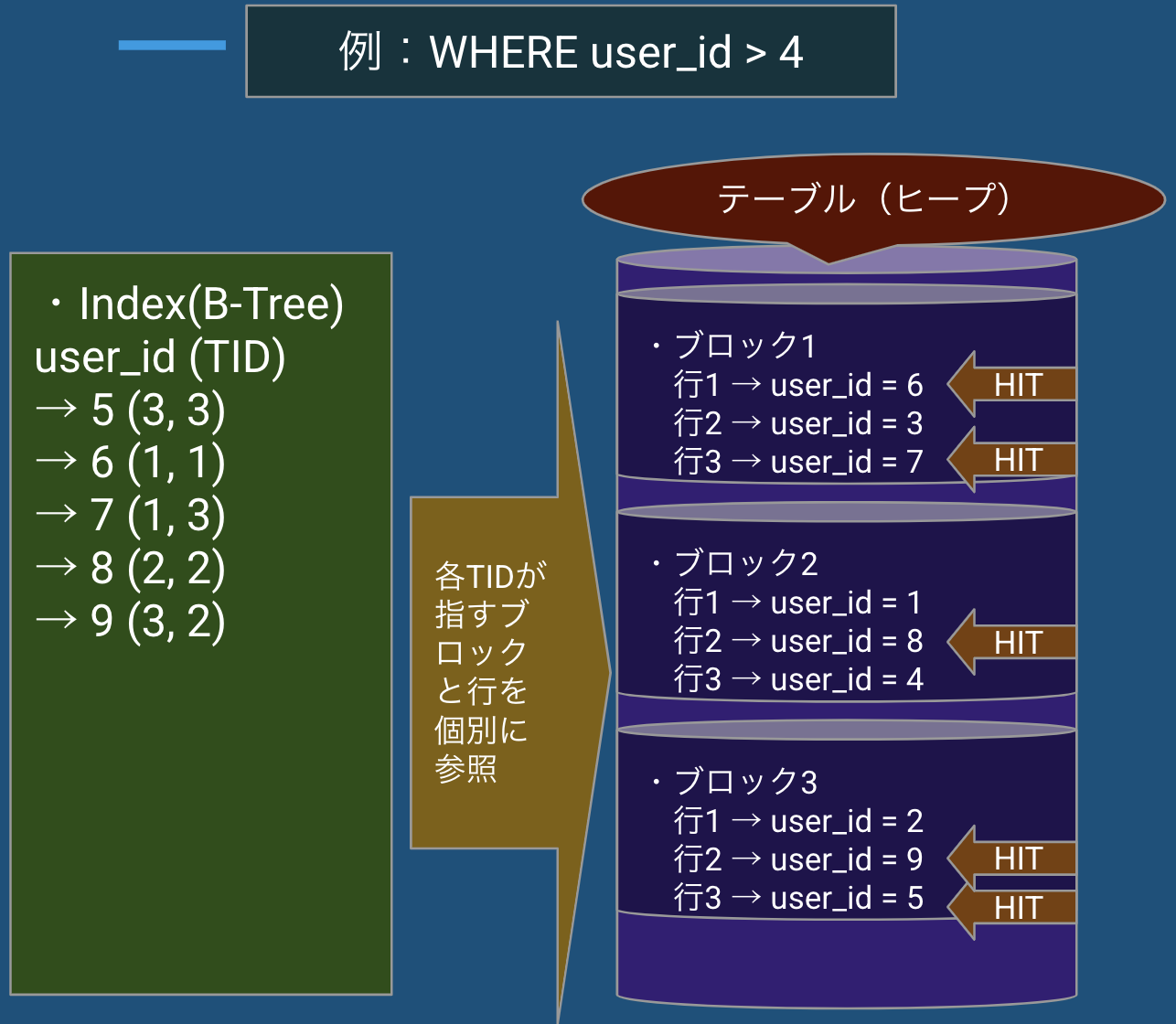
▫️インデックススキャン(Index Scan)※物理順序が整っている場合
- インデックスから対象のTIDを取得し、TID順に近い形でヒープを読む
- 順番に近いため、I/O効率が良く、ランダムアクセスが抑えられる
- 重複が少ない少数検索に最適
💡 TIDとは?
行が格納されている位置情報(ブロック番号 + 行番号)のこと。

▫️インデックススキャン(Index Scan)※物理順序が崩れている場合
- インデックスが返すTIDの順序と物理順序がズレている
- 多くの行にヒットする場合、ランダムI/Oが多発し非効率
- correlationが低い(≒ 0) ときに発生しやすい
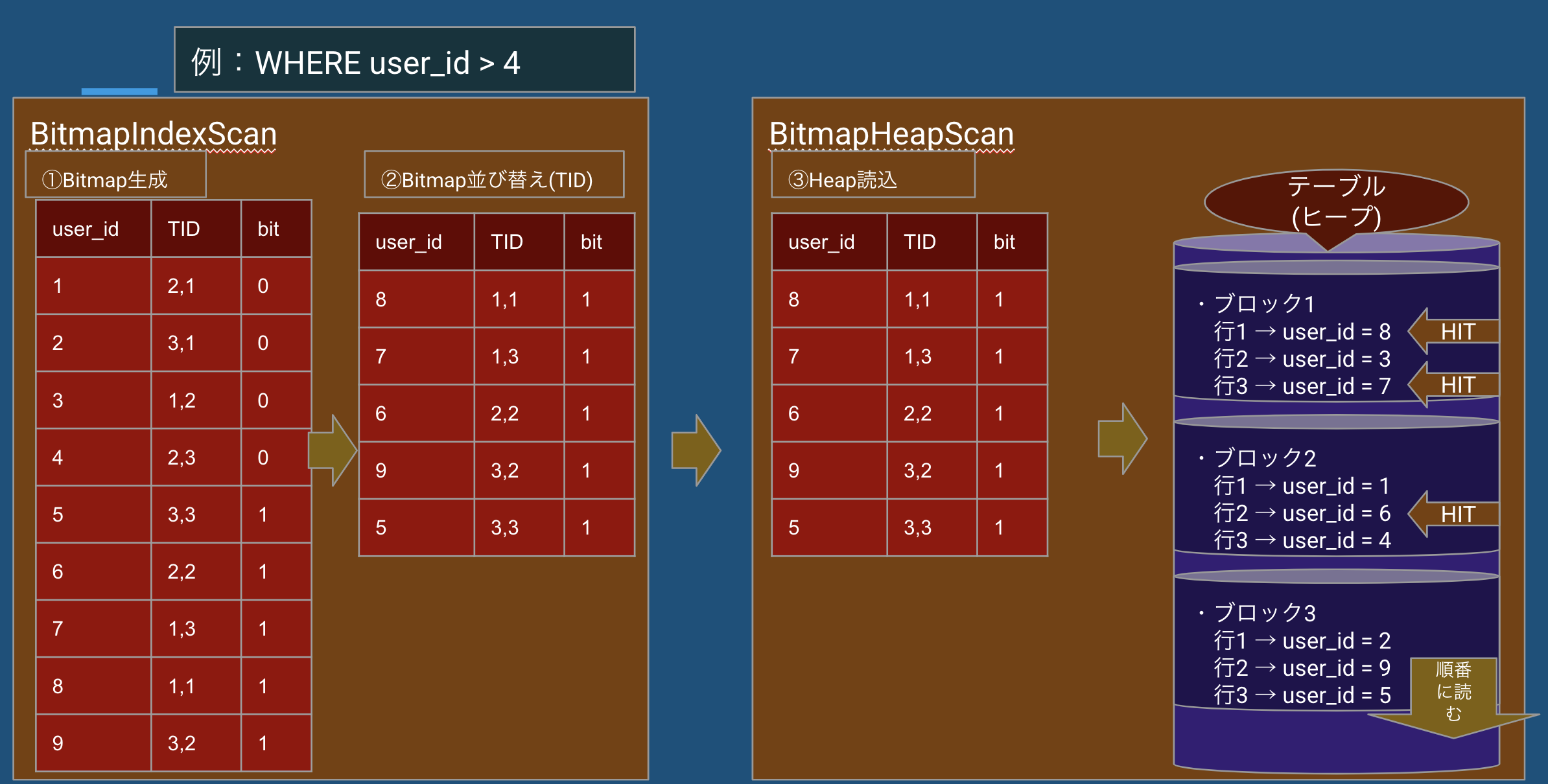
🧩 Bitmap Index Scan の2つのタイプ
▫️Bitmap Index Scan(Exact:TIDベース)
条件に合致した行の TID(ブロック番号+行番号)単位 でビットマップを構成します。
TIDを正確に記録し、無駄なI/Oを最小限に抑えた高速スキャンが可能です。
① Index(B-Tree)を走査し、TID単位でビットマップを作成
- 条件に合致した行の TID に「1」を立てる
- 複数インデックス条件を合成(AND/OR演算)するのにも適している
② ビットマップに立った TID を、 TID順に並べ替え
- I/O効率を高めるため、アクセス順を最適化
③ 並べ替えたTIDを使って、ヒープ(本体)から該当行をピンポイント取得
- TIDで行位置が特定されているため、再チェックは不要
- 正確かつ高速な読み取りができる
▫️Bitmap Index Scan(Lossy:ブロック単位)
対象件数が多すぎる場合や、work_memを超える場合に使用されます。
TIDではなくブロック単位でビットを立てるため、I/Oは抑えられるが再チェックが必要です。
① Index(B-Tree)を走査し、ブロック単位でビットマップを作成
- 条件に合致するブロックに「1」を立てる(行番号は保持しない)
- 大量ヒットやメモリ制約がある場合に自動でLossyに切り替わる
② ビットが立っているブロックを、ブロック番号順に並べ替え
- ランダムI/Oを抑えるためのアクセス最適化処理
③ 各ブロックを一括で読み込み、全行を再チェック(Recheck Cond)
- ビットマップには行の位置が含まれないため、条件に合うかを再判定
- I/Oは削減できるが、CPU負荷が高くなる可能性もある

📊 スキャン方式ごとの比較表
| スキャン方式 | 主な選択条件 | 特徴 | 備考 |
|---|---|---|---|
| Seq Scan | 対象件数が多い、インデックスがない | 全ブロックを順に読む(無駄は多いが安定) | 選択率が高いと選ばれやすい |
| Index Scan(整列) | 少数件、correlation ≈ 1 | ランダムI/Oが少ない | 非常に効率的 |
| Index Scan(乱れ) | 少数件、correlation ≈ 0 | ランダムI/Oが多くなる | correlationが低すぎると切り替わる |
| Bitmap Scan(Exact) | 中〜多件数、複数インデックス条件など | TID単位で正確にビット化、I/O最小 | work_mem に収まれば最良 |
| Bitmap Scan(Lossy) | 大量ヒット、work_mem超過 | ブロック単位でビット管理、再チェック必要 | メモリ制約により自動切替 |
✅ 補足
-
correlation:
pg_statsに格納される値で、列の昇順と物理順序が一致している度合い(-1〜1)。
→ 0に近いほどランダム配置で、Index Scan に不利。 -
TID:
ヒープ構造における行の位置情報。形式は(ブロック番号, 行番号)。
5. 検証:カーディナリティ × 物理順序の違いによる実行速度の変化
🎯 目的
重複の多いデータに対して SELECT を実行し、
物理順序の違いによって実行計画や処理速度に変化があるかを検証する。
🧪 実行環境
| 項目 | 内容 |
|---|---|
| OS | macOS |
| 実行環境 | Docker コンテナ上 |
| データベース | PostgreSQL 17.4 |
| クライアント | PGAdmin 9.1 |
🧪 使用した検証クエリ(PostgreSQL)
クリックで展開
解説
📝 概要(このスクリプトで行うこと)
このスクリプトは、PostgreSQLにおける 物理順序(correlation)と実行計画の関係を検証するための一連の手順です。
PostgreSQLでは、インデックスの使用可否やスキャン方式(Index Scan / Bitmap Index Scan / Seq Scan)を決定する際に、統計情報(pg_stats)を参照します。
特に correlation 値(論理順序と物理順序の一致度)は、実行計画の選定に大きく影響を与える重要な指標です。
このスクリプトでは、以下の流れで 実データの物理順序と correlation の変化、実行計画の違い を確認します。
🔸 ① テーブル定義と関数作成
- ベースとなる
test_tableとtest_table_randomを作成 -
test_tableにid = 1のデータを400万件 INSERT する関数insert_base_data()を作成 - 任意の件数で
id値をランダムに均等分布させるevenly_distribute_ids(n)を作成
🔸 ② 初期データの作成と分布調整
-
insert_base_data()を実行し、id = 1のデータを400万件挿入 -
evenly_distribute_ids(10)のように呼び出し、idを指定数に均等に分布させる(例:10種類)
🔸 ③ 物理順序をランダム化
-
ORDER BY random()を使って、test_table_randomに ランダム順でデータを挿入 - これにより、物理順序が崩れた状態が再現される
🔸 ④ correlationの確認と実行計画の比較
-
ANALYZEで統計情報を更新 -
pg_statsからcorrelationを確認し、物理順序の乱れ具合を数値で把握 -
EXPLAIN ANALYZEで、id = 1に対するクエリの実行計画と処理時間を取得 -
CLUSTERを使ってインデックス順に物理順序を並び替えた後、同じクエリの実行計画を再取得
この一連の操作により、correlation が高まることでスキャン方式や処理時間がどのように変化するかを観察することができます。
PostgreSQLの実行計画チューニングにおける「統計情報と物理順序の関係性」を理解するのに役立つ検証です。
① 検証用テーブルの作成
-- テーブルとインデックスの作成
CREATE TABLE test_table (
id INT,
val TEXT
);
CREATE INDEX idx_id ON test_table(id);
-- 検証用テーブル(ランダム順)
CREATE TABLE test_table_random (
id INT,
val TEXT
);
CREATE INDEX idx_id_random ON test_table_random(id);
-- 初期データ(id=1 × 400万件)をINSERTする関数
CREATE OR REPLACE FUNCTION insert_base_data()
RETURNS void AS $$
BEGIN
INSERT INTO test_table (id, val)
SELECT 1, md5(random()::text)
FROM generate_series(1, 4000000);
END;
-- 初期データのidを引数の種類分均等になるようにUPDATEする関数
CREATE OR REPLACE FUNCTION evenly_distribute_ids(n INT)
RETURNS void AS $$
DECLARE
i INT;
batch_size INT := 4000000 / n;
BEGIN
FOR i IN 1..n LOOP
UPDATE test_table
SET id = i
WHERE ctid IN (
SELECT ctid FROM test_table
WHERE id = 1
ORDER BY random()
LIMIT batch_size
);
END LOOP;
END;
② 初期データの作成
-- 初期データ作成
SELECT insert_base_data();
-- 初期データが均等に分布するようUPDATE
-- 例:10種類に均等分布
SELECT evenly_distribute_ids(10);
③ ランダム並びのテーブルにインサートし物理順序をバラす
-- ランダム順にINSERTして物理順序を崩す
INSERT INTO test_table_random (id, val)
SELECT id, val
FROM test_table
ORDER BY random();
④ correlationの確認・CLUSTERによる順序整列・実行計画の確認
-- 統計情報を更新
ANALYZE test_table_random;
-- correlation(物理順序と論理順序の一致度)を確認
SELECT attname, correlation
FROM pg_stats
WHERE tablename = 'test_table_random';
-- 物理順序並び替え前の実行計画を確認
EXPLAIN ANALYZE
SELECT * FROM test_table_random WHERE id = 1;
-- CLUSTERでインデックス順に並び替え、再度統計情報を更新
CLUSTER test_table_random USING idx_id_random;
EXPLAIN ANALYZE
SELECT * FROM test_table_random WHERE id = 1;
-- 物理順序並び替え後の実行計画を確認
EXPLAIN ANALYZE
SELECT * FROM test_table_random WHERE id = 1;
📌 検証条件
- データ件数:400万件
-
idカラムに対し、以下3パターンで重複の種類数を変えて検証:- 2種類 / 10種類 / 1000種類
-
idに対してインデックスは作成済 - 1回目:物理順序バラバラな状態
- 2回目:
CLUSTERを実行して物理順序を整えた状態 - 検証クエリ:
SELECT * FROM test_table_random WHERE id = 1;
📌 correlation(物理順序と論理順序の一致度)について
実行計画の選択に大きく影響する統計情報のひとつが pg_stats.correlation です。
- この値は、インデックスの論理順(昇順)と、テーブル内の物理順序の一致度を表す指標です。
- 値の範囲は -1 〜 1 で、以下のような意味を持ちます:
| correlation値 | 意味 |
|---|---|
| 1.0 | 論理順と物理順序が完全に一致(高効率) |
| 0.0 | 順序に関連性がない(ランダム) |
| -1.0 | 論理順と物理順が完全に逆(非効率) |
この correlation の値が高いほど、Index Scan 時の I/O 効率が高くなり、ランダムアクセスが減少します。
逆に、correlation が低いと、PostgreSQLのプランナーは Bitmap Index Scan や Seq Scan を選択する傾向が強まります。
🧪 検証パターン(イメージ付き)
この検証では、次の3パターンについて id カラムのデータ分布と物理順序を操作し、CLUSTER 実行前後での correlation 値とスキャン方式の変化を観察しました。
🔸 データが2種類
-
CLUSTER 実行前:
correlation = 0.5043

-
CLUSTER 実行後:
correlation = 1.0000

-
スキャン方式:Bitmap Index Scan → Index Scan に変化
🔸 データが10種類
-
CLUSTER 実行前:
correlation = 0.1058

-
CLUSTER 実行後:
correlation = 1.0000

-
スキャン方式:Bitmap Index Scan → Index Scan
🔸 データが1000種類
-
CLUSTER 実行前:
correlation = -0.0052

-
CLUSTER 実行後:
correlation = 1.0000

-
スキャン方式:Bitmap Index Scan → Index Scan
※実行計画のイメージは、それぞれのケースでスライドや記事内に挿入してください。
📊 検証結果まとめ
| データの種類数 | CLUSTER | スキャン方式 | correlation | 処理時間 (ms) |
|---|---|---|---|---|
| 2 | 前 | Bitmap Index Scan | 0.5043 | 449.838 |
| 2 | 後 | Index Scan | 1.0000 | 341.733 |
| 10 | 前 | Bitmap Index Scan | 0.1057 | 224.348 |
| 10 | 後 | Index Scan | 1.0000 | 56.174 |
| 1000 | 前 | Bitmap Index Scan | -0.0051 | 4.486 |
| 1000 | 後 | Index Scan | 1.0000 | 0.694 |
🔍 考察
-
CLUSTERを実行することで、correlation はすべて1.0に向上 - これにより、Bitmap Scan → Index Scan へとスキャン方式が切り替わり、処理時間も大幅に短縮された
- 特に 10種類のケースでは75%の処理時間削減を確認
- ヒット件数が少ない1000種類のパターンでも、correlationが改善されることで Index Scan に切り替わる傾向が見られた
- 以上から、correlation(物理順序と論理順序の一致度)は、実行計画とパフォーマンスに大きな影響を与える重要な指標であることがわかる
💡 補足
-
CLUSTERは統計情報の更新も自動的に行うため、実行後にANALYZEを手動で実行しなくても correlation の値は更新される - 実運用では、頻繁に
CLUSTERを実行するのは現実的でないため、影響度の高いカラムに限定して定期的に適用するのがベストプラクティス
6. どう直す?統計情報と物理順序のズレ対策
❗ なぜ対策が必要か?
-
統計情報が古い or 実際の物理順序とずれていると、
PostgreSQL のプランナーが 誤った実行計画を選択するリスクがあります。 - 特に、大量の
UPDATEや ランダムなINSERTが行われた場合、- 実データの物理順序は大きく崩れる
- しかし
correlationは 更新されないまま になることがある
📌 その結果…
→ Index Scan が選ばれなくなり、パフォーマンスが劣化する可能性がある
✅ 解決策:ANALYZE or CLUSTER を適切に使い分ける
物理順序と統計情報のズレを修正するには、タイミングに応じて以下のコマンドを使い分けることが重要です。
🔄 ANALYZE vs CLUSTER の違い(比較表)
| 項目 | ANALYZE | CLUSTER |
|---|---|---|
| 目的 | 統計情報の更新(軽量) | 物理順序の最適化(インデックス順) |
| 更新対象 |
pg_stats のみ更新 |
テーブル全体を再配置+統計情報も更新 |
| 実行タイミング | データ変更後すぐ | 順序を整えたいとき(重処理) |
| correlationへの影響 | 値は更新されるが順序は変わらない | 順序も統計も変わる → correlationが1に近づく |
| ロックの種類 | 共有ロック(並行実行OK) | 排他ロック(処理中アクセス不可) |
🛠 CLUSTER のベストプラクティス(6つのポイント)
-
よく使う WHERE 条件のカラムに対して実行する
→ 特にBETWEEN,>=,>の範囲検索に効果大 -
複合インデックスでは、CLUSTER対象のカラムが先頭か確認する
→ CLUSTER は 先頭カラムの順序で並び替える -
他カラムの
correlationが下がるリスクに注意
→ 並び替えは1つの軸にしか最適化できない(全カラムにとってベストとは限らない) -
更新頻度の高いテーブルでは実行タイミングに注意
→ 排他ロックが発生するため、夜間バッチやメンテナンスウィンドウで実施 -
複数の順序が必要なら、パーティション分割や別テーブルの検討を
→ 順序単位でテーブルを分けた方が安定性・柔軟性が高い -
定期実行は不要。correlationが下がったときに実施
→pg_statsのcorrelationをANALYZE後に確認してから判断する
💡 補足
-
CLUSTERは指定したインデックス順でテーブル全体を並び替え、同時に統計情報も更新されるため、correlationの向上が期待できる -
ANALYZEは lightweight な統計更新コマンドで、物理順序の変更は行わない
7. 【おまけ】Oracleで実行計画を固定することの落とし穴
🎯 実行計画は“動的に最適化”されるのが前提
PostgreSQL や Oracle などのリレーショナルデータベースでは、
クエリの実行前に 統計情報や物理順序(correlation)をもとに、最適な実行計画を選択する仕組みがあります。
⚠️ しかし「実行計画の固定」には注意が必要
一部のチューニング手法では、特定の実行計画を「固定(フリーズ)」することも可能ですが、
これには以下のような リスク があります。
- 統計情報が更新されても、実行計画が変わらない
- データ分布が変化しても、非効率なスキャン方式が残り続ける
- → 結果として、パフォーマンスが劣化する
🔄 例:逆効果になり得るケース
- ヒット件数の増加やデータ増加によって、
本来はIndex Scan→Bitmap Scanに切り替わるべき状況でも、
古い実行計画のまま固定されてしまう
💡 PostgreSQLとの違い
| 項目 | Oracle | PostgreSQL |
|---|---|---|
| 実行計画の固定 | 可能(ヒント句 / SQL Plan Baseline) | 原則不可(ヒント無効・毎回生成) |
| 最適化の柔軟性 | 状況次第で固定できるが注意が必要 | 常に統計情報をもとに自動最適化 |
✅ 結論
実行計画を固定することで一時的な安定性は得られるかもしれませんが、
統計情報や物理順序の変化によって逆効果となるリスクも伴います。
チューニング時は、「固定」よりもまず、
統計情報の更新(ANALYZE)や、物理順序の見直し(CLUSTER)で自然に最適化させる方が安全です。
8. まとめ
✅ 統計情報と物理順序は、実行計画に影響する“見えない重要要素”
- 統計情報(件数・分布・カーディナリティ)と
物理順序(correlation)は、どちらも実行計画の選定に直結する - 特に
correlation ≒ 1の状態では、Index Scan が有利に選ばれやすく、I/O効率も高まる
✅ 検証で明らかになったこと
-
CLUSTERによって物理順序を整えると、correlationが1に近づく - これにより、スキャン方式が Bitmap → Index Scan に切り替わり、処理時間も大幅に改善
- 10種類のデータパターンでは75%以上の処理時間短縮を確認
🔧 チューニングの鍵は「適切なコマンドの使い分け」
| 操作 | 主な効果 | 使用タイミング |
|---|---|---|
ANALYZE |
統計情報の更新(軽量) | データ変更後に定期的に実行 |
CLUSTER |
物理順序の最適化+統計情報更新 | correlation が劣化した時 |
🚀 今後の応用ヒント
- correlation が高いカラムを WHERE に頻用するなら、CLUSTER の候補に
- UPDATEが多いテーブルでは、CLUSTERよりもパーティションや物理再設計を検討
- pg_stat_statements や auto_explain で、慢性的な遅延クエリの原因分析にも correlation が活かせる
💡 最後に
✅ 最適な実行計画は、統計と順序の“ダブルメンテナンス”から生まれる。
統計情報と物理順序の両面からチューニングを行うことで、
実行計画は「より正確に」「より高速に」なります。
ぜひ、correlationの監視と適切なタイミングでの CLUSTER 活用を習慣にしてみてください。