TL;DR
- LLMが普及して「情報の獲得」はほぼタダになった。だが知識が積み上がる速度はむしろ落ちた人が多い。
- 原因は2つ。trust laundering(信頼の洗浄) と self-justification loop(自己正当化ループ)。AIの自信ありげな出力を、検証しないまま「自分の知識」として通してしまう。
- だから学習の律速(ボトルネック)は、もう「探す・読む」ではなく 「検証する・定着させる」 に移った。検証だけはAIに委譲できない。
- 自分は外部脳(3層構造 + 5フェーズ + 半年ルール)でこのボトルネックを回しています。仕組みと「明日からできる」手順を共有します。
対象読者は 実務でAIを使い始めた中級者。「Claude / ChatGPT で開発も調査も爆速になったのに、なぜか身についてる気がしない」という違和感を持っている人向けです。
1. 中級者がハマる「分かった気」の正体
初心者の頃は、そもそも情報にたどり着くのが大変だった。公式ドキュメントを探し、英語の記事を読み、Stack Overflow を漁る。情報の獲得そのものがコストだった。
LLMが来て、そのコストはほぼゼロになった。設計の相談も、エラーの原因切り分けも、新しいライブラリの使い方も、聞けば数秒で返ってくる。実務スピードは確かに上がる。
ところが半年経って振り返ると、こうなっていないだろうか。
- AIに聞いた瞬間は「完全に理解した」のに、1週間後には他人に説明できない
- 同じことを3回AIに聞いている
- 自分が「知っている」ことと「AIに聞けば分かる」ことの境界が曖昧
これは記憶力の問題ではなく、学習プロセスに2つの落とし穴があるからです。
1-1. trust laundering(信頼の洗浄)
AIの出力は、整った日本語と自信に満ちたトーンでやってくる。中身が正しいかどうかと、出力の見た目の説得力は無関係なのに、人間は後者で信頼を判断してしまう。
その結果、検証されていない主張が「AIが言ったから」という理由だけで信頼を獲得する。一次情報に当たれば5分で崩れる誤りが、整形された文章を通り抜けることで"洗浄"され、あなたの知識ベースに正規品として並ぶ。
これが trust laundering です。怖いのは、洗浄された誤りはあなた自身の判断として再利用される点。次に誰かに説明するとき、あなたはそれを「自分が検証した知識」として語ってしまう。
1-2. self-justification loop(自己正当化ループ)
「この理解で合ってる?」とAIに確認すると、たいてい「はい、その通りです」と返ってくる。AIはあなたの前提に引っ張られやすく、独立した検証者ではない。
- あなた「Aだと理解しました」→ AI「正しいです(あなたの前提を追認)」
- これを「検証した」とカウントしてしまう
実装でも同じ構図が起きます。AIにテストを書かせ、AIにそのテストを評価させると、自分で自分を採点する閉ループができる。緑のチェックが並んでも、何も検証していない。
中級者の罠は、初心者の「情報が足りない」ではなく、「検証していない情報が多すぎる」 こと。
2. 主張:律速は「獲得」から「検証と定着」に移った
ここから本題です。LLM時代の学習を、3つのフェーズで分けて考えます。
| フェーズ | 中身 | LLM以前のコスト | LLM以後のコスト |
|---|---|---|---|
| 獲得 | 情報を探す・読む | 高い | ほぼゼロ |
| 検証 | 正しいか確かめる | 中 | 下げられない |
| 定着 | 再利用可能な形で残す | 中 | 下げられない |
獲得だけが爆速になり、検証・定着は据え置き。だから全体のスループットは「検証・定着」で律速される。ここに時間を割り当て直さないと、いくら獲得を速くしても知識は積み上がりません。
そして重要なのは、検証はAIに委譲できないということ。
検証とは「この主張を、自分の責任で正しいと判断すること」です。判断の主体を外部化した瞬間、それは trust laundering になる。AIは検証の材料(反例、一次情報の在り処、別の観点)は出せても、最終判断という行為そのものは肩代わりできない。ここが人間に残された仕事です。
3. 仕組み:外部脳でボトルネックを回す
抽象論で終わらせないために、自分が実際に運用している「外部脳」を晒します。Obsidian で組んでいますが、ツールは何でもいい(Notion でも、ただのフォルダでも成立します)。
3-1. 3層構造:信頼度でフォルダを分ける
知識を信頼度ごとに物理的に分離するのが肝です。同じフォルダに混ぜると、検証済みと未検証の区別が消えて trust laundering が起きる。
| 層 | 中身 | 出どころ | 扱い |
|---|---|---|---|
raw/ |
AI出力・記事・メモの生データ | LLM、Web、本 | 未検証。信用しない |
candidates/ |
検証中・要確認の仮説 | rawから昇格 | 保留中。引用するときは注記 |
verified/ |
自分で検証し終えた知識 | candidatesから昇格 | 再利用OK。人に説明できる |
ポイントは、何かを学んだら必ず raw/ から始まること。AIの回答は最初から信用しない。これだけで「整った文章=正しい」という錯覚を構造的に防げます。
3-2. 5フェーズパイプライン
層の間を動かす流れがこれです。
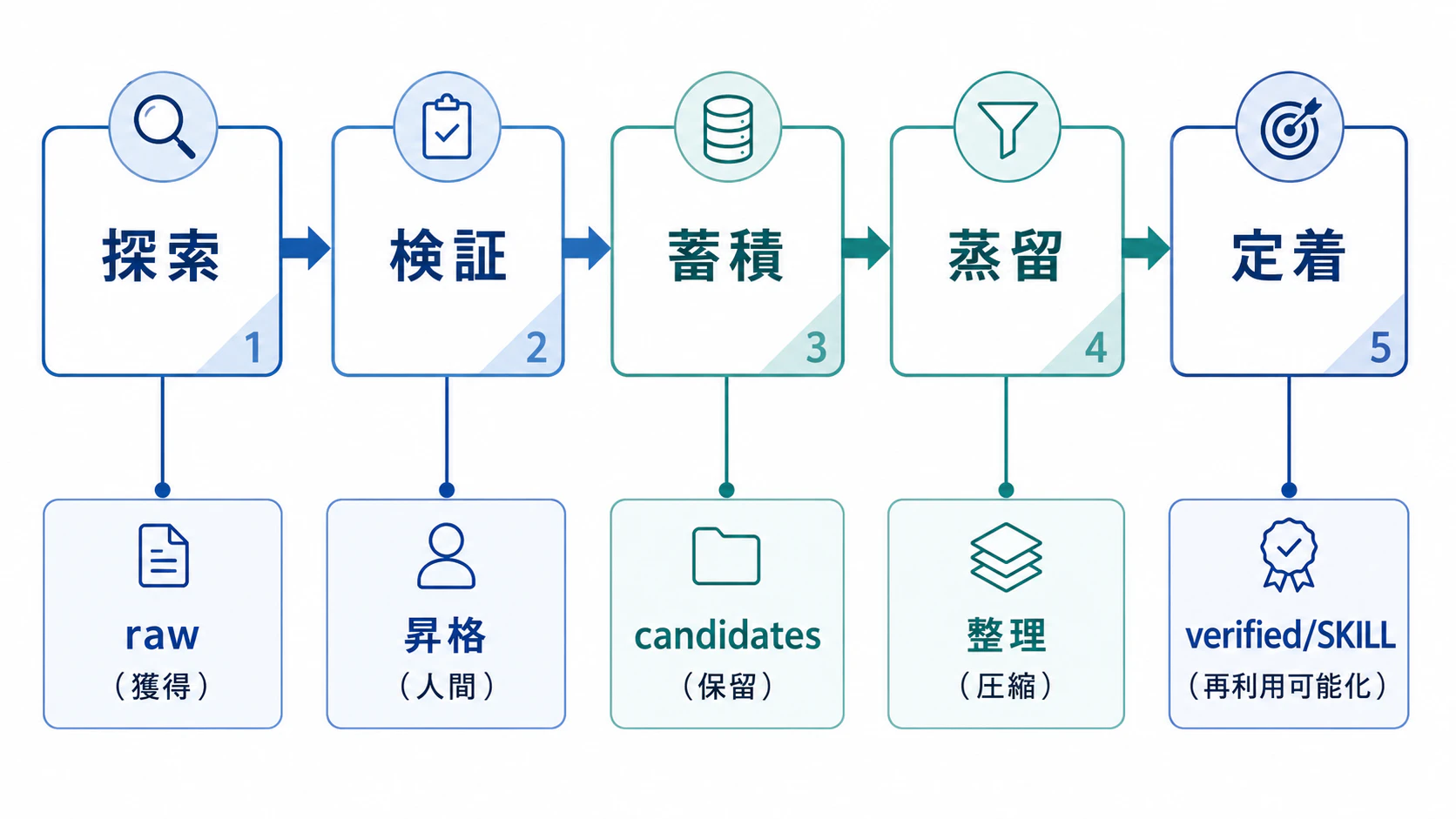
-
探索:AIや記事で広く集める。ここは速くていい。
raw/に放り込む - 検証:← ここが律速。後述の方法で自分で確かめる
-
蓄積:通ったものを
candidates/へ。まだ確信がなければここで寝かせる - 蒸留:複数の知識を圧縮し、再利用可能な単位(例:Claude Code の SKILL、自分用チートシート)にまとめる
-
定着:
verified/または SKILL として出力。出力できて初めて「身についた」
3-3. 半年ルール:使われない知識は捨てる
candidates/ に入れたまま半年触っていない知識はアーカイブします。
外部脳は溜め込むほど検索性が落ちて死にます。「いつか使うかも」の99%は使わない。検証していない知識を抱え続けるコストのほうが、捨てて再取得するコストより高い。LLM時代は再取得がタダなので、この判断はさらに合理的になりました。
4. 検証の具体的なやり方(AIに委譲できない部分)
「検証が大事」と言うだけでは精神論なので、自分が raw/ → candidates/ → verified/ で実際にやっていることを書きます。中級者がそのまま真似できる粒度で。
4-1. 動かす(実装系なら最優先)
コード・設定・コマンドの話は、手元で実際に動かすのが最強の検証です。AIが書いた CDK のスタックも、まず cdk diff で差分を自分の目で見る。緑のテストではなく、自分が観測した挙動を信じる。
self-justification loop を断ち切るコツ:生成と検証を別の主体に分ける。AIにコードを書かせたら、検証は自分が手で動かす。あるいは「このコードの穴を3つ指摘して」と反証側に立たせる(追認ではなく否定をさせる)。
4-2. 一次情報に1点だけ当たる
全部を裏取りする時間はない。なので主張の中で一番クリティカルな1点だけ公式ドキュメント・論文・仕様に当たる。そこが崩れたら全体が崩れる「急所」を狙い撃ちします。
AIには「この主張の一次情報のURLは?」と聞き、そのURLを自分で開いて中身を確認する(URLを聞いて満足したら、それも trust laundering です)。
4-3. 反証を探させる
「これで合ってる?」ではなく「これが間違っているとしたら、どういう理由か」と聞く。前提を追認させず、反対側を言語化させる。出てきた反証が潰せたら、その知識は candidates/ に昇格していい。
検証の本質は「正しい証拠を集める」ことではなく「間違っている可能性を潰す」こと。AIは反証の材料出しは得意。最終判断だけ自分でやる。
5. 明日からできる3ステップ(中級者向け)
仕組みをフルで組むのは重い。最小構成はこれだけです。
-
フォルダを2つ作る:
raw/(未検証)とverified/(検証済み)。AIに聞いた内容は全部raw/から始める。このフォルダ分けだけで意識が変わります。 - 聞き方を変える:「合ってる?」を「間違ってるとしたらどこ?」に置き換える。追認ループを否定ループにするだけ。
-
週1で1個だけ昇格させる:その週に一番使った知識を1つ選び、人に説明できる形に書き直して
verified/へ。書けなければ、それはまだ理解していない証拠。
全部やらなくていい。まず 1 だけでも効きます。
おわりに
LLMで「獲得」がタダになった時代に、勉強法のアップデートで一番大事なのは、節約できた時間を「検証と定着」に再投資することだと思っています。
AIは最高の探索エンジンであり、最高の反証パートナーでもある。でも「正しいと判断する」という行為だけは、最後まで自分の手に残る。そこを手放さないことが、AI時代に知識が積み上がる人とそうでない人を分ける——というのが、実務で使い倒してきた自分の現時点の結論です。
同じ違和感を持っている中級者の参考になれば嬉しいです。検証の運用、みなさんはどうしてますか?コメントで教えてください。