本格的にはDB用意しなくていいんだけど、ちょこっと作業したり実験したりする際に少し使いたいケースが出てきたので、PythonでのSQLite周りを調べてみました。
以下のようなライトなユースケースです。
毎回最初から最後までスキャンしたり書き直したりするのは避けたかったのでCSVを使用しませんでした。MySQLを使用した方が良かったのかもしれませんが、厳しい期限があったので迅速にプログラムを完成するには、SQLサーバを追加設定する時間はありませんでした。この場合、SQLiteで十分でした。
Pythonや機械学習、そして言語の競争について – 極めて主観的な見地から
(他の言語では使っていたことがあるものの、Pythonでは初です)
なお、ベタのクエリよりもORMをメインに扱っていきます。
使うもの
- Python3.6
- Windows10
- SQLAlchemy
- DB Browser for SQLite
- Jupyter Notebook
インストール
SQLite自体は最初からPythonで使えるようです。
また、SQLAlchemyに関しても、Anacondaであれば最初から入っている?ようです(今回使うPython環境ではv1.3.1が入っていました)。
$ pip install SQLAlchemy
Requirement already satisfied: SQLAlchemy in c:\users\****\anaconda3\envs\****\lib\site-packages (1.3.1)
また、内容の確認などのためのクライアントとしてDB Browser for SQLiteをインストールしておきます。Windows版は以下からインストーラーを落とせられます。
インストールしてPCを再起動(必要な場合)した後に、起動してみると以下のようなGUIが表示されました。
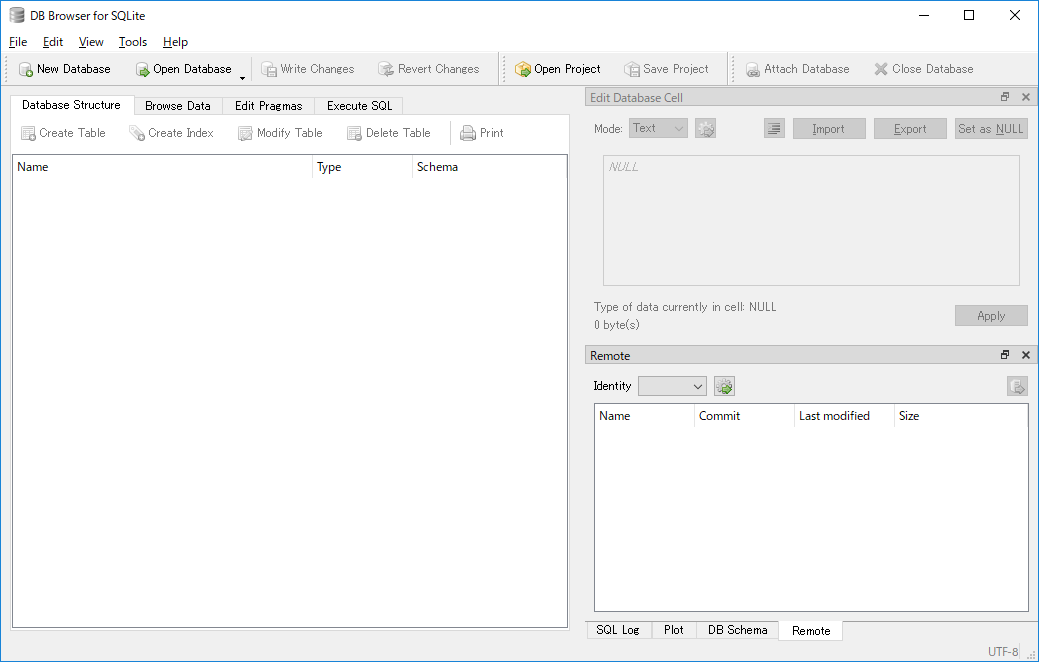
DB生成と接続
Jupyter上で、DB接続などを進めてみましょう。
また、その際にモデルを1つ試しに設定しておきます。
まずは必要なモジュールのimport。
import sqlalchemy
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String
from sqlalchemy.orm import sessionmaker
DBファイルへの接続周りの処理を流します。
第一引数にファイルのパスを指定します。パスの先頭にsqlite:///という特殊な記述が必要になります。スラッシュが3本必要な点も注意してください。
第二引数にTrueを指定すると、モデルでの操作時のクエリのログなどがコンソール出力されるようになります。直接クエリを書いていないと、どんなクエリが流れているのか分かりづらい時があるため、今回はTrueで進めます。
engine = sqlalchemy.create_engine('sqlite:///sample_db.sqlite3', echo=True)
サンプルにモデルを一つ用意します。基底クラスはdeclarative_base経由で用意するようです。
Base = declarative_base()
先ほど用意した基底クラスを継承して、Fruitというモデルを用意しました。
Djangoとかだと、IntegerFieldといったように型に応じたクラスを指定しますが、SQLAlchemyだとColumnクラスを指定して第一引数に型(Integerなど)を指定する形式のようです。
主キー指定のprimary_keyなどはDjangoと同様、max_length的な最大文字数の指定などはlengthと引数が該当するようです。
また、DjangoでのMetaなどによるテーブル名などの指定は、アンダースコア2個の属性を指定する形で設定します。
class Fruit(Base):
id = Column(Integer, primary_key=True)
name = Column(String(length=255))
__tablename__ = 'fruit'
モデルを用意したら、基底クラスのmetadata.create_allメソッドを実行すると、まだ未生成のテーブルが生成されファイルに書き込まれます。
Base.metadata.create_all(bind=engine)
今回は初回なので用意したモデルに対してCREATE文が走っていることが分かります。
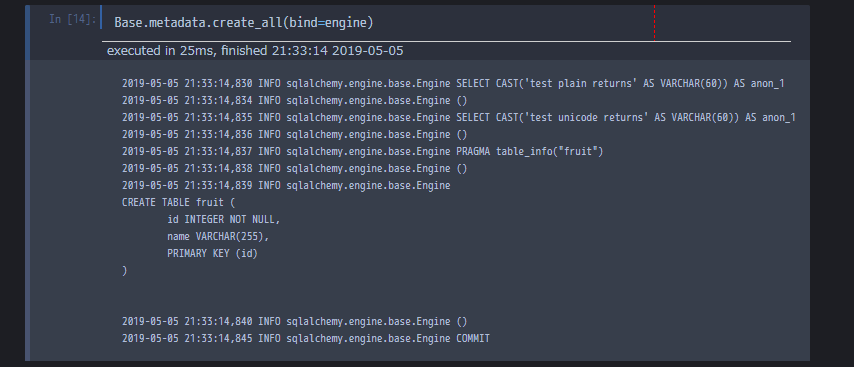
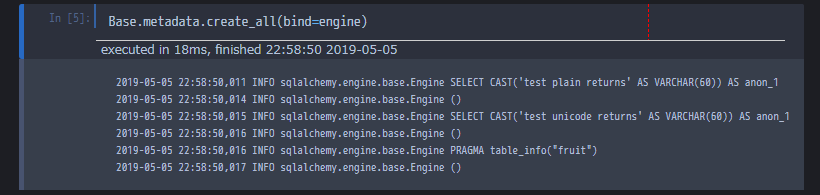
一度カーネルを再起動してまた同じコードを流してみると、今度はすでにテーブルが生成されていないのでCREATE文は流れません。
また、指定した名前でSQLite用のファイルが生成されていることが分かります。
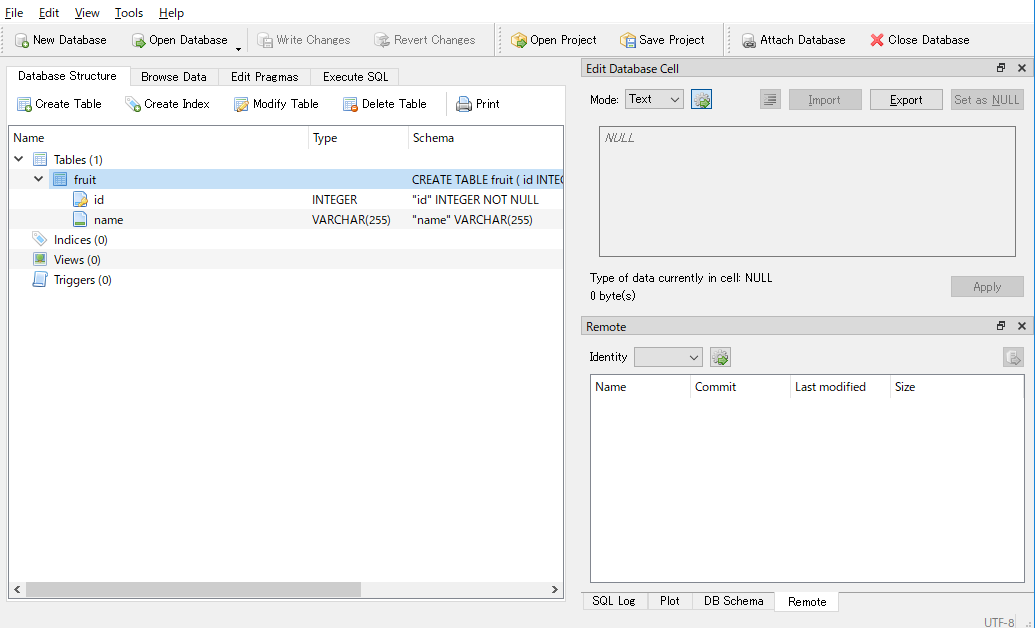
DB Browser for SQLiteのOpen Databaseを選択して内容を確認してみます。
fruitテーブルが正常に生成されているようです。
Insert
用意したモデルのクラスのオブジェクトを作って、値を設定して、addメソッドを呼んで、commitする、馴染みのある流れのようです。
session = sessionmaker(bind=engine)()
apple = Fruit()
apple.id = 3
apple.name = 'apple'
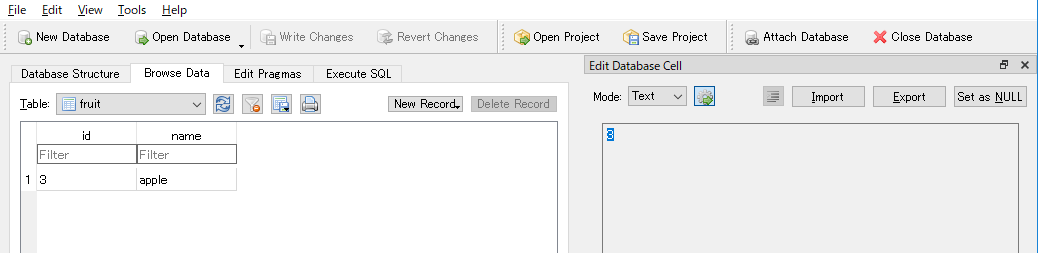
session.add(instance=apple)
session.commit()
Browse Dataのタブを見てみると、正常に値が追加されていることが分かります。
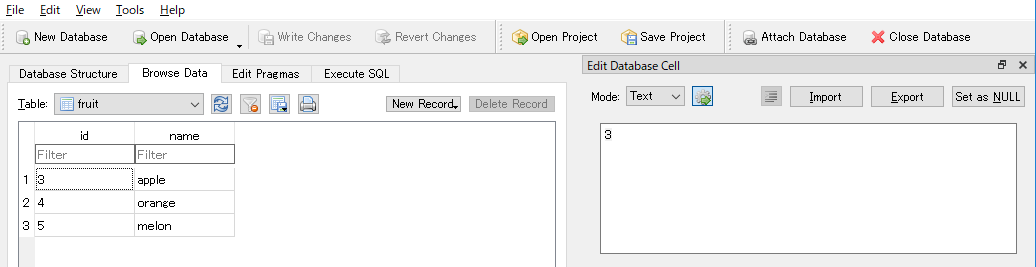
複数挿入する場合にはadd_allを使います。
session.add_all(instances=[
Fruit(id=4, name='orange'),
Fruit(id=5, name='melon'),
])
session.commit()
SELECT
queryメソッドで第一引数に対象のモデルを指定するとiterableオブジェクトが返ってくるので、それをループで回したりしてアクセスします。
query_result = session.query(Fruit)
for fruit in query_result:
print(fruit.id, fruit.name)
3 apple
4 orange
5 melon
条件指定
単純な一致による条件を指定する際にはfilter_byをメソッドチェーンで繋げていきます。
apples = session.query(Fruit).filter_by(name='apple')
for apple in apples:
print(apple.id, apple.name)
3 apple
Not equal的な指定をしたい際にはfilterメソッドで、引数に条件を書きます。
query_result = session.query(Fruit).filter(Fruit.name != 'apple')
for fruit in query_result:
print(fruit.id, fruit.name)
4 orange
5 melon
大なり小なり的な指定も同様にできます。
query_result = session.query(Fruit).filter(Fruit.id >= 4)
for fruit in query_result:
print(fruit.id, fruit.name)
4 orange
5 melon
複数の条件を指定する際には、条件単位で()の括弧で囲んで、ORの場合は|、ANDの場合は&を記載します。Pandasと同じ書き方ですね。
query_result = session.query(Fruit).filter((Fruit.id == 3) | (Fruit.id == 4))
for fruit in query_result:
print(fruit.id, fruit.name)
3 apple
4 orange
query_result = session.query(Fruit).filter((Fruit.id == 3) & (Fruit.name == 'apple'))
for fruit in query_result:
print(fruit.id, fruit.name)
3 apple
部分一致では、モデルのカラム部分にlikeの関数を挟みます。
query_result = session.query(Fruit).filter(Fruit.name.like('%a%'))
for fruit in query_result:
print(fruit.id, fruit.name)
3 apple
4 orange
1件のみ取得
さらにoneメソッドを繋げると、1件のみの取得となり、ループを書かずに済みます。
apple = session.query(Fruit).filter_by(name='apple').one()
print(apple.id, apple.name)
取得件数制限
1件ではなく、件数の制限にはlimitメソッドを加えていきます。
query_result = session.query(Fruit).limit(2)
for fruit in query_result:
print(fruit.id, fruit.name)
昇順・降順の指定
order_byメソッドを加えて、引数にモデルとそのカラムを指定します。カラムはさらに昇順のascや降順のdescなどの関数を持つので、必要なものを指定します。
query_result = session.query(Fruit).order_by(Fruit.id.desc()).limit(2)
for fruit in query_result:
print(fruit.id, fruit.name)
5 melon
4 orange
Update
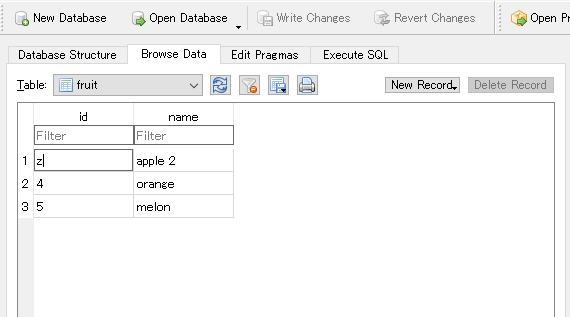
更新対象のオブジェクトをqueryで取得して、変更が必要な属性を更新してcommitします。どうやらupdate的な関数は実行しなくていい・・・模様です。
apple = session.query(Fruit).filter_by(id=3).one()
apple.name = 'apple 2
session.commit()
Delete
レコードを削除する際には、対象をqueryメソッドなどで選択してから、deleteを呼び出します。
orange = session.query(Fruit).filter_by(id=4).one()
session.delete(orange)
session.commit()
※DB Browser for SQLiteで開いている状態では、ロックされていて削除ができませんでした、といったようなエラーが出てきました。アプリを閉じたら問題なく削除できました。
開きながら削除できないっぽい・・?
ロールバック
なんらか処理に失敗すると、以下のようなエラーが出ることがありました。
InvalidRequestError: This Session's transaction has been rolled back due to a previous exception during flush. To begin a new transaction with this Session, first issue Session.rollback().
そういった場合は一度rollbackメソッドを流してあげると操作ができるようになります。
session.rollback()
切断
処理が終わったらcloeseメソッドでセッションを閉じます。
session.close()
とりあえず、基本的なところを動かしつつメモしてみましたが、馴染みのあるAPIで、DjangoやMySQLなどに慣れている方なら特に違和感なく使えるのでは・・・という印象です。