まえおき
- この記事は執筆中のやさしくはじめるPythonプログラミングの本の特定の章の部分抜粋です。
- 入門本なので初心者の方向け。
- Pythonの基本的なところの章が対象となります。
- Qiita記事にマッチしていない箇所(「章」や「ページ」といった単語が使っていたり、改行数が余分だったり、リンクが対応していない等)があるという点はご留意ください。
面倒なのでQiita用に調整するのやりたくない。気になる方は↑のリンクの電子書籍版をご利用ください。 - コメントなどでフィードバックいただいた場合、書籍側にも活用・反映させていただく場合があります。
Pythonの基礎
この章では、Pythonの基本的なところを学んでいきます。地味な内容もまだ多いですが、大切な内容であり且つ基礎がしっかりしていると学習がスムーズになります。スキップせずに、且つ実際に皆さん自身で手を動かしてコードを実行してみて進めてみてください。
足し算、引き算・掛け算...基本的な計算
前の章でも少し出てきましたが、基本的な足し算などの計算方法を見ていきます。
数字や記号は全部半角なので気を付けて
計算に進む前に全角半角について触れておきます。
各コードは全角だと動いてくれないので、半角の数字や記号などを使用してください。序盤のうちは全角で打ってしまったりも結構してしまうと思いますが、そうすると以下のようにエラーになってしまいます。
3 * 3
File "<ipython-input-26-7de8af1d1fd9>", line 1
3 * 3
^
SyntaxError: invalid character in identifier
invalidは「無効な」といった意味で、characterは「文字」、indentifierは「識別子」といったような意味ですが、意味が分かりづらいので特定の(プログラムの)文字列の部分で、といった意味で現状では捉えてみてください。
プログラムの文字列の中に無効な文字が含まれていますよ、というエラーメッセージです。
また、エラーの内容にある^の記号は、上の部分が無効な文字の部分ですよ、ということを指しています。上記の例だと全角のアスタリスクが指し示してあり、そこが修正が必要(半角にする必要がある)なことが分かります。
また、Jupyter上では半角の記号にちゃんとなっていれば、文字が紫色になったりします。全角の場合は黒のままです。
大きさだけではなく色でも識別できるようになっているので、うっかり全角で入力してしまった時など参考にしてみてください。


足し算
まずは足し算の方法です。加算などとも呼ばれます。英語だとAdditionとなり、プログラムでaddといった記述が出てきたら足し算のことを指していることが多いです。
数値 + 数値の形式で、数値の間に半角のプラスの記号を挟むことでPythonで計算することができます。
3 + 4
コード実行結果の出力内容:
7
他の計算も同様ですが、複数の数値で計算することもできます。
3 + 4 + 5
コード実行結果の出力内容:
12
引き算
続いて引き算の方法です。減算などとも呼ばれ、英語だとSubtractionとなり、プログラム上ではsubなどという名前で使われたりします。
数値 - 数値の形式で、数値の間に半角のマイナスの記号(ハイフン)を挟むことでPythonで計算することができます。
5 - 2
コード実行結果の出力内容:
3
掛け算
掛け算は乗算などとも呼ばれます。英語だとMultiplicationとなります。
プログラム上ではmulなどの名前で使われたりします(例 : 高校や大学などで学ぶ行列関係でmatmulといった具合に)。
数値 * 数値の形式で、数値の間に半角のアスタリスクの記号は挟むことでPythonで計算することができます。
3 * 4
コード実行結果の出力内容:
12
割り算
割り算は除算なととも呼ばれます。英語だとdivisionとなります。
少し前のセクションで触れた、0除算のエラー(ZeroDivisionError)でもこの英単語は出てきましたね。
数値 / 数値の形式で、数値の間に半角のスラッシュの記号を挟むことでPythonで計算することができます。
5 / 2
コード実行結果の出力内容:
2.5
余り
次はとある数で割った際の割り切れない分の値(余り)の計算に関してです。剰余などとも呼ばれます。英語だとremainderとかmoduloなどになります。
数値 % 数値の形式で、数値の間に半角のパーセントの記号を挟むことでPythonで計算することができます。
6 % 4
コード実行結果の出力内容:
2
累乗計算
続いて「2の3乗」みたいな、累乗計算の方法です。べき乗などとも呼ばれます。英語だとpowerといった英単語が使われます。「2の累乗」で「a power of two」といった感じの英語になります。
Pythonでは数値 ** 数値の形式で、数値の間に半角のアスタリスクを2つ連続して記述することで計算できます。1つだけだと通常の掛け算になってしまうので注意してください。
2 ** 3
コード実行結果の出力内容:
2
演算子と代数演算子の話
重要度 : ★☆☆☆☆(最初は知らなくてもいいかも)
プログラミングで色々な計算を行う際に使われる記号などは演算子と呼ばれます。英語ではoperatorとなります。
今までに出てきた足し算のプラスや掛け算のアスタリスクなどの記号は、演算子の中でも代数演算子と呼ばれます。
今後、プログラミング関係の記事や本でよく演算子という単語が出てくると思いますが、とりあえずは「計算などをするときに必要になるプラスとかの記号のことなんだな」程度に頭の片隅に入れておいてください。
あなたの年齢は?変数入門
プログラムでは、値に名前を付けると便利なことが多々あります。例えば、「私の年齢」という名前の値を考えてみましょう。
「私の年齢」という名前の値が用意されていると、その値に応じて、ケーキのロウソクの本数を決定する、みたいなプログラムを書くことができます。
また、この値は固定ではなく誕生日を迎えるごとに値が1増えていきます。
このような特定の条件で値が変わり、且つ名前が付けられたものを「変数」と言います。英語だとvariableといいます。短縮されてvarなどと表記されることも多くあります。
年齢が毎年変わるのと同様に、「変わる数」という意味合いを持ちます。ただし、数と付いていますが別に内容は数値に限ったことではありません。「あなたの名前」といった文字列が設定されたりもします。どちらかというと「変わりうるデータ」という方が意味合いが近いかもしれません。
「私の年齢」は「25」です、といったように定義することを「変数宣言」とか「変数定義」と言います。英語では「define a variable」といった感じに、「define」という単語が使われます。もしくは、「割り当てる」という意味でのassignを使って、「assign a variable」や「variable assignment」といった風に使われます。
変数の名前はそのまま変数名(variable name)と呼ばれ、この例では「私の年齢」部分が変数名となります。
Pythonで変数を定義するには、変数名 = 変数の値という形で変数名と変数の値の間にイコールを記述することで定義することができます。
プログラムの変数名は基本的に、計算の時の記号と同様に全て半角の英数字や記号などで表現します(一部例外のケースはあります)。
Pythonだと全角の文字を使っても動いたりしますが、一般的なプログラミングの慣習では半角が基本となりますので、全角の英数字を使わないように気を付けてください。
変数名は、複数の英単語から構成される場合には、間をスペースではなく半角のアンダースコア(_)などの記号で単語を繋いだりして表現します。もしくはアンダースコア自体を省略するケースもPythonだと良くあります。
例えば、「私の年齢」という変数名ではmy_ageといったように変数名を付けます。
先ほどの例で変数宣言をしてみると、以下のような形になります。
my_age = 25
このように変数に値を設定(代入)するような、イコールの記号の演算子は「代入演算子」と呼ばれます(英語だとassignment operator)。
変数の内容を確認する
変数の中身(値)を確認するには、print(変数)というフォーマットでプログラムを書きます。print(my_age)といった具合です。
このprintと括弧による記述は関数という機能を使っています。関数に関しては後のセクションで触れるので、一旦はそのまま「変数の内容を表示するにはprintを使う」とだけ覚えておいてください。
my_age = 25
print(my_age)
コード実行結果の出力内容:
25
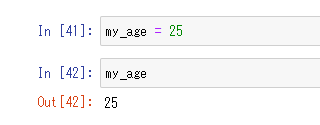
また、Jupyter上であればprintを省略しても、その変数単体をセルに入力してある場合(厳密には違いますが)にセルを実行すれば変数の内容を確認することができます。
JupyterのOut[]部分に変数の内容が表示されます。
変数の内容を変更する
変数の内容を変更するには、もう一度同じ変数名でイコールの記号を使うことで設定ができます。
たとえば、先ほどの変数のmy_ageの値を25から26に変更するには以下のように記述します。25の値を設定するときと一緒ですね。
my_age = 26
足し算と変数の更新を同時に行う : 加算代入演算子
また、変数の値が数値の場合、プラスやマイナスなどの記号とイコールを一緒に記述することで、「現在の値に対して」計算をすることができます。
例えば、my_ageという変数の値を1プラスする際には、my_age += 1といったような書き方になります。
変数への値の設定と足し算を同時にやっているので、「加算代入演算子」と呼ばれます(英語だとaddition assignment operator)。
引き算なども同様に、「減算代入演算子(subtraction assignment operator)」
「乗算代入演算子(multiplication assignment operator)」、「除算代入演算子(division assignment operator)」と名前が付いています。
何だか小難しい漢字が並んでいますが、ゆっくりと時間をかけて用語は覚えていけばいいので、今は「足し算などと変数への値の設定を同時にやれる」ということだけを覚えておけば大丈夫です。
一応本書では各用語にもある程度触れていきますが、プログラムを楽しむ上では重要ではないのと、長いことプログラミングをしていれば自然と少しずつ覚えていけるので気楽に構えていただいて問題ありません。
加算代入演算子を使うには、変数に事前に数値を入れておく必要があります。例えば、my_age = 25といったコードが必要になります。
数値が入った変数に対して、以下のように加算代入演算子などを使えます。
my_age = 25
my_age += 2
print(my_age)
コード実行結果の出力内容:
27
最初に変数に設定した25の値に2プラスされて、結果のprint部分で表示される変数の内容が27となっていることが分かります。
なお、加算代入演算子を使う代わりに、以下のようにただの代入演算子(イコールだけの記号)を使ってmy_age = my_age + 2とプログラムを書いても同じ27という結果になります。
my_age = 25
my_age += 2
print(my_age)
コード実行結果の出力内容:
27
どちらの書き方も「変数の現在の値に対して」値を足している形になるため、プログラムの結果は変わりません。
ただし、加算代入演算子(+=)を使った書き方の方が大体のケースでシンプルになります。
加算代入演算子が使えるケースではそちらの利用がおすすめです。
引き算と変数の更新を同時に行う : 減算代入演算子
+=の記号を使う加算代入演算子と同様に、-=の記号を使う形で「現在の変数の値に対して引き算を行う」計算を行うことができます。こちらの記号は減算代入演算子(subtraction assignment operator)と呼ばれます。
挙動や使い方は足し算の部分が引き算になるだけで、他は加算代入演算子のときと同じです。
my_age = 25
my_age -= 2
print(my_age)
コード実行結果の出力内容:
23
掛け算と変数の更新を同時に行う : 乗算代入演算子
*=の記号を使うと、前のセクションで触れた加算や減算と同様に「現在の変数の値に対して掛け算を行う」計算を行うことができます。こちらの記号は乗算代入演算子(multiplication assignment operator)と呼ばれます。
挙動は足し算や引き算のものと同様で、内容が掛け算になるだけです。
my_money = 1000
my_money *= 3
print(my_money)
コード実行結果の出力内容:
3000
割り算と変数の更新を同時に行う : 除算代入演算子
足し算、引き算、掛け算と来たので、勿論割り算もあります。
/=の記号を使うと、「現在の変数の値に対して割り算を行う」計算を行うことができます。こちらの記号は除算代入演算子(division assignment operator)と呼ばれます。
my_money = 1000
my_money /= 4
print(my_money)
コード実行結果の出力内容:
250.0
型ってなに?
今後、色々本を進めていくにつれて、「型」という概念が重要になってきます。
英語だとtypeとなります。
初めて見ると型とはなんだろう?という感じですが、重要な内容なので、このセクション以降では基本を丁寧に説明していきます。
説明のために、アスタリスクの記号を使った以下の数値の掛け算のコードと結果を見てみてください。
2 * 5
コード実行結果の出力内容:
10
結果が10となりました。
続いて、数値ではなく文字に対して掛け算と同じアスタリスクでのコードを実行してみるとどうなるでしょうか?
Pythonで文字は''などのクォーテーションと呼ばれる記号で囲むと表現できます。
'猫' * 5
コード実行結果の出力内容:
猫猫猫猫猫
今度は文字が5個になりました。2や'猫'といった値に応じて、挙動が変わっていますね。
このように、プログラムでは値に応じて振る舞いが変わります(数値の場合はこうなる、文字の場合はこうなる、といったように)。
また、値によってできることとできないことが異なります。
この数値や文字などの種類が、それぞれ「型」になります。Pythonでは、数値や文字などの他にも様々な型が存在します。
「振る舞いが違う色々な値の種類」と考えると少し分かりやすいかもしれません。
色々な型がありますが、次のセクション以降で少しずつ触れていきます。一度にたくさん覚えようとすると大変なので気楽に進めていただいて、忘れたときにはそこだけ復習するといった具合に進めてみてください。
焦らなくても、プログラムを書き続けてさえいれば自然と身についてきたり、覚えているものの数が増えていきます。
| 2, 5, 20...整数(int)の入門
整数の型はintとなります。英語だと整数がintegerなので、その略称としてPythonでは型の名前がintとなっています。
今まで出てきたPythonの基本計算でも既に色々使ってきましたね。
変数へ整数を設定するには、今まで触れてきた通り=の記号を使いつつ、右辺に整数の値を配置すれば設定できます。
my_age = 10
print(my_age)
コード実行結果の出力内容:
10
また、型の確認はtype()と書いて()の括弧の中に値を直接入れたり、変数を入れたりすることで確認ができます。
以下のようにコードを書く と、値はintですよ、ということを確認できます(もしくは、Jupyter上であればセルの末端であればprint部分を省略しても型の内容を確認できます)。
my_age = 10
print(type(my_age))
コード実行結果の出力内容:
<class 'int'>
class 'int'という形で表示されていますが、class部分については後々別のセクションで触れていきます。
このtype()での型の調べ方は、他の値でも使えます。
| 1.5, 0.05, 30.3...浮動小数点数(float)の入門
1.5や0.05といった、少数の値を含んだ数値はfloatという型で扱います。
特に、コンピューター・プログラミング関係では浮動小数点数という形で少数を扱います。
英語だとfloating point numberとなり、そこにfloatという型の名前が由来しています。
浮動小数点数と対になるもので固定小数点数というものもあります。
浮動小数点数に「動」という漢字がありますが、これは小数点の位置が動いても扱える、という意味合いを持ちます。0.01でも538.1500023といった値でも扱えます。
一方で、固定小数点数は決められた小数点の位置しか扱えません。1030.3123や0391.8812といった値になります。
浮動小数点数の方が、少数点部分が柔軟に扱える(扱える数値の範囲が広い)代わりに、固定小数点数の方が計算が速いという特徴がありますが、基本的に普通に触っている分にはほぼ浮動小数点で困ることはありません。
一応、Pythonでは固定小数点数も利用ができるのですが、基本的には一部の特殊なケース以外、ほぼほぼ浮動小数点数しか利用しません。そのため、小数を扱うときには浮動小数点数のfloatを使うと考えていていただいても問題ありません。
この辺りは小難しい話ですし、固定小数点数が必要になるケースは少ないと思うので、深くはこの本では触れません。
浮動小数点数を扱うには、半角の数字と半角のドット.の記号を使って表現します。
pi = 3.1415
print(pi)
コード実行結果の出力内容:
3.1415
普通に変数に設定する以外にも、最初は整数の型(int)だったものが、計算の途中で浮動小数点数(float)になっている、などのケースもあります。例えば、割り算を/=の記号を使ってしてみると、最初はintの型だったものがfloatになっていることが分かります。
money = 1000
print(type(money))
コード実行結果の出力内容:
<class 'int'>
上記のように、変数宣言の時点では整数(int)になっています。
money = 1000
money /= 6
print(type(money))
コード実行結果の出力内容:
<class 'float'>
割り算をしたら型が浮動小数点数(float)になりました。これは、割り算によって変数(money)の値が166.66666666666666といったように、小数が必要な値に変化したことによってPython側が自動で変換してくれています(割り切れる計算の場合でも、割り算をすると基本的に結果は浮動小数点数になります)。
'りんご', '猫', '晴れ'...文字列(str)の入門
日本語や英語などの文字はstrという型で扱います。
猫とかaといった単一の文字は英語でcharacterとなります。プログラミングではよくcharなどと短くした形で使われます。
ペルシャ猫やappleといった、複数の文字からなるものを、文字列と呼びます。文字列は英語でstringで、Pythonの文字を扱う型のstrはこの英語に由来します。
1文字のときも複数文字の場合も、両方とも同じstrの型で扱えます。
文字列を扱うには、'の記号(シングルクォーテーションと呼ばれます。英語だとsingle quotationとなります)で文字列を囲むか、"の記号(ダブルクォーテーションと呼ばれます。英語ではdouble quotation)で文字列を囲む必要があります。
例えば、'ペルシャ猫'といった形や、"ペルシャ猫"といったように'や"の記号を使って表現します。
シングルクォーテーションを使ったサンプル :
cat_name = 'ペルシャ猫'
print(cat_name)
コード実行結果の出力内容:
ペルシャ猫
ダブルクォーテーションを使ったサンプル :
cat_name = "ペルシャ猫"
print(cat_name)
コード実行結果の出力内容:
ペルシャ猫
シングルクォーテーションを使ってもダブルクォーテーションを使っても基本的な文字列の挙動は変わりません。
ただし、例えば文字列の中にシングルクォーテーションやダブルクォーテーションが含まれる場合には、含まれていない方のクォーテーションを使うとシンプルになります。
文字列内にシングルクォーテーションが含まれているので、ダブルクォーテーションを使っているサンプル :
string = "That's it."
print(string)
コード実行結果の出力内容:
That's it.
シングルクォーテーションを含んだ文字列に対してシングルクォーテーションを使うことも一応はできます。ただし、「エスケープ」という対応が必要になります。
エスケープは、\記号(環境によって、半角のバックスラッシュもしくは半角の円記号で表示されます)を使います。
文字列内でこのエスケープ用の\記号の後に設定された文字は、「特殊な挙動をしないただの文字」になります。
シングルクォーテーションやダブルクォーテーションはPythonでは文字を囲むための特殊な挙動をします。それがエスケープ用の記号を直前に置くことで、プログラム的に意味を持たないただの文字となります。
前述のシングルクォーテーションを含む文字列のサンプルで、エスケープをしながらシングルクォーテーションで囲むにはThat\'s it.といったように、シングルクォーテーションの直前に\記号を配置してください。
string = 'That\'s it.'
print(string)
コード実行結果の出力内容:
That's it.
また、仕事などで複数人でPythonのコードを書くようなケースでは、人によってシングルクォーテーションを主に使うのかダブルクォーテーションを主に使うのかがバラバラで、そのままだと各クォーテーションがごちゃまぜになってしまいます。
そういったことを避けるために、コードを扱う各プロジェクトで「基本的にはシングルクォーテーションをメインに使う」とか、逆に「基本的にはダブルクォーテーションをメインに使う」といったルールを決めることが多いです。
※前述のように、メインで使うのはシングルクォーテーションだけれども、文字列内にシングルクォーテーションが含まれているから例外的に一部たけダブルクォーテーションを使う、といったことは問題ありません。
こういったルールの集まりを、「コーディングルール」とか「コーディング規約」等と呼びます。
参考までに、PEP8という、Pythonのプログラム自体のコーディング規約にも、どちらをメインで使うのかを各々で決めてください、という記述があります(20年前くらいのドキュメントになります)。
Python では、単一引用符 ' で囲まれた文字列と、二重引用符 " で囲まれた文字列は同じです。この PEP では、どちらを推奨するかの立場は示しません。どちらを使うかのルールを決めて、守るようにして下さい。
必須ではありませんが、皆さんの好みや仕事で複数人での作業が必要になった場合は同僚の方と相談したりして、どちらをメインに使っていくのかを必要に応じて決めてください。
本書ではシングルクォーテーションをメインに使っていきます。
文字列の連結
数値の時は+の記号を使うと足し算となりました。文字列で+の記号を使うと、文字列同士の連結になります。
以下のサンプルでは、apple_nameという文字列の変数とorange_nameという文字列の変数を+の記号を使って連結して、最終的に1つの文字列の変数のconcatenated_strにしています。
apple_name = 'りんご'
orange_name = 'オレンジ'
concatenated_str = apple_name + orange_name
print(concatenated_str)
コード実行結果の出力内容:
りんごオレンジ
複数のクォーテーションによる文字列の連結
また、複数のクォーテーション区切りの文字列が連続していても1つの値(変数)になります。
fruit_name = 'りんご''オレンジ''メロン'
print(fruit_name)
コード実行結果の出力内容:
りんごオレンジメロン
もちろん、前述のサンプルのようにクォーテーションを複数使わなくても以下の1つの文字列にはなってくれます。
fruit_name = 'りんごオレンジメロン'
print(fruit_name)
コード実行結果の出力内容:
りんごオレンジメロン
では何故クォーテーションを複数分ける形にすると何が便利なのか?という点ですが、例えば長い文字列を扱うときに、見やすくするために改行を挟んだりすることができます(文字列自体には改行は含まれません)。
改行を挟む際には、コードの行末にエスケープ用の半角のバックスラッシュ(環境によっては半角の円の記号になります)を設定する必要があります。
text = '吾輩は猫である。名前はまだ無い。'\
'どこで生れたかとんと見当がつかぬ。'\
'何でも薄暗いじめじめした所でニャーニャー'\
'泣いていた事だけは記憶している。'\
'吾輩はここで始めて人間というものを見た。'
print(text)
コード実行結果の出力内容:
吾輩は猫である。名前はまだ無い。どこで生れたかとんと見当がつかぬ。何でも薄暗いじめじめした所でニャーニャー泣いていた事だけは記憶している。吾輩はここで始めて人間というものを見た。
このようにクォーテーションを複数使って改行を入れることで、ひたすら1行に詰め込まれていて横スクロールを頑張らないと読めないといったケースを避けることができ、便利な場合があります。
昨今では大分モニターの解像度も上がっていて横に長くなっていても問題ないケースもありますが、他の方がコードを書くときにエディタの画面を分割していて横幅が狭くなっているケースもありますし、あまり1行に詰め込みすぎるとあまり好ましくありません。
Python界隈では、Python自体のコーディング規約で半角で79文字以内と定められていますので、それに準じているプロジェクトやライブラリなどが多めです。そちらも必要に応じてご参照ください。
すべての行の長さを、最大79文字までに制限しましょう。
PEP: 8 Python コードのスタイルガイド
余談ですが、行数が多くて行末にエスケープの記号\を毎回記述するのが手間な場合は、()の括弧の中に各文字列を入れることで、行末のエスケープの記号を省略することができます。
text = (
'吾輩は猫である。名前はまだ無い。'
'どこで生れたかとんと見当がつかぬ。'
'何でも薄暗いじめじめした所でニャーニャー'
'泣いていた事だけは記憶している。'
'吾輩はここで始めて人間というものを見た。'
)
print(text)
コード実行結果の出力内容:
吾輩は猫である。名前はまだ無い。どこで生れたかとんと見当がつかぬ。何でも薄暗いじめじめした所でニャーニャー泣いていた事だけは記憶している。吾輩はここで始めて人間というものを見た。
文字の繰り返し
数値に対して*の記号を使うと掛け算ができました。文字もしくは文字列に対して*の記号と任意の整数を指定すると、その文字(もしくは文字列)を整数の数分繰り返した文字列を作ることができます。
print('りんご' * 5)
コード実行結果の出力内容:
りんごりんごりんごりんごりんご
複数行の文字列
特殊な文字列の表現方法となりますが、クォーテーションを3つ連続して記述すると改行などのそのまま含んだ文字列を定義できます。
少し前のセクションで触れた、クォーテーションを分割して文字列を分割したときのように、長い文字列を扱う時に便利です。
以下のように、文字列の開始と終了の部分にダブルクォーテーションを3つ書くことで使えます。
text = """吾輩は猫である。名前はまだ無い。
どこで生れたかとんと見当がつかぬ。
何でも薄暗いじめじめした所でニャーニャー泣いていた事だけは記憶している。"""
print(text)
コード実行結果の出力内容:
吾輩は猫である。名前はまだ無い。
どこで生れたかとんと見当がつかぬ。
何でも薄暗いじめじめした所でニャーニャー泣いていた事だけは記憶している。
後々の章で触れますが、この書き方はdocstringと呼ばれる、Pythonのコードに対する説明・ドキュメントを書くときに使われるため、後々の章では多く出てきます。また後で触れますが、頭の片隅に入れておいてください。
なお、ダブルクォーテーションではなくシングルクォーテーションでも同じように3つ連続して記述することで複数行の文字列を定義できます。
ただし、この書き方はPython自体のコーディング規則で「ダブルクォーテーションを使う」と書かれていることもあり、大半はダブルクォーテーションが使われています。
三重引用符 で文字列を囲むときは、PEP 257 での docstring に関するルールと一貫させるため、常に二重引用符 """ を使うようにします。
PEP: 8 Python コードのスタイルガイド
猫は好きですか?「はい」か「いいえ」の真偽値(bool)の入門
「はい」か「いいえ」といったような、2つの値だけを取る真偽値という型もPythonには存在します。型の名前はboolとなります。真偽値の英語がbooleanなので、その省略形としてboolとなっています。
真偽値の値には、TrueもしくはFalseという二つの値のみが利用できます。True(真)とFalse(偽)といったように、この2つの値は真偽値という名前の由来にもなっています。Trueが「はい」、Falseが「いいえ」といったように扱われます。
猫は好きですが?
- 「はい」であればTrue
- 「いいえ」であればFalse
といった具合です。
TrueとFalseの各真偽値の値を変数に設定したい場合には、そのままTrueもしくはFalseとプログラム上で書いて変数に格納します。例えばTrueを設定したい場合には以下のようなコードになります。
i_like_cats = True
逆にFalseを設定したい場合には以下のようなコードになります。
i_like_cats = False
今のところ、これらの真偽値を何に使うのだろう?という印象がするかもしれませんが、後々の章で条件分岐と呼ばれるプログラムの章で頻繁に使用します。条件分岐はたとえば「猫が好きであれば〇〇」といったような条件によってプログラムの挙動を変えるような制御のことを言います。
詳しくは後々触れていきます。現時点では真偽値という型があるということだけ頭に入れておいてください。
Pythonの生みの親の名前は?定数入門
Pythonの生みの親の方はなんという名前でしょうか?
答えは、Guido van Rossum(グイド・ヴァンロッサム)さんです。
このような、Pythonの生みの親 = Guido van Rossumさんという定義は過去も将来も変わったりはしません。
一方で、「東京の今の気温」といった値は刻一刻と変わり続けます。
前のセクションで、条件や時間経過などによって変わる値を変数と言う、ということを説明しました。「東京の今の気温」といった定義は変数が向いています。
反対に、「Pythonの生みの親」という基本的には変わらない定義は、変数ではなく「定数」と呼ばれるもので定義します。
「値が一定で変わらない」という意味も持ちます。英語だとconstantとなります。プログラム上では、よく省略形でconstなどと書かれたりします。
Pythonで定数を定義する時には、「大文字の英語」と「単語ごとにアンダースコアで区切る」形で表現します。
例えば、「猫の名前」という定数を定義したい場合にはCAT_NAMEといったように書きます。
CAT_NAME = 'ミケ'
他のプログラミング言語でも勿論定数の機能が用意されていることが大半です。それらでは、基本的に定数は1度設定したらプログラムを止めたりしない限り変更ができません(変えようとするとエラーになります)。
しかし、Pythonでは名前が大文字などを使う以外、機能的には変数と変わりません。基本的にはやりませんが、以下のように定数として定義した値に別の値を設定することもできてしまいます。
CAT_NAME = 'ミケ'
CAT_NAME = 'タマ'
print(CAT_NAME)
コード実行結果の出力内容:
タマ
そのため、Pythonの定数の定義としては「値が変えられないもの」というよりかは、「値を変えないもの」という方がしっくりきます。
値が変えられるのであれば、全部変数でいいのでは?という印象もするかもしれませんが、定数として定義することで、後で他の人がコードを読んだ時などに、CAT_NAMEといったように大文字で定義された値が出てきたら、「この値は変わらない(変えない)値なんだな」とすぐに理解することができます。定数として定義することでコードの説明として役立ちます。
なお、私は他のプログラミング言語を昔使っていてから、Pythonを初めて使い始めたのですが、その時にPythonの定数の「値を変えないもの」として使う仕様に結構驚いた記憶があります(他の方に聞いてみても、最初は違和感があったそうです)。
しかし、Pythonに慣れてきて、何年もずっとPythonを書き続けてきた限りでは、特にこの仕様で大きく問題になったりするケースは発生していません。
逆に、後々の章で触れるテストスクリプトなどを書くときなどに、この仕様による柔軟性が役立ったりすることは意外と経験しています。
余談ですが、Python3.8以降のバージョンであれば「値は変えられない」挙動をする機能を利用したりもできるようになっています。Python3.7以前のバージョンでも、ライブラリなどを使うことで「値は変えられない」定数の挙動を実現することは可能です。もし必要になった場合には、それらも検討してみてください。
順番を持った色々なデータのかたまり : リスト入門
10個のデータがあった時に、順番の情報を含めて1つにまとめておくとプログラミングで便利なことがあります。
たとえば、そのかたまりに対して一括でなんらかの処理をしたり、平均を出したり、値が低い順に並べ替えたり、コードをコピーしたりすることなく、1つのコードで1つ1つの値に対して処理をしたりと様々です。
そういった時にはPythonのリスト(list)と呼ばれる型のデータを使うと便利です。
リストを使うと任意の複数の値を格納して、ひとかたまりすることができます。

リストは、プログラミングの領域では配列とも呼ばれたりします(英語ではarray)。
厳密にはPythonではlistとarrayがそれぞれ別で存在するのですが、現時点ではリストの方を使うことが大半ので、リスト = 配列くらいに思っていただいても差支えありません。
格納できるものは、数値でも文字列でも、それ以外でも色々格納することができます。
リストの変数を作るには、[]の括弧を使います。中に値を入れて、複数の値の間に半角のコンマ,の記号を使って書きます。
例えば、1, 2, 3という3つの値を格納するリストを作りたい場合には以下のように書きます。
number_list = [1, 2, 3]
数値以外の値、例えば文字列なども格納できます。
string_list = ['ミケ', 'タマ', 'ポチ']
変数を使ってリストに値を格納することもできます。
cat_name = 'ミケ'
dog_name = 'ポチ'
varibale_list = [cat_name, dog_name]
print(varibale_list)
コード実行結果の出力内容:
['ミケ', 'ポチ']
作ったリストの変数には、[]の括弧を変数の後に付けて、その括弧の中に番号を指定するとリストの中の値にアクセスすることができます。
括弧の中に指定する番号は0からスタートします。リストの先頭の値であれば0、その次の値であれば1、さらにその次の値では2...といった具合です。1からスタートするわけではないので注意してください。
string_list = ['ミケ', 'タマ', 'ポチ']
print(string_list[0])
コード実行結果の出力内容:
ミケ
print(string_list[1])
コード実行結果の出力内容:
タマ
print(string_list[2])
コード実行結果の出力内容:
ポチ
この[]の中に指定する番号のことをインデックスと呼びます(英語だとindex)。
リストの件数を超えるインデックスを指定するとエラーになります。3件のデータのリストであれば2を超えるインデックスを指定するとエラーになります。インデックスは0からスタートするため、件数 - 1のインデックスまで指定することができます。
データの件数以上のインデックス番号を指定するとエラーになります。
string_list = ['ミケ', 'タマ', 'ポチ']
string_list[3]
IndexError Traceback (most recent call last)
<ipython-input-75-9c0019cfd088> in <module>
1 string_list = ['ミケ', 'タマ', 'ポチ']
----> 2 string_list[3]
IndexError: list index out of range
list index out of rangeというエラーメッセージになっています。「リストに指定されたインデックスが範囲外ですよ」といったような意味になります。3件のリストなので、0~2までしかインデックスが指定できないので、3を指定しているためにout of rangeとなっているわけです。
リストで最後から順番に値にアクセスするには?
前のセクションで、0, 1, 2...と順番にインデックスでリストの値にアクセスできることを確認しました。
では、リストの最後から順番にアクセスしたい時にはどうすればいいのでしょうか?
やり方はいくつかありますが、手段の一つとしてマイナスのインデックスを使うという方法があります。
インデックスに-1を指定すると、「リストの最後の値」にアクセスすることができます。
また、-2を指定すると「最後から2番目の値」、-3とすると「最後から3番目の値」にアクセスすることができます。
string_list = ['ミケ', 'タマ', 'ポチ']
print(string_list[-1])
コード実行結果の出力内容:
ポチ
print(string_list[-2])
コード実行結果の出力内容:
タマ
print(string_list[-3])
コード実行結果の出力内容:
ミケ
通常の正のインデックス(0, 1, 2など)を指定していたときと同様、インデックスの範囲を超えてしまうと同じエラーになります。
リストの値が3つだけなので、-1, -2, -3まではエラーなく使えますが、-4を指定するとエラーになってしまいます。
string_list[-4]
IndexError Traceback (most recent call last)
<ipython-input-85-1ab74fd28c19> in <module>
----> 1 string_list[-4]
IndexError: list index out of range
リストで特定の範囲の値にアクセスする
今まではリストで特定の1つのインデックスの値にアクセスしてきました。
では、「2番目以降」とか「3番目まで」とか、「2番目~3番目の範囲」といった、リストで特定の範囲の部分を抽出したい場合はどうすればいいのでしょうか。
こういった場合には、インデックスを指定する際に、半角のコロンの:の記号を使うことで対応することができます。いくつかパターンがあるので、一つ一つ触れていきます。
なお、この特定の範囲だけをリストか抽出することをスライス(英語でslice)と呼びます。
〇未満のインデックスという条件で抽出する
〇未満のインデックスという条件、たとえばインデックスが2未満の部分をリストから抽出したい場合には、コロンの記号を使って[:2]といったように書くことで実現できます。
[:2]といったように書いた場合、抽出されるのは0と1のインデックスの2件です。
以下のサンプルコードで確認してみると、先頭のインデックス(0)のミケとその次のインデックス(1)のタマの2つが抽出されていることが分かります。
string_list = ['ミケ', 'タマ', 'ポチ', 'ピーター']
print(string_list[:2])
コード実行結果の出力内容:
['ミケ', 'タマ']
〇以上のインデックスという条件で抽出する
〇以上のインデックスという条件、たとえばインデックスが2以上の部分をリストから抽出したい場合には、コロンの記号を使って[2:]といったように書くことで実現できます。未満の条件の時と比べて、数字とコロンの記号の位置が変わっていることに注意してください。
以下のサンプルコードで確認してみると、3番目の位置(2のインデックス)のポチと4番目の位置(3のインデックス)のピーターの2つが抽出されていることが確認できます。
string_list = ['ミケ', 'タマ', 'ポチ', 'ピーター']
print(string_list[2:])
コード実行結果の出力内容:
['ポチ', 'ピーター']
〇以上×以下のインデックスという条件で抽出する
〇以上×未満のインデックスという条件、たとえばインデックスが1以上3未満という範囲でリストから抽出したい場合には、コロンの記号を使って[1:3]といったように書きます。コロンの両側に数値が必要になります。
以下のサンプルでは、先頭と末尾の要素は含まれずに、真ん中に位置しているタマとポチという部分が抽出されていることが確認できます。
string_list = ['ミケ', 'タマ', 'ポチ', 'ピーター']
print(string_list[1:3])
コード実行結果の出力内容:
['タマ', 'ポチ']
リストを作る時に改行を入れる
リストの変数などを作る時に、設定する値が多くなるとひたすら横に長くなってしまいます。
前のセクションで触れたように、Pythonのコーディング規約では1行に半角で79文字までに納めるという規則もあり、あまり横に長くなりすぎると横スクロールが必要になって読みづらくなったりします。
そのため、リストの値が多くなってきたら値ごとなどで改行を入れると横スクロールなどが不要になって読みやすくなります。例えば以下のように書きます。
string_list = [
'ミケ',
'タマ',
'ポチ',
'ピーター',
'きなこ',
'マロン',
]
最後の値の'マロン',という行に注目してみます。値の後に半角コンマの,の記号が入っていますが、このような最後の値の後のコンマはPythonではあっても無くてもどちらでもエラーにはなりません。
以下のように最後の値の後のコンマを省いても同じ挙動をします('マロン'という値の部分で、半角のコンマが省略されている点に注目してください)。
string_list = [
'ミケ',
'きなこ',
'マロン'
]
最後の値の後に半角のコンマがあっても無くてもプログラム上は問題は無いのですが、リストに将来値を追加する時などに、最後に値を追加すると直前の値は最後の行では無くなるので、コンマの追加が必要になります。
例えば以下のように文字列のリストで最後に値を追加した際に、コンマを追加し忘れてしまったとします。そうするとどうなるでしょう?
string_list = [
'ミケ',
'きなこ',
'マロン'
'ポチ'
]
print(string_list)
コード実行結果の出力内容:
['ミケ', 'きなこ', 'マロンポチ']
printで出力される内容が、'マロン'と'ポチ'が一緒になってしまいました。一体何が起きているのでしょう?
少し前のセクションで触れた、文字列の連結のものを思い出してみてください。
クォーテーションを分割して、連続して文字列を定義することで、Python上では1つの文字列となり、改行などが入れれて長い文字列で便利といったことを説明しました。
また、()の括弧を使うと、行の末尾でエスケープ用の\が無くても改行ができるとも説明しました。
そのような文字列の挙動が、リストを作るときにコンマが足りていないことによって発生してしまっています。つまり、コンマが無いことによってPythonが「これは1つの文字列だ」と判断してしまって、'マロン'と'ポチ'を連結してしまっているわけです。
こういったケースでは、エラーなども出ずに気づきにくいので注意が必要です。そのため、個人的にはリストなどで改行を入れて扱う場合には、「値の行の最後に必ずコンマを入れる」という書き方をすることが多いです。少し前で触れた以下のサンプルコードのような感じですね。
string_list = [
'ミケ',
'タマ',
'ポチ',
'ピーター',
'きなこ',
'マロン',
]
このように最後の値の後にもコンマを入れる形で、全ての値に対して同じように書くことでコンマの追加漏れなどによるうっかりミスを避けることができます。
補足ですが、文字列など一部を除いて、例えば整数や変数などをリストに使った場合には以下のようにエラーになるので、こちらは比較的コンマ漏れなどには気づきやすくなっています。
int_list = [
1,
2,
3
4
]
File "<ipython-input-105-6d665419c4f6>", line 5
4
^
SyntaxError: invalid syntax
以下のようにリストの4の部分がおかしいとPythonがエラーメッセージが教えてくれています。
4
^
エラーメッセージで示されている箇所の前後でなんらかおかしいところがある、ということなので、こういったエラーが出た際には前後のコードを確認してみてください(今回は「4の前にコンマなどが無いとおかしい」というケースになります)。
変数などを使ったリストでも同様です。
one_var = 1
two_var = 2
three_var = 3
variable_list = [
one_var,
two_var
three_var
]
File "<ipython-input-111-997c24591ae1>", line 8
three_var
^
SyntaxError: invalid syntax
もう一点補足となりますが、必ずしも値ごとに改行をしなくても元々の目的であった1行が長くなりすぎるという点は解決できます。例えば、以下のように1行に値を数件程度、あまり長くならない程度に任意の件数設定するのは問題ありません。
string_list = [
'ミケ', 'タマ', 'ポチ', 'ピーター',
'きなこ', 'マロン',
]
名前付きのデータの集まり : 辞書入門
東京都に住んでいる方の中で、特定の住所に住んでいる方の情報が必要になった、みたいなケースが発生したとしましょう。
このセクションを書いている時点では、東京都の人口は1000万人を超えています。これをリストのデータを使って、1件1件探す・・・みたいなことを人力でするととても大変です。コンピューターを使っても、工夫しないと時間がかかってしまいます。
一方で、〇〇の住所はAさん、××の住所はBさん、△△の住所はCさん・・・といったデータがあるとどうでしょう?
住所さえ分かればそこに住んでいる方が一発で分かるので、値を探す必要が無くなります。すぐに処理が終わりそうですね。
Pythonの辞書という機能は、この「住所からそこの住人の情報を得る」みたいなプログラムを書くときに便利です。英語ではそのままdictionaryです。
名前の由来になっている辞書で、英語の紙の辞書を考えてみましょう。もう長いこと、スマホや電子辞書などでほとんど使う機会が無くなっているので、馴染みがあまり無い方も多いかもしれませんが・・・。
紙の辞書では、例えばcatという単語を調べるとき、「C」のページ部分を開いて単語を探していく・・・といったように扱います。
Pythonのプログラミングでも同じように、辞書の機能では「なんらかの文字列」を参照して「該当する値」にアクセスするような挙動をします。
プログラムで書くときには、半角の{と}の括弧を使います。この記号は日本語だと波括弧、英語だとcurly bracketなどと呼ばれます。
また、半角のコロンの:記号で区切り、左側にキー(英語でkey)と呼ばれる値、右側に該当する値(英語でvalue)を設定して、{'key': value}といったように書きます。コロンの左側にはスペースを入れず、右側には半角のスペースを入れるのが一般的です。
左側のキーは、前の説明で言うと「住所」や「辞書のC」といった部分が該当します。右側の値は、住人の情報やcatという英単語の情報、といった具合です。
辞書のキー(左側)に日本語の国名、値(右側)に英語の国名を格納する辞書をサンプルとして作ってみます。コードでは以下のように書きます。
country_name_dict = {'日本': 'Japan'}
1つの辞書に、複数のキーと値を設定することもできます。先ほどの辞書に、日本だけでなくアメリカのキーと値を追加してみます。追加するには、半角のコンマの,の記号を値の後に置いて区切り、別のキーと値を配置します。
country_name_dict = {'日本': 'Japan', 'アメリカ': 'United States of America'}
辞書に格納されているデータにアクセスするには、['キー名']といったように変数の後に記述します。
たとえば、先ほど作った辞書で日本というキーの値にアクセスしたい場合には以下のようにcountry_name_dict['日本']と書きます。
print(country_name_dict['日本'])
コード実行結果の出力内容:
Japan
日本というキーにアクセスすると、該当する値のJapanが取得できていることが分かります。
他のキーでも同様です。アメリカのキーにアクセスするには以下のようになります。
print(country_name_dict['アメリカ'])
コード実行結果の出力内容:
United States of America
辞書のキーには以下のコードのように変数や定数などを使うことができます。
NAME_KEY = 'name'
AGE_KEY = 'age'
cat_info_dict = {NAME_KEY: 'タマ', AGE_KEY: 7}
print(cat_info_dict)
コード実行結果の出力内容:
{'name': 'タマ', 'age': 7}
辞書の値の方にも、変数や定数を指定することができます。
cat_name = 'タマ'
cat_age = 7
cat_info_dict = {'name': cat_name, 'age': cat_age}
print(cat_info_dict)
コード実行結果の出力内容:
{'name': 'タマ', 'age': 7}
また、リストのセクションで触れたのと同じように、値が多くなると1行に全部書くと横にとても長くなってしまって読みづらくなるので、キーと値の1セットごとに改行を入れることもできます。
cat_info_dict = {
'name': 'タマ',
'age': 7,
'location': '東京',
'favourite': 'またたび',
}
Pythonとインデントの話
リストや辞書のセクションで、説明を入れていませんでしたが改行を入れた時に以下のように値の前に半角のスペースを入れていました。
int_list = [
1,
2,
3,
4,
]
以下のように、Pythonのプログラム自体はスペースを入れなくても動きます。
int_list = [
1,
2,
3,
4,
]
スペースを入れなくてもプログラムは動くのに、何故半角のスペースを入れているのでしょう?
理由の1つとして、「コードが読みやすくなる」という点が上げられます。
プログラムなどでは、よくコードの構造の階層を表すためにスペースなどが使われます。
コードの構造の階層と言ってもいまいちピンと来ないかもしれないため、フォルダで例えてみましょう。
「フォルダ1」というフォルダの中に「フォルダ2」というフォルダが入っていて、さらにそのフォルダ2の中に「フォルダ3」というフォルダが格納されているとします。
Windowsなどでフォルダを開いたときのエクスプローラーで見てみると、場所の表示がフォルダ1 > フォルダ2 > フォルダ3といったように表示され、各フォルダの階層が一目で分かるようになっています。
もしくは、エクスプローラーなどの左のメニューで、以下のように階層が表示されるのも馴染みがあるかもしれません。
フォルダ1
└ フォルダ2
└ フォルダ3
どちらの表示でも、一目で階層がどうなっているのかが分かり、且つ右にいく程階層が深くなっているというのは分かります。
リストや辞書などのインデントも同じように階層的に考えることができます。
例として以下のコードで考えてみます。
int_list = [
1,
2,
3,
4,
]
フォルダ的に考えると、int_listという変数 > int_list内の値といった形で表現できます。
このようにプログラムでインデントを使うことで、右に行くほど階層の深いコードを表すことができ、ぱっと見でどういったプログラムになっているのかが把握しやすくなります。
こういった「コードの把握のしやすさ」や「コードの読みやすさ」のことを「可読性」などと呼んだりしますが、コードを書く上ではこの可読性がとても大切になってきます。特に仕事などでは複数人で一緒にコードを書いたりするため、読みにくいコードを書いてしまうと他の人に迷惑をかけてしまいます。また、自分で何か月も後に読み返すときなども読みづらいコードになっていると苦労します。
インデントをうまく使っていくことで読みやすいコードを書くことに役立ちますので、最初は些細なことに思えるかもしれませんが、重要なことなんだな、と心の片隅に置いておいてください。
なお、リストや辞書の部分では前述のコードのようにインデントを省いても動きます。一方で、Pythonではインデントが意味を持つケースが多くあります。そういったケースではインデントを省いたり間違えたりするとエラーになったり変な挙動になったりします。その辺りのことは後々の章で詳しく説明します。
Pythonのインデントの基本
一般的に、インデントは半角スペース2個、半角スペース4個、Tabの3つがよく使われます。どれが使われるかは、プログラム言語やプロジェクトのルールによって様々です。
しかしPythonでは、以下のようにPython自体のコーディング規約で「半角スペース4個」と定められており、ほとんどのPythonのプロジェクトでも半角のスペース4個が使われます。そのため、特に理由がなければ半角のスペース4個でインデントを表現しましょう。
1レベルインデントするごとに、スペースを4つ使いましょう。
...
スペースが好ましいインデントの方法です。
タブを使うのは、既にタブでインデントされているコードと一貫性を保つためだけです。
Python 3 では、インデントにタブとスペースを混ぜることを禁止しています。
Python コードのスタイルガイド
Jupyterなどでも、デフォルトではTabキーを押した時に挿入されるインデントは半角スペース4個になっていますので、大体のケースではTabキーを押しておけば問題はありません。Jupyter以外のエディタを使うときなどには設定が半角スペース4個以外になっていないか注意してください。
半角スペース4個以外になるケースもあります。
基本的にはインデントは半角スペース4個で設定します。しかし、「読みやすさのために上の要素と位置を合わせる」ために4個以上のインデントを入れるケースがあります。
例えば、以下のようなコードのケースが対象となります。本書をお読みの端末のフォント次第でスペースがずれてしまったりする可能性があるので、画像で表示しています。
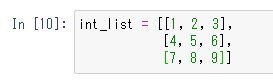
2重のリスト(リストの中にリストが入っている)構成になりますが、[1, 2, 3]の上の方に位置しているリストと、その下に続いている[4, 5, 6]や[7, 8, 9]のリストの位置を合わせています。インデントはスペース4つではなく、多くのスペースを使用しています。
何故このようになっているのでしょうか?疑問の解決のために、前のセクションで触れたフォルダ階層の例を思い出してみましょう。
ルールとしては、右にいくほど階層が深くなる、というものです。プログラムであればスペースのインデントが増えるほど構造が深い階層のものになっていきます。
先ほどの画像と異なり、上([1, 2, 3])のリストと位置を合わせていない以下のコードを考えてみます。
int_list = [[1, 2, 3],
[4, 5, 6],
[7, 8, 9],
]
プログラムでその階層のルール(右にいく程階層が深いというルール)に従うと、[1, 2, 3]もその下の[4, 5, 6]といった値も、int_listという変数 -> その中のリスト -> さらにその中に格納されたリストという階層になっているので、両方同じインデントじゃないとおかしくなります。
しかし上記のコードでは、[1, 2, 3]のリストが[4, 5, 6]や[7, 8, 9]といったリスト部分よりも右に来ています。プログラム上の階層としては同じ位置にある値なのに、このようにインデントの位置がずれているのは好ましくありません(誤解の元になってしまいます)。
そのため、こういったケースでは4つのスペースによるインデントではなく「上の要素に位置を合わせる」形のインデントが設定される形になります。
このようなインデントにするというルールは、Python自体のコーディング規約でも以下のように定められています。
行を継続する場合は、折り返された要素を縦に揃えるようにすべきです。
Python コードのスタイルガイド
また、Jupyterでもそちらのルールに合わせるようにインデントが入るようになっています。
例えばJupyter上で以下のようなコードの2の直前にカーソルを合わせてEnterキーを押して改行を入れてみてください。
int_list = [1, 2]
以下の画像のように2が1と同じ位置になるように、インデントが自動で設定されると思います。
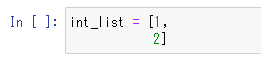
Python自体のコーディング規約でも定められていますし、Jupyterなどのライブラリやツールなどの挙動もそちらに合うようにされています。そのため特に理由がなければこれらのインデントのルールに合わせるようにしましょう。
先ほどのケースでも4つのインデントでコードを書きたいときは?
先ほどのセクションで触れた上記のコードに関して、もし4つのインデントでコードを書きたい場合にはどうすればいいのでしょうか?
答えは、「合わせるべき上の要素も改行などを入れて普通のインデントの位置にする」という書き方です。
以下のコードのように、[1, 2, 3]のリスト部分の前に改行を入れて、そこにスペース4つのインデントを設定すれば、[1, 2, 3]や[4, 5, 6]などの各リストのインデントの位置を合わせつつ、4つのスペースによるインデントを設定することができます。
int_list = [
[1, 2, 3],
[4, 5, 6],
[7, 8, 9],
]
リストに似ているけど、中身が変えられない : タプル入門
リストと同じように値を順番に格納し、値のインデックスなどによる参照ができる型でタプルというものがあります(英語でtupleとなります)。
タプルは半角の(と)の括弧を使うことで作成することができます。
tuple_value = (10, 15, 18)
print(tuple_value)
コード実行結果の出力内容:
(10, 15, 18)
値の参照はリストのようにインデックスで[1]といったような括弧と番号を指定することで対応することができます。
tuple_value = (10, 15, 18)
print(tuple_value[1])
コード実行結果の出力内容:
15
リストと比べて何が違うんだ?という感じですが、タプルは格納する値を変更することができないという特徴があります。
例えばリストであれば,以下のように設定した値を途中で変更することができます(コードでは0~2までのインデックスで3つの値を格納したリストを作り、その後に真ん中の1のインデックスの値を16に変更しています)。
age_list = [10, 15, 18]
age_list[1] = 16
print(age_list)
コード実行結果の出力内容:
[10, 16, 18]
一方でタプルでは前述のコードのように値を変更することができません。
以下のように特定のインデックスに値を設定しようとするとエラーになります。
tuple_value = (10, 15, 18)
tuple_value[1] = 16
TypeError: 'tuple' object does not support item assignment
タプル(tuple)は要素の割り当て(assignment)をサポートしていません、といったようなエラーメッセージになります。
もう一つのタプルの特徴として、「(と)の括弧は省略ができる」という点があります。つまりコンマだけでタプルを作ることができます。
以下のコードのように、10, 20と括弧を省略した形でコードを書いてもtype()で確認できる型はタプル(tuple)になっていることが確認できます。
tuple_value = 10, 20
print(tuple_value)
print(type(tuple_value))
コード実行結果の出力内容:
(10, 20)
<class 'tuple'>
さらに加えて、タプルを使って複数の変数に同時に値を割り振ったりすることもできます(リストでも同様のことはできます)。
以下のコードではイコールの記号の右側にタプルの値を設定し、左側には2つの変数(value_1とvalue_2)に対して値を設定しています。内容を出力してみると、それぞれの変数にタプルに設定されていた値(100と200)が反映されていることが確認できます。
tuple_value = (100, 200)
value_1, value_2 = tuple_value
print(value_1)
print(value_2)
コード実行結果の出力内容:
100
200
リストと比べてどういった時にタプルは必要になるのかといった点ですが、基本的には普段使うのはほぼほぼリストで問題はありません。ただ、コンマのみでタプルを作れる点とPythonでコンマを使った書き方は多用するため、意識しなくても自然とタプルを使うケースが結構発生します。
例えば後々の章で触れる関数の返却値と呼ばれるもので、複数の返却値を設定する場合にはコンマを使うため内容はタプルになっていたりします。同様に後々出てくる引数と呼ばれるものでもタプルが絡んできたりします。
その他にも辞書などには以下のコードのようにキーに複数の値を設定できますが、その際にはコンマを指定しているためキーにタプルが使用されていることになります。
data_dict = {}
data_dict['apple', 10] = 100
リストと比べると影が薄くなりがちなタプルですが、このようにPythonでコードを書いていると自然とタプルを利用しているケースがたくさんあります。目立たない存在ですが縁の下の力持ちのような型になります。
本章の演習問題 その1
[1]. 以下のようなコードを書いたところ、エラーになってしまいました。なにが問題なのでしょう?
1 + 1
File "<ipython-input-120-40ba61a5ceee>", line 1
1 + 1
^
SyntaxError: invalid character in identifier
[2]. Pythonで5と10の足し算を計算してみて、結果が15になるコードを書いてみてください。
[3]. Pythonで10から5を引く(引き算の)計算をしてみて、結果が5になるコードを書いてみてください。
[4]. Pythonで5の4倍の掛け算を計算してみて、結果が20になるコードを書いてみてください。
[5]. Pythonで10を5で割る計算をしてみて、結果が2になるコードを書いてみてください。
[6]. Pythonで10を4で割った時を余りを計算してみて、結果が2になるコードを書いてみてください。
[7]. Pythonで2の3乗を計算してみて、結果が8になるコードを書いてみてください。
※答案例は次のページにあります。
演習問題その1の答案例
[1]. プラスの記号に全角記号(+)が使われています。Pythonで必要な各記号は半角の記号(プラスであれば+)が必要です。
記号以外にも、スペースなども全角が入っているとエラーになったりします。注意してください。
[2]. 足し算では半角のプラスの+の記号を使います。
5 + 10
コード実行結果の出力内容:
15
[3]. 引き算では半角のマイナスの-の記号を使います。
10 - 5
コード実行結果の出力内容:
5
[4]. 掛け算では半角のアスタリスクの*の記号を使います。
5 * 4
コード実行結果の出力内容:
20
[5]. 割り算では半角のスラッシュの/の記号を使います。
10 / 5
コード実行結果の出力内容:
2.0
[6]. 余り(剰余)を求めるには半角のパーセントの%の記号を使います。
10 % 4
コード実行結果の出力内容:
2
[7]. 累乗を計算するには、半角のアスタリスクの*の記号を二つ連続して記述します。
2 ** 3
コード実行結果の出力内容:
8
本章の演習問題 その2
[1]. 値は7で、「猫の年齢」を示す変数を作ってみましょう。
[2]. 作った変数の内容を表示してみましょう。
[3]. 数値の変数に対して、現在の変数の値に対して足し算・引き算・掛け算・割り算をしてみましょう。足し算などで設定する数値はなんでも構いません。
※答案例は次のページにあります。
演習問題その2の答案例
[1]. 変数は半角英数字(ただし、先頭に数字は使えません)と一部記号が設定できます。単語間は半角のアンダースコアの_の記号を使って作ります。変数名は以下ではcat_ageとしましたが、他のものでも意味が伝わりやすい変数名であれば問題ありません。
cat_age = 7
[2]. 変数の内容を確認するには、print(変数)といったように書きます。括弧などは全て半角です。もしくは、Jupyterなどであればセル内で変数のみを記述したり、セルの末端であればprintの記述を省略することもできます。
cat_age = 7
print(cat_age)
コード実行結果の出力内容:
7
[3]. 現在の値に対する計算を行うには、足し算であれば+=、引き算であれば-=、掛け算であれば*=、割り算であれば/=を使います。
足し算の例 :
cat_age = 7
cat_age += 2
print(cat_age)
コード実行結果の出力内容:
9
引き算の例 :
cat_age = 7
cat_age -= 4
print(cat_age)
コード実行結果の出力内容:
3
掛け算の例 :
cat_age = 7
cat_age *= 3
print(cat_age)
コード実行結果の出力内容:
21
割り算の例 :
price = 300
price /= 3
print(price)
コード実行結果の出力内容:
100.0
※それぞれ以下のように、記述は長くなりますが変数を2回書く形でも間違いではありません。
cat_age = 7
cat_age = cat_age + 2
print(cat_age)
コード実行結果の出力内容:
9
本章の演習問題 その3
[1]. 小数を含んだ変数を作ってみてください。値はなんでも構いません。
[2]. 文字列の変数を作ってみてください。値はなんでも構いません。
[3]. 二つの文字列の変数を作って、それぞれの文字列を連結して1つの変数を作ってみてください。
[4]. 以下の文章を、横に長くなりすぎないようにしつつ文字列の変数に設定してみてください。
どこで生れたかとんと見当がつかぬ。何でも薄暗いじめじめした所でニャーニャー泣いていた事だけは記憶している。吾輩はここで始めて人間というものを見た。しかもあとで聞くとそれは書生という人間中で一番獰悪な種族であったそうだ。
[5]. 猫という文字を10回繰り返した変数を作ってみてください。ただし、直接10回繰り返した文字列を指定する(例 : 猫猫猫...)以外の方法で対応してください。
※答案例は次のページにあります。
演習問題その3の答案例
[1]. 小数を含んだ値(浮動小数点数 : float)を作るには、半角のドットの記号.を使います。
tax = 1.1
[2]. 文字列の変数を作るには、シングルクォーテーションの記号'もしくはダブルクォーテーションの記号"を使って文字列を囲みます。
シングルクォーテーションを使う例 :
cat_name = 'タマ'
ダブルクォーテーションを使う例 :
cat_name = "タマ"
[3]. 文字列の変数同士を連結するには、足し算の時にも使った半角のプラスの記号+を使います。
cat_name = 'タマ'
dog_name = 'ポチ'
concatenated_str = cat_name + dog_name
print(concatenated_str)
コード実行結果の出力内容:
タマポチ
[4]. いくつかやり方があります。1つ目として、行末にエスケープのための半角のバックスラッシュ(円記号)の\を設定し、クォーテーションを分ける方法があります。
long_str = 'どこで生れたかとんと見当がつかぬ。'\
'何でも薄暗いじめじめした所でニャーニャー'\
'泣いていた事だけは記憶している。'\
'吾輩はここで始めて人間というものを見た。'\
'しかもあとで聞くとそれは書生という人間中で'\
'一番獰悪な種族であったそうだ。'
2つ目として、()の括弧を使い、エスケープの記号を省略して書く方法です。
long_str = (
'どこで生れたかとんと見当がつかぬ。'
'何でも薄暗いじめじめした所でニャーニャー'
'泣いていた事だけは記憶している。'
'吾輩はここで始めて人間というものを見た。'
'しかもあとで聞くとそれは書生という人間中で'
'一番獰悪な種族であったそうだ。'
)
※他にも複数の方法が存在します。同じ結果を実現できるのであれば、それらの方法でも問題ありません。
[5]. 掛け算のときに使った半角のアスタリスクの記号*を文字列などに使うと、その文字列の繰り返しが表現できます。
cat_str = '猫' * 10
print(cat_str)
コード実行結果の出力内容:
猫猫猫猫猫猫猫猫猫猫
本章の演習問題 その4
[1]. 定数を、定数名の一般的なルールに従って作ってみてください。値や定数名は好きな値で問題ありません。
[2]. 数値を10個格納したリストの変数を作ってみてください。数値はなんでも構いません。
[3]. [2]で作ったリストから、リストの2番目の値を表示してみてください。
[4]. [2]で作ったリストから、リストの最後の値を表示してみてください。
[5]. [2]で作ったリストから、リストで2番目~3番目の値のみを抽出してみてください(スライスを使ってください)。
[6]. 猫の名前と猫の歳の値を格納する辞書を作ってみてください。
[7]. [6]で作った辞書の、猫の歳の値を表示してみてください。
演習問題その4の答案例
[1]. 定数名は、半角の英数字で、単語間を半角のアンダースコアの_の記号で繋ぐ形で定義します。定数名の先頭には数字は利用できません。
CAT_NAME = 'タマ'
[2]. リストを作るには、[と]の括弧の記号を使います。値の間には半角のコンマを設定します。
ages = [4, 6, 1, 3, 9, 7, 4, 3, 8, 0]
[3]. 2番目の値にアクセスするには、[1]といったように括弧内に数字(インデックス)を入れてアクセスします。インデックスは0からスタートするので、「2番目の値」にアクセスする場合には[2]ではなく[1]となります。
ages = [4, 6, 1, 3, 9, 7, 4, 3, 8, 0]
print(ages[1])
コード実行結果の出力内容:
6
[4]. リストの最後の値にアクセスするにはインデックスに-1を指定します。
ages = [4, 6, 1, 3, 9, 7, 4, 3, 8, 0]
print(ages[-1])
コード実行結果の出力内容:
0
[5]. リスト内で特定のインデックス範囲の値を抽出するにはスライスという、半角のコロン:と数値を使います。コロンの左側の数字は「〇のインデックス以降」を表し、コロンの右側の数字は「×のインデックス未満」を表します。問題の「2番目~3番目」の値が必要な場合には、インデックスは0からスタートするので、「1のインデックス以降」~「3のインデックス未満」として[1:3]という指定が必要になります。
以下のサンプルでは、2番目の6と3番目の1という値が抽出できています。
ages = [4, 6, 1, 3, 9, 7, 4, 3, 8, 0]
print(ages[1:3])
コード実行結果の出力内容:
[6, 1]
[6]. 辞書を作るには半角の{と}の括弧を使います。左側にキー(名前)、間に半角のコロン:、右側に値を設定します。複数のキーと値を設定するには、値の後に半角のコロンの,の記号が必要になります。キーと値のセットごとに改行を入れたりすると、見やすくなったり1行にひたすら長くなってしまったりを避けられます。
cat_info_dict = {
'cat_name': 'タマ',
'cat_age': 10,
}
[7]. 辞書内の特定の値にアクセスするには、[キー名]といったように括弧と文字列や数値など(数値や文字列の変数でも可)を指定します。問題では猫の歳の値にアクセスしたいので、['cat_age']という形で値にアクセスしています。
cat_info_dict = {
'cat_name': 'タマ',
'cat_age': 10,
}
print(cat_info_dict['cat_age'])
コード実行結果の出力内容:
10
本章の演習問題 その5
[1]. 以下の辞書を作るコードはエラーになります。どこがいけないのでしょう?
cat_info_dict = {
'cat_name': 'タマ'
'cat_age': 10
}
エラー内容 :
File "<ipython-input-1-b77443bd7b07>", line 3
'cat_age': 10
^
SyntaxError: invalid syntax
[2]. 同様に、以下の辞書を作るコードもエラーになります。どこがいけないのでしょう?
dog_info_dict = {
dog_name: 'ポチ',
dog_age: 7,
}
エラー内容 :
NameError Traceback (most recent call last)
<ipython-input-2-e524f90796d3> in <module>
1 dog_info_dict = {
----> 2 dog_name: 'ポチ',
3 dog_age: 7,
4 }
NameError: name 'dog_name' is not defined
[3]. 以下の文字列を作るコードでもエラーとなります。どこがいけないのでしょう?
text = 'どこで生れたかとんと見当がつかぬ。'
'何でも薄暗いじめじめした所でニャーニャー'
'泣いていた事だけは記憶している。'
File "<ipython-input-3-aa4cdfafbfa7>", line 2
'何でも薄暗いじめじめした所でニャーニャー'
^
IndentationError: unexpected indent
演習問題その5の答案例
[1]. 複数のキーと値のセットを持つ辞書になっていますが、それらの間にコンマがありません。以下のように、キーと値のセットの間('タマ'部分の直後)に半角のコンマを入れることで解決することができます。
cat_info_dict = {
'cat_name': 'タマ',
'cat_age': 10
}
最後の値の後(今回の例では10の後)にコンマを入れるかどうかは任意です。入れ忘れないように、毎回入れるようにするというのも好ましい書き方になります。
[2]. 辞書のキーの部分(今回の例ではdog_nameやdog_ageの部分)には、文字列や数値などを指定する必要があります。文字列で指定するには半角のクォーテーションで囲む必要があります('や"などの記号)。
クォーテーションで囲んでいないと、Pythonが対象のキー部分が変数だと認識してしまいます。一方で、dog_nameなどの変数は今回は定義していない(作っていない)ので、「'dog_name'という変数が定義されていませんよ」というエラーメッセージとしてNameError: name 'dog_name' is not definedという内容が表示されています。
クォーテーションで囲んでエラーが出ないように書くと以下のようになります。
dog_info_dict = {
'dog_name': 'ポチ',
'dog_age': 7,
}
また、変数が事前に定義されていれば、辞書のキーに変数を使うことも問題ありません。
key = 'dog_name'
dog_info_dict = {
key: 'ポチ',
}
print(dog_info_dict)
[3]. 文字列でクォーテーションを分けて改行を入れたい場合には、行末にエスケープの記号の半角のバックスラッシュの\が必要です。以下のように書くとエラーが無くなります。
text = 'どこで生れたかとんと見当がつかぬ。'\
'何でも薄暗いじめじめした所でニャーニャー'\
'泣いていた事だけは記憶している。'
もしくは、以下のように(と)の括弧で囲うことで行末のエスケープの記号を省略することもできます。どちらでも問題はなく挙動は変わりません。
text = (
'どこで生れたかとんと見当がつかぬ。'
'何でも薄暗いじめじめした所でニャーニャー'
'泣いていた事だけは記憶している。'
)
本章の演習問題 その6
[1]. 以下のコードはPythonのコーディング規約上好ましくない点が含まれています。どういった点でしょうか?
dog_info_dict = {
'name': 'ポチ',
}
[2]. 以下のコードも同様にPythonのコーディング規約上好ましくない点が含まれています。どういった点でしょうか?
dog_info_dict = {'name': 'ポチ',
'age': 100,
}
演習問題その6の答案例
[1]. 辞書のキーと値の部分('name': 'ポチ',)の前にインデントが入っていません。フォルダ階層の表示のように、dog_info_dictという辞書の変数 -> その中に入っているキーと値というプログラムの階層を表すために、以下のように半角の4つのスペースでインデントを入れるのが好ましいです。
dog_info_dict = {
'name': 'ポチ',
}
[2]. 'name': 'ポチ'という部分と'age': 100という部分はプログラムの階層的に考えると、同じ階層に位置しています(両方とも同じ辞書内のキーと値のセット)。
そのため、インデントの位置も合わせるべきです。対応としては以下の「上の要素の位置にインデントを合わせる」方法と「上の要素で改行を入れて、半角のスペース4つに統一する」方法の2つが考えられますが、どちらでも問題はありません。
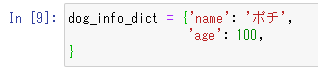
※閲覧されている端末のフォントによってはずれて表示されてしまうため、画像で表示しています。
上の要素に対して改行を入れて半角スペース4つに統一する方法の例 :
dog_info_dict = {
'name': 'ポチ',
'age': 100,
}
章のまとめ
- Pythonでは足し算は
+、引き算は-、掛け算は*、割り算は/の記号を使います。 - 他の記号もそうですが、これらの記号は半角で全て書く必要があります。うっかり全角で書いてしまうとエラーになってしまいます。初めのうちは半角にすべきところが全角になっていても中々気づけないかもしれません。注意していきましょう。
- 余りを計算するには
%の記号を使います。 - 累乗を計算するには
**といったように半角のアスタリスクの記号を2つ連続させた形で使います。 - 値が変わるもので、且つ特定の値を任意の名前で保持するものを「変数」と言います。
- 変数に値を設定するには半角のイコールの
=の記号を使います。 - 変数の内容を確認する時には
printを使います。 -
+=や-=といったように、プラスやマイナスなどの記号と一緒にイコールの=の記号を使うことで、「変数の今の値」に対して足し算や引き算、掛け算などを行うことができます。 - 数値や文字列など、プログラムには色々な「型」が存在します。型に応じてプログラム上の挙動が変わったり、出来ることが変わってきます。
- 基本的に値を変えない想定の値は定数と言います。名前は大文字とアンダースコアを使って、
CONST_VALUEといったように設定します。 - 整数の型は
intと言います。 - 浮動小数点数の型は
floatと言います。 - 文字列の型は
strと言います。 - 文字列を作るには文字をシングルクォーテーションの
'の記号もしくはダブルクォーテーションの"の記号のどちらかで囲む必要があります。 - 順番を持った色々なデータのかたまりはリストといい、型は
listになります。 - リストの中で特定の範囲の値を抽出する処理はスライスと言います。半角のコロンの
:の記号を使います。 - キーと値のセットになったデータを辞書と言います。型は
dictになります。 - プログラムの階層構造に応じてインデントを入れてコードを読みやすくします。インデントはPythonでは多くの場合4つの半角スペースでインデントを表現します。
ごく基本的なところを扱う、Pythonの基礎の章はこれで終わりになります。大分長めでしたが、お疲れさまでした・・・!
各所のコード、実際に自分で書いてみて動かして進められていますでしょうか?また、今回の章から演習問題が出てきましたが、実際に考えたりコードを書いてみたりできていますでしょうか?
もしかしたら面倒に思ってコードを書いたりはスキップしてしまっているかもしれませんが、実際にコードを自分で書いてみて動かしてみたり、自分で考えてみたりを繰り返すと、ただ眺めているだけの場合と比べるととても身に付きます。是非コピーペーストなどせずに、自分で手を動かしてみてください。
また、途中でエラーなどでつまづいてしまったり、解決できずに悩んでいた時や、演習問題であまり正解できなかったりする方もいらっしゃるかもしれませんが、そういったものは大して気にしなくて大丈夫です。
それらのつまづきや悩みだったり、演習問題での考える作業は皆さんの糧となります。むしろどんどん悩んで、色々調べてみたり、試行錯誤したり、間違えたりしていきましょう。
また、調べても解決しないところや、本章の内容で分かりづらい記述のところなどは、「分からないことに遭遇したら?」の章で書いたように、Githubで質問のissueの登録などを利用してみてください。
次章からはPythonの「関数」に入門していきます。こちらも本章の内容と同様、基本的なものでとても大事な内容になります。
基礎ばかりであまり面白く無いかもしれませんが、基礎を疎かにすると難しい問題がプログラミングで解きづらくなってしまって、将来余計につまらなくなってしまいます。大切な内容なのでスキップせずに進めていきましょう!
他にもPythonなどを中心に色々記事を書いています。そちらもどうぞ!
今までに投稿した主な記事たち
参考文献・参考サイト一覧
※他の章のものも含まれます。
- 学びを結果に変えるアウトプット大全
- 「1日30分」を続けなさい!人生勝利の勉強法55
- 最強のプログラミング勉強法が写経である理由
- Qiitaで記事を公開するときに気を付けるべきマナーについて 〜無断でネットや書籍の内容を丸写しするのはやめよう〜
- AnacondaのJupyter notebookでnbextensionsを使う
- シェル、ターミナル、コンソール、コマンドライン
- Google Colaboratoryの90分セッション切れ対策【自動接続】
- カーネル(英:kernel)とは
- Jupyter Notebookをインストール・設定して勉強ノート作成環境をつくる [Mac]
- トレーサビリティ (流通) - Wikipedia
- 浮動小数点数について本気出して考えてみた
- 固定小数点とは
- PEP8
- グイド・ヴァンロッサム - wikipedia
- Python/関数
- スコープ - Wikipedia
- マジカルナンバー <~人が覚えていられる情報は、3~5個!?~>
- なぜ引数はArgumentと呼ばれるのか
- もう参照渡しとは言わせない
- Effective Python ―Pythonプログラムを改良する59項目
- python 組み込み関数を全て(69個)紹介する
- ビルトイン 【 built-in 】
- 組み込み関数
- Pythonで小数・整数を四捨五入するroundとDecimal.quantize
- 端数処理 - Wikipedia
- Why are reversed and sorted of different types in Python?
- Python format()
- Python, formatで書式変換(0埋め、指数表記、16進数など)
- What are the differences between type() and isinstance()?
- Pythonの組み込み関数all(), any()の使い方