PHP カンファレンス福岡 2019 にて、「PHP の関数実行とその計測」という題でお話させていただきました。
使ったスライドは slideshare に上げていますが、話の内容の方もテキストとしてネット上にあった方がよい部分もあるかな、と思い、登壇時の原稿とスライドで使った画像から雑に記事を用意してみました。自己紹介のように明らかに不要な部分は抜いています。元が原稿なため、やや話し言葉っぽい部分があります。
内容の誤り等にお気づきの際はお気軽にコメント / PR いただければ助かります。
PHP の関数実行とその計測
今回話す内容は以下です。
- 1 つは PHP の関数実行の仕組みについて
- もう1つはその性能計測について
PHP で関数というのは、プログラムに行わせる一連の処理のまとまりです。
<?php
function sum(int $a, int $b): int {
return $a + $b;
}
echo sum(1, 2);
こんなコードのものですね。
まずはこのコードが処理系によってどう実行されているかの話からです。
Zend Engine の概要
この中に Zend Engine というのを聞いたことがある方はどのくらいいらっしゃいますでしょうか。
(けっこう手が上がる筈)
ありがとうございます、では Zend Engine が何のことか、雑になんとなく分かる、という方はどのくらいいらっしゃいますでしょうか。
(けっこう減る筈)
ありがとうございます。
Zend Engine は PHP の公式処理系のコア部分です。php.net で配布されている、いわゆる公式処理系です。かつて PHP 4 の頃に、 Zeev さんという人と Andi さんという人が中心となって、PHP 3 までの処理系を大きくリニューアルしました。彼らの名前から 2 文字ずつとって、Zend Engine と処理系のコアが名付けられました。
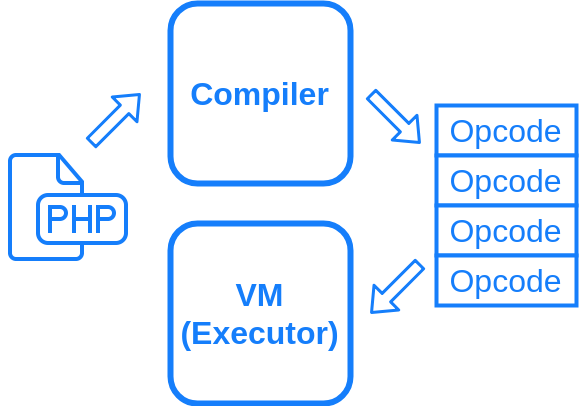
Zend Engineは、ざっくり言ってバイトコードコンパイラとバイトコードを実行するVM、仮想マシンから成ります。
バイトコードというのは仮想マシンの命令です。オペコードとも呼びます。
PHP コードが実行される際、Zend Engine のコンパイラがコードを ZendVM のオペコードの列にコンパイルします。ZendVM がこのオペコードの列から一つ一つ命令を取り出し、対応する処理を実行していきます。
大体こんな図になります。
実行部分をもう少し細かく見ると、だいたいこんな図になります。
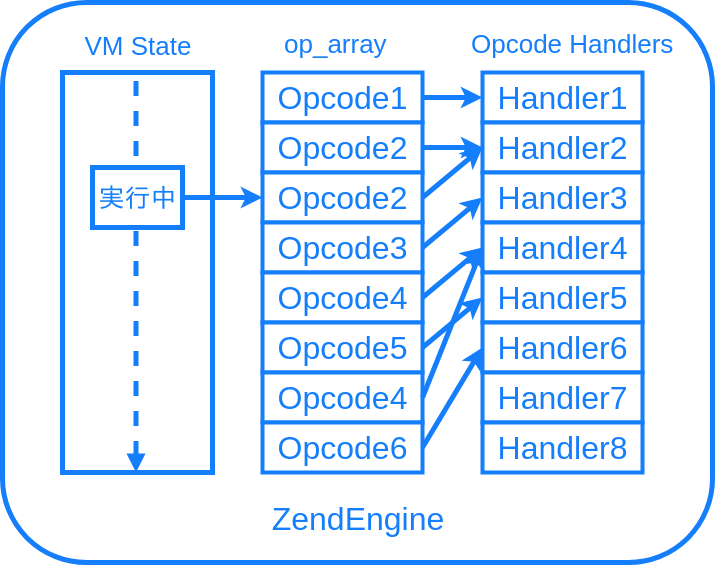
オペコードの列、VM の命令列を、Zend Engine では op_array と呼びます。オペコードの配列、ということです。op_array は関数ごとに作られます。
PHP コードをコンパイルした結果 op_array が作られて、VM が一つ一つ命令を取り出し、各命令に対応する C 言語側処理であるオペコードハンドラというものが、一つ一つ呼び出されていきます。
PHP っぽい疑似コードで表すと、大体こんな流れになります。
// 実際にはもう少し複雑
foreach ($op_array as $opline) {
// 例: [ADD, [1, 2]]
[$opcode, $operands] = $opline;
$handler = $opcode_handlers[$opcode];
$handler($operands);
}
op_array からオペコードとオペランドを取り出し、オペコードに対応したハンドラを取り出して、その処理を呼び出します。
なお、オペランドというのは命令にくっつけるパラメータです。例えば足し算。1 足す 2 を表すコードがあるとして、足す、ADD という命令に対応する 1 と 2 というのがオペランドです。
実際の処理系は最適化のためオペランドの種類に応じて特化したオペコードハンドラがあったりと、もう少し複雑です。が、概念的には大体こんな流れです。
PHP スクリプトがどうにかして仮想マシンの命令列に変換され、仮想マシンが命令列を実行していく、というのが、今のところの話の流れです。
その PHP コードがどう仮想マシンの命令に変換されるか、というコンパイル処理についても、少し駆け足で説明します。
コード実行の流れ

まず大まかな流れです。PHP のソースコードは最初に字句解析と呼ばれる処理で、言語の規則に従った単語みたいなものの集まりへと分解されます。次に構文解析と呼ばれる処理で、字面として言語のルールにちゃんと則ったプログラムになっているか、正しい文法で書かれている感じがするか、というのを判定します。同時に抽象構文木、AST と呼ばれるデータ構造をメモリ上に構築し、コード生成と呼ばれる処理がこの AST をてっぺんから解釈しつつ、op_array を構築していきます。
それでは、各段階についてもう少し細かく見ていきます。
字句解析
字句解析というのは、プログラムのソースコードを字句というものの集まりに分類し、分解することです。
さっきの PHP コードをもう一度ここで使います。
<?php
function sum(int $a, int $b): int {
return $a + $b;
}
echo sum(1, 2);
この PHP コードのそれぞれの部分は、↓のような形で字句に分割されます。
T_OPEN_TAG
T_FUNCTION T_STRING (T_STRING T_VARIABLE, T_STRING T_VARIABLE): T_STRING {
T_RETURN T_VARIABLE + T_VARIABLE;
}
T_ECHO T_STRING(T_LNUMBER, T_LNUMBER);
構文解析
構文規則
構文解析の処理はソースコードの先頭から字句を取り出していって、決められた構文規則に当てはめることができるか、PHP プログラムとして正しく書かれているか、というのをチェックする処理です。
処理系内で構文規則の定義には BNF という記法が使われています。
ざっくりいって、左側にルールの名前、右側にその構成要素と並び方が書いてあるような記法です。
関数定義に関する構文規則のみを、処理系のソースコードからはしょりつつ一部抜粋します。
top_statement: function_declaration_statement
function_declaration_statement:
function returns_ref T_STRING '(' parameter_list ')' return_type
'{' inner_statement_list '}'
returns_ref:
/* empty */
| '&'
parameter_list:
non_empty_parameter_list
| /* empty */
non_empty_parameter_list:
parameter
| non_empty_parameter_list ',' parameter
parameter:
optional_type is_reference is_variadic T_VARIABLE
| optional_type is_reference is_variadic T_VARIABLE '=' expr
optional_type:
/* empty */
| type_expr
type_expr:
type
| '?' type
type:
T_ARRAY
| T_CALLABLE
| name
name:
namespace_name
| T_NAMESPACE T_NS_SEPARATOR namespace_name
| T_NS_SEPARATOR namespace_name
namespace_name:
T_STRING
| namespace_name T_NS_SEPARATOR T_STRING
return_type:
/* empty */
| ':' type_expr
;
top_statement、つまり <?php から始まるトップレベルの PHP コードを指すルールがあります。その中では function_declaration_statement、つまり関数定義を書くことができます。関数定義は function から始まり、参照を返すかどうかの & 、関数名と続いて、引数をくくる括弧があって、parameter_list、つまり引数リストがあります。その後返り値の型宣言、続いて波括弧があり、inner_statement_list、つまり関数の中身の文のリストがあって、という構造になっています。
この parameter_list とか inner_statement_list というのにも同様の形でルール定義があります。このルールはこういう内容から成り、そこに出てくるこのルールはこういう内容から成って、というのを繰り返していくと、最終的には字句解析で切り出されるような言語の字句の集まりが残るようになっています。
具象構文木
さっきの字句解析結果に構文規則を当てはめると、
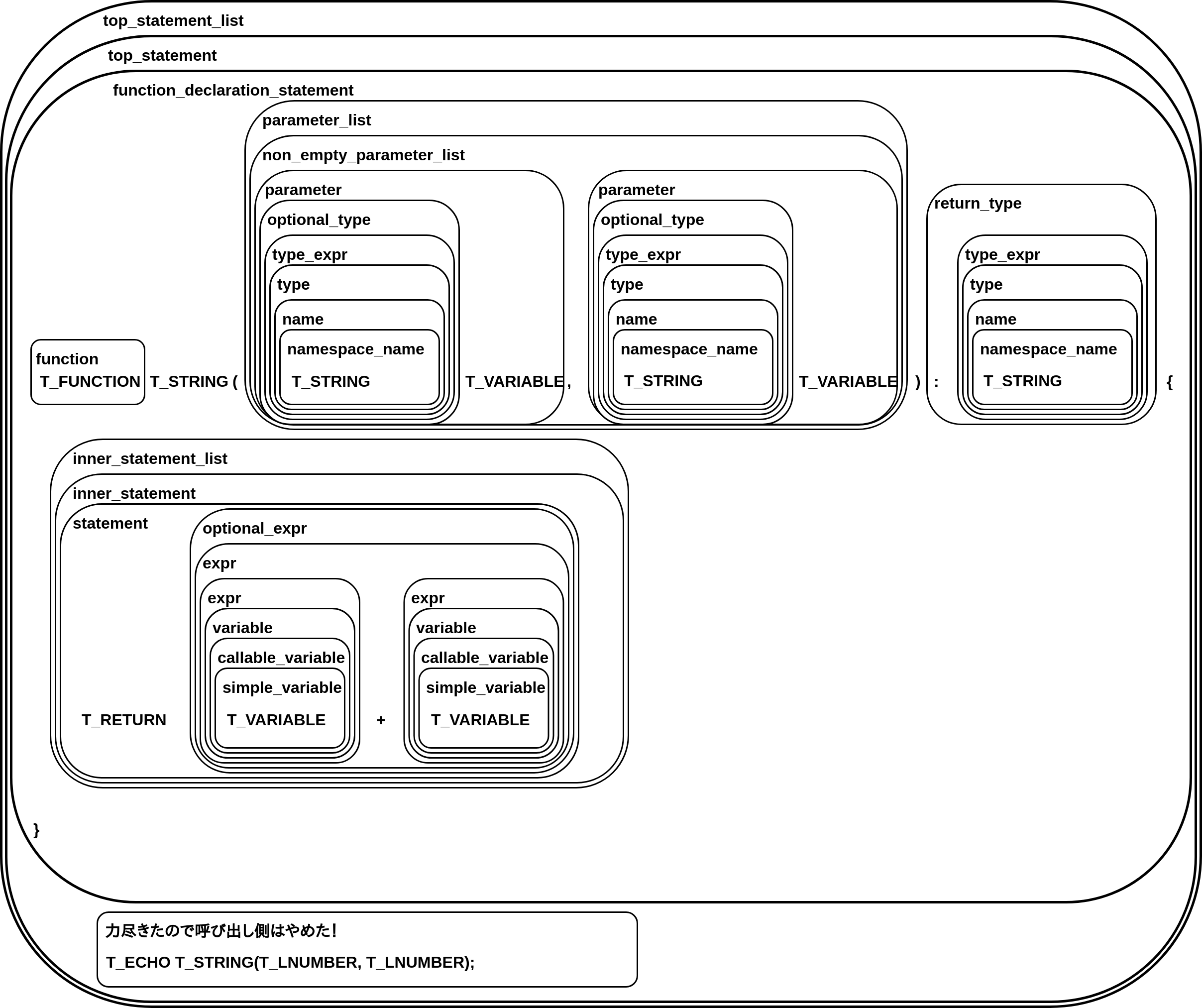
こんな感じになります。
構文解析の処理は、このようにプログラムへ構文規則を当てはめて、コードが正しく書かれているか、というのを判定する処理となっています。これは字句の列からプログラム全体を表す構文規則へ収束していく、ある種のツリー構造を構築することが出来るかを確かめていくような処理となっています。
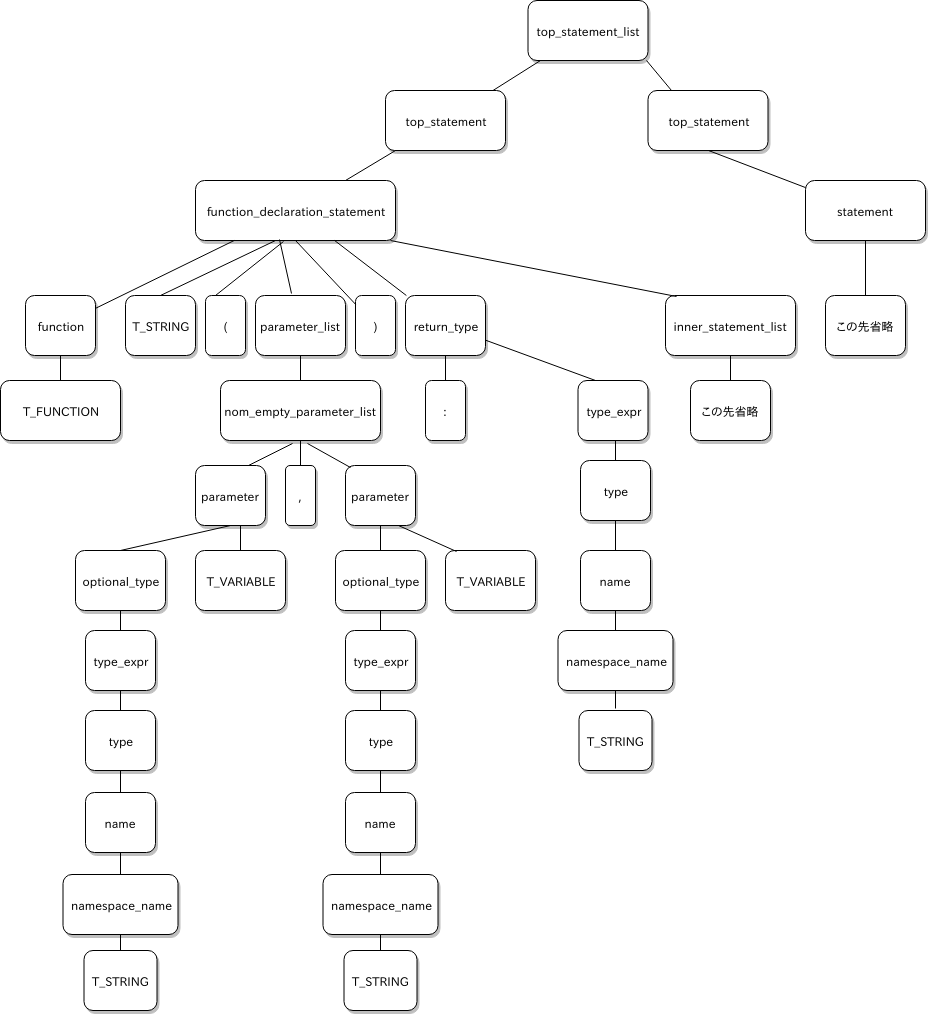
「コードのこの部分はこういう構文規則の一部で、またその部分は別の構文規則の一部で、それがまた別の構文規則の一部で」という入れ子構造のデータからツリー構造を導き出すのは、日頃から入れ子構造の HTML と DOM ツリーの間を行ったりきたりしてきた PHP 使いの皆さんには、案外馴染みのある話なんじゃないかな、とも思います。
構文規則をソースコードへ当てはめることで作ることのできるツリー構造を、具象構文木と呼びます。コードを正しくツリー構造へ当てはめられるなら、コードの各部分がどういう役割と対応しているか、の分類が、そこそこできている状態ということにもなります。実マシンや仮想マシンで実行するコードを生成する際、この情報を使えると便利そうです。
AST(Abstract Syntax Tree)、抽象構文木
具象構文木からコード生成に使える情報だけを残したものを、抽象構文木、Abstract Syntax Tree とか AST とか呼びます。PHP の構文解析処理は、この AST の生成をプログラムの構文上の正しさの検証と同時に行っていきます。
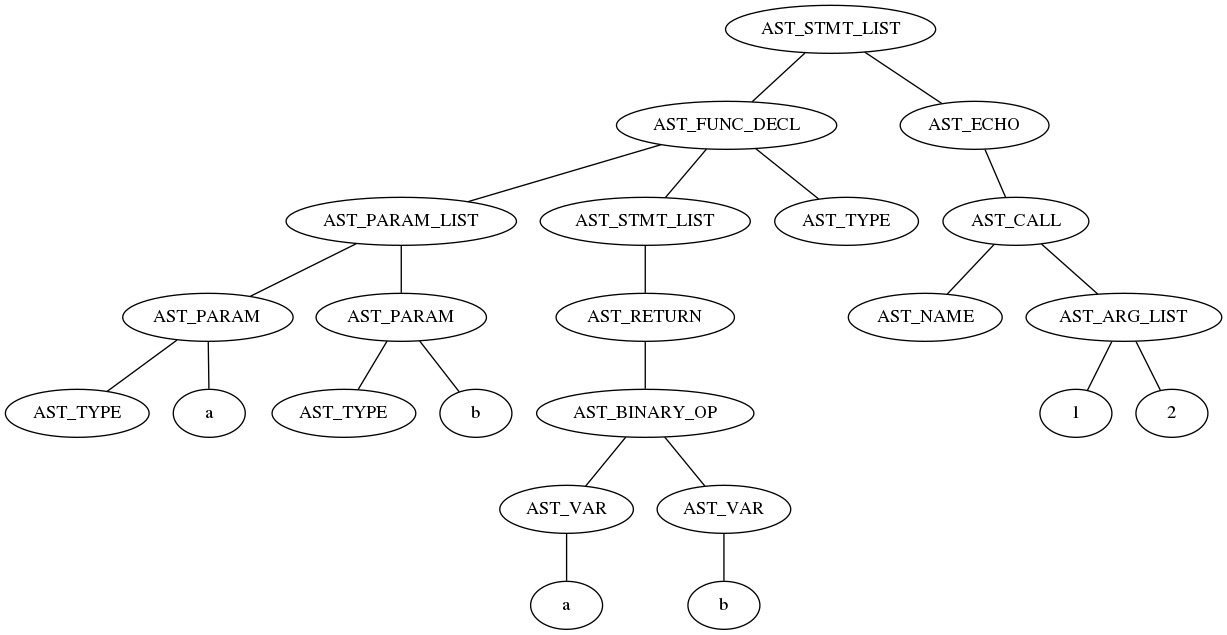
上図は nikic/php-ast でのダンプ内容から、 php-ast 側で利便性のために追加するノードを取り除いて Graphviz で出力したものですが、具象構文木からだいぶ内容が簡略化されているのが分かります。
AST からのコード生成
最終的に、コンパイル処理は AST を上から順にたどって、オペコードを生成していきます。
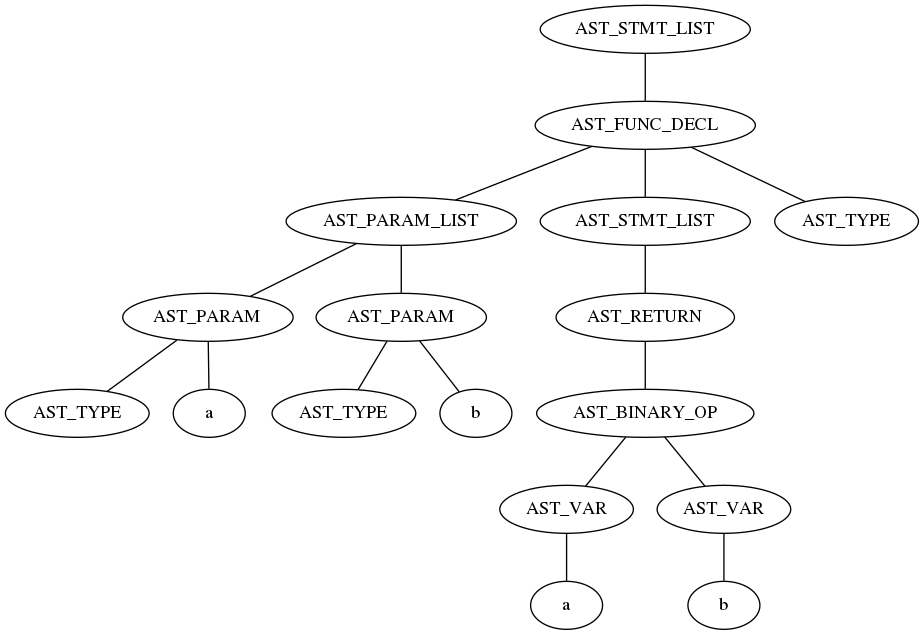
これは先ほどの AST から関数の定義部分のみを抜き出したものです。
これがこんな感じ↓に処理されます。
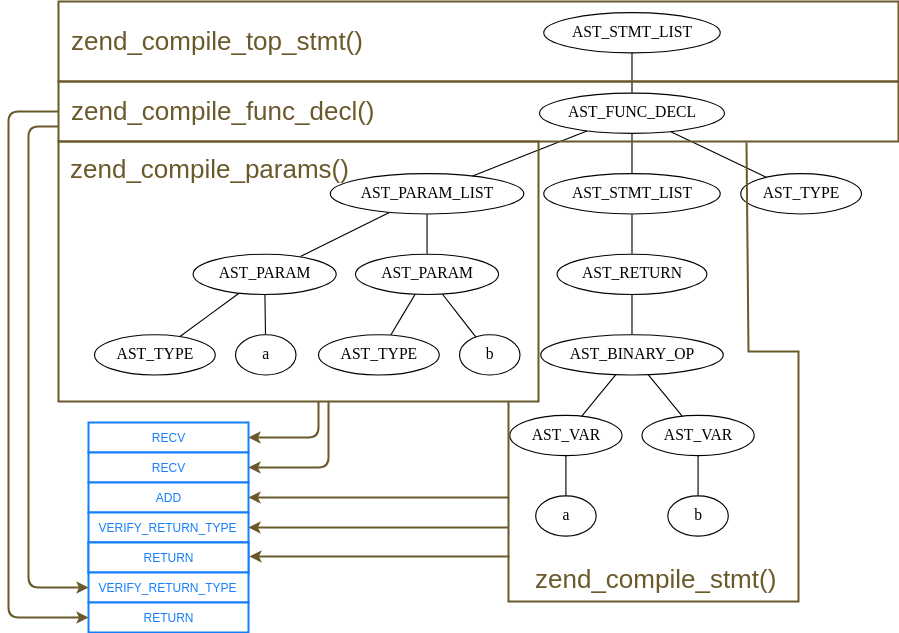
まず zend_compile_top_stmt() という関数が処理系内で呼ばれて、これが top_statement、トップレベルのコードと対応します。
zend_compile_top_stmt() は AST の子ノードを順繰りにたどり、ZEND_AST_FUNC_DECL、つまり関数定義と対応するノードがあれば、zend_compile_func_decl() を呼び出します。そこで新たな op_array を用意したり、処理系内部の関数登録表へその op_array を登録します。その後 AST の子ノードから更に引数リストや処理本体と対応するノードを取り出して、zend_compile_params() や zend_compile_stmt() といった、それぞれのノードを処理するための関数を呼び出していきます。こうして少しずつ op_array へオペコードを詰めていきます。
※ 作図の問題で返り値型宣言と対応する AST_FUNC_DECL の子ノード AST_TYPE が処理されていないように見えますが、本当は zend_compile_params() で引数ノードの AST_PARAM_LIST とあわせて読み込まれて処理されています
今回のコードは結果としてはこんなオペコードとなります。
$_main:
INIT_FCALL 2 128 string("sum")
SEND_VAL int(1) 1
SEND_VAL int(2) 2
V0 = DO_UCALL
ECHO V0
RETURN int(1)
sum:
CV0($a) = RECV 1
CV1($b) = RECV 2
T2 = ADD CV0($a) CV1($b)
VERIFY_RETURN_TYPE T2
RETURN T2
VERIFY_RETURN_TYPE
RETURN null
関数と op_array
さて、このような過程で PHP のソースコードがオペコードの配列へ変換されるわけですが、先程の説明でちょっと触れたように、このオペコードの配列、op_array は関数ごとに作られます。では関数定義の中にない PHP ファイルのトップレベルのコードはどうなるでしょうか。これについては、ファイルを読み込んでコンパイルした直後に呼び出す擬似的な main() 関数があるかのように、独立した op_array へコンパイルされます。
だいたいこんなイメージです。
<?php
// function 擬似的なmain関数() {
function sum(int $a, int $b): int {
return $a + $b;
}
echo sum(1, 2);
// }
まとめるとこのようになります。
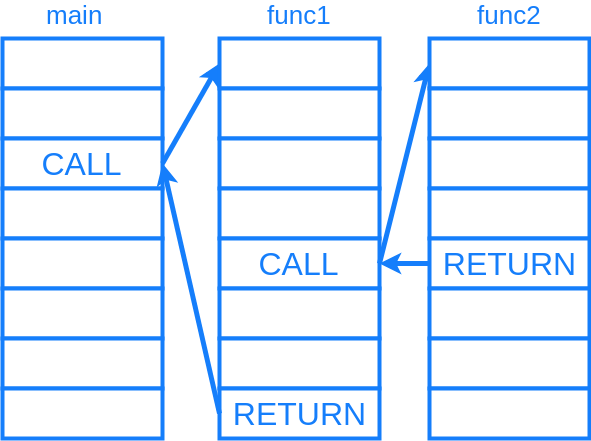
トップレベルの疑似main関数用の op_array があって、そこから呼び出す関数には別の op_array があります。もちろん、さらにそこから呼び出す関数にも独立した op_array があります。関数呼び出し命令で VM の実行は別の op_array へジャンプして、リターンすると呼び出し元へジャンプする、というような形になります。
こんな感じで関数ごとに op_array が存在します。
関数呼び出しのオペコード
さて、ここまで説明したところで、あらためて先程の PHP コードとそのコンパイル結果をもう一度見てみます。
<?php
function sum(int $a, int $b): int {
return $a + $b;
}
echo sum(1, 2);
$_main:
INIT_FCALL 2 128 string("sum")
SEND_VAL int(1) 1
SEND_VAL int(2) 2
V0 = DO_UCALL
ECHO V0
RETURN int(1)
sum:
CV0($a) = RECV 1
CV1($b) = RECV 2
T2 = ADD CV0($a) CV1($b)
VERIFY_RETURN_TYPE T2
RETURN T2
VERIFY_RETURN_TYPE
RETURN null
トップレベルのコード、疑似 main 関数は INIT_FCALL 'sum' という命令から始まり、SEND_VAL 1 と SEND_VAL 2 が続き、DO_UCALL、RETURN で終わります。関数 sum では RECV という命令が 2 つ続き、その結果を ADD という命令に渡した後、更にその結果を VERIFY_RETURN_TYPE 命令に与え、RETURN 命令に渡します。
DO_UCALL が関数を呼び出す、つまり VM の次の命令実行を別の op_array へジャンプさせる命令で、ADD が 2 つのオペランドの加算結果を出力する命令、VERIFY_RETURN_TYPE が返り値の型検査を行う命令、ということは、命令の名前からなんとなく分かりやすいのではないかな、と思います。
少し分かり辛いかもしれないのが、INIT_FCALL と SEND_VAL、RECV です。これらは VM のスタックに関する命令です。
VM スタック
ZendVM は実マシンのスタックと別に、VM の実行状態を保持するためのスタックを持ちます。使っている内に確保したメモリ領域が足りなくなったら、新たに確保して単方向リストでつなぐ、という形で管理されています。VM スタックには関数の呼び出し状況や変数等、VM の実行状態が保持されます。関数が呼び出されるたび、INIT_FCALL の実行によって、この VM スタック内へコールフレームと呼ばれる領域が確保されます。
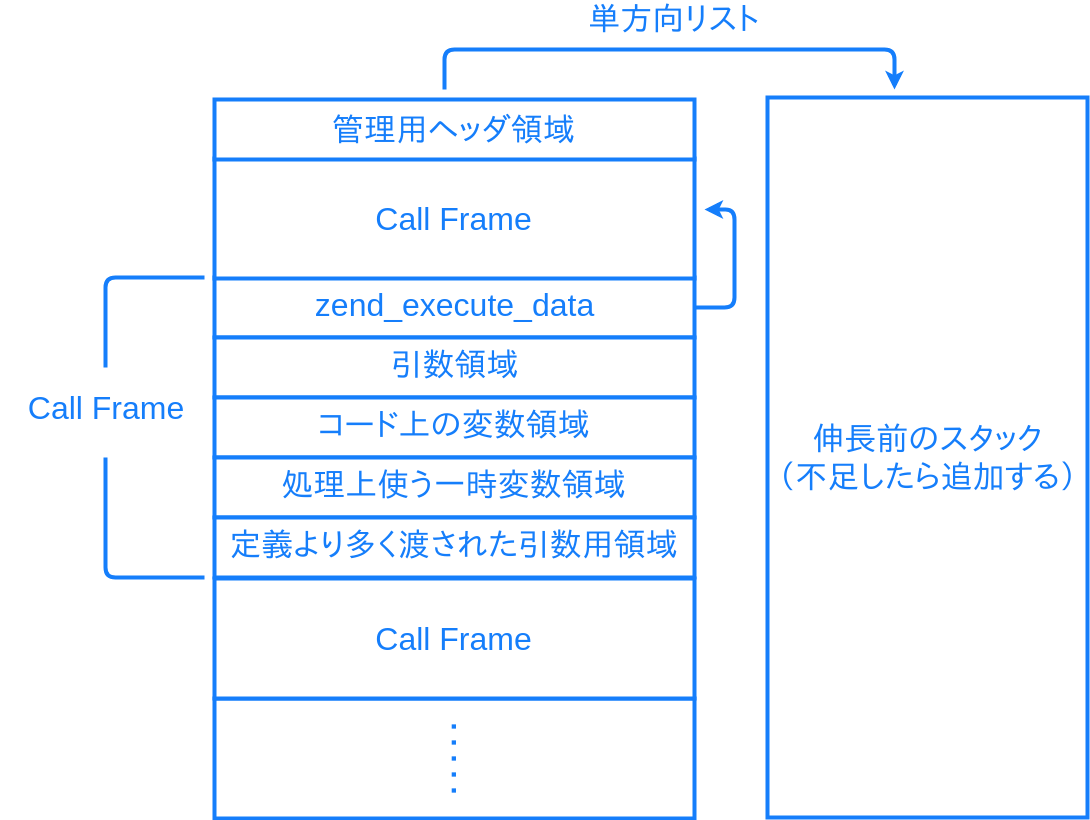
だいたい上図のような内容です。
コールフレームの先頭には zend_execute_data という、実行中の関数やオペコード、RETURN 先を得るための呼び出し元コールフレームへのポインタなどの情報を持つ構造体があります。続いてその関数の引数用のメモリ領域、変数や一時変数用のメモリ領域がコールフレーム内に配置されます。関数の呼び出し側は SEND_VAL 命令でこのコールフレーム内の引数用の領域へデータをコピーし、呼び出された側は RECV 命令で引数用の領域から値を取り出して、必要な型検査を行います。
ファイルがコンパイルされる時
あらためて PHP コードがコンパイルされるタイミングからの流れをまとめると、このようになります。
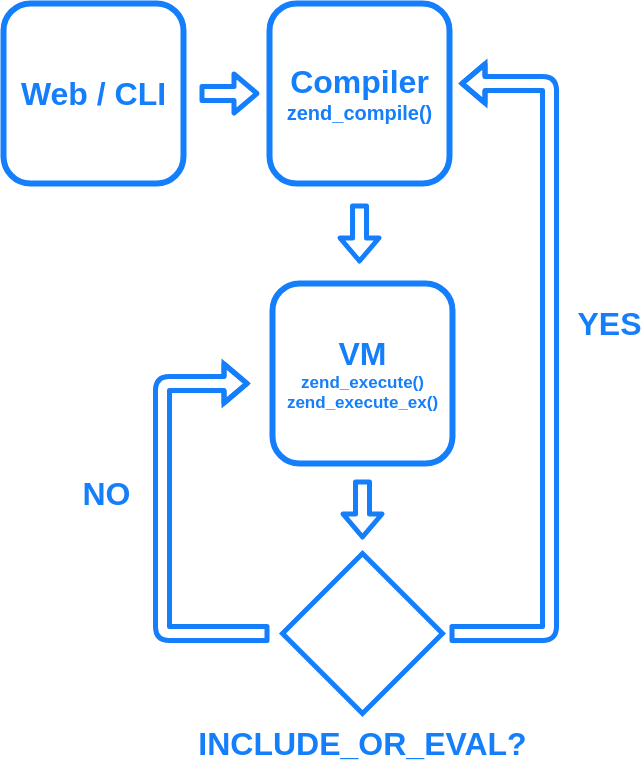
コマンドラインなら起動時に与えるファイル名で、Web なら Web サーバがアクセスされた URL に対応するパスを与える形で、処理系へ実行する PHP ファイルが指示されます。
まずソースコードを zend_compile() という内部処理でコンパイルし、関数ごとの op_array が生成されます。zend_execute() という処理が zend_execute_ex() という別処理を呼び出し、疑似的な main 関数に対応する op_array 内の命令を、VM が順繰りに実行していきます。
もしその op_array 中で、INCLUDE_OR_EVAL、 という PHP コードの include や eval に対応する命令が実行されると、別の PHP スクリプトが読み込まれ、コンパイルされます。そして読み込んだファイルに対応する擬似的な main 関数が呼び出されます。
と、いう感じにスクリプトの処理が進んでいきます。
executor_globals (EG)

処理系がその時々でどういう状態にあるか、どの op_array のどのオペコードを実行しているか、という情報は、executor_globals という構造体に格納されています。VM の全ての実行状態を取得できる、非常に重要な構造体です。executor_globals にはシンボルテーブルや関数テーブル、VM スタックへのポインターといった情報があります。current_execute_data という構造体へのポインタをフィールドとして持っていて、これを通して実行中の関数、そしてその op_array のどこを実行しているか、といった情報が得られます。ポイント先は関数呼び出し時に VM スタックのコールフレーム先頭へ確保される構造体そのもので、関数呼び出しやファイル読み込みで実行中の op_array が切り替わるたび、つど更新されます。ZendVM が命令を実行していくに従って、これらの情報がメモリ上で都度更新されていくわけです。
処理系の標準処理のフック
ここまで話してきた Zend Engine の動作は、拡張を通してある程度カスタマイズすることが可能です。
例えば、先の話に出てきた zend_compile(正確にはそれを呼び出す zend_compile_file)、zend_execute_ex、といった処理は処理系内部では関数ポインタになっており、拡張からその実装をフックして差し替えることが可能です。標準のコンパイラが AST を構築した後のタイミングには zend_ast_process という関数ポインタが呼び出されますし、zend_set_user_opcode_hadler では特定のオペコードに対応するオペコードハンドラを差し替えるようなこともできます。このように、拡張から内部処理をフックできるポイントは幾つかあります。
実際に xdebug や opcache といった拡張は、これらの処理を目的に応じて差し替えることで機能しています。zend_execute_ex をフックすると、例えば PHP の全関数呼び出しの前後へ時間計測関数を挟み込み、差分を記録していく拡張を作ることも可能です。
Zend Engine の話のまとめ
以上、少し駆け足でしたが、Zend Engine における関数実行のされ方について説明をしてきました。
Zend Engine における関数実行の仕組み、なんとなくのイメージはできましたでしょうか。
PHP のソースコードが字句に分解され、構文が検査されるとともに AST が構築され、関数ごとオペコードの配列へコンパイルされます。VM が一つ一つオペコードを取り出し、executor_globals や VM スタックといった内部状態を更新しながら動作していきます。そしてそれらコンパイラや VM の処理の一部は、拡張を通して差し替えることができます。
それでは次に、PHP コード、関数の実行性能はどのようにして計測できるか、というお話をさせていただきます。
関数実行の計測
趣味やお仕事でプログラムの高速化をしよう、という話があったとします。
例えば PHP のファミコンエミュレータで、マリオが 6 FPS しか出ないから、60 FPS 目指してみようか、とかそういう時ですね。
こんな時、とりあえず何をすればいいか分かりますでしょうか?
「推測するな、計測せよ」
はい、とりあえず計測です。誰がこんなオヤジギャグみたいなうまいこと言ったのか分かりませんが、きっと日本人なのでしょうね。しかしそれにしてもうまいこと言ったものです。
ボトルネック
システムの中で特に遅く、他の足を引っ張っているような部分を、そのシステムのボトルネックと呼びます。
ボトルネックを見つけ出し、遅くなっている原因を取り除いてやることで、効率的にプログラムの性能改善を行っていくことができます。ボトルネックを見つけ出すには計測が必要です。
原始的計測
先のコードを使い回し、関数 sum の実行時間を計測してみます。
<?php
function sum(int $a, int $b): int {
return $a + $b;
}
$start = microtime(true);
$result = sum(1, 2);
$end = microtime(true) - $start;
}
実行前に Unix エポックからのマイクロ秒で現在時刻を取得します。
実行後同様に時間を取得して、実行前の値との差をとります。
これは PHP プログラムを計測する際の、非常に原始的な方法です。
このやり方には良い部分も悪い部分もあります。
原始的計測の良いところ
例えば良いところは、追加のライブラリやツールのインストールが要らないことです。
また、だいたい Controller の処理が実行される前まで、とか、View のレンダリングが開始してからリクエストが終了するまで、とか、任意の区間を対象に計測をとることができます。
DB アクセスやキャッシュアクセス等の共通コードに仕込むことで、実行時間の大枠をつかめるようにもなります。
原始的計測のびみょいところ
ただし、この方法では計測箇所ごとにコード修正が必要です。
細かく見た時にどこがボトルネックになっていそうかな、というのを推測したり、外れた時や改修の過程でボトルネックが変わった際は人力二分探索気味に、計測区間を変えながら計測用の実行を繰り返す必要ができたりします。
DB アクセスがボトルネックな場合は、クエリを実行する共通コードへ時間計測を仕掛けて、クエリごとに実行時間を記録することで性能改善に取り組むこともできます。が、ボトルネックが PHP コード側にある場合、「うーんこの array_map() が遅いんだろうか……?」というように、見るもの全てが容疑者に思え、どこに時間計測を仕掛ければいいのか分からなくなってしまいます。
ここでプロファイラを使うことで、人力でコードを修正してつどつど時間計測処理を仕込むことなく、ほぼ無修正のプログラムをいい感じの区間で計測することができます。
Profiler とは
プロファイラは性能解析のためのツールです。プログラムの各処理の実行時間を収集し、統計情報を出力します。
2 種類の計測方式
PHP には大きく分けて 2 種類のプロファイラが存在します。
一つは関数呼び出しフック方式(以下フック方式)、もう一つがサンプリング方式です。
それぞれ特徴があり、この記事の前半で説明した Zend Engine に関する知識が少しあると、理解が若干簡単になります。
それではまず、フック方式の話から始めます。
フック方式
Zend Engine についての説明の最後の方で、zend_execute_ex()、つまり op_array 内のオペコードを VM に実行させる処理は、処理系内で関数ポインタとなっており、拡張から差し替えることができる、という話をしました。
この zend_execute_ex() を差し替え、まず開始時刻を取得し、元々の zend_execute_ex() のオペコード実行処理を呼び、終了時刻を取得して、その差分を記録する、という処理へ替えます。
全関数呼び出しの実行時間が自動的に記録され、呼び出し階層のどの部分で何から呼ばれた何に処理時間がどれだけかかった、ということが、ほとんど全て把握できるようになります。
これがよくあるフック方式のプロファイラの仕組みの例です。
フック方式のプロファイラは幾つか存在し、いずれも処理系へ組み込んで使うC言語拡張として提供されています。デバッガの xdebug に付いているのもフック方式ですし、xhprof や xhprof から派生した tideways、blackfire、spx といったプロファイラもあります。
この中で特に他への影響が大きいと言えるのは xhprof なので、とりあえず xhprof についての話から始めます。
xhprof
xhprof は Facebook 製の拡張です。
基本的な動作原理は、先にフック方式のプロファイラの仕組みの例として話した通りのもので、全関数呼び出しをフックするものです。OSS として公開されていたことで、後に blackfire や tideways といった他プロファイラへ派生しています。
xhprof が出るまでは xdebug が唯一のPHPプロファイラでしたが、xdebug のプロファイラは尋常でなく重く、一方 xhprof はたまに動かす分には本番環境でさえ使える軽さ、というのがウリでした。
しかしFacebook が HHVM へ移行し ZendVM を捨てたことで、PHP7 をサポートしないまま破棄されてしまいました。
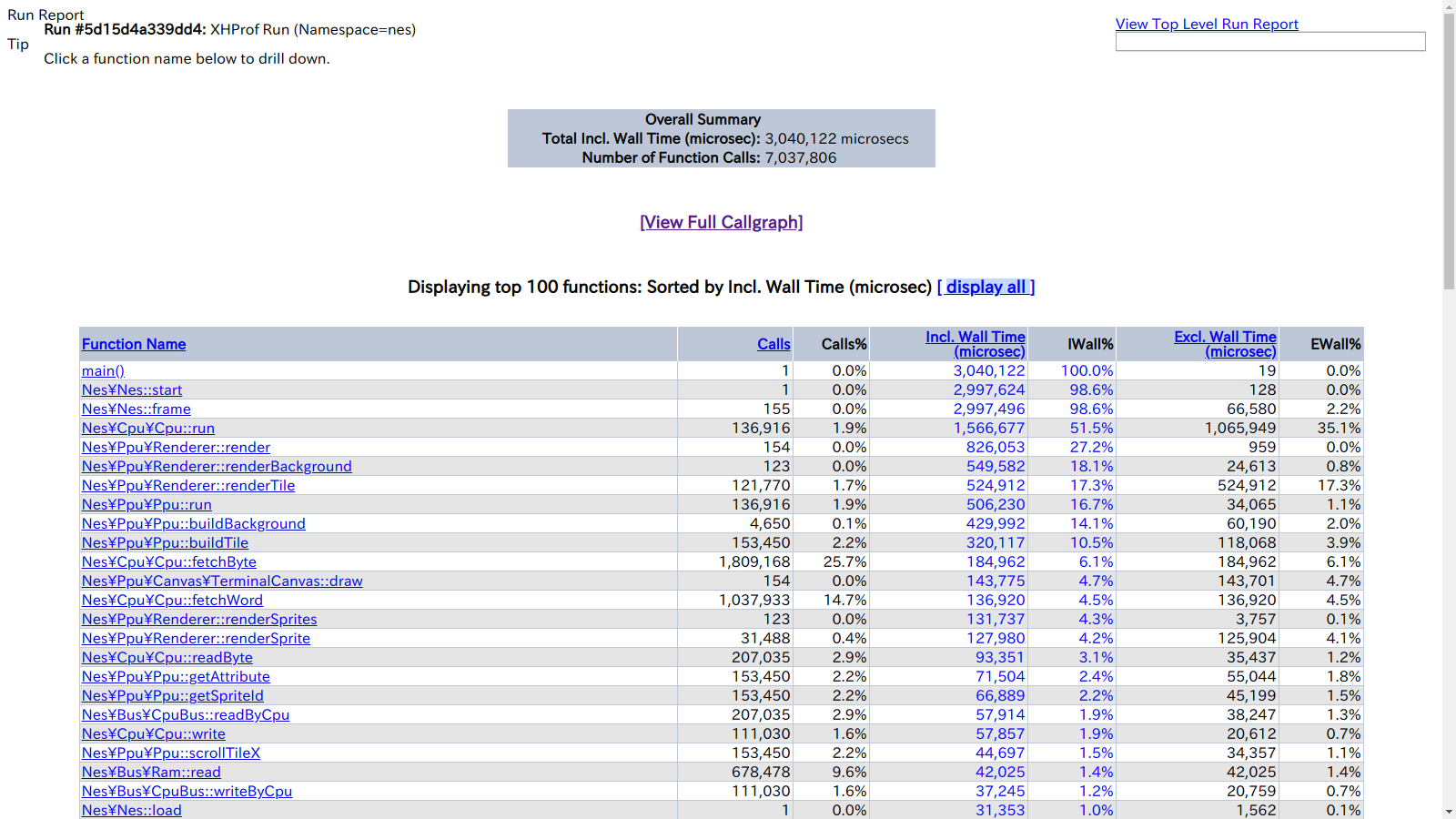
こんな感じにブラウザからプロファイル結果を見ることができます。
標準ではファイルへプロファイル結果を吐き出すのですが、データベースへ蓄積したプロファイル結果を見るためのサードパーティのビューアも幾つか存在します。
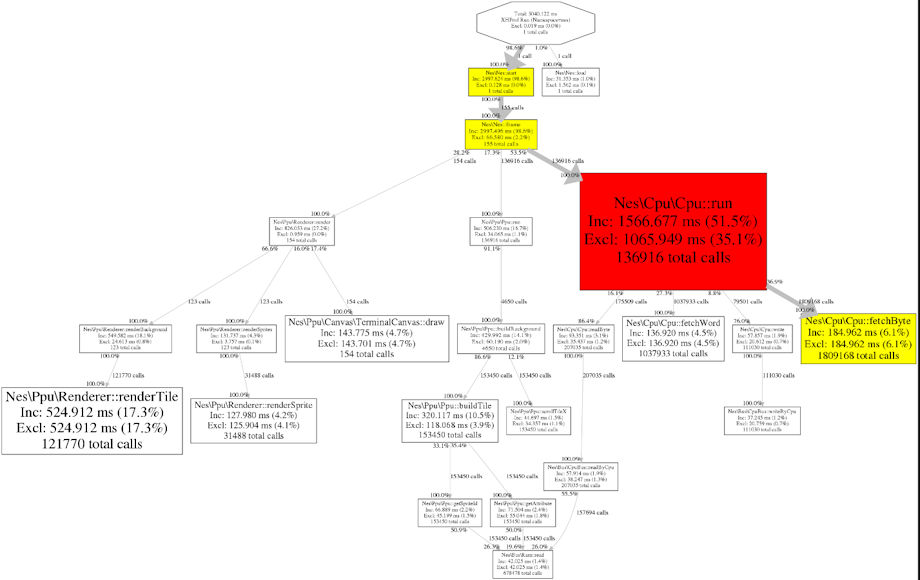
コールグラフとかも見れます。
tideways
xhprof から派生したプロファイラの 1 つに、tideways というプロファイラがあります。
tideways は xhprof 派生の拡張と PHP 側から利用するクラスライブラリ、SaaS のセットです。
拡張側は元は xhprof へ区間計測機能のような新機能を追加したオープンソースのものでしたが、後に 0 からコードがリライトされ、同時に拡張のコードもクローズドソースになっています。
しかし tideways 本体の拡張がクローズドソースになってからも、xhprof 互換機能のみを切り出した tideways_xhprof が OSS として公開されています。
tideways_xhprof は PHP7.3 にも対応しており、xhprof 互換の無料で使えるプロファイラの中では特によくメンテされてるものです。
中のコードは元の xhprof よりきれいですし、性能も元の xhprof より良いです。
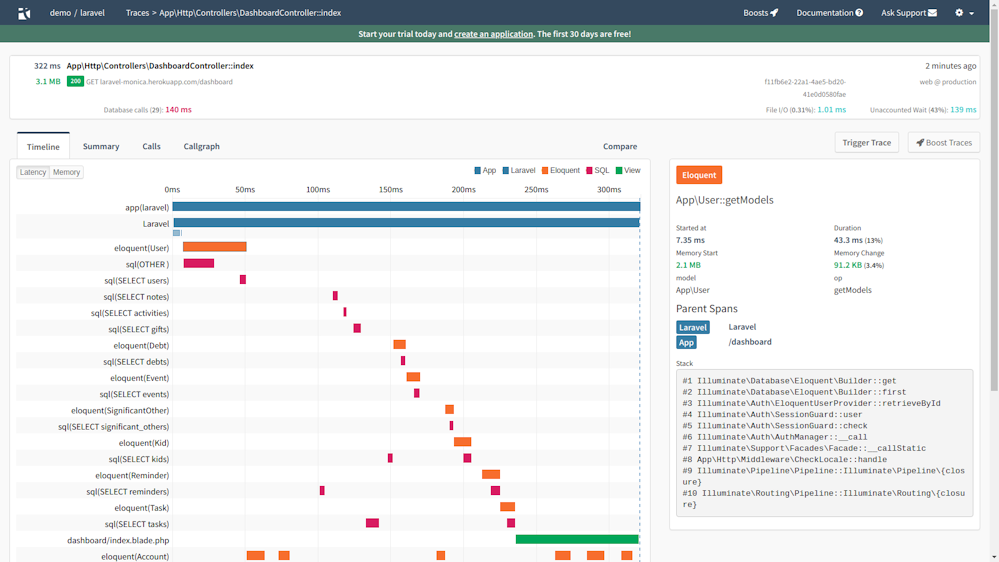
SaaS の方の tideways は大体こんな感じです。xhprof 形式で実行時間を集計する機能と別に、区間計測データを集めて視覚的に表示するような機能も付いています。これは xhprof 形式の計測より計測負荷も低いみたいです。
要件やコスト感が合えばぜひ SaaS の方を契約して買い支えてあげてください。
フック型の計測オーバーヘッド
これらフック型のプロファイラに共通して言えるのは、計測時のオーバーヘッドに注意する必要がある、ということです。
例えば Zend Engine には、zend_execute_ex が拡張によってフックされている場合に限って無効になってしまう最適化があります。拡張からのフックがない場合、ユーザ定義関数の呼び出しは他命令と同じ VM のループの中で、 zend_execute_data を差し替えながら実行されます。が、これは再帰をループへ展開する類の最適化が行われた結果の現状実装であり、zend_execute_ex がフックされている場合はこの最適化が無効となり、関数呼び出しごとに zend_execute_ex を再帰的に呼び出すという古い挙動へフォールバックします(これのおかげで、 zend_execute_ex をフックして関数実行を監視する拡張が動作し続けられています)。
当然、実行時間を取得して記録する処理自体にもわずかながらオーバーヘッドがあります。
関数本体の実行時間が長い場合には誤差でしかないようなものですが、これらがほぼ固定時間で全ての関数呼び出しにかかる、というのが問題です。

※ この図どうせならもう少しやばそうな差にした方がよかったですね、気が向いたら差し替えます
1 つ 1 つの実行は高速であるような関数が、何万回も大量に呼び出されることを考えてみてください。
チリツモで計測負荷が大きく効いてくることになり、なんなら本体の処理より計測負荷の方が大きいような状況になってしまうこともあります。
本当は大した時間のかからない速い処理なのが、呼び出し回数が多いばかりに計測負荷の分で遅く見えてしまい、本来のボトルネックを隠してしまうことさえあり得ます。
呼び出し回数に応じ計測負荷が各関数に対して非対称な影響を与えてしまう、というのは、フック型プロファイラで広範囲な計測を取ろうとすると避けられない問題です。
※ 一応、多く呼ばれる関数を計測対象から除外するという軽減策はあります。
PHP 8 の JIT
来年冬にリリースされる PHP8 には JIT コンパイラが導入されることが決まっています。I/O バウンドな処理についての負荷はあまり変わりませんが、CPU 負荷の高い、それこそ速い関数が大量に呼び出されるようなユースケースも今後ある程度増えていくのではないかと思われます。この際、VM の実行方式が変わることで zend_execute_ex のフックによる性能計測は機能しなくなる可能性があります。zend_ast_process あたりのフックにより拡張から AST 操作を行う等して、関数呼び出しごとに自動で計測処理を挟み込むようにする、という手はあります。が、命令の実行速度が上がり、その恩恵を受けられる(PHP 側処理を多く行う)コードを実行する以上、計測処理のオーバーヘッドは割合としては上がりがちとなり、合計オーバーヘッドがやばくなる問題はおそらくますます避けがたくなります。
フック方式まとめ
フック方式のプロファイラについてまとめます。あらゆる関数呼び出しを計測可能で、計測する箇所ごとに計測コードを差し込まなくても使えます。ただし計測対象を大量に呼び出す場合は計測オーバーヘッドが大きくなってしまいます。重めの I/O 等、1 回あたりの実行時間が長い分かりやすいボトルネックがある場合に便利です。
サンプリング方式
フック型の問題を解決できるのが、サンプリング方式のプロファイラです。
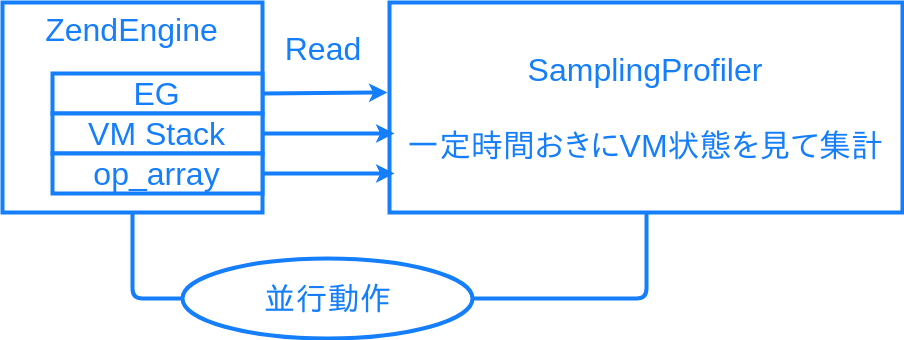
計測対象と平行動作するプログラムにより、VM の実行状態をサンプリングして監視します。
ExecutorGlobals から実行中の命令位置などの内容を定期的に読み取り、よく実行されている箇所が重い箇所、ということになります。
サンプリング方式の例
サンプリング方式のプロファイラは今のところあまり種類がありません。知る限りでは nikic/sample_prof、そして adsr/phpspy、その他に krakjoe/trace というものもあります。
今回はこのうち sample_prof、phpspy を順に取り上げます。
sample_prof
sample_prof はフック型のプロファイラと同様 、C 言語拡張として作られています。フック型プロファイラは関数レベルの解像度でしか計測をとれませんが、sample_prof ではソースコードの行レベルでコードのどのあたりが頻繁に実行されているかを計測することができます。行レベルでの計測がとれることで、各関数に散在する変数代入がチリツモで遅い、とか、極度に CPU バウンドな処理で型検査のコストが重い可能性とかにも気付くことができます。
内部ではプロファイラの開始時に pthread_create() でスレッドを起動し、指定したサンプリングレートで計測スレッドが VM の内部状態を監視するようになっています。
// 起動自体は他プロファイラと似たような方法でいける
sample_prof_start(50); // ここでスレッド生成
register_shutdown_function(function(){
sample_prof_end();
$data = sample_prof_get_data();
file_put_contents(uniqid() . 'prof.txt', serialize($data));
});
スレッドはメモリ空間を共有するので、別スレッドから普通に ExecutorGlobals が読めるわけです。
また PHP スクリプト本体の処理と別スレッドで計測スレッドが動くということは、CPU コアが余っていればあまり本体の処理に影響を与えずに計測がとれます。仮にコアが余っていなくても、OS がいい感じにスケジューリングしてくれる限り、少なくとも計測対象の関数が速く多く呼ばれる場合の負荷の非対称性は生まれません。
sample_prof はスレッドで動く C 言語拡張なので、ある種のなるほど感があります。まあ動くだろうな、という感じです。
sample_prof と違い、明らかに頭がおかしいことをやっているのが phpspy です。
phpspy
phpspy はスタンドアロンの C 言語プログラムで、PHP の拡張ではありません。
どういうことかというと、こんなふうに実行中の PHP プログラムが何をしているかを別プロセスから覗き見ることができます。
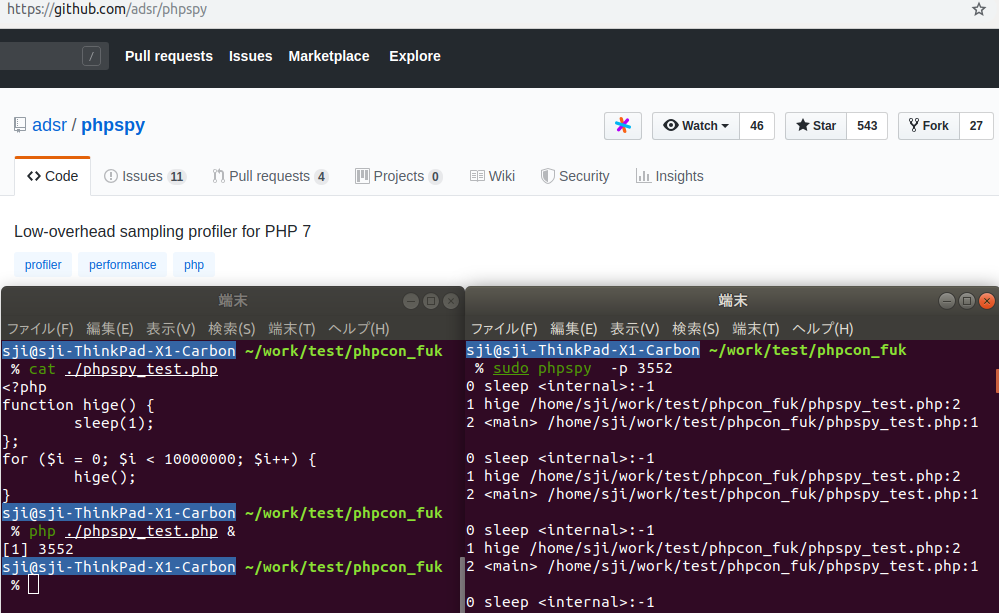
もうパッと見で意味が分からない、という感じがします。
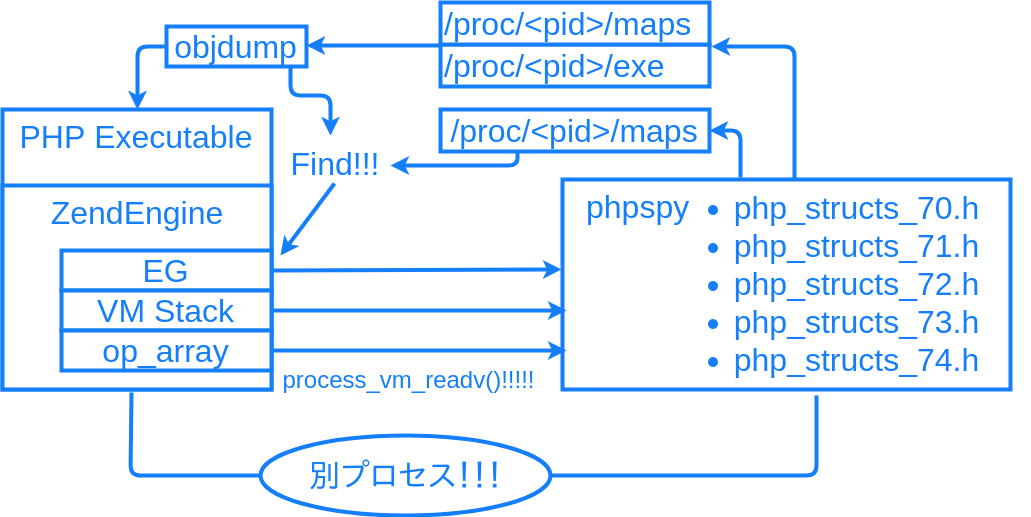
phpspy は各バージョンの PHP 処理系の ExecutorGlobals 等、構造体のメモリレイアウトについて自前で情報を持っています。/proc/<PID>/maps や PHP バイナリの ELF ヘッダ等の情報を読み取って強引に各構造体のアドレスを特定し、process_vm_readv() で読み取って、完全にプロセス外から VM の実行状態を解析します。
各関数の実行性能を読み取れるばかりか、実行中のスクリプトの変数の値を覗き見ることさえできるのです。
それも、拡張インストールやスクリプト中での計測の開始処理などを一切必要とせずにです。
元々は Ruby で同様のことをやっている rbspy というのがあり、それのパクリだそうです。
rbspy を作った人が超楽しそうに解説をしてる動画があるので、興味のある方はぜひ見てみてください。
サンプリング方式のまとめ
サンプリングプロファイラについてのまとめです。サンプリングプロファイラは計測対象の処理に影響を与えずに、性能解析を行うことができます。サンプリングのため、サンプリングレートによっては取りこぼしてしまう関数実行もあり、全ての呼び出しを確実に記録してプログラムの実行のされ方を観察する、という使い方には向きません。大量に呼び出される関数でも計測オーバーヘッドの累積が起きず、どのあたりがボトルネックになっていそうか、という点については比較的正確なイメージを得ることができます。
おしまい
気が向いたらたまに内容を拡充したり説明を丁寧にしたり図を親切化したり実際のコードへのハイパーリンクを足したりしたい、という気持ちだけはあります。気持ちだけはね!