はじめに
k次元のユークリッド空間に点を空間分割で分類し、k次元領域の
点探索を効率的におこなうのがk-DTreeです。
SciPyにこんなのがあるとは知らなったので、どれくらい効率がいいか?
ベンチマークを行ってみたいと思います。
以降、2次元は2-D, 3次元は3-Dという風にk次元について
k-Dと表記します。
比較条件
データ件数 100000件
検索回数 10000回
2-Dから8-Dデータまで行います。
各次元について4回ずつ探索を行います。
leafsizeは10固定。
環境
Anaconda
Python 3.7.6
scipy.version.full_version 1.3.2
windows10
プログラム
kdtbench.py
def search(S, pt):
# 距離を求める
distary = ss.distance.cdist([pt], S, metric='euclidean')
# 最小のインデックスを求める
idx = distary.argmin()
return (distary[0, idx], idx)
def benchmark(x, s, kdt, no, i):
# k-DTree 探索
kdstart = time.time()
for search_cond in s:
dist, hitindex = kdtree.query(search_cond)
kd_elapsed_time = time.time() - kdstart
print('%d:%d-D K-DTree(秒) %.2f' % (i, no, kd_elapsed_time))
# 総あたり 探索
brstart = time.time()
for search_cond in s:
dist, hitindex = search(x, search_cond)
br_elapsed_time = time.time() - brstart
print('%d:%d-D 総当たり(秒) %.2f' % (i, no, br_elapsed_time))
return kd_elapsed_time, br_elapsed_time
count_data = 100000
count_key = 10000
numturns = 4
np.random.seed(0)
for n in range(2,9): #2-D...8-D
X = np.random.rand(count_data, n) * 1000.0
S = np.random.rand(count_key, n) * 1000.0
kdtree = ss.KDTree(X, leafsize=10)
total_k = 0
total_a = 0
for i in range(0,numturns):
ktm, atm = benchmark(X,S, kdtree, n, i)
total_k += ktm
total_a += atm
print('Avg k-DTree:%.2f秒 総当たり:%.2f秒' % (total_k/numturns, total_a/numturns))
print()
ベンチマーク実施
プログラムを実行。
$ python kdtbench.py
0:2-D K-DTree(秒) 2.00
0:2-D 総当たり(秒) 6.61
1:2-D K-DTree(秒) 1.99
1:2-D 総当たり(秒) 6.62
2:2-D K-DTree(秒) 2.02
2:2-D 総当たり(秒) 6.78
3:2-D K-DTree(秒) 2.01
3:2-D 総当たり(秒) 7.33
Avg KDTree:2.00秒 総当たり:6.83秒
0:3-D K-DTree(秒) 2.71
0:3-D 総当たり(秒) 7.81
~~~ 省略 ~~~
ベンチマーク結果
条件ごとの測定結果の平均時間(秒)が下記です。
| 総当たり(秒) | K-DTree(秒) | |
|---|---|---|
| 2-D | 6.83 | 2.00 |
| 3-D | 7.65 | 2.67 |
| 4-D | 8.18 | 4.17 |
| 5-D | 9.29 | 7.13 |
| 6-D | 10.97 | 12.67 |
| 7-D | 11.51 | 20.41 |
| 8-D | 13.30 | 46.03 |
各PC事に性能が異なるため時間うんぬんは意味が無く、比較で見て下さい。
測定値をグラフ化
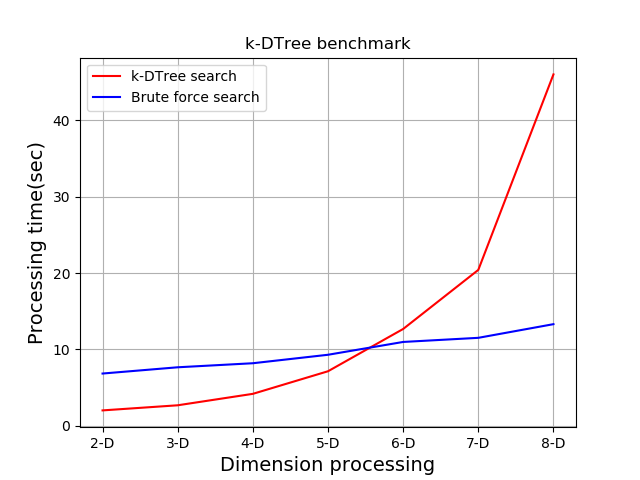
K-DTree searchがK-DTreeによる探索処理の結果を示し、
Brute force searchが総当たり探索処理の結果です。
5-D以降、性能が逆転することがわかりましたが、ここまで使うかは
今のところ分かりません。自分の場合は使ってもせいぜい3-Dくらいまで、
たぶんpythonではこういう使い方はしないかな。
ご清聴ありがとうございました。