よりVS CodeのPythonの入力補完を精度良くしたり、入力補完が効かない部分をちゃんと補完してもらったり、もしくは静的型付き言語でコンパイルして型のエラーが無いか調べるがごとく、CIなどでチェックして安全にプロジェクトを扱うためのPythonの型アノテーションやPyrightなどについて学んでいきます。
記事執筆する際に使っている環境
- Python 3.7.3(Anaconda。本記事の内容は古いPythonバージョンでは使えないものが含まれます)
- Windows10
- VS Code 1.45.1
- Kite
- VS Code上の以下の拡張機能
- Python
- Kite Autocomplete for Python and JavaScript
- Pyright
※Kiteの有無などで若干補完結果が皆さんの環境と本記事でずれたりするかもしれませんがご了承ください。
そもそも型アノテーションって何?
Pythonにおける関数や変数などに対する型の明示的な指定です。型ヒントなどとも呼ばれます。
型アノテーション使うと何が嬉しいの?
型アノテーションを利用することで以下のようなメリットがあります。
エディタで入力補完が効きづらい箇所で補完が効くようになる
なにもしなくてもVS CodeなどでPythonの拡張機能やKiteなどが入っていれば結構入力補完が効いたりしますが、VS Code側で型の推測がしきれない場合には補完が効かない部分が発生します(たとえば、関数の返却値の型が推測できないケースや、参照の無い関数の引数など)。
そういったケースでも入力補完を有効にすることができ、快適且つミスを減らすことができます。
例えば以下のような関数を書いたとして、通常だと定義した直後だと引数に対して型が不明で補完が効きません。一方で型アノテーションがしてあると引数に対してエディタ上などで補完が効くようになります。
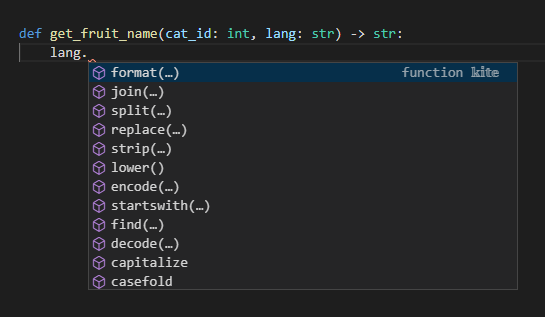
型によるチェックが実行できる
他の静的型付き言語と異なり、Pythonはビルド時に型のチェックがされたりといったことがありません。
ビルドが終わるのを待たずに部分的に実行したりテストを走らせたりできる一方で、不適切な型の利用などを検知しづらいというデメリットがあります(例えば引数に想定外の型の値を指定してしまっていたなど)。
勿論大きなプロジェクトではテストを書くのが当たり前なケースが多いので事前にミスを検知できるケースも多くありますが、静的型付き言語のようにコンパイルエラー的に自動でチェックしてくれるとより安心です。
型アノテーションとチェック用のライブラリを使うと、エディタ上やCLIでCI的に静的型付き言語をコンパイルするのと近い形でチェックを走らせることができます。
特にコード量が膨大なプロジェクトなどではこれらの自動チェックがあると安心・安全です。
例えば400万行以上のPythonコードが存在するDropboxなどでは、型アノテーションとチェックがしっかりと使われています。
Dropbox の Python コードは数百万行にも及ぶ規模となっていますが、その動的型付けによってコードが必要以上に理解しにくくなり、生産性に深刻な影響を与えるようになりました。
...
静的型チェックの鍵は、規模です。プロジェクトが大きくなればなるほど、静的型チェックの必要性を感じるようになります(最終的には必須になります)。
...
型チェッカーは大小問わず多くのバグを見つけます。「None」 値などの特別な条件の処理が忘れられているような場合が、よくある例です。
Python の型チェックが 400 万行に到達するまで
コードの理解を助けてくれる
型が明示されていることで、他の人がコードを読んだとき「どんな型の引数が必要なのか」「どんな型の値が返るのか」「この変数の型は何なのか」がすぐに把握できます。
また、半年後などに自分でコードを見返したりする際にも大抵はコードのことを忘れてしまっているので、書いた当時のことを思い出すときなどに役立ちます。
もちろんdocstringがその辺りの可読性に役立つことが多々ありますが、docstringでは厳密なチェックがされないため、実際の型とずれてしまっていたり、もしくは書き忘れてしまったりするケースが発生しかねません。
また、関数などの説明などは逆に型アノテーションだけだと分からないので型アノテーションだけあればOKというものでも無くできたらdocstringと型アノテーション両方利用すべきだと考えています。
※docstringに関しては昔記事を書いたのでそちらの記事をご確認ください。
実際に仕事での数十万行程度のPythonプロジェクトで、途中から自作してPyPI(pip)登録したdocstringチェック用のLintを通したところ、docstringが実際と色々乖離していたという経験をしています(例 : 途中で引数を加えたけどdocstring側に引数を加えていなかったとか、返却値があるのに返却値の説明を書いていなかったとか、もしくはそもそもdocstringが書かれていない関数があるなど)。
docstringに関して記事を自分で書いている身ではありますが、それでも自身のコードでうっかりミスが色々見つかっています。チェックが無い状態では(気を付けていても)コードの信頼に少し欠けるので、型アノテーションなどでの静的チェックは有益に感じています。
この辺りはDropboxの記事でも触れられているので引用しておきます。
もちろんドキュメンテーション文字列(docstring)で文書化されているのが理想的ですが、経験上、そうではないことが多いと圧倒的に言えます。ドキュメントがあっても、その正確さを当てにはできません。ドキュメンテーション文字列があっても、あいまいであるか正確でないことも多く、誤解を招く余地が多くあります。
Python の型チェックが 400 万行に到達するまで
事前のPyrightの追加
型アノテーションなどに詳しく触れていく前に、チェック用として使うため事前にVS Codeの拡張機能としてPyrightを入れておきます。
Pyrightはマイクロソフトによって作られたライブラリで、機能としては有名なmypyなどと同じような感じで型チェックのVS Codeなどの拡張機能とCLIが用意されています。Pyrightの方が後発のライブラリとなります。
mypyなどと比べてどっちがいいのだろう?と思いましたが、大雑把に比較してみたところ以下のような感じでした。
- VS Codeに入れるのはPyrightの方が楽だった。
- VS Code上でInstallボタンを押すだけで完了した。mypyの方は追加のライブラリインストール関係で怒られたり、エラー内容に沿って対応してみても躓いてしまった(私の環境の問題かもしれません)。
- マイクロソフト製のライブラリというだけあって、同じマイクロソフト製のVS Codeでの利用が楽だなと感じました。
- Githubのスター数はこの記事を書いている時点でmypyが8500くらいなのに対してPyrightは5200くらい。
- Pyrightの方が結構後発で期間的には不利なのと、型チェックの先駆者的なmypyが知名度を加味してもやっぱりスター数は多そうです。
- まあでもどちらも使う分には十分なレベルかな・・・という印象。
- ライセンスはともにMIT。
- issueはこの記事を書いている時点ではPyrightが8件のOpenと609件のClosed。mypyは1257件のOpenと4080件のClosed。
- この辺りはOpenのissueの少なさ的に、後発のPyrightでももう十分安定しているのでは・・・?という印象です。
- 速度はPyrightの方が速いらしい。
- mypyよりも平均で数倍程度は速いそうです。将来お仕事でウン十万行のPythonコード達にCI的に全体にチェックを走らたいと考えている点を加味すると速さという要素は意外と馬鹿にできません。
- 対応しているエディタはmypyの方が多そう。
- この記事を書いている時点だとPyright側はVS CodeとVimのみ記述があります。対してmypyはVS Code、PyCharm、Vim、Emacs、Sublime、Atomと色々なエディタに対する記述があります。
- 対応しているPythonバージョンはPyrightは3系のみ。mypyは2系のコードに対しても処理を走らせることはできますが、実行自体は3系が必要(2系のプロジェクトであればmypy実行用のみに別途3系のインストールが必要)とのことです。
今回は仕事で使いたいプロジェクトのコードベースが結構大き目なのと、インストールでスムーズだったのでPyrightを使いますが、mypyも素晴らしいライブラリだと思うので皆さんの環境に合わせて選択ください。
Pyrightの拡張機能のVS Codeへのインストールが終わると、チェックが開始されます。試しにstrの型を指定して整数を代入してみます。
name: str = 100
マウスオーバーしてみるとエラー内容が表示されています。ちゃんと動作してくれているようです。

型アノテーションのやり方
変数への型アノテーションの書き方
変数に関しては: 型名といった形で記載します。例えばnameという変数に対して文字列を設定したい場合にはname: strといったように書きます。
この時点でname = 'タマ'といったように値を設定していなくても補完が効くようになります。
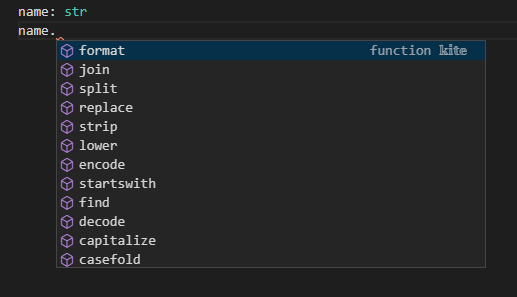
以下のように型アノテーションと値の代入を同時に行うこともできます。
name: str = 'タマ'
特定の名前空間内のクラスなどを指定したい場合はその名前空間も一緒に指定しないと怒られます。たとえばimport collectionsというimportの記述がある状態でdefaultdictを指定したい場合には: defaultdictと書かずに: collections.defaultdictと書きます。
import collections
cat_defaultdict: collections.defaultdict
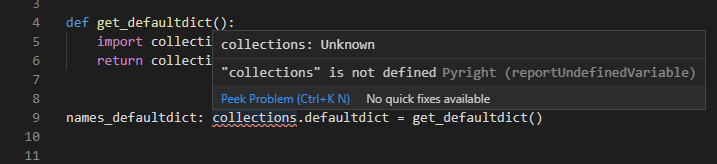
名前空間が解決できない場合(例えば別のモジュールでimportされている型で、今使用しているモジュールではimportされていない場合など)にはエラーが表示されます(以下のサンプルでは関数内でimportしているため、スコープ的に関数の外ではアクセスできないのでエラーになっています)。
def get_defaultdict():
import collections
return collections.defaultdict(int)
names_defaultdict: collections.defaultdict = get_defaultdict()
この書き方に関してはPythonの3系の途中のバージョンからの対応となっています。2系では使うことはできません(といってもEoL的に大半の方は3系を使っていらっしゃるとは思いますが・・・)。
2系で型アノテーションを使う必要がある場合には代替としてインラインコメントで# type: <特定のクラス>といったように指定することで同じようなことができます。
インラインコメントをする際にはPEP8で半角スペースを2個以上設定することとされているのでそちらに従って2つスペースを付与して書きます。
name = 'タマ' # type: str
※こちらの書き方はPython2系でもサポートされているというだけで、3系でも使えます。ただし3系での利用で大きなメリットは今の所思いつきません・・・(コードで2系と3系両方サポートする必要がある場合などに便利?)。
Pyrightで不正な値を指定してみても、ちゃんと認識してくれていることが確認できます。
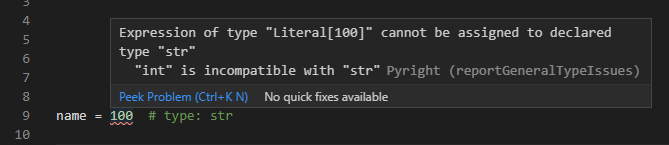
インラインコメントを使った書き方の場合、型のコメントだけではエラーになってしまいます(代入などの記述が必要になります)。例えば、name: strといった書き方はそれだけでも書くことができますが、name # type: strといった書き方だと未定義のエラーになってしまいます。
NameError: name 'name' is not defined
インラインコメントによる型アノテーションのみの書き方ができないことによって、例えばループで生成される変数に対する型指定などがやりづらいという弊害があります(そのうちPythonやライブラリ側で対応してくれるかもしれませんが・・・)。
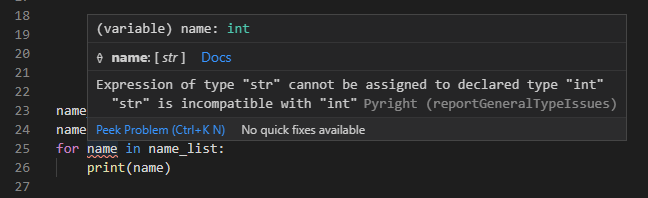
例として以下のように、事前にiという変数に型を指定しておくことで、ループで割り振られる値の型がおかしいといったことを検知したりがインラインコメントだとできません(for name in name_list: # type: strみたいな書き方は認識してくれませんし、name # type: strみたいに型アノテーション単体では前述の通りNameErrorになります)。
name_list = ['タマ', 'ポチ']
name: int
for name in name_list:
print(name)
型アノテーション単体での指定ができないため、例えばif文などでも
こういった細かい点でコロンを使った書き方よりも不便なケースがちらほら見受けられるので、特に理由がなければインラインコメントではなくコロンを使った書き方を使う方向で問題ないと感じます。
そのほか、importが足りていない場合にエラーになる点はコロンを使う書き方同様、インラインコメントを使う書き方でもエラーを表示してくれます。
def get_defaultdict():
import collections
return collections.defaultdict(int)
names_defaultdict = get_defaultdict() # type: collections.defaultdict
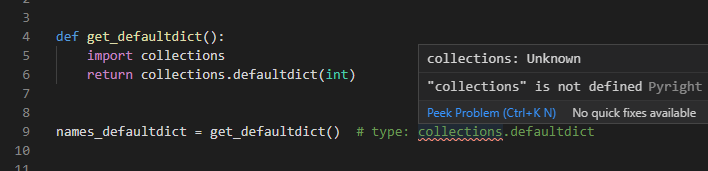
なお、余談ですがインラインコメント内の型アノテーションも含め、importが正しくないケースはflake8などのライブラリでも引っかかってくれます。Pyrightなどを入れていないプロジェクトでも、flake8をすでにCIなどで入れてあればその辺りはチェックすることができます。
リストの中身が特定の型のみの場合の書き方
リストの中身が特定の型のみの変数に対して、単純な: listという型アノテーションではなくリストの中身の型まで指定したい場合にはビルトインのtypingモジュールのListを使ってList[型名]といったように書きます。
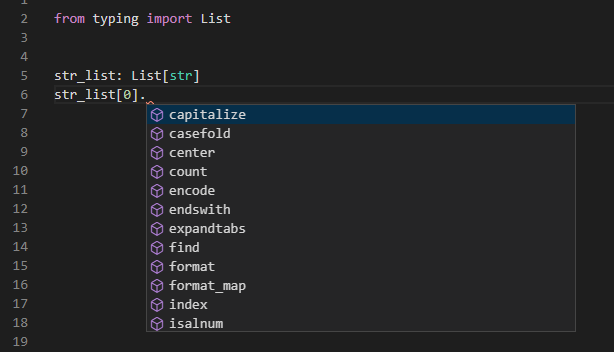
たとえば文字列を格納するリストであればstr_list: List[str]といったように記述します。
from typing import List
str_list: List[str]
このように型アノテーションをすることで、リストに対して添え字を指定して値にアクセスしたときに補完が効くようになります(まだリストの中身を指定していない状態でも補完が効きます。以下のスクショでは文字列の候補が表示されています)。
※記事執筆時点でもVS CodeとKiteなどの拡張機能も大分賢いので、シンプルなコードであれば型アノテーションしなくてもリストに添え字を指定した際に補完してくれることが多くあります。ただし複雑なコードになってきたりサードパーティーのライブラリの都合などでリストの中身までは補完が効かないケースはぼちぼち発生し、そういったケースなどにもリストの型アノテーションは便利です。
typingモジュールは最近のPythonバージョンであればビルトインになっていますが、Python2系や古い3系ではビルトインにはなっていません。ただしpipでバックポートできるようになっそているので古いバージョンを使わないといけない場合にはそちらをインストールします。
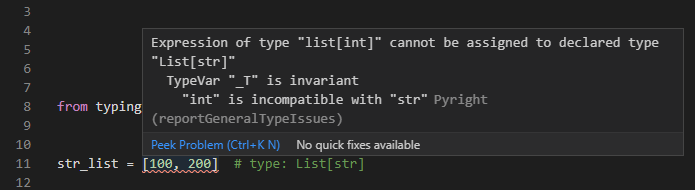
インラインコメントでも同様にtypingモジュールによる型のアノテーションを使用することができます。以下のサンプルのように不正な型の値がリストの内部に入っているとエラーになります。
from typing import List
str_list = [100, 200] # type: List[str]
タプルで内部の値に型を指定する場合の書き方
単純にタプルとして補完が効くようにする場合には: tupleといったように指定すればOKです。タプル内部の値まで含めて補完してくれるようにして欲しい場合にはリストと同様にtypingモジュールのTupleクラスを使います。: Tuple[型名]といったように書きます。
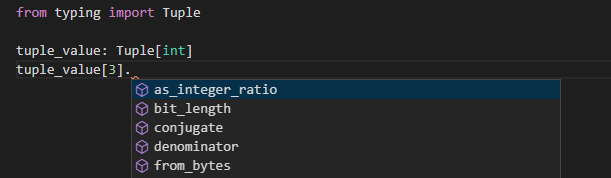
以下のコードのように、整数を格納するタプルの場合にはTuple[int]といった形になります。値を設定していなくても特定のインデックスの値にアクセスした場合にはVS Codeで補完が効いていることが分かります。
from typing import Tuple
tuple_value: Tuple[int]
タプルはリストと異なり、一度値が設定されたら値の件数や型は変わりません。そのため、値の件数と各値の型の分だけコンマ区切りで型を指定します。
たとえば整数, 文字列, 整数という3つの値を格納するタプルがあった場合にはTuple[int, str, int]といったように記述します。
from typing import Tuple
tuple_value: Tuple[int, str, int]
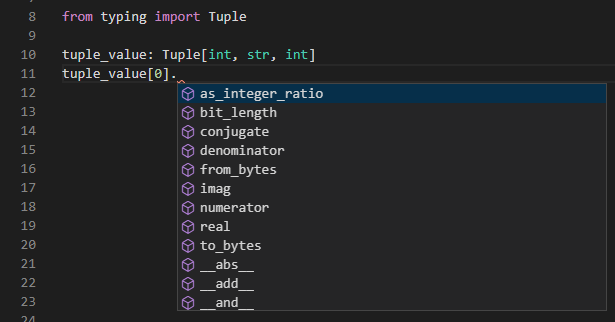
VS Code上で試すと、参照するタプルのインデックスに応じて補完結果が整数や文字列などにちゃんと反映されていることが確認できます。
整数のインデックスを参照している場合 :
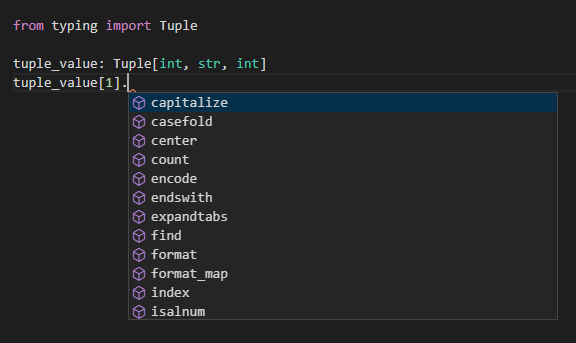
文字列のインデックスを参照している場合 :
※リストは基本的に内部の値が変動したりしうるため、List[str, int]といったように複数の型を指定するとエラーになります。
from typing import List
list_value: List[str, int]
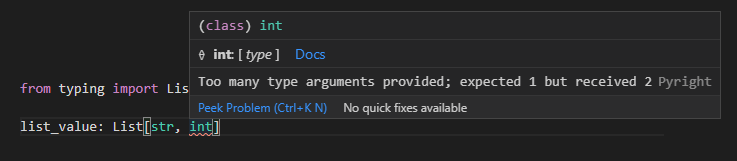
タプルの件数と型の指定の件数が一致していない場合にはエラーで引っかかります。
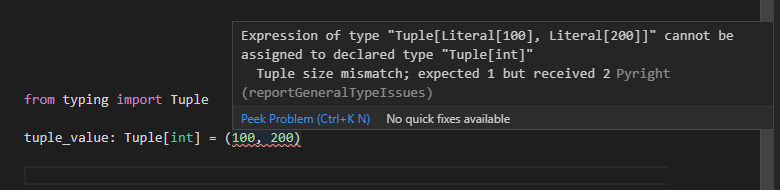
from typing import Tuple
tuple_value: Tuple[int] = (100, 200)
もし全てintのタプルだ・・・みたいな型の指定をしたい場合には先頭にその型を、2番目の位置にEllipsisオブジェクトの...を指定することでエラー無く記述することができます(Pythonの3つのドットはEllipsisオブジェクトとして意味を持ちます)。
from typing import Tuple
tuple_value: Tuple[int, ...] = (100, 200)
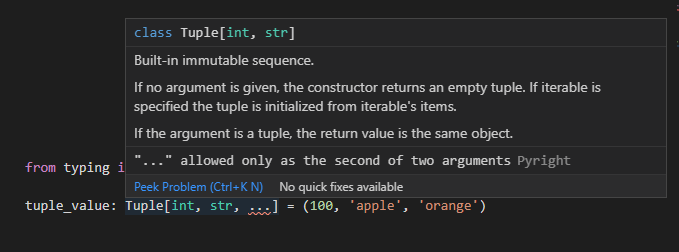
先頭はint、次はstr、それ以降はずっとstr...といった指定をしたいときにはTuple[int, str, ...]といった書き方はできないようです。Pyright側でEllipsisオブジェクトの指定は2番目以外受け付けないとエラーになります。
from typing import Tuple
tuple_value: Tuple[int, str, ...] = (100, 'apple', 'orange')
インラインコメントによる型アノテーションも同様にタプルなどでも利用できます。基本的に他の型でも同様に利用できるので、以降は変数に対するインラインコメント関係の型アノテーションの説明は特殊なものを除いて割愛します。
辞書でキーと値に型を指定する場合の書き方
辞書もtypingモジュールを使うことでキーと値に対する型のアノテーションをすることができます(単純に辞書としてだけアノテーションしたい場合にはtypingモジュールを使わずに: dictと指定します)。
typingのDictクラスを使って、: Dict[キーの型, 値の型]という形式で書きます。例えばキーに文字列、値に整数が設定される場合にはDict[str, int]といったように書きます。
以下のサンプルのように、正しくキーに文字列、値に整数が設定されている場合にはエラーになりません。
from typing import Dict
dict_value: Dict[str, int]
dict_value = {'apple_price': 200}
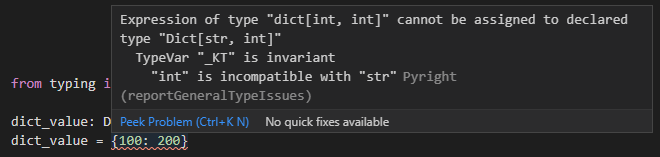
対して、キーに整数が設定されているような不正な辞書の値を指定した場合にはエラーになります。
from typing import Dict
dict_value: Dict[str, int]
dict_value = {100: 200}
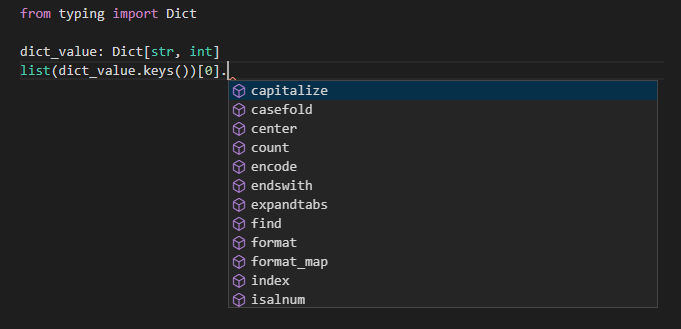
また、辞書のkeysやvaluesで取れるiterableオブジェクトをリストにキャストし、特定のインデックスにアクセスしてみてもちゃんと指定した型に応じた補完がされます。
辞書のキーを参照した際に文字列の補完がされるサンプル :
from typing import Dict
dict_value: Dict[str, int]
list(dict_value.keys())[0].
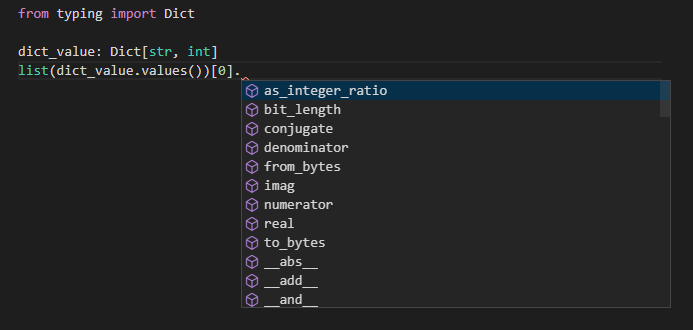
辞書の値を参照した際に整数の補完がされるサンプル :
from typing import Dict
dict_value: Dict[str, int]
list(dict_value.values())[0].
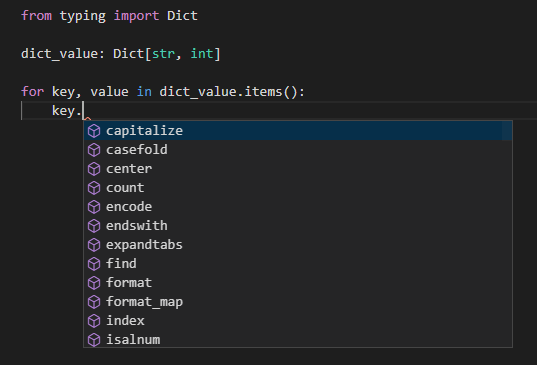
他のキーと値が絡む処理、例えばループを回したりするときにもキーと値でそれぞれ補完が効きます。
from typing import Dict
dict_value: Dict[str, int]
for key, value in dict_value.items():
key.
関数の引数と返却値に対して型を指定する
関数の引数や返却値に関しても変数などと同じように型を指定していくことができます。
引数に関しては変数と同じようにコロンを使って記述し、返却値に関しては関数定義(defの行)の最後に -> 返却値の型:と書きます。
仮にtype_idとlocation_idという2つの整数の引数を持つ関数の場合にはtype_id: int, location_id: intといったように引数を書き、整数の返却値を返す場合には -> int:といったように書きます。
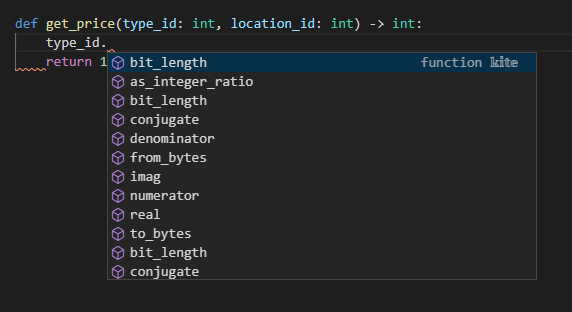
def get_price(type_id: int, location_id: int) -> int:
return 100
型アノテーションをしておくことで、引数参照時に補完が効いていることを確認できます。
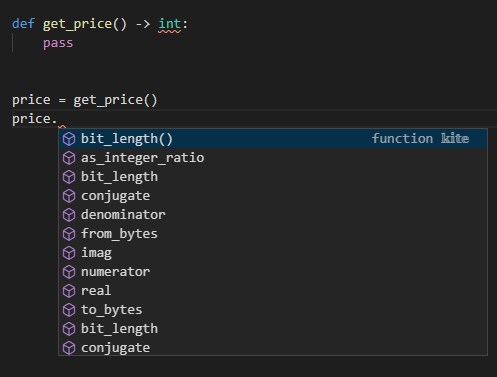
また、返却値に関しても関数の内容を書く前から実行後の返却値で補完が効くことを確認できます。
def get_price() -> int:
pass
price = get_price()
price.
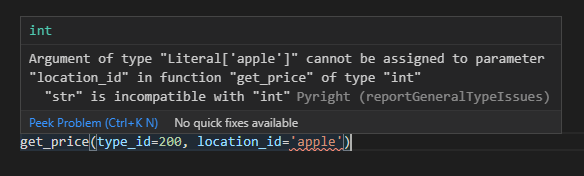
関数呼び出し時に引数の型が一致していない場合にはエラーになります。
def get_price(type_id: int, location_id: int) -> int:
return 100
get_price(type_id=200, location_id='apple')
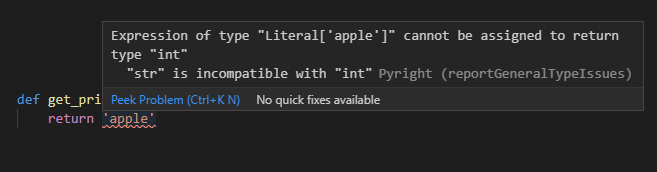
また、返却値に関しても指定した型と内実が合っていない場合にはエラーになります。
def get_price(type_id: int, location_id: int) -> int:
return 'apple'
デフォルト値が必要な場合には型の記述の後に設定することができます。
def get_price(type_id: int=100) -> int:
return 100
返却値の無い関数の場合には -> None:といったようにNoneを指定します。もしくは型アノテーションの記述を省略してもいいかもしれません。
def get_price(type_id: int) -> None:
pass
引数が多くて1行の長さが長くなってしまう場合(PEP8などの規約に抵触してしまう場合)には引数と一緒に型アノテーション部分を改行させる書き方ができます。
def get_price(
arg_1: int,
arg_2: int,
arg_3: str,
arg_4: bool,
arg_5: list) -> int:
return 200
Python2系などの都合でコロンを使った書き方が使えない場合には、関数の直下にコメントで# type: (コンマ区切りの引数の型名) -> 返却値の型名といったように書くことができます。
def get_price(type_id, location_id):
# type: (int, int) -> str
return 100
ただし、この記事を書いている環境ではVS Codeでの補完か利きませんでした。他の環境のVS Codeでは効いていたので何故でしょうね・・・?(Pyrightを入れたから・・・?)
引数部が長くなる場合には以下のように改行を入れる形も許容されるそうです。ただしこちらもVS Code上で補完が効かず・・・。
def get_price(
arg_1, # type: int
arg_2, # type: int
arg_3, # type: str
arg_4, # type: bool
arg_5 # type: list
):
# type: (...) -> int
return 101
まあとりあえずはPyright使える環境であればコロンや->などを使ったアノテーションが使えるケースが大半だと思うため、コメントではなく普通にそちらを使いましょう・・・といったところでしょうか。
コメントでの書き方が必要な場合にはmypyなどの方が無難かもしれません(未検証)。
関数を変数として扱う場合の引数と返却値の型の指定
あまり使う機会はありませんが、関数を変数に設定して扱う必要がある際にはtypingモジュールのCallableクラスを使います。
第一引数にリストの形式で各引数の型を書き、第二引数に返却値の型を書きます。例えば整数と文字列の引数を受け取って整数を返す場合にはCallable[[int, str], int]といったように型を指定します。
from typing import Callable
def get_price(type_id, name):
return 10
x: Callable[[int, str], int] = get_price
price = x(100, 'apple')
上記サンプルコードではget_priceという関数には型のアノテーションがしてありませんが、一方でxという変数に関しては型が指定してあるので(仮に関数の内容が未実装でも)返却値に補完が効きますし、不正な型の値を引数に指定するとエラーになることを確認することができます。
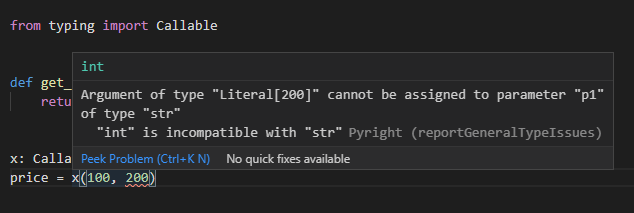
複数の型を受け付ける場合の書き方
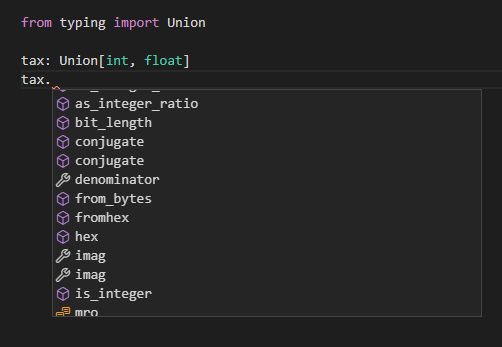
ある特定の変数などが、複数の型を許容する場合にはtypingモジュールのUnionクラスを使用します。例としてintとfloat両方受け付ける場合にはUnion[int, float]といったように書きます。
from typing import Union
tax: Union[int, float]
補完のリストを見てみると、intとfloatのもの両方が含まれているようです(intにしか無いbit_lengthとか、floatにしか無いis_integerなど)。
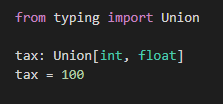
Unionで指定した通りにintやfloatの値を指定した場合にはエラーになりません。
intを指定したケース :
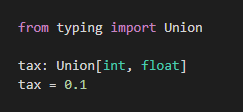
floatを指定したケース :
一方で、Unionで指定した値以外(文字列など)を指定した場合にはエラーになります。
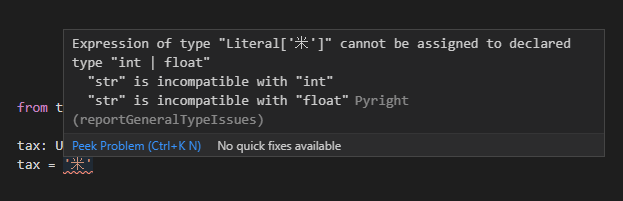
「文字列もしくは数値を格納するリスト」といった場合には、typingモジュールのListとUnionを入れ子にします。
from typing import List, Union
list_value: List[Union[int, str]]
list_value = [100, 'apple']
Unionで指定されていない値をリストに入れてみるとエラーになることが確認できます。
list_value = [100, 'apple', {}]
関数の引数などでも使えます。例えば引数でリストでもタプルでもどちらでも指定できるといった場合には以下のように書きます。
from typing import Union
def get_price(targets: Union[list, tuple]) -> int:
return 10
返却値も同様で、例えば関数内で分岐によってintもしくはfloatが返るといったようなケースには以下のように書くことができます。
from typing import Union
def get_price(tax_included: bool) -> Union[int, float]:
if tax_included:
return 1.1
else:
return 1
受け付ける型が膨大にある。そんなときは・・・
基本的にあまりこういったケースは無いような気もするのですが、対象となる型が膨大にあって型のアノテーションをすると記述が膨大になってしまうケースにはtypingモジュールにAnyというクラスが用意されているのでそちらを使うか、もしくは型のアノテーション自体をスキップします。
from typing import Any
any_value: Any
もちろん補完も効きませんし、チェックが緩くなるので使うメリットはあまりありません。
チェックのエラーを特定の行で無視したい場合
こちらもあまり使うケースはありませんが、特定の行で何らかの理由でチェックを無効化したい場合にはインラインコメントで# type: ignoreと指定します。
以下のコードのようにエラーで引っかかるような条件を書いても、Pyrightでエラーにはならなくなります。
def get_price() -> int:
return 10
price: str = get_price() # type: ignore
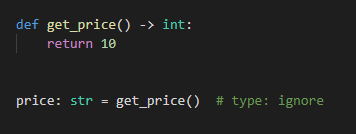
インラインコメントを外した場合 :
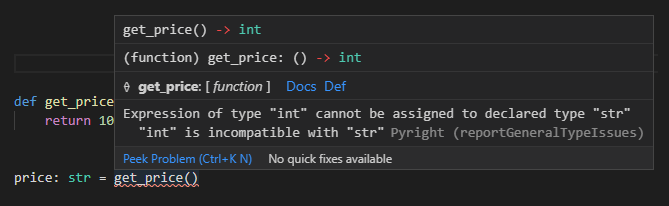
※エラーを握りつぶすのと同じような対応になるので、多用はしないようにしておくといいと思われます。
再代入を禁止する形(定数的な値)の型を指定する
typingモジュールにはPython3.8以降という制約が付きますが、Finalというクラスが存在します。PEP 591で追加された機能になります。
PEP 591ではJavaのfinalみたく、クラスやメソッドの上書きなどを禁止する機能が追加されたのですが、同時に型アノテーションとしてのFinalクラスを使うことで定数に近い制御ができるようになっています(実行の際にはPython3.8以降が必要になります)。
以下のように書きます。
from typing import Final
INT_CONSTANT: Final = 10
Finalクラスを指定した変数に対して再代入しようとするとエラーになります。
from typing import Final
INT_CONSTANT: Final = 10
INT_CONSTANT = 20
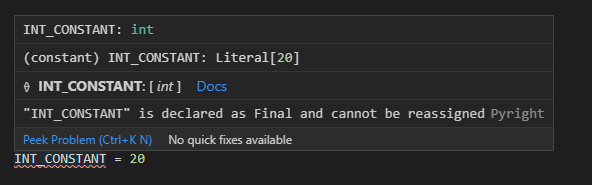
型まで指定したい場合にはFinalだけでなくFinal[型名]といったように書きます。例えば整数の制限を付与したい場合には以下のように書きます。
from typing import Final
INT_CONSTANT: Final[int] = 10
Finalは他のものを入れ子にすることもできます。例えばListを中に格納して、再代入できない値を作ることができます(以下は再代入しようとしていてエラーになっている例)。
from typing import Final, List
LIST_CONSTANT: Final[List[int]] = [100, 200, 300]
LIST_CONSTANT = '100'
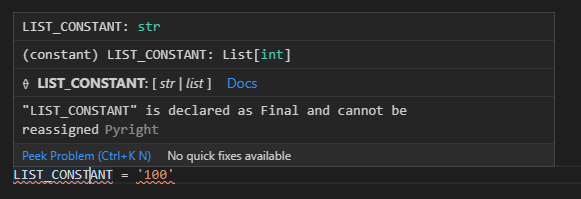
ただし、「再代入ができない」という定義なので、「リストはリストのまま、appendメソッドなどで中に値を追加する」といったことはできてしまうため厳密には「定数のリスト」とは異なります(以下の例で、Pyrightでエラーになっていないことを確認できます)。
from typing import Final, List
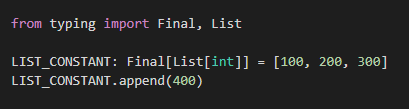
LIST_CONSTANT: Final[List[int]] = [100, 200, 300]
LIST_CONSTANT.append(400)
内部の値も固定したい場合にはタプルもしくはtypingモジュールのSequenceクラスを使います。Sequenceクラスは1つの型の値(整数であればintのみ等)のみリストなどへ指定できます。タプルは複数の型を指定できますが、長さに合わせてそれぞれに対して型を指定する必要があります(Ellipsisオブジェクトをタプルで使うとSequenceと似たような挙動になります)。
FinalとSequenceは以下のように合わせて使います。appendなどをしようとするとエラーになることが確認できます。
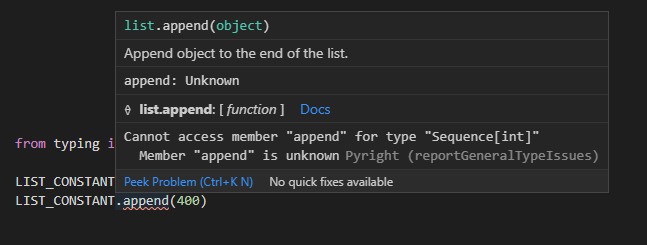
from typing import Final, Sequence
LIST_CONSTANT: Final[Sequence[int]] = [100, 200, 300]
LIST_CONSTANT.append(400)
クラスの属性に関しては、PEP591でコンストラクタを持つクラスであればコンストラクタの__init__のメソッド内でのみFinalを使うように、という記述があります(メソッドを通さずにダイレクトに属性をFinalで設定するのはOKだそうです)。
as self.id: Final = 1 (also optionally with a type in square brackets). This is allowed only in
__init__methods, so that the final instance attribute is assigned only once when an instance is created.
PEP 591 -- Adding a final qualifier to typing
そのため属性に対してFinalを使う場合には__init__内で設定します。
from typing import Final
class Cat:
def __init__(self) -> None:
self.age: Final = 10
以下のように他のメソッドなどで設定しないようにします。
from typing import Final
class Cat:
def __init__(self) -> None:
pass
def set_age(self, age: int) -> None:
self.age: Final[int] = 10
※現在この書き方をしてもPyrightではエラーにならないようなので要注意です。issueを出したら「次のバージョンで直しておくよ」と返信いただいたので、きっと近いうちに修正が入ると思われます(issue #717)。
追記 2020-06-14 : マイクロソフトの方が対応してくださり、アップデートでPEP591のチェックが最新バージョンからされるようになりました!
また、__init__を経由せずに以下のように直接属性を設定することもPEPなどで推奨されていません。__init__での設定を利用しましょう。
from typing import Final
class Cat:
age: Final[int] = 10
def __init__(self) -> None:
pass
list-likeやdict-likeなダックタイピングでの書き方
Pythonだとダックタイピング的にlist-like(もしくはarray-like)やdict-likeといった形で引数などを受け付ける書き方が多くされています。
型アノテーションでそれらに対応したい場合には、typingモジュールのIterableクラスやMutableMappingクラスなどを利用します。
まずはlist-likeの対応としてIterableクラスについてリスト・タプル・NumPy配列の三つで試してみます。
使い方は今までと似たような形で、値に対してまでアノテーションが必要であれば: Iterable[型名]といったように書きます。それぞれのケースでVS Code上でエラー(赤い下線)になっていないことが確認できます。
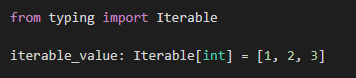
from typing import Iterable
iterable_value: Iterable[int] = [1, 2, 3]
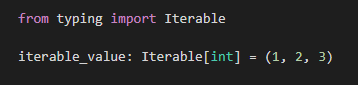
from typing import Iterable
iterable_value: Iterable[int] = (1, 2, 3)
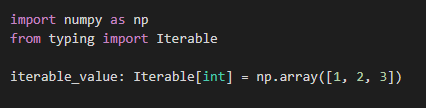
import numpy as np
from typing import Iterable
iterable_value: Iterable[int] = np.array([1, 2, 3])
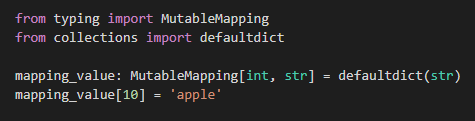
同じような形で、dict-likeのものに対して型のアノテーションをしたい場合にはMutableMappingクラスを使います。
Dictクラスの型アノテーションと同様に、キーと値にまでアノテーションをしたい場合には: MutableMapping[キーの型, 値の型]と指定します。dictとdefaultdictで試していますが、それぞれでエラーになっていないことが確認できます。
from typing import MutableMapping
mapping_value: MutableMapping[int, str] = {10: 'apple'}

from typing import MutableMapping
from collections import defaultdict
mapping_value: MutableMapping[int, str] = defaultdict(str)
mapping_value[10] = 'apple'
クラスを引数に指定する場合の書き方
たまにクラスを関数の引数に設定するケースがあります。そういった場合の型アノテーションにはいくつかやり方があります。
まずは引数へ: typeと型アノテーションするやり方です。型情報を調べるtype関数のイメージが強かったのですが、クラスの変数や引数としての指定もtypeを設定するようです。
このやり方の場合にはインスタンス化する部分で対象のクラスの型を指定します(以下の例ではcat: Catという部分)。
class Cat:
def __init__(self):
self.name = 'タマ'
self.age = 10
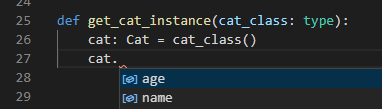
def get_cat_instance(cat_class: type):
cat: Cat = cat_class()
このやり方でもインスタンス化後に補完が効いていることが確認できます。
関数呼び出し時でも引数にクラスを指定しているとエラー無く通ります。
get_cat_instance(cat_class=Cat)
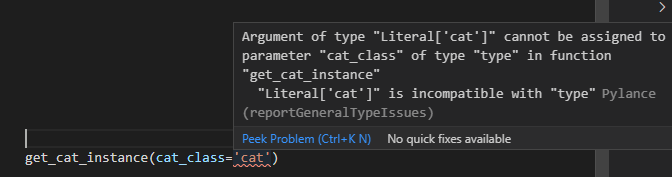
引数にクラス以外、例えば文字列を指定した場合などにはエラーで弾いてくれることを確認できます。
get_cat_instance(cat_class='cat')
ただしこの書き方だと引数に指定する値はクラスであれば何でも許容されてしまいます。
たとえば以下のように引数に指定したクラスと関数内で型アノテーションされている型がずれた場合にはエラーになってくれません。
def get_cat_instance(cat_class: type):
cat: Cat = cat_class()
class Apple:
def __init__(self):
self.price = 100
get_cat_instance(cat_class=Apple)
もう一つの方法はtyping.Typeを引数の型アノテーション部分に指定する方法です。括弧の中には対象のクラスを指定する形で: Type[Cat]といった形で書きます。
この書き方の場合にはインスタンス化の時に型アノテーションをしなくても補完などが効いてくれます。
from typing import Type
class Cat:
def __init__(self):
self.name = 'タマ'
self.age = 10
def get_cat_instance(cat_class: Type[Cat]):
cat = cat_class()
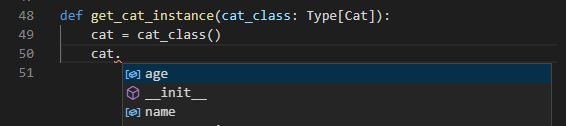
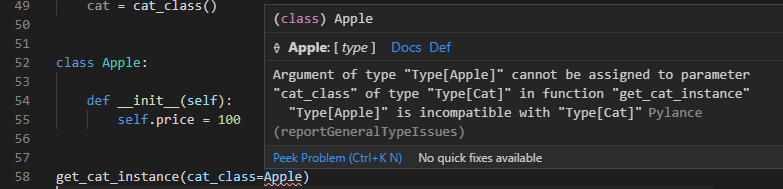
また、この書き方の場合は引数指定時にクラスの相違があればエラーで気づけるのでより堅牢なコードになります。
class Apple:
def __init__(self):
self.price = 100
get_cat_instance(cat_class=Apple)
Jupyterでの利用は?
Jupyter上で型アノテーションを使いたい場合には、いくつか選択肢があります。
まず一つ目がVS CodeのPythonの拡張機能を入れると、JupyterがサポートされているのでVS Code上でJupyterを使う方法です。以下のように型アノテーションをすると補完が効くようになります。
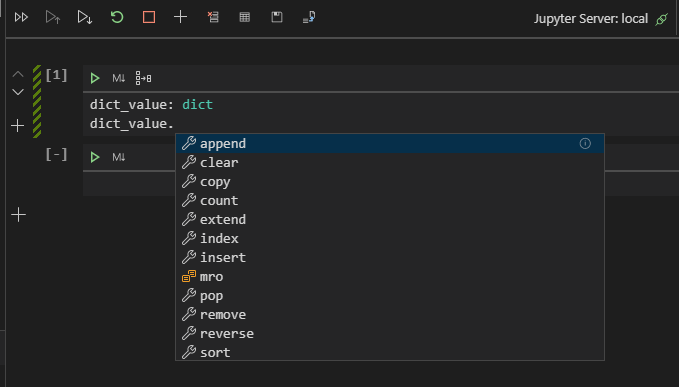
ただしこちらはPyrightやKiteなどが有効になってくれないため、型チェックが実行されず補完もKiteなどのものは使われません。
もう一つの方法は、以前「ついにJupyterLabの入力補完??Tab押さずに補完してくれるjupyterlab-lspを試してみた」の記事で書いた通り、JupyterLabであればリンク先の記事で紹介したライブラリを使ってpyls-mypyとかを利用することで型アノテーションによる補完や型チェックが有効になります(ただし、以前触った時にはPandasとかは補完に時間がかかっていました。アップデートで変わった可能性はありますが未確認)。
LabではなくJupyter notebookでは、マジックコマンドなどで一応型チェックもいけそう?な気配はありますが、マジックコマンドだとちょっと辛いかな・・・?という気もします。もっとよく探せばもしかしたら利用方法があるかもしれません。
import関係でエラーが出る!という場合は
なにやらimport関係でPyrightでエラーが出る場合には、使っている環境の切り替え(VS CodeでいえばCtrl + Shift + Pキーでの「Python: Select Interpreter」コマンドでの環境切り替え)や仮想環境のパス指定、その他↓の記事のextraPathsなどの設定でいけると思われます。
VSCodeでPyrightとpylintからのimport警告を無くしたい
コマンドラインでのPyrightの利用
インストール
コマンドラインで使う場合にはVS Codeの拡張機能と違ってある程度インストールで作業が必要になります。
まずはnode.jsをインストールします。今回の記事ではAnacondaを使っていたのでそちらにインストールします。
ref: https://anaconda.org/conda-forge/nodejs
$ conda install -c conda-forge nodejs
...
The following NEW packages will be INSTALLED:
nodejs conda-forge/win-64::nodejs-14.4.0-0
python_abi conda-forge/win-64::python_abi-3.7-1_cp37m
...
Anaconda Prompt上でnpmのコマンドが打てることを確認 :
$ npm --help
npmでPyrightをインストール :
$ npm install -g pyright
Pyrightがコマンドラインから打てることを確認 :
$ pyright --help
...
Usage: pyright [options] files...
Options:
--createstub IMPORT Create type stub file(s) for import
--dependencies Emit import dependency information
-h,--help Show this help message
--lib Use library code to infer types when stubs are missing
...
コマンドラインで実行してみる : シンプルな実行
最低限の実行自体はとても簡単で、pyright <ファイルパス>とするだけです。
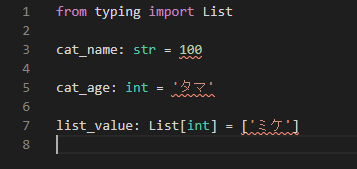
試しにエラーがたくさん発生するような内容の.pyファイルを用意します。
from typing import List
cat_name: str = 100
cat_age: int = 'タマ'
list_value: List[int] = ['ミケ']
Anaconda環境にインストールしてあるのでAnaconda Promptでコマンドを実行してみます。
$ pyright sample.py
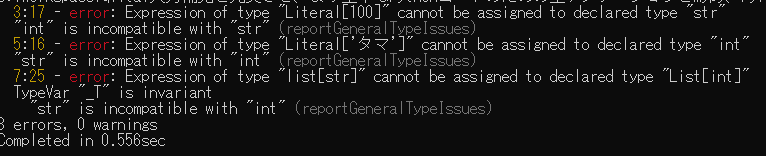
行と列番号と共にエラー内容が色々出てくれました。お手軽です。
また、ファイルパスではなく以下のようにディレクトリを指定しても.pyファイルを検索して処理してくれるようです。
$ pyright ./
パフォーマンスの統計情報を表示する
--stats引数を追加するとパフォーマンスの統計情報を表示してくれます。
$ pyright sample.py --stats
Analysis stats
Total files analyzed: 9
Timing stats
Find Source Files: 0sec
Read Source Files: 0.01sec
Tokenize: 0.04sec
Parse: 0.06sec
Resolve Imports: 0.04sec
Bind: 0.05sec
Check: 0.02sec
Detect Cycles: 0sec
出力をJSONファイルにする
CI的に自動で回したりする場合にはJSON形式でアウトプットできると色々制御が楽です。
--outputjson引数を加えると標準出力の内容がJSON形式になります。今回は>>のリダイレクト表記でファイルに出力してみました。
$ pyright sample.py --outputjson >> result.json
{
"version": "1.1.41",
"time": "1591706367489",
"diagnostics": [
{
"file": ".....\\sample.py",
"severity": "error",
"message": "Expression of type \"Literal[100]\" cannot be assigned to declared type \"str\"\n \"int\" is incompatible with \"str\"",
"range": {
"start": {
"line": 2,
"character": 16
},
"end": {
"line": 2,
"character": 19
}
}
}
],
...略
"summary": {
"filesAnalyzed": 9,
"errorCount": 3,
"warningCount": 0,
"timeInSec": 0.211
}
}
Completed in 0.549sec
そのままだと最後のComplete...といった部分が余分です。
ドキュメントを読んでいたのですが、末尾のものを表示しないようにする方法が分からず・・・今はそういったオプションが無かったりするのでしょうか?その辺りが少し曖昧です。
まあでも正規表現とかでさくっと消せる範囲ではあります。
参考文献・サイトまとめ
- Static type checker for Python
- Python と型アノテーション
- Python の型チェックが 400 万行に到達するまで
- [Python]可読性を上げるための、docstringの書き方を学ぶ(NumPyスタイル)
- NumPyスタイルのdocstringをチェックしてくれるLintを作りました。
- Type hints cheat sheet (Python 3)
- Type hints cheat sheet (Python 2)
- Kite - AI Coding Assistant for Python and JavaScript
- typing・PyPI
- PEP 591 -- Adding a final qualifier to typing
- 2020年5月におけるPython開発環境の選択肢
- Pyright Command-Line Options
- VSCodeでPyrightとpylintからのimport警告を無くしたい
- PEP 484 -- Type Hints