High Compute Queryは2017年11月に廃止になったので、この記事は過去の思い出です。
https://cloud.google.com/bigquery/docs/release-notes?hl=en#november_14_2017
今後はBillingTierが100を超えない限りは、特に料金が変わることはありません。
BillingTier100超えはかなりの無茶をしないと出てこないので、滅多に気にすることはありません。
ただ、単純なパフォーマンスチューニングとして、以下のノウハウはまだ役に立ちます。
High Compute Queryに備える!Dremelの気持ちになって考えるパフォーマンスチューニング
以下、過去の思い出話となった内容
BigQueryのQuery料金は今までどんな複雑なクエリを書いても、データを読み込んだ容量に対して料金が決定されていました。
しかし、2017/01/01より、Queryの処理量によってクエリ料金が変動するようになります。
それが High Compute Query と呼ばれるものです。
BillingTier
High Compute QueryのためにBillingTierという新しいパラメータが追加されました。
これはQueryの処理量を表すもので、1以上の整数値が入ります。
現状、BillingTierはクエリを実行してみないと分かりません。
これは対象のデータの容量や偏りなどによって、BillingTierの値を算出しているからではないかと思われます。
BillingTierが上がる要因としては、JOINや複雑なユーザ定義関数などがあります。
クエリ料金
現行 : $5 per TB
新 : $5 * Billing Tier per TB
BillingTierの値が2だと料金が倍になる計算です。
これは2017/01/01から適用される予定です。
今から備えておくこと
既存のクエリのBillingTierを確認する
BillingTierは料金には反映されていませんが、すでにクエリの結果に含まれています。
BigQuery Web ConsoleからでもQuery Historyを確認すれば、BillingTierの値が分かります。
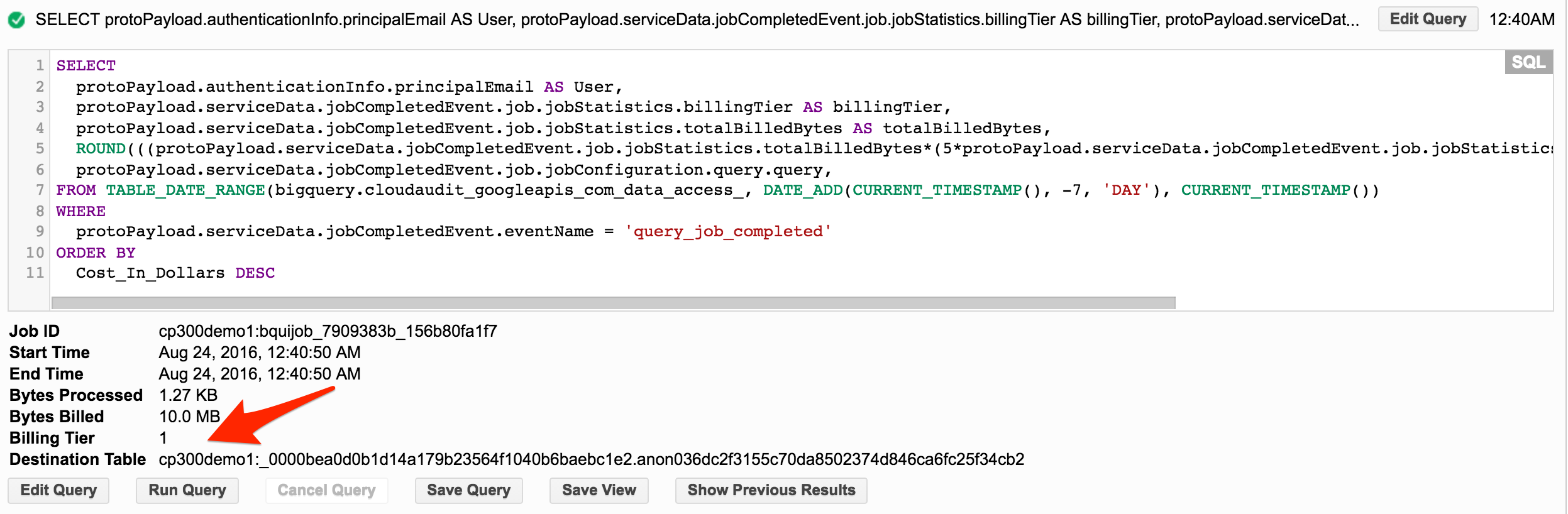
また、audit logをBigQueryにExportしている場合、以下のような感じでクエリを実行すれば、BillingTierの高いクエリを探すことができます。
-- 直近1ヶ月で実行されたクエリを、billingTierの高い順に並び替えて取得する
SELECT
protoPayload.authenticationInfo.principalEmail AS User,
protoPayload.serviceData.jobCompletedEvent.job.jobStatistics.billingTier AS billingTier,
protoPayload.serviceData.jobCompletedEvent.job.jobStatistics.totalBilledBytes AS totalBilledBytes,
ROUND(((protoPayload.serviceData.jobCompletedEvent.job.jobStatistics.totalBilledBytes*(5*protoPayload.serviceData.jobCompletedEvent.job.jobStatistics.billingTier))/1000000000000),2) Cost_In_Dollars,
protoPayload.serviceData.jobCompletedEvent.job.jobConfiguration.query.query,
FROM
TABLE_DATE_RANGE(bigquery.cloudaudit_googleapis_com_data_access_, DATE_ADD(CURRENT_TIMESTAMP(), -1, 'MONTH'), CURRENT_TIMESTAMP())
WHERE
protoPayload.serviceData.jobCompletedEvent.eventName = 'query_job_completed'
ORDER BY
protoPayload.serviceData.jobCompletedEvent.job.jobStatistics.billingTier DESC,
totalBilledBytes DESC
BilligTierの値が高いクエリを探してチューニングを行い、BillingTierの値を低く保つようにしましょう。
クエリ実行時にmaximum_billing_tierを指定することを考える
billingTierはクエリ実行時に分かるため、事前に把握することはできません。
Developerはクエリ実行時にmaximum_billing_tierの値を指定することで、BillingTierの上限値を決めます。
BigQuery Web ConsoleではQuery Optionを指定します。
bq commandだと以下のように指定します。
bq query --maximum_billing_tier 2
shellなどで自動で実行しているクエリのBillingTierが1を超えていて、それでも実行したい場合は、maximum_billing_tierを明示的に指定しましょう。
デフォルトは1になっているため、実行したクエリに必要なBillingTierが1を超えている場合、billingTierLimitExceededが返ってきます。
もしクエリごとにmaximum_billing_tierを指定するのが面倒な場合は、GCP Project単位でデフォルトのmaximum_billing_tierの値を変更することもできます。
BigQuery High-Compute Queries Quota Request Form
ただし、maximum_billing_tierのデフォルト値を上げると、思わぬ課金が発生する可能性もあるので、注意してください。
さいごに
今までどんなに無茶なクエリを書いても料金が変わらなかったBigQueryですが、UDFも登場して流石に計算量を料金にフィードバックしないといけなくなったみたいです。
値上げではありますが、 Long Term Storage での値下げもあるので、ある程度は相殺されてるんじゃないでしょうか。
因みに僕はクエリの複雑さとデータ容量が足らないのか、現状BillingTierは1で収まっています。
次は、BillingTierの値を下げるために、BigQueryのクエリのチューニングについても書いていきたいと思います。
BillingTierの値を下げるために、発表したスライドのLinkを貼っておきます。
High Compute Queryに備える!Dremelの気持ちになって考えるパフォーマンスチューニング