はじめに
本記事では、S3上に収集したGitLabのデータをAmazon Athena/AWS Glueを利用して分析できるようにします。この記事では大きく「Glue クローラーによるData Catalog(構造)化」と「AthenaによるData Catalogを利用したS3データ読み取り」の2つを説明します。
前回までの記事は以下をご覧ください。
なお、本記事の正確性や完全性について保証しませんので、ご注意ください。
Glue クローラーによるData Catalog(構造)化
AWS Glue は AWSのページでは以下のように説明されています。
AWS Glue は、データの準備をより簡単、迅速、低コストにするサーバーレスデータ統合サービスです。 70 を超える多様なデータソースを検出して接続し、一元化されたデータカタログでデータを管理し、ETL パイプラインを視覚的に作成、実行、モニタリングして、データをデータレイクにロードできます。
今回はAWS Glue の機能の一つであるGlue クローラーを利用します。Glue クローラーにより、S3上のデータを自動で読み取り、構造化されたインデックスをカタログ(AWS Glue Data Catalog)として保存できます。これにより、S3上のデータをインデックスを利用して、容易に取得することができます。
AWS Glue および クローラの詳細は、以下のAWS ドキュメントを御覧ください。
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/catalog-and-crawler.html
クローラー作成、実行手順
Glueクローラを作成して、S3上のデータをカタログ化してみます。
- AWS Glue のページから[Crawlers] -> [Create crawler]を選択します。
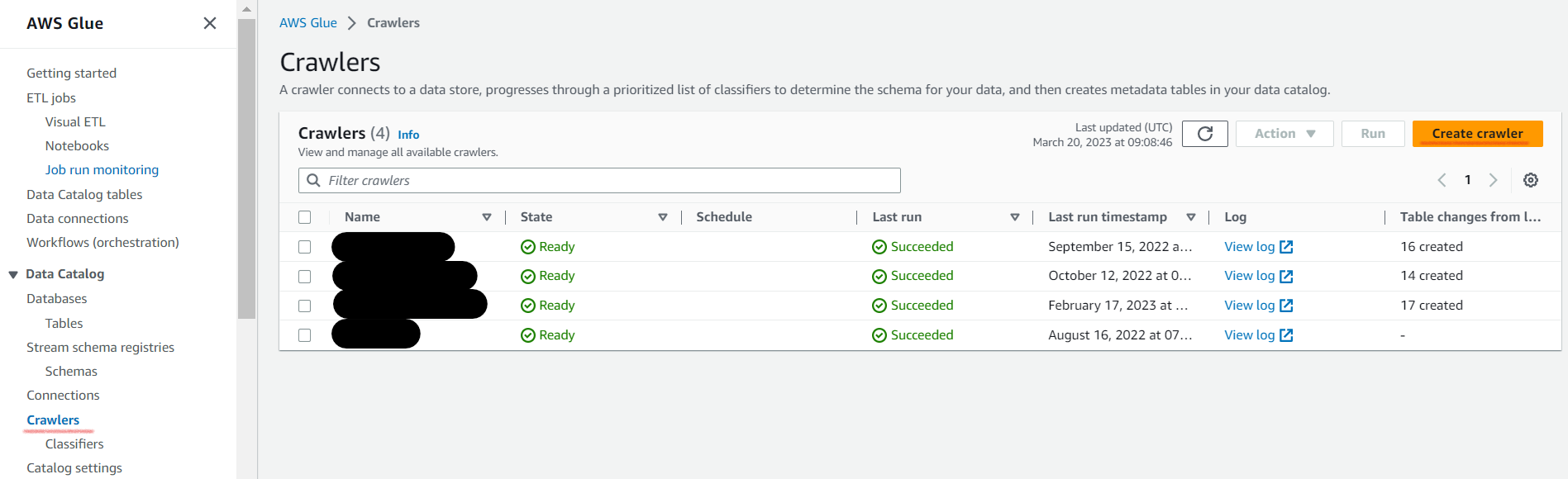
- 以下を指定してクローラを作成します。
- [Data source configuration]: Not yet
- [Add data source] : データソースを追加します。
- Data source : s3
- S3 path : gitlabデータが格納されているs3のパス(s3://gitlab-data)
- Subsequent crawler runs : Crawl all sub-folders
- Target database : テーブルを作成するglue database (作ってなければadd databaseから作成)
- 他の項目も環境に合わせて適時指定してください(S3接続用のIAM等の設定を忘れずに)
- 作成したクローラを実行(Ran crawler)します。
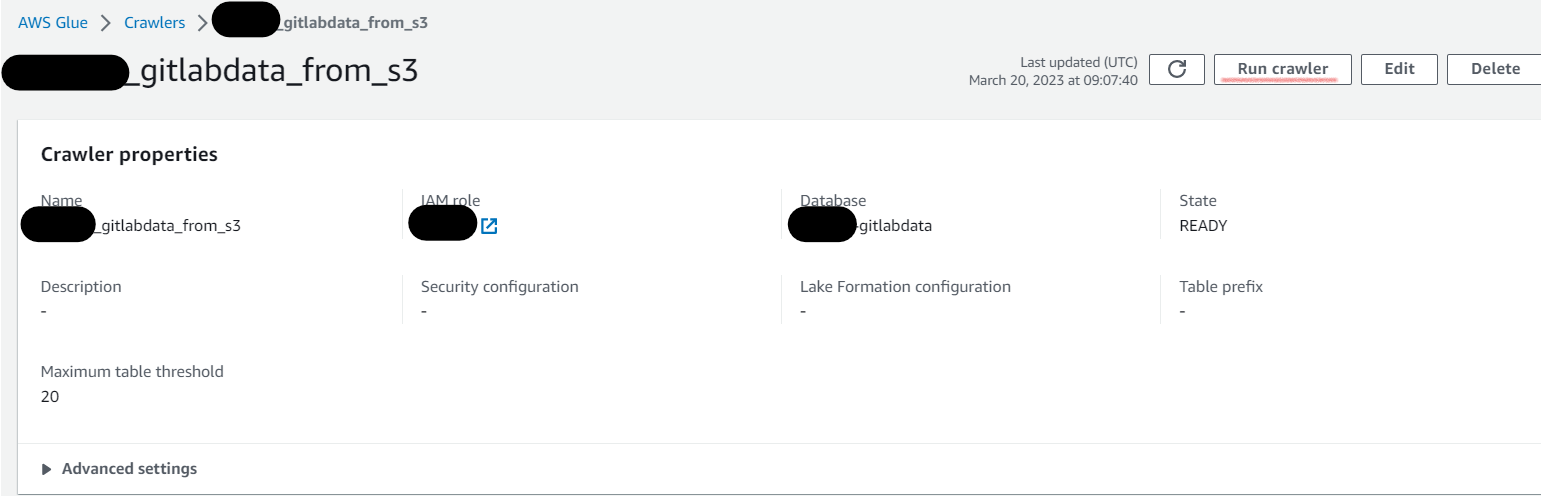
- 実行結果を確認するとS3のデータを読み取って、指定したデータベースにテーブルが作成されています。
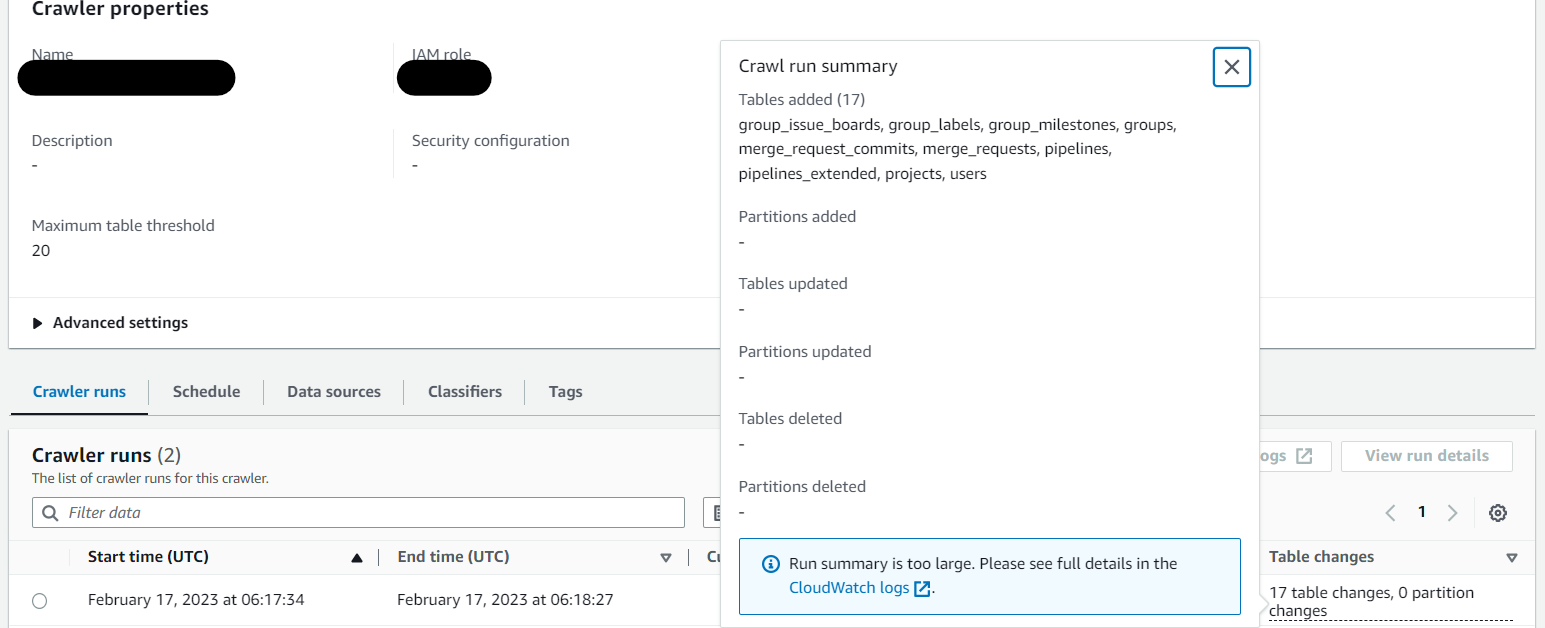
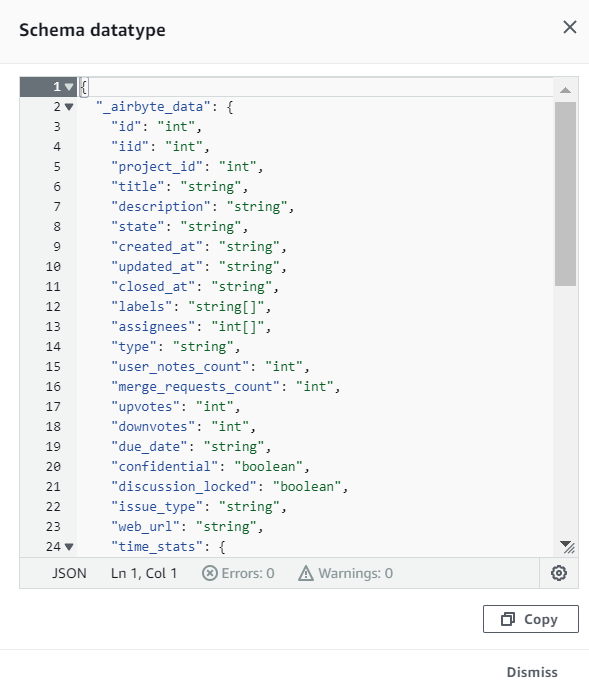
- 作成されたテーブルの中を見てみると、S3上のデータが正しく構造化されて登録されていることがわかります。
(画像はissuesの_airbyte_dataの中身、tableを選択してSchemaのDatatypeのstructをクリックすることで見れます。 )
- うまくいかない方は、クローラの設定が間違っていないか(パスや権限周り)を確認ください。
- 特殊な構造のデータの場合は適切に読み取れない場合があり、その場合は手動で構造を指定することもできます。詳しくはカスタム分類子を御覧ください。
- 実行結果を確認するとS3のデータを読み取って、指定したデータベースにテーブルが作成されています。
S3上のデータの構造が変わる可能性がある場合に備えて、クローラーをスケジュール設定することも可能です。
高頻度にクロールするとそれなりに費用を要するので注意ください。
また、本記事では対象外としますが、Data Catalogに登録しておくことで、Glue Studioなどを利用して大規模データのサマリ化などバッチ的にデータ処理することもできます。
AthenaによるData Catalogを利用したS3データ読み取り
Amazon Athena はAWSの説明によると以下のとおりです。
Amazon Athena は、サーバーレスでインタラクティブな分析サービスであり、ペタバイト級のデータが存在する環境で、簡便かつ柔軟に分析する方法を提供します。
S3のデータをSQL Like(正確にはPresto SQL)な命令で容易に取得、分析することができ、非常にエンジニアフレンドリーです。
今回はAthenaとGlue Data Catalogを利用することでS3上のデータをSQL Likeなクエリで取得してみます。
手順自体は非常に簡単で、Amazon Athenaでのクエリ実行時に、データベースにGlue Data Catalogのデータベースを指定することで、クエリ内でデータベース内のテーブルやテーブル内の項目名を使うことができます。
*Glue Data CatalogでDatabaseを作成していると、Athenaには自動で連携(指定候補に表示)されます。
例えば、S3上の保存されたGitLabデータのissuesデータ内のiidとtitleを表示させるクエリは以下になります。
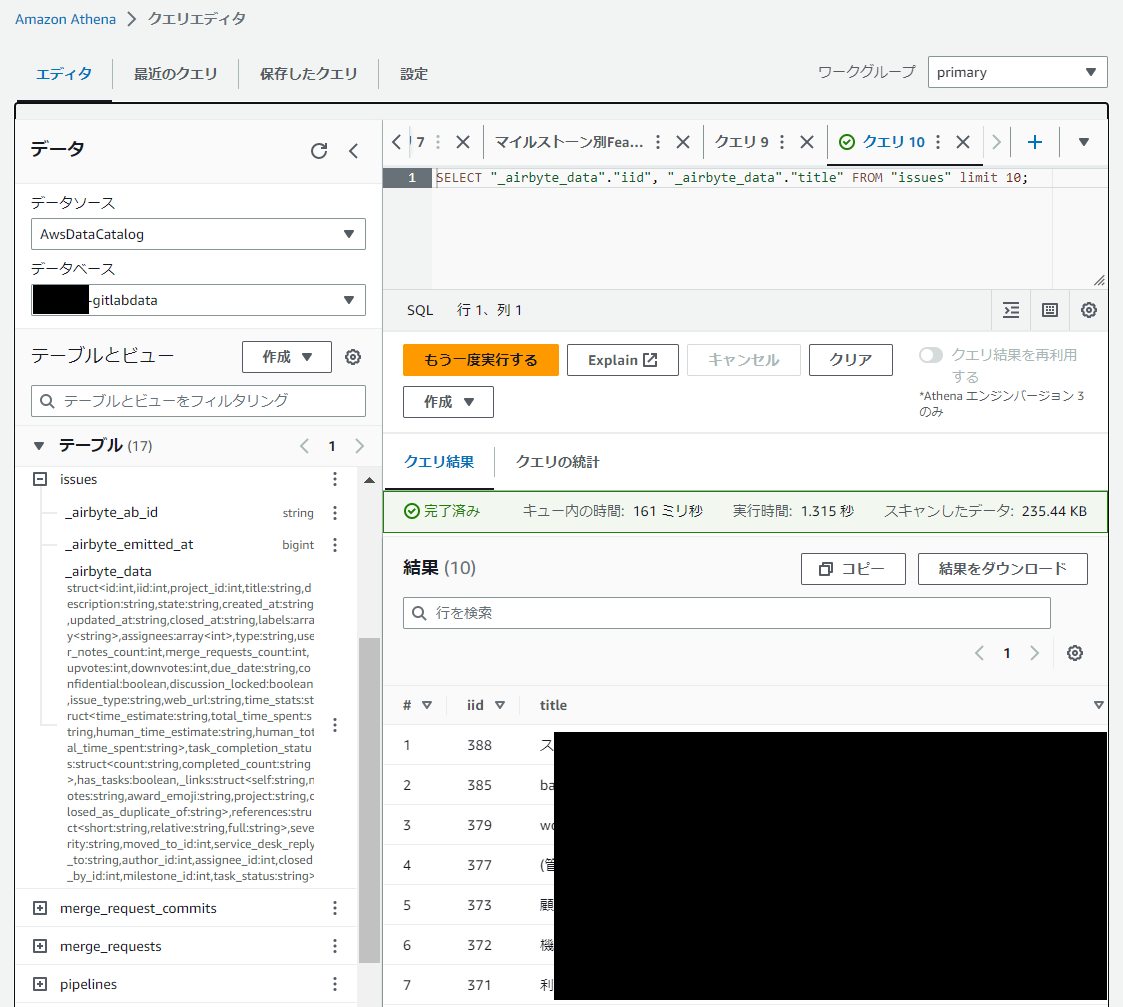
データソースとデータベースに、GitLabのS3データをクロールしたテーブルが登録されているデータベースを指定することで、テーブル内の各項目を参照できます。
Glue Data Catalogを使っていない場合はS3のデータ構造を事前に指定する必要があり、Glue Data Catalog (Glue Crawler) を使うとAthenaの使い勝手がかなり良くなります。
次回は、Athenaで取得するデータをグラフィカルに可視化するため、Amazon ECSとAWS Fargateを利用してGrafanaを構築します。
商標
- AWSおよびAWSの各種サービスは、Amazon.com, Inc.またはその関連会社の商標です。
- 記載の会社名、製品名、サービス名等はそれぞれの会社の商標または登録商標です。