はじめに:多段レビューしてるのに、なぜ事故るのか
AIにコードを書かせ、別のAIにレビューさせ、さらに別のチェックを通し、最後に人間が承認する——。こういう多段のレビューチェーンを組んだのに、「品質が上がった実感がない」「むしろ前より見落としが増えた気がする」と感じたことはないだろうか。
レビューの段数を増やしたのに事故る。これは運用が雑だからではなく、多段レビュー特有の構造的な落とし穴にハマっているからかもしれない。
本記事ではその落とし穴を「信頼ロンダリング」と名付けて定義し、それを避けるための HITL(Human-in-the-Loop:人間を判断の輪の中に入れる設計)を、明日から自分の設計に反映できる粒度で整理する。
手を動かす実装記事ではなく、設計思想とその具体パターンの話だ。ただし「気をつけよう」で終わらせず、自己診断チェックリストと設計パターンまで落とす。
「信頼ロンダリング」とは何か
マネーロンダリングは、出所の怪しいお金を複数の口座や取引を経由させることで、最終的に「クリーンな資金」に見せかける行為だ。
信頼ロンダリングは、これのレビュー版である。
十分に検証されていない判断が、複数のAIレビューを経由するうちに「検証済み」に見えてしまう現象。
各段階で「チェック済み」という痕跡(✓やLGTM)が積み上がる。最後に人間がそれを見て、「これだけ通っているなら大丈夫だろう」と判断を委ねる。だが各レビューが実質的な検証をしていなければ、積み上がっているのは検証の事実ではなく、検証の“見た目”だけだ。
ロンダリングされるのはお金ではなく、責任である。「誰かが/何かがちゃんと見たはず」という空気だけが残り、実際には誰も最終的な責任を負っていない状態が完成する。
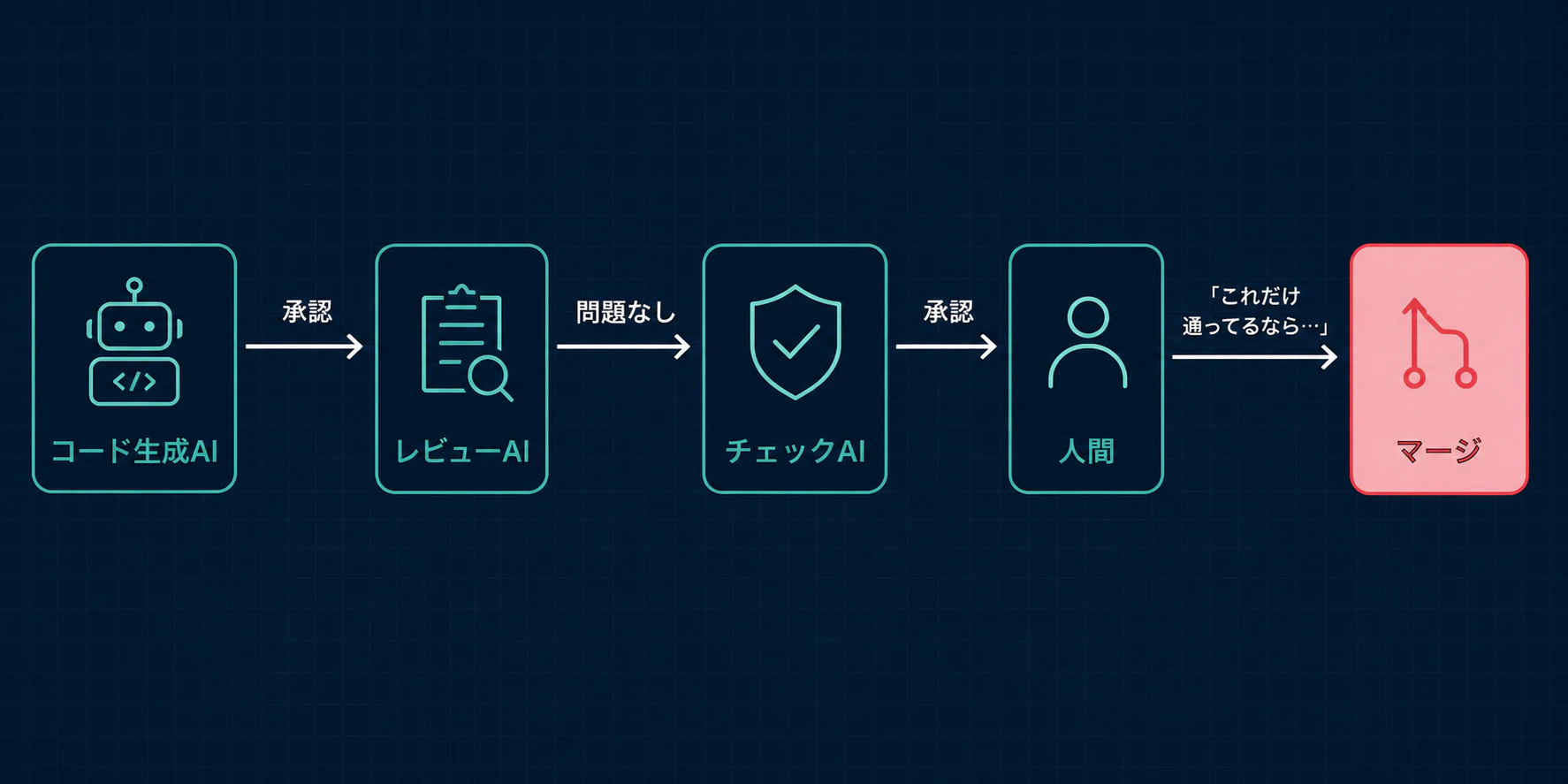
各段で「✓」が積み上がるほど安心に見えるが、実質的な検証は誰も負っていない。
なぜ起きるのか(4つのメカニズム)
信頼ロンダリングは、関係者の誰かがサボっているから起きるわけではない。むしろ全員が「自分の役割は果たした」と思っているのに起きる。原因は次の4つにある。
1. 承認のインフレ
人間のレビューは時間とコストがかかるから、おいそれと量産できない。一方、AIの「LGTM」は実質タダで無限に出せる。承認が安くなると、承認1個あたりの価値が下がる——通貨を刷りすぎたときと同じだ。✓が大量に並んでいても、それは「たくさん検証された」ことを意味しない。
- 兆候:レビューAIがほぼ100%「承認」を返している。却下や保留がめったに出ない。
2. 自動化バイアス
人間は、自動化されたシステムが出した判断を過剰に信頼する傾向がある(automation bias)。画面に✓が並んでいると、脳は「すでに確認されたもの」として扱い、自分で精査するモードに入りにくくなる。本来チェックすべき人間が、✓の存在そのものによって思考を省略してしまう。
- 兆候:人間の最終承認にかかる時間が極端に短い。差分を開かずに承認している。
3. 相関した盲点
「多段でチェックしているから安全」という発想は、各段のチェックが独立であることを暗黙に前提にしている。だが、似た訓練データ・似たプロンプト・似た価値観を持つAIを並べても、それらは同じ間違いを同じように見逃す。独立した3つの目ではなく、同じ目を3つ並べているだけ——独立チェックの幻想だ。
- 兆候:レビューAI同士がほぼ同じ指摘しかしない。あるいは同じ前提ミスを全段が共有している。
4. 責任のパス回し
人間は「AIが何段も見たんだから」と考える。一方、システム設計は暗黙に「最後に人間が見るんだから」と人間を当てにしている。双方が“最終的な砦は相手側にある”と思い込むことで、実際には誰も最終責任を引き受けていない真空地帯が生まれる。これは集団における責任の希薄化(diffusion of responsibility)そのものだ。
- 兆候:事故後に「AIが通したので」「最終チェックは自動化されていたので」という説明が出てくる。
自己診断:あなたのチェックは信頼ロンダリングしていないか
次のうち、いくつ当てはまるだろうか。
- レビューAIが「却下」「要修正」を出したのを、ここ最近見ていない
- 人間の最終承認は、たいてい数秒〜十数秒で終わる
- 各レビューAIに渡している指示は、実質ほぼ同じ内容だ
- レビュー結果は「OK / NG」の二値で、根拠が残っていない
- 問題が起きたとき、「誰の判断ミスか」を一人に特定できない
- 「AIが通したから大丈夫だと思った」と言った(思った)ことがある
3つ以上当てはまるなら、レビューチェーンは“検証”ではなく“検証の見た目”を生産している可能性が高い。次章で立て直そう。
HITLを儀式にしない設計:5つの原則
ここからが本題だ。HITL(Human-in-the-Loop)は「最後に人間を置く」ことではない。ただ置くだけの人間は、✓を眺めてハンコを押す儀式の担当者(rubber stamp)になり、信頼ロンダリングの最終工程に組み込まれてしまう。
人間を “involved(実際に関与している)” な状態に保つための原則を、原則 → ありがちなアンチパターン → 設計パターンの3点セットで示す。
原則1:人間の判断点を意図的に設計する
- アンチパターン:とりあえずフローの最後に「人間の承認」を置く。何を判断してほしいかは決めていない。
- 設計パターン:「どこで・何を・どの粒度で人間が判断するか」を先に決める。全部を見せるのではなく、リスクの高い変更(認証・課金・データ削除・外部公開など)にだけ人間の判断を集中させ、それ以外はAIに委ねる。判断してほしい1点を明示して渡す。
原則2:AIの出力を「承認」から「指摘と根拠」へ
- アンチパターン:レビューAIに「OKかNGか」を答えさせる。出力が「LGTM」だけ。
- 設計パターン:AIには判断を下させず、判断の材料を出させる。「ここが懸念点」「その根拠はこれ」「見るべき差分はここ」。最終的な可否判断は人間(責任者)が下す。AIはレビュアーではなく、優秀な調査アシスタントとして使う。
原則3:レビュー間の相関を断つ
- アンチパターン:同じモデルに同じ指示を与えたレビューを3段並べ、「三重チェック」と呼ぶ。
- 設計パターン:各レビューに違う役割・違う視点を割り当てる。たとえば一つはセキュリティ視点、一つは可読性・保守性視点、一つは要件との整合性視点。視点を分けることで相関した見逃しを減らし、初めて“多段”に意味が出る。
原則4:✓ではなく不確実性・反論・根拠を可視化する
- アンチパターン:レビュー結果を緑のチェックマークだけで表示する。
- 設計パターン:「自信度が低い箇所」「判断が割れた箇所」「あえての反対意見」を前面に出す。人間が“省略”しにくいように、安心させる情報ではなく引っかかる情報を見せる。緑一色のダッシュボードは、自動化バイアスを誘発する装置になりうる。
原則5:責任のアンカーを固定する
- アンチパターン:「チェーン全体で承認された」状態にして、最終責任者が曖昧。
- 設計パターン:最終的に「このマージはこの人が判断した」と一人に紐づける。AIのレビューは判断の補助であって、責任の肩代わりではない、と制度として明文化する。「AIが通したから」を言い訳にできない構造にする。
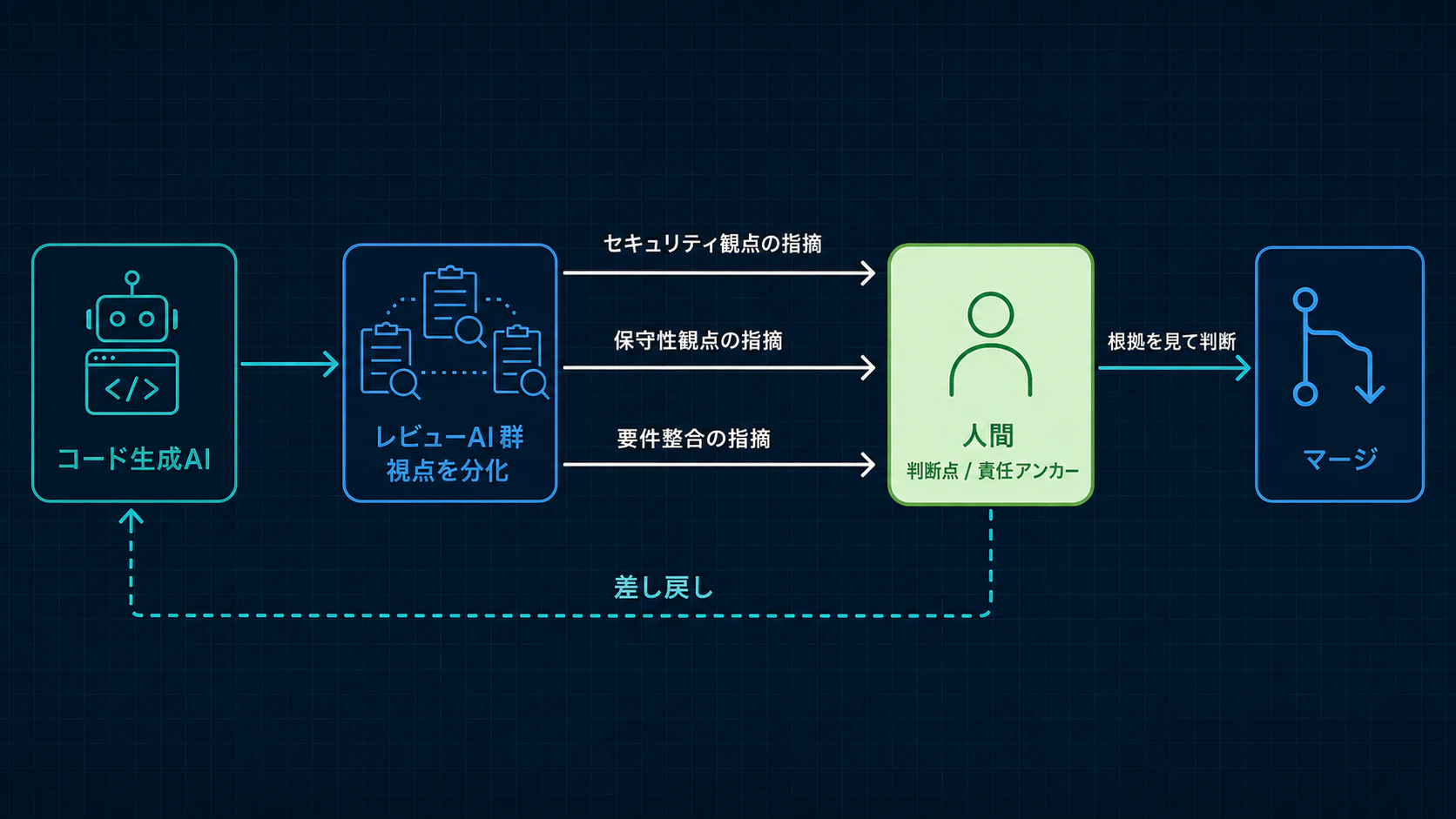
AIは「承認」ではなく「指摘」を出し、判断と責任は人間に集約する。
設計を運用に落とす(一般化パターン)
原則を日々の運用に落とすときに効く、ツールや組織に依存しない一般パターンを挙げる。
- 判定に構造化フォーマットを課す:レビューの結論を自由記述ではなく、「通す/通さない」「その理由」「確認した観点」「見送った観点」といった決まった項目で残させる。根拠が必須になることで、空虚な承認が出しにくくなる。
- ゲートを“全部緑=自動通過”にしない:CIや自動チェックが全部緑でも、それは自動マージ許可ではなく「人間が判断するための前提が揃った」状態と定義する。止める権限と責任を、制度として人間側に残す。
- 統合点を一本化する:変更が最終的に合流する地点を一つに絞り、その直前に必ず人の判断を一点だけ挟む。判断点を分散させると、どこでも誰かが見ているようでいて、結局どこでも誰も見ていない状態になりやすい。
- 却下の実績をモニタする:レビューAIの却下率・人間の差し戻し率を記録する。長期間ゼロが続いているなら、それはチェックが機能している証拠ではなく、機能していないサインとして扱う。
これらは「人間の手間を増やす」ためではなく、増やすべき一点と、安心して任せてよい大半とを切り分けるための仕組みだ。
やりすぎ注意:HITLのコストとトレードオフ
ここまで読むと「結局すべてに人間を挟めばいいのか」と思うかもしれないが、それは別の失敗だ。全工程に人間を挟めば、AIで開発を速くした意味が消え、レビュー疲れで判断の質も落ちる。皮肉なことに、人間を挟みすぎても——形だけのチェックが増えて——信頼ロンダリングは起きる。
要は配置の問題だ。リスクの高い場所に人間の判断を厚く、低い場所はAIに大胆に委ねる。判断点はコストなので、無限には置けない前提で「どこに置くと一番効くか」を設計する。全部を見る人間は、何も見ていない人間とそう変わらない。
まとめ
多段レビューは、それ自体が品質や安心を保証するものではない。設計を誤れば、検証の“見た目”だけを量産し、責任を希薄化させる装置——信頼ロンダリングの仕組み——にもなりうる。
鍵は、人間を「最後に置く」ことではなく「実際に判断させる」こと。そのために、
- 判断点を意図的に設計し、
- AIには可否ではなく根拠を出させ、
- レビューの視点を分化させ、
- 安心ではなく引っかかりを可視化し、
- 責任を一人に固定する。
発想を一言で変えるなら、こうだ。
「AIにレビューさせる」から、「人間が判断するためにAIを使う」へ。