色々Pythonを速くするための世の中に方法はありますが、本記事ではCythonやPyPyなどの高速化のTIPSに触れていきます。
この記事で触れること
- プロファイラーなどの計測関係
- ビルドインモジュールなどの機能
- Pythonのキャッシュ関係
- Cython
- Numba
- PyPy(紹介だけ)
- その他一部のサードパーティーのライブラリ関係
この記事で触れないけどそのうち書くかもしれない内容
- 並列処理(multiprocessing)、並行処理(threading)、非同期処理(asyncio)、それらの組み合わせ(concurrent.futures)など
- Dask関係
- PyPyの踏み込んだ検証内容など
- 話題のVaex
記事で使う環境
- Windows10(ローカルのJupyter)とUbuntu(クラウド上のカーネル)で進めていきます。
- 言語はPython3.7.1(win)とPython3.6.6(Ubuntu)を使います。
- Jupyter上での実行を前提とします。.pyファイルだと少し話が変わってくるところもぼちぼちあります。
まずは計測する方法を学ぶ
まずはとにかく計測します。どこが遅いのかがそもそも把握できないと、改善しようとして頑張っても効果が薄かったりします。
100秒の処理を10%改善する方が、10秒の処理を50%改善するよりも効果が大きく、簡単なことが多いので前者を探していく、といった感じです。
%timeitのマジックコマンド
まずはお馴染みのtimeitのマジックコマンドです。結構Python本でも出てくることが多いので、ご存知の方が多いと思います。
指定されたコードが何度が実行され、結果の処理時間が出力されます。
マジックコマンド全般に言えることですが、単一行であれば%を一つ、セル内の複数行の処理であれば%%timeitと%記号を二つ並べることで使えます。
単一行の例 :
%timeit [i for i in range(3000000)]
267 ms ± 50.9 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
複数行での例 :
%%timeit
index_list = []
for i in range(3000000):
index_list.append(i)
417 ms ± 4.27 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
%prunのマジックコマンド
シンプルな処理であればtimeitのマジックコマンドで事足ります。
しかし、長い処理とかで、かつその中で色々な関数を呼び出していたりすると少し把握が難しくなります。
そういった場合は%prunのマジックコマンドを使うと、実行された関数単位で色々計測結果を見ることができます。
def sample_func_1():
index_list = []
for i in range(1000000):
index_list.append(i)
def sample_func_2():
index_list = []
for i in range(2000000):
index_list.append(i)
def sample_func_3():
index_list = []
for i in range(6000000):
index_list.append(i)
def sample_func_4():
sample_func_1()
sample_func_2()
sample_func_3()
適当な4つの関数を用意しました。
4つ目の関数はそれぞれの関数を呼び出しているだけです。
マジックコマンドとともに、4つ目の関数を実行してみます。
%%prun
sample_func_4()
そうすると、docstringを表示したときのように、Jupyterの下の方に計測結果が表示されます。
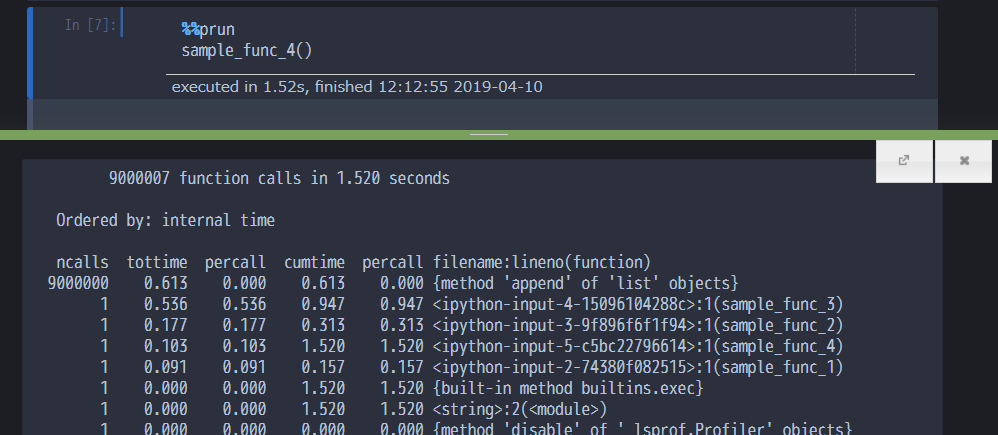
9000000 0.613 0.000 0.613 0.000 {method 'append' of 'list' objects}
appendメソッドが9000000回呼ばれていたり、そこで時間が0.61秒かかっていたり、そのほかの関数は1回ずつ呼ばれていたり、といったことが分かります。
(※4番目の関数、関数呼び出しだけですが、0.1秒もかかっているというのは違和感がありますが、計測のオーバーヘッドとかなのでしょうか・・?基本遅い関数を特定するのが目的なので、問題ないと判断して進めます)
各カラムは以下のような内容を表します。
- ncalls: その関数の呼び出し回数
- tottime: その関数の、ほかの関数実行を除いた処理時間
- percall: その関数の1回の呼び出しあたりの処理時間(今回のappendみたいな、処理は早いけど膨大な回数実行するような内容だと値が0になります)
- cumtime: 他の呼び出している関数なども含めた実行時間
- filename:lineno: 対象の関数名や行番号(セル内の行番号)を表します
行単位での処理時間を調べる : line_profiler
prunでの計測で遅い関数が分かったとして、もしかしたらその関数がとても長くて、関数の中でどの処理が遅いのかが分からない・・というケースもあるかもしれません。
そういった際にはline_profilerのライブラリを使うことで、関数内の行単位で詳細を調べていくことができます。
まずはライブラリが必要になるので入っていなければpipでインストールします。
$ pip install line_profiler
もしくは、Windows環境とかの場合で且つAnacondaなどを使っている場合、conda経由の方がインストールが楽かもしれません。(私のときはUbuntu環境ではさくっとpipでいけたものの、WindowsではC++関係でエラーになり、別途サイトから落としてきたりの対応が要求されたりしたので)
$ conda install -c anaconda line_profiler
今回はline_profiler-2.1.2のバージョンを使っていきます。
使い方は、関数の追加や実行などをして、その後にprint_statsメソッドを呼ぶと計測結果を表示してくれます。
import line_profiler
def sample_func():
index_list = []
for i in range(1000000):
index_list.append(i)
for i in range(3000000):
index_list.append(i)
for i in range(10000000):
index_list.append(i)
profiler = line_profiler.LineProfiler()
profiler.add_function(sample_func)
_ = profiler.runcall(sample_func)
profiler.print_stats()
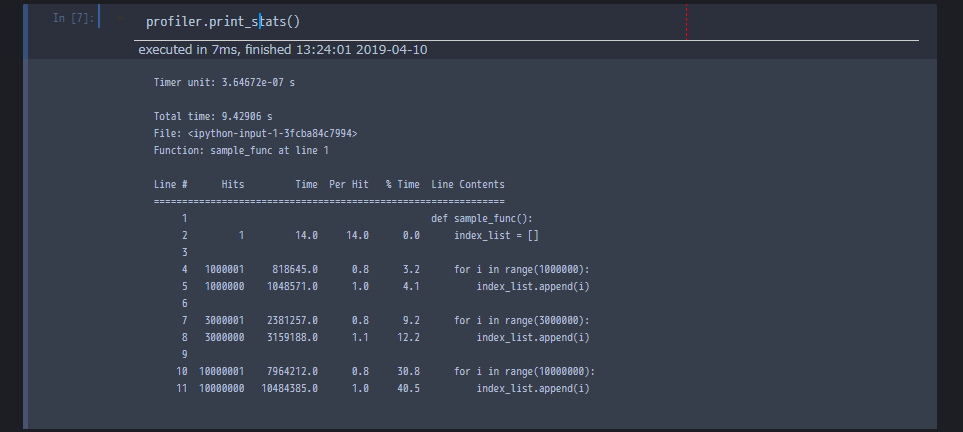
その行で処理を何回実行しているのか(Hits)、処理時間はどんなものなのか(Time)、1回あたりの処理時間はどの程度なのか(Per Hit)、関数全体で占める割合はどのくらいなのか(% Time)、対象行の内容(Line Contents)が表示されます。
適切なデータ構造などを使って速くする
速度改善で色々なテクニックがあるものの、まずは必要な機能とそれに適したものが何なのか、という引き出しを多くもっておくというのがシンプルで役に立つケースがあります。
サンプルとしていくつか見ていってみます。
リストの先頭が変動するケースが得意なdeque
例えば、リストへの要素の追加を考えてみましょう。
append関数で、リストの末尾に追加する場合、追加先のリストの件数が多くてもそこまで速度で問題になってはきません。
追加先のリストの件数が少ない場合と多い場合の比較。件数が大きくなっても特にパフォーマンスに影響が出てきたりはしません :
small_list = [i for i in range(1000)]
large_list = [i for i in range(100000000)]
%%timeit
small_list.append(10)
76.3 ns ± 4.95 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)
%%timeit
large_list.append(10)
74.4 ns ± 24.7 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)
しかし、たとえばリストの先頭に追加が必要なケースやpopで先頭の要素を取り出したりする場合などには、インデックスがずれるのでリストの件数が多いと大きな負担となります。
リストの件数の多さでパフォーマンスが大きく変わってくる例 :
small_list = [i for i in range(1000)]
large_list = [i for i in range(100000000)]
%%timeit -n 100
small_list.insert(0, 10)
643 ns ± 70.1 ns per loop (mean ± std. dev. of 7 runs, 100 loops each)
%%timeit -n 3
large_list.insert(0, 10)
68.7 ms ± 569 µs per loop (mean ± std. dev. of 7 runs, 3 loops each)
処理時間が、小さいほうのリストではナノ秒の単位で終わっている一方で、大きいリストの方ではミリ秒単位の処理時間がかかるまでの差が出てきました。
※timeit の-n引数は実行回数です。デフォルトみたく勝手に実行回数が決められる状態だと少ないリストの方に膨大に値が追加されてしまって、段々遅くなるため、少ない回数にしています。
また、もしかしたら末尾に要素を追加する場合でも、1件追加したら先頭の1件を取り除く、みたいなキューの実装が必要になることもあるかもしれません。
そういった場合には、例えばビルドインモジュールのdequeなどを使うとうまいこと改善できます。
dequeモジュールを使うことで、小さいリストでも大きいリストでも、それぞれ短時間で先頭に要素を追加できる例 :
from collections import deque
small_list = [i for i in range(1000)]
large_list = [i for i in range(100000000)]
q1 = deque(small_list)
%%timeit -n 100
q1.insert(0, 10)
84.4 ns ± 2.33 ns per loop (mean ± std. dev. of 7 runs, 100 loops each)
q2 = deque(large_list)
%%timeit -n 100
q2.insert(0, 10)
80.7 ns ± 3.04 ns per loop (mean ± std. dev. of 7 runs, 100 loops each)
作成したdequeのオブジェクトは、若干リストとは使い勝手が違いますが、リスト同様インデックスなどで値にアクセスできます。先頭の要素にアクセスすると、追加した要素になっていることが分かります。
q1[0]
10
また、dequeの第二引数のmaxlenを指定することで、末尾に要素を加えた際にもその分だけ先頭の要素を取り除く、という実装ができます。
q3 = deque(large_list, maxlen=10000000)
len(q3)
10000000
%%timeit -n 100
q3.append(100)
51.6 ns ± 4.54 ns per loop (mean ± std. dev. of 7 runs, 100 loops each)
末尾の要素にアクセスしてみると、たしかに追加した要素になっています。
q3[-1]
100
また、追加した分、先頭の要素が取り除かれ、全体の件数が変わっていない点も確認できます。
len(q3)
10000000
リストで末尾に要素を加えて、さらに先頭の要素を削除して・・とするのに比べると、シンプルにぐぐっと速くなります。
もちろん、リストに対してdequeの方がすべてのケースで好ましいかと言われると、当然そんなことはなく、例えば先頭への追加や削除などによるインデックスがずれるような処理は得意としている一方で、真ん中のあたりへの要素の追加は苦手としています。
q4 = deque(large_list)
%%timeit -n 100
q4.insert(5000000, 200)
11.6 ms ± 135 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
dequeを使っていてもミリ秒の単位と、大分遅くなってしまいました。このように、得意・不得意な領域があるので、実装したい内容や集計内容などに応じてうまいこと使い分けることが大切になってきます。
キーのチェックが不要なdefaultdict
ループで回して、いずれかのキーの値をインクリメントしていくような処理(もしくは任意の値を加算などしていく処理)を考えてみます。
そういった際に、通常のdictの場合インクリメントの際にキーの有無をチェックするような分岐が必要になってきます。
普通の辞書で処理する例 :
import numpy as np
random_key_arr = np.random.randint(low=0, high=100, size=10000000)
%%timeit
sample_dict = {}
for random_key_int in random_key_arr:
has_key = random_key_int in sample_dict
if has_key:
sample_dict[random_key_int] += 1
else:
sample_dict[random_key_int] = 1
2.14 s ± 1.74 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
大した処理ではないので、これでも1000万件のループ程度であれば十分早いスピードで処理できました。
しかし、こういった場合はdefaultdictを使うと記述がシンプルになり、余分な分岐も無くなるので少し早くなったりします。
defaultdictは、dequeと同じくcollectionsパッケージに含まれるビルドインのモジュールで、辞書生成時に格納される値の型を指定することで、その型に応じた初期値を自動で設定してくれます。たとえば、intを指定すれば0、strを指定すれば空文字が設定されます。
from collections import defaultdict
%%timeit
sample_dict = defaultdict(int)
for random_key_int in random_key_arr:
sample_dict[random_key_int] += 1
1.55 s ± 1.12 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
記述がすっきりして、且つ速度も微妙に早くなりました。
なお、キーが複数必要な場合はキーにtupleを使うか、もしくはlambda式でさらにdefaultdictを格納すると、複数のキーを持った辞書が扱えます。こちらの場合も、ネストした部分にif文を書かなくて済むのでシンプルです。
何も考えずにネストしていくあまり良くない例 :
random_key_arr_1 = np.random.randint(low=0, high=100, size=1000000)
random_key_arr_2 = np.random.randint(low=0, high=100, size=30)
%%timeit
sample_dict = {}
for random_key_1 in random_key_arr_1:
has_key = random_key_1 in sample_dict
if not has_key:
sample_dict[random_key_1] = {}
for random_key_2 in random_key_arr_2:
has_key = random_key_2 in sample_dict[random_key_1]
if has_key:
sample_dict[random_key_1][random_key_2] += 1
else:
sample_dict[random_key_1][random_key_2] = 1
10 s ± 22.3 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
%%timeit
sample_dict = defaultdict(lambda: defaultdict(int))
for random_key_1 in random_key_arr_1:
for random_key_2 in random_key_arr_2:
sample_dict[random_key_1][random_key_2] += 1
ネストするようなケースでは大分記述のシンプルさに差が出てきます。
6.81 s ± 16.2 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
※キーにtupleを使う場合はネストするケースでは、ネストしても通常の辞書とdefaultdictでそこまでシンプルさに差はありません。
単純に要素のカウントだけなら、Counterでもっとシンプルにできる
そもそも、前述のような辞書でのループも必要なく、カウントだけであればビルドインのcollections.Counterモジュールで一瞬で処理が終わります。
from collections import Counter
random_key_arr = np.random.randint(low=0, high=100, size=10000000)
%%timeit
counter = Counter(random_key_arr_1)
116 ms ± 136 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
1000万件のカウントで約116ミリ秒。結構早いです。
少なくともループを回すよりは大分早いです。(もちろん、Pandasとか使ってもいい感じではありますが・・)
生成したCounterオブジェクトは、辞書感覚でカウント値にアクセスができます。
counter[50]
10045
そのまま出力すると、キーと件数での組み合わせになっていることが分かります。
counter
Counter({63: 9890,
16: 10009,
8: 10123,
18: 10030,
46: 10127,
57: 9737,
...
前方一致検索だけでいいならトライ木などを使うのがいい
たとえば、Qiitaのタグの設定時に出てくる候補を探したりするケース。普通に判定してもいいのですが、タグが膨大になってくると結構速度的に辛いものがあります。
そういった場合にはトライ木みたいなデータ構造を使うと非常に高速に検索ができます。
色々なトライ木のライブラリがありますが、今回はpatricia-trieというライブラリを使います。
$ pip install patricia-trie
Successfully installed patricia-trie-10
試しに、ランダムな文字列を用意して試してみましょう。
16文字のA~Zまでのアルファベットの組み合わせの文字列を生成する関数を用意しました。
from random import choice
from string import ascii_uppercase
def make_random_str():
"""
16文字のA~Zの組み合わせのランダムな文字列を生成する。
Returns
-------
random_str : str
生成された文字列。
"""
return ''.join(choice(ascii_uppercase) for i in range(16))
以下のような文字列が生成されます。
make_random_str()
'ILWYLJBHPOHMUBCZ'
まずは300万件の文字列を用意して、何も考えずにループで、文字列の先頭が"ABC"で始まる文字列を探す対応の速度を見てみます。
random_str_list = [make_random_str() for i in range(3000000)]
%%timeit
matched_str_list = []
for random_str in random_str_list:
if random_str.startswith('ABC'):
matched_str_list.append(random_str)
289 ms ± 2.42 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
件数の割にはぼちぼち速いですが、しょっちゅう実行されるようなケースでは大分辛い印象です。
トライ木を使ってみましょう。
辞書の形式が必要だったりするので、キーにランダムな文字列、値は参照しないので0を指定した辞書を用意します。
from patricia import trie
random_str_dict = {random_str: 0 for random_str in random_str_list}
random_str_trie = trie(**random_str_dict)
このトライ木の用意の部分は少し時間がかかります。
準備ができたら、以下のようにすると前方一致で検索ができます。
matched_str_list = list(random_str_trie.iter('ABC'))
matched_str_list[:3]
['ABCIMAZBADIAJLMU', 'ABCIXODUIXBVHFNA', 'ABCIAIMMAZVGEVYY']
速度を測ってみます。
%%timeit
matched_str_list = list(random_str_trie.iter('ABC'))
178 µs ± 918 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
300万件の検索が、ミリ秒の単位からマイクロ秒の単位になるまで、大分早くなりました。
特徴として、計算速度がほぼ文字列の最大長に依存する形になっています(対象の件数にほとんど依存しません)。そのため、長文とかには不向きかもしれませんが、タグや前方一致で問題がない入力補完なんかで、検索対象が膨大にあって且つパフォーマンスが要求されるようなケースで力を発揮します。
この他にも、例えばmarisa-trieのような、普通の辞書よりもアクセスが遅く、使用感が少々特殊なものの、辞書のメモリ使用量が圧倒的に低く済むデータ構造など色々あります。
String data in a MARISA-trie may take up to 50x-100x less memory than in a standard Python dict; the raw lookup speed is comparable; trie also provides fast advanced methods like prefix search.
marisa-trie
他にもいろいろありますが、とても記事が長くなってしまうので割愛します。
それぞれの特徴・向き不向きを把握しておいて、引き出しを多くしておくと、いざ仕事で扱うときに要件にマッチしたものを選べて役立つかもしれません。
Python上のキャッシュの話
クエリをキャッシュしたりするのと同様、Pythonの関数などもキャッシュすると速くできたりします。
(ただ、引数の組み合わせが膨大になるケースなど、毎回キャッシュがない・・ような場合は逆に負担になるだけなので、どこでも使えるというものでもありません)
そのあたり、ビルドインで用意されているものを中心に見ていきます。
関数をメモリ上にキャッシュする
functoolsモジュールのlru_cacheをデコレーターとして使うと、引数の内容がすでに実行したことのあるパターンの場合はキャッシュして、ダイレクトに返却値を返してくれるようになります。
from functools import lru_cache
@lru_cache()
def add(a, b):
print(f'計算処理を実行します : a = {a}, b = {b}')
return a + b
add(a=100, b=300)
計算処理を実行します : a = 100, b = 300
400
1回目の実行は通常の関数の実行と変わりません。
もう一度、同じ引数条件で実行してみます。
add(a=100, b=300)
400
今度は、「計算処理を実行します」という部分のprintがされず、結果だけ返ってきました。つまり、関数の中身は通らず、返却値がダイレクトにキャッシュから返却されています。
別の引数の条件で実行してみます。
add(a=300, b=500)
計算処理を実行します : a = 300, b = 500
800
このように、すでに実行済みの引数条件の際にはキャッシュからそのまま返却、そうではない場合には関数の中を通して値を返却するという挙動になります。
引数の条件の組み合わせが、何度も同じものが実行されるような条件の際に高い効果を発揮します。
キャッシュする条件数を変えるには、引数のmaxsizeの値を変更します(デフォルトでは128といった少ない値が設定されています)。
@lru_cache(maxsize=1024)
def add(a, b):
print(f'計算処理を実行します : a = {a}, b = {b}')
return a + b
この件数よりも多くの参照がされた場合には、古いキャッシュから消えて新しいキャッシュが追加されます。(lruがleast recently usedの略なので、最近のものが残ります)
数値が大きいほど色々な条件のキャッシュができる一方で、メモリが多く必要になってきます。
不要になったキャッシュなどは、cache_clear関数で消すことができます。この関数はデコレーターが設定された関数が持ちます。(関数が関数を持つという、ちょっと不思議な感覚・・)
add.cache_clear()
ディスク上でキャッシュする
メモリ上のキャッシュは速くてお手軽ですが、そこまでの速度は不要で、且つメモリは他のところに割きたいというケースもぼちぼちあります。
そういったケースではjoblibライブラリを使うとディスク上への関数のキャッシュなどができます。
まずは、インストールがされていなければインストールします。
$ pip install joblib
...
Successfully installed joblib-0.13.2
※注意 : Windows上で試していたら、なぜかキャッシュがうまいことされませんでした。もしかしたら日本のWindowsでパス的なところで問題があるのかもしれません・・(パスの都合でキャッシュが無い判定になっているなど)。以下のものは、Ubuntu環境で進めています。
locationの引数で、キャッシュを格納するディレクトリを指定します。
import time
from joblib import Memory
memory = Memory(location='./disk_cache', verbose=0)
使い方はメモリ上のキャッシュと似たような感じで、関数にデコレーターを指定するとキャッシュしてくれます。
@memory.cache
def add(a, b):
print(f'計算処理を実行します : a = {a}, b = {b}')
time.sleep(3)
return a + b
初回の実行は普通に関数の中を通ります。
add(a=100, b=200)
計算処理を実行します : a = 100, b = 200
300
二回目からは関数の中を通らず、ダイレクトに値が返却されていることが分かります。
add(a=100, b=200)
300
こちらも、関数にclear関数が追加されるので、そちらを参照することでキャッシュのクリアができます。
add.clear()
Cython
Cython は、C言語によるPythonの拡張モジュールの作成の労力を軽減することを目的として開発されたプログラミング言語である。その言語仕様はほとんど Python のものと同じ (上位互換) だが、Cの関数を直接呼び出したり、C言語の変数の型やクラスを宣言できるなどの拡張が行われている。
Wikipediaより
Python感覚で書けて速いという噂のCython。深掘りするとCython単体でオライリーの本1冊になるくらいなので気軽に使えて且つ高速化の恩恵をぼちぼち得られる範囲でこの記事では触れていきます。
Cythonの環境
UbuntuでAnacondaを入れていれば、ほぼ何も考えずに使えます。
Windowsだとちょっと面倒な感じになってきます。
そのまま使おうとすると、以下のエラーとかで怒られます。
DistutilsPlatformError: Unable to find vcvarsall.bat
Python3.5以降を使っていると想定して、Visual Studio コミュニティとかを入れるのが比較的シンプル・・なのでしょうか?
参考 : PythonでUnable to find vcvarsall.batと言われる際のまとめ
結構面倒くさそうな印象を受けたのと、仕事だと大体Linuxで作業していることが多いので、今回の記事の内容はUbuntu環境で進めます。(Windowsの方はさくっと試したい場合にはColaboratoryなど推奨です)
CythonをJupyter上で使う
以下のようなマジックコマンドを実行すると、Jupyter上でCythonが使えるようになります。
%load_ext Cython
あとは、Cythonで書きたいセルの先頭で%%cythonとマジックコマンドの記述をすれば、その記述がCythonのものになります。
%%cython
def hello_cython():
print('Hello!')
他のセルからは、マジックコマンド無しで呼び出せます。
hello_cython()
Cythonの変数定義
cdefキーワードで、型宣言付きで変数を定義できます。intやdoubleといった色々な型が用意されています。
型宣言をすることで、コードの実行が大分早くなります。
ごく簡単な例として、1億回インクリメントする処理を試してみます。
まずは普通のPythonのコード。
def sample_func():
a = 0
for i in range(100000000):
a += 1
return a
%timeit sample_func()
6.91 s ± 174 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
6.91秒。
続いてCythonのコード。
%%cython
def sample_func_cython():
cdef int a = 0
for i in range(100000000):
a += 1
return a
%timeit sample_func_cython()
71.5 ns ± 3.45 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)
71.5ナノ秒。全然違います。
特筆すべき点として、一応は別の言語扱い?ですが、Pythonとほぼ同じような記述で書けて学習コストが低く、そのままJupyter上や.pyファイルでさくっと使えて、通常のPythonのコードとも連携が簡単にできる点でしょうか。
なお、cdefの後の記述を省略して、型宣言無しで使ってみると、生のPythonよりかは早いものの極端に遅くなります。
1.59 s ± 6.08 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Cythonでのキャスト
<型名>と記述することでキャストすることができます。
%%cython
cdef int a = 100
cdef double b
b = <double> a
print(b)
Cythonでの関数定義
Cythonでは、以下のような関数定義のキーワードがあります。それぞれ特徴が異なります。
- def -> Pythonからも呼び出しができる。関数呼び出しのオーバーヘッドは通常のPythonと変わらず、ぼちぼち遅い。
- cdef -> 関数呼び出しのオーバーヘッドが少ない。ただし、Python側から呼び出せず、Cython環境でのみしか使えない。Python連携するには不向き。3つの中では一番速い?
- cpdef -> Cython環境の時にはCython用の速いもの、Python環境から呼び出した際には遅いけどPython連携ができる形となる。
特に関数呼び出し回数は多くならないものであればdef、多く呼び出して且つPythonから呼び出さないものはcdef、両方で使いつつ且つCython環境でもなるべく早いまま使いたい場合はcpdefといった感じでしょうか。
どのみち、Python上から呼び出す場合にはオーバーヘッドが影響してくるので、Pythonから膨大な回数呼び出すのは不向きなところがあります。
引数と返却値
基本はPythonと一緒ですが、型を指定するところが異なります。
引数であれば、int aといったような記述、返却値であれば関数名の前に記述する形式のようです。
%%cython
cpdef int sample_func_cython(int a):
a += 1
return a
なお、Python側から呼び出す場合には、返却値に型を指定してもパフォーマンス向上に貢献しない印象があります。
また、defで定義した場合、そもそも返却値の型の指定をしているとエラーになります。
%%cython
def int sample_func_cython(int a):
a += 1
return a
/tmp/.cache/ipython/cython/_cython_magic_05fbbf12e127a0f1a676e1014a1f2a9d.pyx:2:8: Expected '(', found 'sample_func_cython'. Did you use cdef syntax in a Python declaration? Use decorators and Python type annotations instead.
Cythonのクラス
クラスの方は、cdefと書いても普通にPythonからアクセスができます。
ただし、属性の場合はpublicと指定しないと、Python側からアクセスはできません。
他の、__init__やselfなどはPythonと同じです。
%%cython
cdef class Fruit:
cdef public int fruit_id
cdef public int price
def __init__(self, int fruit_id, int price):
self.fruit_id = fruit_id
self.price = price
apple = Fruit(1, 100)
apple.fruit_id
1
apple.price
100
なお、Cythonの関数をPythonから呼び出す場合、キーワード引数を受け付けてくれないようです。
%%cython
cpdef int sample_func_cython(int a):
a += 1
return a
sample_func_cython(a=100)
TypeError: sample_func_cython() takes no keyword arguments
一方で、クラスの方のコンストラクタなどは、キーワード引数を受け付けてくれるようです。
apple = Fruit(fruit_id=1, price=100)
クラス内の関数はpublicの記述は不要なものの、Pythonから参照する際にはdefもしくはcpdefじゃないと参照できません。
%%cython
cdef class Fruit:
cdef int fruit_id
def __init__(self, int fruit_id):
self.fruit_id = fruit_id
def get_fruit_id(self):
return self.fruit_id
apple = Fruit(fruit_id=1)
apple.get_fruit_id()
1
Cythonでの配列
cdef 型名 変数名[行数][列数] という形式で、配列を定義できます。ベクトルであったり、もしくはもっとサイズの大きいテンソルなどの場合は括弧の数を増減させてください。([10]とか[10][10][10]といったように)
10行5列の整数の配列を作成する例 :
%%cython
cdef int arr[10][5]
print(arr)
[[0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0]]
更新や参照は普通にインデックスで行えます。、
%%cython
cdef int arr[10][5]
arr[2][3] = 10
print(arr[2][3])
10
ただし、Pythonの感覚でファンシーインデックスやスライスなどはできません。個別にインデックスにアクセスする必要があります。
Cythonで遅い記述をしていないか調べる
例えば、型を記述していないとかで遅くなる要因の個所など、そういったことを調べたい場合はcythonのマジックコマンドで引数に-aを指定すると、詳細を表示してくれます。
%%cython -a
cdef int func_1(int c):
return c * 2
def func_2(d):
return d * 2
cdef a = 0
cdef int b = 0
cdef int i
for i in range(100000000):
a += 1
b += 2
以下のようなアウトプットがノート上に表示されます。
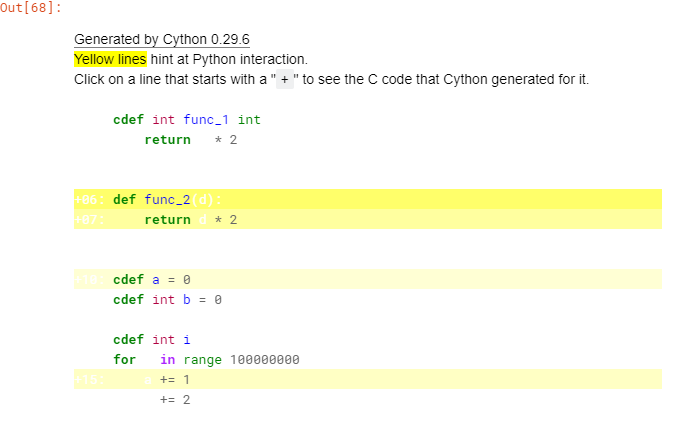
白い部分の行は文句無しに速く、黄色い行の個所は処理が多い遅い個所です。
濃い黄色になるほど遅くなります。
たとえば、型宣言をしていないとか、cdefではなくdefで定義しているところなどが該当します。
各行をクリックすると、Cython上で必要な処理が表示できます。
白い行をクリックすると、少ない行数の内容が表示され、必要な処理が少なくて済んでいることが分かります。
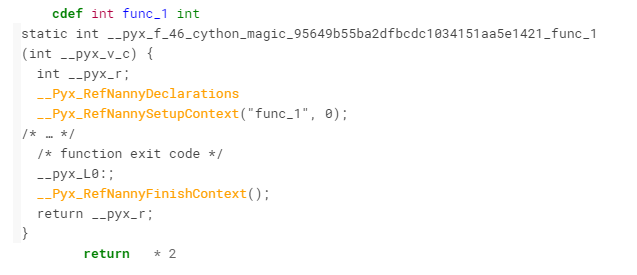
逆に黄色い個所をクリックすると、色々な処理が出てきて、必要な処理が多く負荷の高いことが分かります。
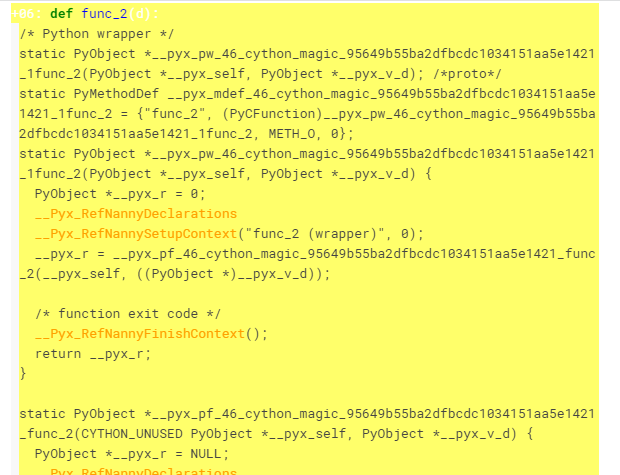
しっかりとチューニングしたい場合にはこういった感じで確認してみて、黄色くなっている個所で直せそうな個所があれば修正すると速くなります。
Numba
Cython同様、高速化でよく見かけるNumba。
Cythonが事前に内部でコンパイル的な処理を行うのに対して、こちらはJIT(Just-In-Time)と呼ばれる方式で、関数呼び出しなどで必要になったときに準備がされ、高速化などがされます。
Numbaの環境設定
基本的にはAnacondaなどでそのまま使えるので、Anacondaなどでそのまま扱うのがシンプルでいいかもしれません。
pipでバージョンを変えたりした場合、他の依存するものとの兼ね合いでエラーに悩まされたりしたので、pip単体でインストールしたりする場合もしかしたらぼちぼち手間がかかるかもしれません。
(アップデートなどする場合はpipではなくconda経由など・・が無難なのでしょうか?)
Cythonの時と異なり、こちらはAnacondaだけ入れてあれば、Windows上でも他に対応しなくても使えています。
また、Numba自体がバージョンアップで結構大きく変わったりしているそうで、バージョンによってもしかしたらこの記事のように動かない場合もあるかもしれません。ご了承ください。
本記事では以下のバージョンで進めます。
import numba
numba.__version__
'0.41.0'
基本的な使い方はとてもシンプルで、関数にjitのデコレーターを付けるだけです。
import numba as nb
@nb.jit
def sample_func(x, N):
for i in range(N):
x += 1
return x
5000万回のループを回してみます。
%%timeit
sample_func(x=100, N=50000000)
210 ns ± 2.64 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
ナノ秒の単位。大分早いです。
デコレーターの指定無しの生のPythonで試してみると差が歴然です。
デコレーター無しの元の関数は、関数に追加されるpy_func関数で参照ができます。
いちいち別途定義しなくても済むので、速度比較などの際に便利です。
%%timeit
sample_func.py_func(x=100, N=50000000)
2.08 s ± 11.3 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
2.08秒。大分遅い。
Numbaで遅い個所がないか調べる
Cython同様、Numbaでも関数内で遅くなる要因の個所が無いか調べる機能が提供されています。
また、Cythonで制約があるのと同様、こちらでもNumba特有の制限があります。
基本的にNumba自体が数値計算を高速化する目的で作られているので、数値計算以外は速くならないケースが多いです。文字列の連結などの基本的な操作などでも、高速化の対象外となります。(将来のバージョンでは変わっているかも)
デコレーターを付けた関数のinspect_types関数で詳細を調べることができます。
試しに、Numbaで高速化が効かない文字列を指定した際の挙動を調べてみます。
なお、JITの性質上、実際に関数を呼び出さないとコンパイルがされないので、1度呼び出してからinspect_typesを実行します。
@nb.jit
def sample_func(x, text):
for i in range(300000):
x += 1
for i in range(30000):
text += 'a'
return x, text
_, _ = sample_func(x=100, text='apple')
sample_func.inspect_types()
sample_func (int64, unicode_type)
--------------------------------------------------------------------------------
# File: <ipython-input-5-4908c684f6c2>
# --- LINE 1 ---
# label 0
@nb.jit
# --- LINE 2 ---
def sample_func(x, text):
# --- LINE 3 ---
# x = arg(0, name=x) :: pyobject
# text = arg(1, name=text) :: pyobject
# jump 2
# label 2
# $36 = const(LiftedLoop, LiftedLoop(<function sample_func at 0x00000221A20420D0>)) :: XXX Lifted Loop XXX
# $37 = call $36(x, func=$36, args=[Var(x, <ipython-input-5-4908c684f6c2> (3))], kws=(), vararg=None) :: XXX Lifted Loop XXX
# del $36
# x = static_getitem(value=$37, index=0, index_var=None) :: pyobject
# del $37
# jump 26
for i in range(300000):
# --- LINE 4 ---
# label 26
...
なにやら長いテキストが出力されました。
よく見てみると、セルのコードが分解されつつ、それらに:: pyobjectといった説明が付与されています。
このpyobjectといった記述になっている個所が、コンパイル後の型を示します。
pyobjectとなっている場合、jit側でうまいことコンパイルができず、Pythonのオブジェクトとして扱っている(=遅いまま)ことを示しています。
逆に、int64などの他の型になっていればネイティブモードと呼ばれる状態にコンパイルされており、非常に高速に処理がされます。
つまり関数内でpyobjectが存在しない状態にすべきであり、もしpyobjectが存在する場合、速くならないどころらNumbaのオーバーヘッドで逆に遅くなったりします。
試しに、文字列関係を含まない形にして、数値計算のみを扱う関数にしてみて内容を確認してみましょう。
@nb.jit
def sample_func(x):
for i in range(300000):
x += 1
return x
_ = sample_func(x=100)
sample_func.inspect_types()
sample_func (int64,)
--------------------------------------------------------------------------------
# File: <ipython-input-8-fefc9b602652>
# --- LINE 1 ---
# label 0
@nb.jit
# --- LINE 2 ---
def sample_func(x):
# --- LINE 3 ---
# x = arg(0, name=x) :: int64
# jump 2
# label 2
# $2.1 = global(range: <class 'range'>) :: Function(<class 'range'>)
# $const2.2 = const(int, 300000) :: Literal[int](300000)
# $2.3 = call $2.1($const2.2, func=$2.1, args=[Var($const2.2, <ipython-input-8-fefc9b602652> (3))], kws=(), vararg=None) :: (int64,) -> range_state_int64
# del $const2.2
# del $2.1
# $2.4 = getiter(value=$2.3) :: range_iter_int64
...
今度は、pyobjectの記述が消え、int64などの型の記載となりました。この状態であれば非常に高速に関数が実行されます。
うっかり、pyobjectが含まれている状態で使ってしまったりを防ぐために、デコレーターの引数でnopython=Trueと指定すると、pyobjectを許容しなくなります。もし含まれる場合にはエラーで弾かれます。
文字列を操作する処理で弾かれる例 :
@nb.jit(nopython=True)
def sample_func(text):
for i in range(100):
text += 'a'
return text
sample_func(text='apple')
TypingError: Failed in nopython mode pipeline (step: nopython frontend)
Invalid use of Function(<built-in function iadd>) with argument(s) of type(s): (unicode_type, Literal[str](a))
Known signatures:
* (int64, int64) -> int64
* (int64, uint64) -> int64
* (uint64, int64) -> int64
* (uint64, uint64) -> uint64
* (float32, float32) -> float32
* (float64, float64) -> float64
* (complex64, complex64) -> complex64
* (complex128, complex128) -> complex128
* parameterized
...
This is not usually a problem with Numba itself but instead often caused by
the use of unsupported features or an issue in resolving types.
To see Python/NumPy features supported by the latest release of Numba visit:
http://numba.pydata.org/numba-doc/dev/reference/pysupported.html
and
http://numba.pydata.org/numba-doc/dev/reference/numpysupported.html
その処理は対応していないよ、サポートしているやつはここを見てね、という親切なエラーが出ます。
ある程度触ってみた所感としては、制限は結構色々あり、数値計算で部分的に使ったり・・といった具合が現実的なところでしょうか。
PyPy
ライブラリ関係のPyPIなどと名前が似ていますが別物です。
こちらもNumbaと同様、JIT方式です。
ただし、特徴的な点として、CythonやNumbaなどと比べた際に、「マジックコマンドやデコレーターなどを記述しなくても勝手に高速化する」という点が異なります。
毎回個別にマジックコマンドなどを書かなくて済みますし、いちいち細かくチューニングしたりといった負担も減ります。
また、Pythonのビルドインモジュールやサードパーティーのライブラリなども高速化できるところは勝手に高速化されるので、デコレーターなどが付けるのが難しい個所などでも高速化の対応ができます。
それだけ聞くとなんだか凄そうに見えますが、一方でCythonやNumbaと比べると、「Python環境自体が既存のものとは別になる」ので、Cythonなどで「部分的に高速化する」みたいな気軽な導入ができません。
例えば、すでにリリースされているDjangoアプリなどでは、多くのコードが存在するプロジェクトなどでは、「気軽にPyPyに移行しよう」とは出来なさそうな印象はあります。
プロジェクトの最初からPyPy前提で組むか、もしくはマイクロサービス的に切り分けて部分的に反映するか、もしくは手間をかけて対応したりが必要になりそうな印象があります。
すみませんが、仕事で触っているDjangoのものなどは、PyPy移行などは工数とリソース的に現実的ではないので試していません。
Django関係のものを時雨堂さんが公開していらっしゃったので、そちらを引用する程度で留めておきます。
検証をじっくりやった事もあり、かなり時間がかかった。
...
結果的には CPU 使用率は半分になり性能は倍になった。もちろん、本番で、だ。
これから徐々に CPython 環境を PyPy 環境へと置き換えていく。PyPy の最大の魅力はその性能だろう。性能が大きく上がるため、既存環境にかかっているサーバ費用を削減することが出来る。
ただ、注意して欲しいのは PyPy はとてつもなくメモリーを消費する。
PyPy を本番に導入した
Jupyterであれば、ノートごとに切り分けたり、環境を別のものを使ったりというのも現実的で気軽に試せそうな気配はあります。残念ながらWindows版に関してはまだ使えるレベルではないそうなのと、Colaboratoryなどのクラウドカーネルで使ったりもできない点、自宅のPCが壊れて新しくした都合、まだUbuntuなどを入れていないため、時間がかかりそうなので今回は本記事では検証などはスキップします。(将来、機会があれば別の記事で試してみます。)
PyPy3.5のWindows版に関してはプロダクションユースのレベルには達していないと考えられており、利用する場合は注意が必要。
PyPy 7.0.0登場、3系統同時リリース
参考
- Advanced Python Programming: Build high performance, concurrent, and multi-threaded apps with Python using proven design patterns
- PyPy を本番に導入した
他にもPythonなどを中心に色々記事を書いています。そちらもどうぞ!
今までに投稿した主な記事たち