
(StackGAN-v2のリポジトリより画像を転用。(ライセンス)
ディープラーニングのGANsに関して、日本語の資料が少ないので色々書いていきます。
記事の留意点
- 私自身、大した知識はありませんので、もし間違っていたらコメントなどでご指摘ください。
- 数学・統計的なところなどは扱いません。(読み物程度な範囲)
小難しい数式が並ぶとげっそりするよね。
そもそもGANsってなに
略さず書くと、Generative Adversarial Networksで、各種論文やGoodfellow本などと呼ばれている?Deep Learningの松尾研の方々の翻訳本などでは敵対的生成ネットワークなどと表記(訳)されているようです。
敵対的、とあるように、普通のディープラーニングのネットワークと異なり、GeneratorとDiscriminatorと主に呼ばれる複数のネットワークが存在します。
Generator側のネットワークは騙す人、Discriminator側のネットワークは暴く人、といったものになります。
Learning Generative Adversarial Networksの書籍の例などを参考にしたり、他の方のスライドなどを見ていた感じ、Generator側は怪盗、Discriminator側は探偵的なものに例えるとしっくりきます。
Generator(怪盗)側はいかに探偵側をよくだますことができるかを学習していき、Discriminator(探偵)側は怪盗側の偽装いかに正確に暴けるのかを学習していきます。

基本的にはGenerator側とDiscriminator側交互に学習を進めていきます。
そのやりとりはまるでスポーツの勝負のようで、それに由来して「敵対的」という名前が付けられています。
Generator側が学習のステップ(エポック)が進むにつれて、どんどん偽造が本物と区別がつかなくなり、Discriminator側の学習のステップが進むごとにどんどん偽造の難易度が高くなっていきます。
結果として、学習が終わることにはGeneratorは本物と区別が付きづらいレベルのデータの生成ができるようになります。
(記事の先頭に添付した、AIが作成した画像など、人が見ても猫の画像は猫に見えます。)
どんな風に使われているの?
まず一番目立つのが画像の生成。
与えたデータセットから、今までになかった画像を生み出すという研究が色々公開されています。
また、画像の生成と絡めて、文章から画像を生み出すといった研究も公開されています。(黄色い羽根の小さい嘴をもった小鳥 を生成といった具合に)
本物に近い画像の生成ができる、ということは他のディープラーニングの学習用のデータセットとしても使えるケースがある、ということになります。
ディープラーニングのデータセットはまともな量を高い精度で集めようとすると、とても大変です。
一度、5桁件数の画像のデータセットを手作業で分類するということをしたことがありますが、大分泥臭くしんどい作業でした。(CIFAR10などのデータセットを手作業で分類した方は偉大だなと・・)
且つ、時間のかかる作業なので、「猫」「犬」といった明確な分類の場合は問題ありませんが、もっと曖昧な主観によるものの場合、途中で「あれ、これこっちのクラスじゃね?」といったことが起こりえます。(分類を始めてしばらくたった後など)
総じて辛い作業と言えます。(その分、分類済みのデータセットが金山に例えられたりするわけですが)
Apple Machine Learning JournalのImproving the Realism of Synthetic Image
などを読んでも、以下のようなことが書かれています。
- 高い精度を出すには多くのデータセットが必要になる。
- それらは用意するのに高いコストがかかる。
- 代替として、合成(AIによって生成)された画像を使ってデータセットを補助する方法がある。
- しかし、合成画像の場合、十分にリアルに見えない(ので、本物に見えるGANsの手法を開発した)。
iPhoneの顔認証など、セキュリティ的にとても高い精度が求められますが、おそらくそれらにはこういった技術が応用されているのでしょう。
90%程度の精度を出すのは大変ですが、こういったセキュリティが絡むものは9がたくさん並ぶ精度まで求められると思います。(とてもじゃないですが、手作業では対応はできない印象)
GAN は、AI――特にディープラーニング――の進化にとってきわめて大きな障害となる「膨大な手作業の必要性」を解消するものです。
Generative Adversarial Network とは――トップ研究者が解説
余談ですが、この辺りのビジネスによって必要な精度が異なるという点は、機械学習の記事だったりデータサイエンスの本などでよく見かけるので、それらも読んでみても面白いかもしれません。
ある気象学者は、ハリケーンが自分の町を襲う確率を予測していた。街を襲わない確率は99%から100%の間であると、95%の信頼度で推定した。彼はこの精度に喜び、避難勧告は必要ないと街にアドバイスした。残念ながら、ハリケーンはやってきて、街中が水没した。
この例は、精度(accuracy)だけを使って結果を予測するということの不備を示している。
Pythonで体験するベイズ推論 PyMCによるMCMC入門
他にも、条件付きGAN(Conditional GAN、CGAN)の応用で、例えば線画を着色したり、モノクロ画像に色を付けたりといった研究もされています。
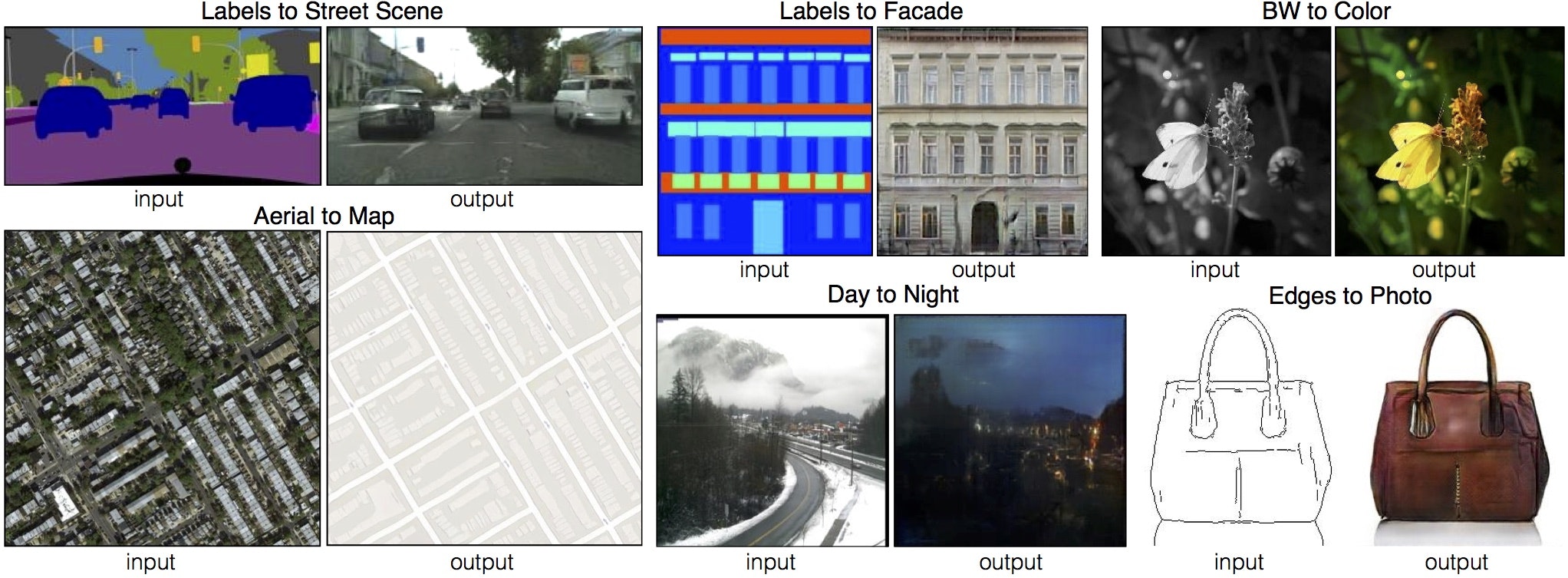
pix2pixのリポジトリより。(ライセンス)
バッグの線画に、本物の写真のような色を付けたり、四角などの単純な画像を建物の画像に変換したりなど。
上記のpix2pixのものは、Facadeのデータセットなどを使って実際に学習をさせてみたり、線画着色などを試してみたりしてみましたが、少ないデータセットでも優れた結果が出たり、そのパワフルさに驚いた覚えがあります。(Facadeデータセットなどに至っては、訓練データが数百程度?だったように記憶しています。通常の数万~数十万の画像の学習が必要な画像分類から考えるととても少ない)
Qiitaでも、こういった方面は以前初心者がchainerで線画着色してみた。わりとできた。などの記事で話題になったので、ご存じの方は多いのでは。(私も、上記のPaintsChainerのもので大きくGANs方面に興味を持ちました)
(勉強してみて、ハードルの高さを大分感じましたが、初心者とは一体なんだったのか・・Preferred Networksの社員の方という点で、察するべきでした・・)
そのほか、強化学習や自然言語関係と絡めたり、音声関係など様々な分野で応用されています。
上記のようなメリットだったり、後述しますが少ないデータセットでもパワフルに動作するといった点から、今後もディープラーニング方面でよく使われていくのでは、と思われます。
(歴史はまだ浅いとも言え、どんどん早いスピードで発展していったりしています)
2017年のディープラーニング技術は主に画像系技術で革新的な進歩がありました。それをけん引したのは敵対的生成技術(GAN)です。GAN技術とは、画像等を生成する生成器と"生成された"画像かどうかを見分ける識別器を互いに競わせることで性能を向上させる技術です。非常にパラメータチューニングの困難な技術であり、これまで研究が停滞していましたが、2017年には大きなブレークスルーを起こしました。
2017年のディープラーニング論文100選
敵対的生成ネットワークの波が言語処理にも確実に来ており、Discriminatorに注目したこの研究は様々な応用が効くように感じた。
言語処理学会第24回年次大会(NLP2018)に参加 & 論文賞受賞しました
使ってみたい!でもどんな勉強をすれば良さそう?
とりあえずPythonとディープラーニングの基礎的な知識はあると便利なので、Pythonの本(データサイエンス方面の技術も含む)とゼロから作るDeep Learningだったりが未消化であれば先にそちらをやっておくといいと思われます。
ディープラーニングのライブラリに関しては、論文は結構PyTorchを見かけます。
また、KerasだったりTensorflowだったりでgithubに各論文を動かすためのコードを公開してくれてたりもよく見かけます。
そのため、それらをある程度触れるといいかもしれません。
普通のディープラーニングのものと比べると、モデルのコードが結構長くなるので、試行錯誤がしやすいPyTorchが人気なのでしょうか?このあたりはPyTorchを軽くしか触ったことがないためなんとも・・
他の方の記事でも、KerasだけでなくPyTorchを身に付けたい(もしくは、身に付けてみたら使いやすい)ということをよく見かけるので、近いうちに身に付けたいところです・・。
(PyTorchだったりKerasの和書が少なく、Kerasは私も洋書で勉強しましたが、辛いところ・・)
ただ、pix2pixなどいろいろなGANsの公開されている論文のものは、githubで公開されていく手順を踏んでいくことで、ライブラリだったり数学だったりの知識がほぼなくても遊べます。(環境的なものか、最初はエラーに大分悩まされましたが・・逆にエラー内容を解決するためにLinuxだったりPython周りで結構知識を使ったような)
そういった遊びでも、自身でデータセットを集めて線画着色など実現してしまうので、勉強する前に実際に自分で動かしてみても面白いかもしれません。
できそうなことはだいたいできる画像生成AI、pix2pixの汎用性に驚くの記事なども参考になるかなと。
(ちなみに、結構データセットが綺麗なもので、長時間かかるエポック分pix2pixで学習させたところ、大分綺麗な画像が出力されることが結構ありました。画像の一部が濁ったり汚くなったりは、データセットなどを工夫したりで回避できそうな印象があります。この辺りはそのうち検証できたら記事を書きます)
なお、より深いところまで学んでいこうとすると、普通のGANsでは物足りなくなり、たとえば複数のGANを重ねてより本物らしい画像を生み出すStackGAN方面だったり、Conditional GAN方面(pix2pixなど)も色々応用が広がっていくと思います。(どんどんより優れた論文などが出たりしていて、キャッチアップがとても大変ですが・・)
そういった論文を読むためにも、数学だったり統計だったり他のディープラーニング方面の知識だったり、そもそもそういった新しめのものは大体英語だったりするため、やはり英語がある程度読めたりするといいのかなぁ・・という印象です。
この辺りは、敷居が高く、私も全然勉強が足りていない(追いついていない)ですが、とてもわくわくする領域なので、それをモチベーションに頑張っていくしかないかなと。
まとまりませんが、今回の記事は以上です。