この投稿は、私が所属するKDDIテクノロジーで行っているアドベントカレンダーの最終日12月25日分の記事となります。他の記事はこちらです。
https://qiita.com/advent-calendar/2024/kddi-technology
今年の私のアドベントカレンダーでは「生成AIアプリの進化について考えてみる」として、次の投稿行ってきました。
本エントリーは「生成AIアプリ」をテーマに、現在の姿と将来の進化について、主にアプリ開発やアプリ市場の観点で技術動向を俯瞰し、予測を試みる3回目となります。
現在の生成AIアプリの提供形態はSaaSが中心ですが、今後スマートフォンなどのアプリとして提供されるようになると予想されています。そのときの「生成AIアプリ」のUI/UXは従来のアプリとは変わることが予想されます。また、場合によってはそのアプリを搭載するスマートフォンの形状も変わり、提供するユーザー体験も変わってくる未来が訪れるかもしれません。そのときのデバイスがポストスマートフォンと呼ばれる将来像を期待しています。
本稿は、今年6月に幕張メッセで開催されたInterop Tokyo 2024での講演「進化するアプリ イマ×ミライ~生成AIアプリへ続く道と新時代のアプリとは~」の資料を基に、その後の生成AI動向を踏まえて加筆修正したものです。
https://forest.f2ff.jp/introduction/9177?project_id=20240601
なお、本稿は嶋是一個人の見解に基づくものであり、所属団体およびその組織の総意を代表するものではありません。
生成AIとアプリの概観
まだスマートフォン上で生成AIが動作し、スマホアプリとして提供できる仕組みが整っていません。それは第1回、第2回で紹介したように、生成AIの頭脳となる「LLM」が端末上で動作できる「事実上の標準となる実行環境」が普及していない為です。現状では、一部の端末でしか動作しないか、異なる実行環境ごとに個別のアプリを開発する必要があるため、アプリ開発は困難です。
そのため、現在もっとも現実的な開発手法は、端末上でLLMを動作させる事をあきらめて、クラウド上でLLMを動かし、その結果をネットワーク越しにアプリが取得する手法です。利用者にとって、LLMがサーバーで動いているか、端末で動作しているかは気にしません。スマートフォンの画面を見る限り、ほとんど区別がつかないためです。
現在、スマートフォン上で動作する、ChatGPTアプリやGeminiアプリなどは全てこのモデルです。画面はスマホアプリ画面ですが、その実態はクラウド上で(SaaSとして提供されるAPIをアプリから呼び出して)LLMを実行させています。
現在の生成AIサービスの多くは、チャット形式(チャットUI)のUX(ユーザー体験)として提供されています。具体的には、生成AIが生成したテキストが左側に、自身が入力したテキストが右側に表示される画面構成(UI)となっています。ユーザー体験(UX)としては、あたかもスマートフォンとチャットしているような操作を実現させています。
チャットUIの例
携帯電話のUIの進化
携帯電話は電話をかける装置でした。そのため待ち受け画面は、ハードウェアのテンキーを押せば電話番号が入力され、もっとも電話を掛けやすいUIを作り上げて、「電話」というユーザー体験をもたらすガジェットとして提供されていました。
スマートフォンとなり、メールやWeb中心のユーザ体験を実現する装置に変化しました。すると待ち受けに検索窓が設けられたり、メールなどのコミュニケーションツールのアプリを稼働しやすいように、待ち受け画面にアイコンが羅列されるUIに変革しました。タッチパネルによる直感的な操作は、この流れに合致し、使いやすさを大きく向上させました。
さて、生成AI時代のアプリは、チャットUIです。すると待ち受け画面はどのように変化するでしょうか。
当然そんな変革を今ここで予言することはできないのですが、少なくても解っていることは、待ち受けに「でーん」と文字入力窓があり、そこに文字列を入力するようなUIには「ならない」という事です。文字入力を待つよりも、アイコンからアプリを選択する方が迅速に目的の操作にたどり着けるからです。
文字でないならば、スマートフォンなので音声で入力するのが標準となるかもしれませんし、カメラに写り込んでいる情報をベースに操作が進むようなUIとなる可能性もあります。まだまだUIは変わっていく可能性があります。
それでも、待ち受けから生成AIとの対話へは、簡単な動作で入れるような導線となるでしょうし、対話状態に入ってしまったら、従来のチャットUIの左右対話の画面となるでしょう。またアプリの起動は、従来のアイコンメニューからだけでなく、チャットの内容から自動的に起動したり、または、起動候補(行動提案)が出されて行動選択を促されるような形で起動するかもしれません。どちらにしても、利用者が従来の操作よりも「簡単だ」とか「嬉しい、楽だ」と思う操作で実現される事でしょう。
チャットUIの端末スタイル
昨今のスマートフォンは画面サイズが大きく、縦に長い画面が採用される事が多いです。それは画面にアイコンの一覧や情報を羅列するため、一度に多くのアイテムが表示された方が、利用者が選択する際に使い勝手が良いためです。
チャットUIは、下部に自分の入力テキストを記入して、それに対応するLLMから応答を得る事で実現させます。新しい入力や応答が得られるたびに、その履歴が画面の最下行に追加されて、対話が進むにつれて残りの上の部分は順次上へスクロールしていきます。このやり取りを繰り返すと、画面上部には古い履歴が蓄積され、短い対話の場合、かなり過去の履歴まで表示されることになります。
しかし、古い履歴は対話中に必要でしょうか?
対話を続けているときには、「今の内容」に集中して対話を進めるため、古い履歴はそれほど重要でなくなります。そのため、チャットUIに適しているのは「縦に長く、画面が広い端末」ではなく、「適当な履歴が数行表示できるだけのデバイス」である可能性があります。
それを具現化したデバイスがあります。生成AIデバイスとして開発された、Rabbit r1というデバイスです。このデバイスは今年のCES2024で発表され、とても話題になったデバイスです。正方形のディスプレイに最適化されたUIを持ち、音声入力を主体とする設計となっています。このように、チャットUIに適したスマートフォンの形状を考えると、従来のスマートフォンで当たり前だった常識を塗り替えてきます。

もちろん、Rabbit r1が広く生成AIのUXとして受けいられているかというと、残念ながら現実は厳しいもので、実用面ではまだまだ課題がありそうな状況です。まだ、最適な形状やフォームファクタは、市場で実験中という状況だと思います。
ちなみに弊社KDDIテクノロジーでは、この毎年1月に米国ラスベガスで行われているCESへ(社員の希望者を募って)毎年視察を行っています。実は今年の調査メンバーは、このRabbit r1を現地で必死になって探したのですが、展示を見つけ出すことができませんでした。それもそのはず、プレス向けの発表であり、発売は後日であったため、一般へのお披露目はされていなかったようなのです。後日こちらのデバイスを入手して、社内で調査を行っています。
生成AI時代のポストスマートフォンに向けた進化
ポストスマートフォンとは、将来スマートフォンに置き換わって普及する仮想の装置、端末、またはデバイスを指します。かつてのフィーチャーフォン(ガラケー)がスマートフォンに取って代わったように、スマートフォンに続く革新的なデバイスへの期待を込めて、「ポストスマートフォン」という言葉が用いられています。
この変化を予測するには、やはり過去の進化軸をもとに考え見るのが良さそうです。そこで筆者が昔から好んで使っている「属人機」という物差し(IRI藤原先生の影響です)を使って話を進めてみたいと思います。
そこから、生成AI時代のアプリや、そのアプリが動作するデバイスの進化を「生成AI時代の属人機」としてを考えてみたいと思います。
属人機としての進化
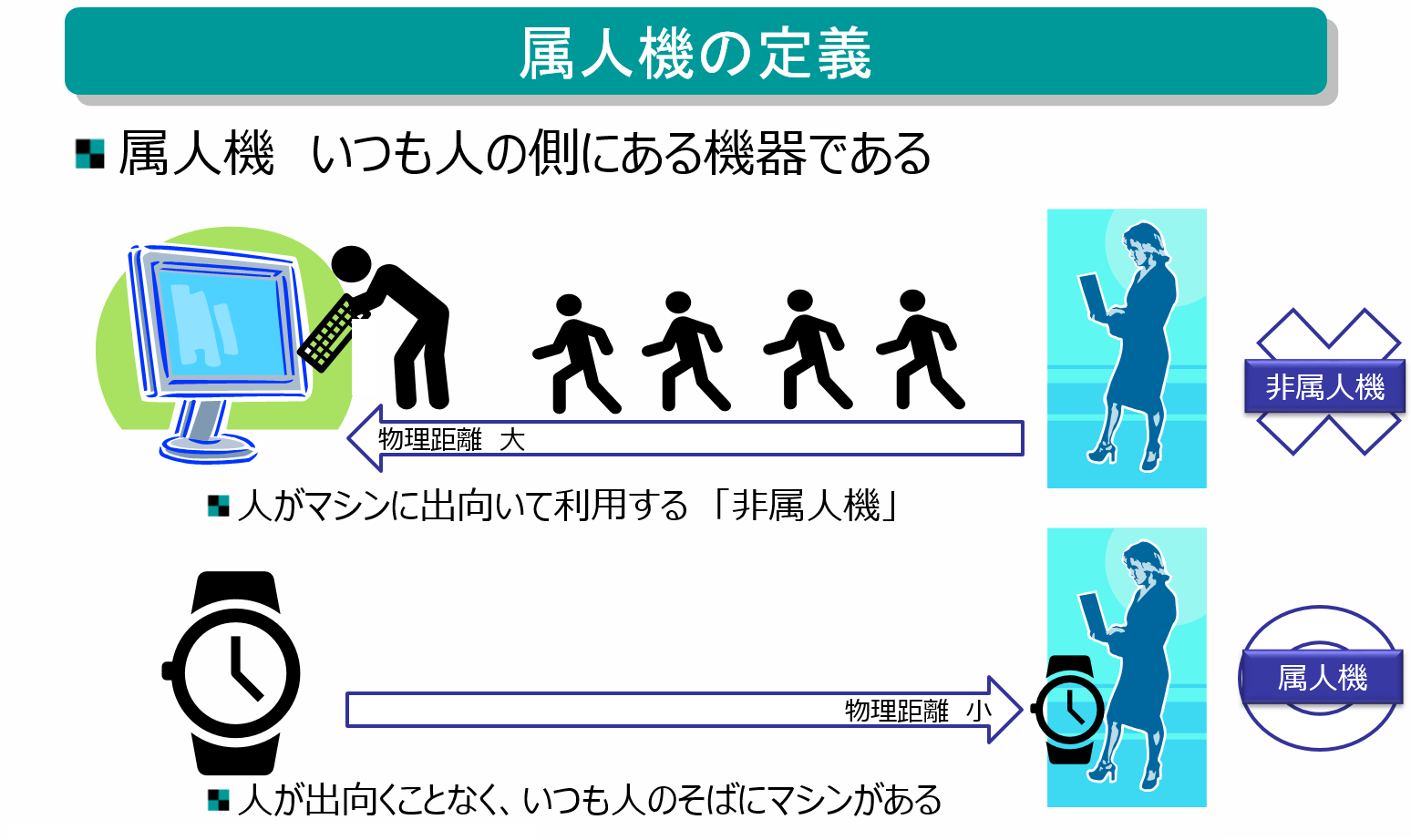
人が生活している時間の多くを一緒に過ごすような装置を「属人機」と呼んでいます。なぜなら人に寄り添い、人の側(サイド)で動くような「人に属するマシン」だからです。そのような属人機としての確固たるイス(身につける場所)を獲得したデバイスは、人間の歴史では2つしかありません。一つは「腕時計」であり、もう一つは「携帯電話」です。一方、パソコンやテレビなどは「非属人機」となります。なぜならば、利用するのに、人が設置場所まで移動してから利用するためです。そういう意味で、属人機とは、デバイスが、どれだけ物理的に人に近しいところで動き、いかに体の一部のように振る舞えているのかを測る指標となります。
非属人機のパソコンは、人が移動してパソコンの前に座らないと利用できないため、利用できるシチュエーション、場所、時間帯などに制約があります。そのため、利用時間自体も属人機に比べると短くなってしまいます。一方、属人機は日常持ち歩いたり体につけて(ウェアラブル)利用するため、人からの距離が極めて近いため、ほぼ身体機能(五感)のひとつのように活用できるため、利用時間も長くなります。例えば、時計は人間の時間感覚を拡張し、より正確な時間認識を可能にします(少なくても、腹時計よりは正確でしょう)。また、写真撮影は記憶の補助として機能します。このように、人体の機能や認知を拡張する役割に属人機は適していると言えます。
このような属人機としての「3つ目のイス」を狙うデバイスとして、ウェアラブルデバイスであるスマートウォッチや、活動量計、そしてスマートグラスなどが、その座を虎視眈々と狙いつつ進化を続けています。しかし残念ながら、イスを獲得するまで(普及するまで)には至っていない状況です。これら第三のデバイスがポストスマートフォンとなり得る可能性を秘めていると考えられます。
生成AI時代の属人機とは
先に述べた通り「属人機」は人とマシン(機械)と物理的な距離で測られます。
では、「生成AI時代の属人機」をどのように定義すべきでしょうか。
その答えから先に言うと、物理的な距離ではなく、人との思考的な距離で測るべきです。
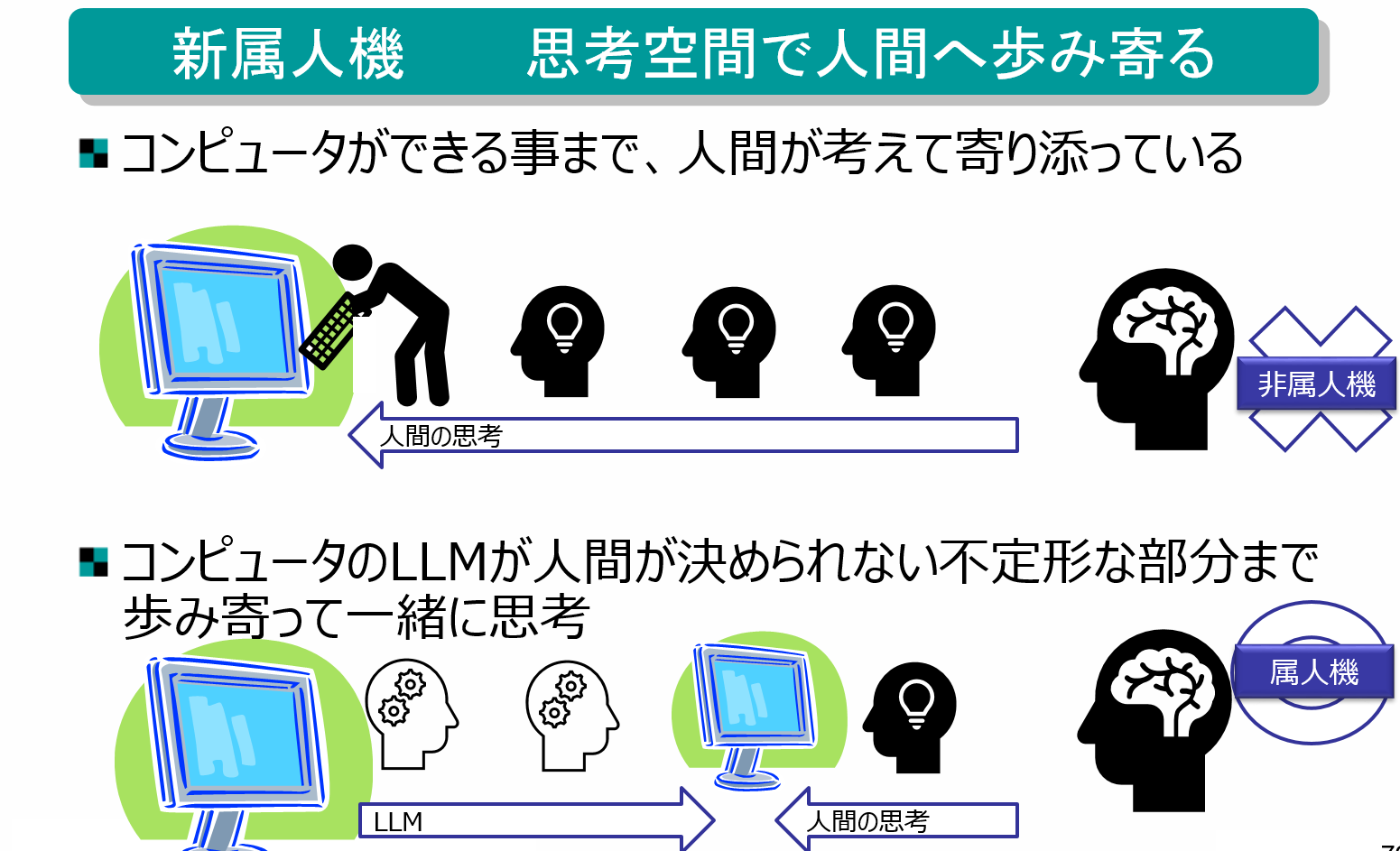
現在のコンピュータでできる事の多くは、定型的な処理に限られているため、コンピュータができる事まで、人が頭で考える必要があります。例えば、おなかがすいた時に何かネット注文すれば食事にありつくことができます。しかし、食べる料理の種類、注文するサイト、料金の支払い方法などを事前に調べて、全てを自分の考え(意思)として準備しておかないと、注文の手続きを完了させることができません。それは、コンピュータシステム側が「決められた注文を受ける」事しかできないためです。これはまさに非属人機の「人がマシンまで物理的に歩いて使いに行く」ようなもので、これは、人の思考がマシンに合わせることを強いられている状態と言えます。「人の思考がマシンに歩み寄っている」ような状態です。
一方、生成AIを活用することにより、人が事前に決められない部分や、不定形な条件などを、マシン側で提案(仮説)や整理を行うことができるようになります。現在のLLMの性能ならばチャットというユーザーインターフェイス(UI)を用いて、対話を行いつつ少しずつ思考や仮説を絞り込んでいく手法が成功しているように思えます。つまり、マシンが人の思考を肩代わりする割合が増えるほど、思考的な距離は縮まると言えます。
このように、マシンが人の考えに歩み寄るのが「生成AI時代の属人機」と考えられます。
属人さに応じてUIがかわり、UXもかわる
「究極のUXはUIを持たない」という、センセーショナル表現を用いています。
UIが不要と言っているわけではありません。
UXはユーザ体験(User Experience)であり、スマホなどの場合は使った時に感じる「面白さ」「便利だ」「使いやすい」「サクサク動く」などの印象や感動、満足感などの体験したことすべてを意味します。一方UIはユーザーインターフェイスであり、端末を利用するときに、人との間に存在する接点(インターフェイス)の事です。スマホの場合なら、ディスプレイやその画面上の表示や、スピーカーで鳴らす音声、着信時などに震えるバイブレーション機能などもUIとなります。
UIの良し悪しは、端末の使いやすさに大きく影響します。UIが良ければ良いUXを得られるし、その逆も然りです。つまり、端末を操作するときの余計なUIはオーバーヘッドであり、最小のUIで目的の動作ができることが理想だと考えられます。そのため多くのUIの存在は必要悪であり、できれば利用者に気にさせないような空気のような存在であるべきと考えます。ここで「生成AI時代の属人機」が登場します。属人機の割合によって、このUIが変化するというものです。
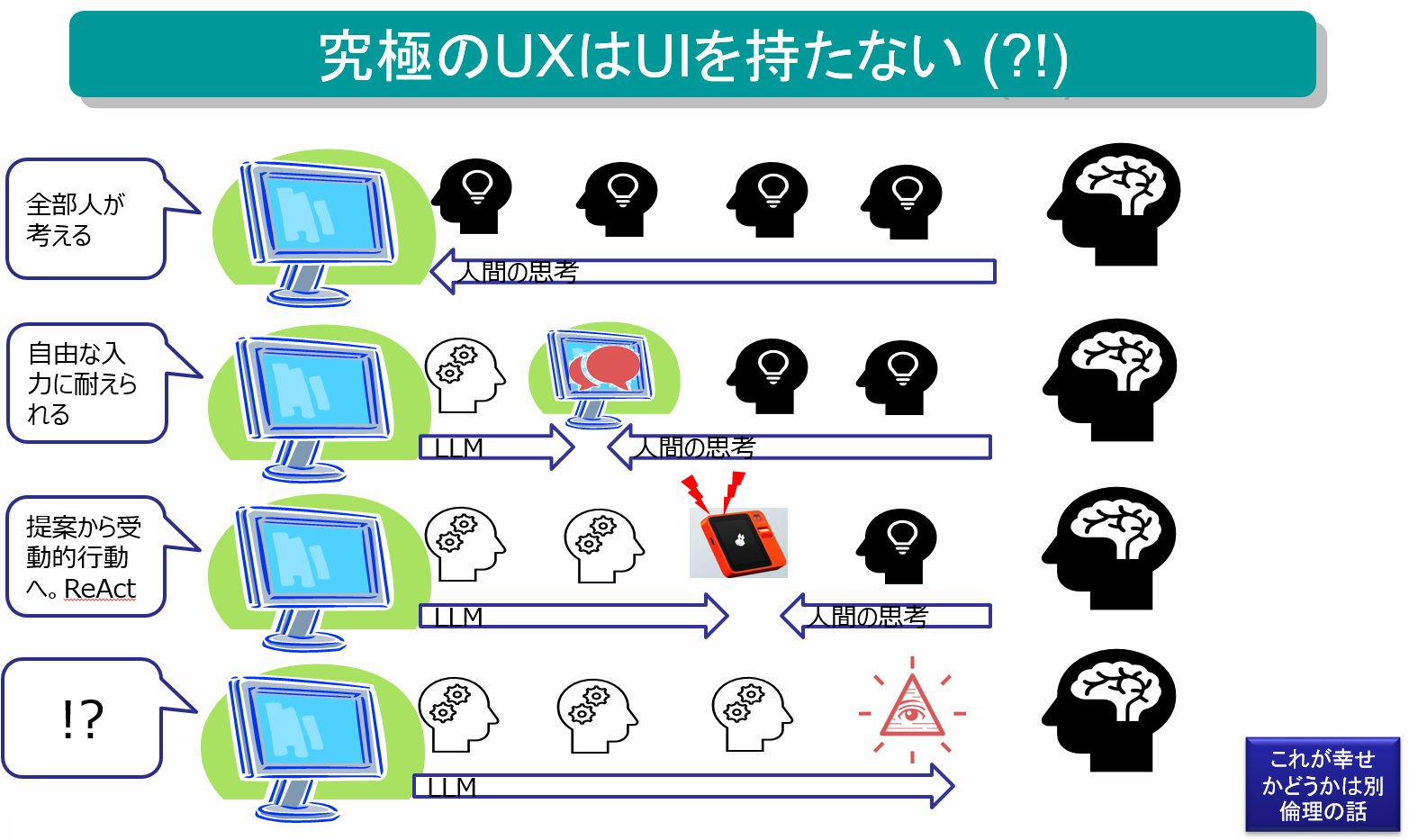
まず始めに、生成AI「以前」の端末では、全てを人間が考える必要がありました。

ところが生成AI時代になると、(自然)言語をシステムが理解してくれるため、人が求められた言葉を発するまでの、考える量が減ります。現在もっとも普及しているこの生成AIの使い方は「チャットUI」の形式です。人が話す「不定形な自由な入力」に対応して、理解されたような応答が返ってきます。つまり、これまでのコンピュータシステムではフォームに文字を入力するか、ボタンを選択するしかなかったところに、チャットUIのおかげで人が自由な順番で、自由な自然言語の文章を入力して、回答を得る事ができるようになりました。

次にチャットをしているときに、同じ質問でも、屋内にいるのか、屋外にいるのかで、期待される回答は異なってきます。できれば期待通りの回答を欲しいところです。そこで登場するのがLLMのマルチモーダル機能です。マルチモーダルLLMとは、テキストだけでなく、映像や音なども一緒に処理することができます。テキストや音声などのような入出力となる情報の種類を「モダリティー」と呼びます。複数のモダリティーを用いる事で、LLMはより情報が複合した複雑な実行(推論)を行う事ができます。そして、このような映像や音声などをマルチモーダルLLMで処理すると、その利用者の状況(屋内か屋外か、空腹か満腹か、暑いか寒いか、など)を、より正しく把握しやすくなります。
そこから期待されるのが、アシスタント機能です。利用者が行いたい事を、生成AIを用いて提案するというReACTという考え方も、進化するとアシスタント機能となります。これにより、LLMは受動的に利用者から質問された内容を推論して返答するだけでなく、行動を提案することができるようになることを期待されています。

デバイスが利用者の状態と意図をある程度正確に把握できるようになれば、利用者の操作に先んじてアプリが起動し、結果を提供できる可能性もあります。この予測が正確でればあるほど、UIも最小限で済み、突き進めば必要なくなることも考えられます。最終的に得られるUXが同じであれば、UIは無くても良いと考える世界感がそこにあります。
現実には期待されるような正確な予測は難しく、UIを表示するディスプレイは搭載され続けるでしょう。しかし高精度なLLMが作られることにより、ディスプレイの利用目的が変化し、サイズが小さくなったり、本体には搭載されず外部のディスプレイを用いて表示されたれするような、世界観もやってくるかもしれません。

人の操作をLLMに予測させ、先んじて実行させておく「全自動アシスタント」の考えは、やや飛躍した発想であり、倫理的な観点についてはここでは言及を避けますが、思考実験の一つとして紹介しました。ただスマートフォンを利用していている時に、不要なポップアップが表示され「OK」ボタンを要求してきたり、必要な情報がアプリに散らばっているためメールを作成いる際に複数のアプリを切り替えながら作成せざるを得ないなど、不要(面倒)と思われる操作が多く存在します。そのようなものが自動化されて動く端末ならば、「簡単だ」とか「嬉しい、楽だ」と思える操作となり得ることは理解できるのではないでしょうか。
生成AI時代のポストスマートフォンの実現
コンピュータのLLMが人間の曖昧な思考に寄り添えるかどうかは、利用者の行動を高精度に推測できるかどうかにかかっています。これが実現できないと、生成AI時代の属人機を実現することはできないと思います。
このような利用者に深く寄り添うためには、利用者の深い部分までの行動の推測を行う事が必要となります。それは簡単な事ではないでしょう。
生成AIのサービス開発の一角では「ナラティブ体験」というキーワードが使われます。さまざまな解釈がありますが、ここでは「人に寄り添い、深いパーソナライズに基づいて紡ぎ出される個人の物語」と解釈します。つまり、生成AIサービスを利用する際に、サービス構築する際に作成されたあらかじめ用意されたユーザーストーリーに沿った使い方を強いるのではなく、あたかも自分がそのタイミング、その環境で行いたい事が、自分から自発的に物語(ストーリー)紡ぎ出されて、その物語とおり(ここでは)システム側が寄り添うように動作してくるような環境を意味します。これにより、個人に肯定的な行動変容することをナラティブ体験を呼ばれています。
このナラティブを実現するためには、相当高度の推測が必要となります。そのための現状認識を行うためには、従来のマルチモーダルLLMでは不十分で、もっと新しいモダリティー(各種センサー情報: 位置情報、温度情報、身体情報など)が追加される必要などがあるのでは無いかと考えています。
生成AI時代の端末サービス
GoogleはProject Astraという取り組みで、マルチモーダルな情報からAIエージェントの開発がされています。Google I/O 2024でも「すべての人に役立つAIエージェントを目指す」と発表されています。下図は、スマートフォンのカメラを用い画像認識を行いつつ、表示画像の上にタッチパネルを用いて絵を描き、マイクから音声で指示を出すと、それらの各々の情報をLLMが「動作すべき行動」を判定して、行動を起こしてくれるデモストレーションです。ここでは、スピーカーの小さいコーン(ツイーター)の映像をカメラからディスプレイに表示させ、タッチパネルを指でなぞって矢印がツイーターを指すように描きます。すると、ツイーターの解説の説明を音声合成で話し始めます。アシスタント機能が、矢印先のものを認識して、その説明を自動で実行してくれたデモストレーションとなります。

いま、各社がAIエージェントの開発を積極的に進めており、この分野は急速に進化しています。その中で、よりパーソナライズされた「属人性」が高いサービスが生まれることを期待しています。
また、Claudeを開発するAnthropicから「Computer Use(β)」というサービスが11月に発表されています。これは、プロンプトで指示することで、複数のアプリケーションを横断的に操作し、Windows OSの機能のようにPCを自動操作する「アシスタント機能」を実現しています。従来、アプリケーション間での情報連携にはAPIの実装が必要でしたが、Computer UseではWindows PC上でのユーザー操作を模倣することでAPIなしに同様の操作を可能にしています(ただし、現時点では精度や機能に制約がありますが)。これは、テキストや音声などで操作指示ができるRPA(Robotic Process Automation:業務自動化)のような動作と言えます。
将来的には、同様の機能がスマートフォンに搭載されることで、ユーザーの操作を大幅に削減し、より使いやすい端末が開発される可能性も考えられます(ただし、セキュリティリスクへの対応は重要な課題となります)。
まとめ
以上のことから、生成AIアプリは、人とAIの思考的な距離を縮める属人機として進化する可能性があります。また端末のUIは、属人機の度合いにより変わり、場合によってはスマートフォン自体の形状も変えていく可能性があります。その変革の先に、ポストスマートフォンがあるのではないかと妄想しています。
さて、生成AIとポストスマートフォンに関して、後日談として少々追記させていただきます。

とある携帯電話のハカセ級の方とお話ししたときの話題です。ポストスマートフォンというか、生成AIに依って変化するスマートフォンの形状についてディスカッションしました。そのときに、二つ折りのスマートフォンの話が出ました。foldable(フォルダブル)と言われている、折り曲げることができるディスプレイが搭載されている端末です。通常は横開きなのですが、一部に昔ながらのガラケーさながら「縦開き」できる端末もあります。まさに二つ折りケータイの形状です。注目したのは、その畳んだときの形が、ディスプレイが正方形に近く、Rabbit r1のような形状に近くなっていたことです。今後Rabbit r1のUIが成功するならば、「開くとスマートフォン、閉じている間は生成AIのポストスマートフォン」などのような形状も出てくる可能性もあります。あくまでも、将来の可能性の一つだとしてですが。
最後に
3回にわたる本稿を最後までお読みいただき、ありがとうございました。もともとこの内容は、夏に幕張メッセで行われたインターロップの講演にて45分で説明させてもらったものです。講演内容をテキストに落とし込むにあたり、40分という時間制約の中で十分に伝えきれなかった部分を補足することも意図して執筆しました。今回執筆を通して、40分という時間で十分に伝えきれないような膨大な内容であったことを改めて認識しました。
現在の取り組み
株式会社KDDIテクノロジーでは、AndroidやiOSのアプリを中心に、生成AIやクラウドを用いた開発や、新しい技術を扱う仲閒を、積極的に募集しています。ともに開発やPMの仕事をしてみませんか?
興味ある方は是非こちらの採用ページからご相談ください。お待ち申し上げています。
→ https://recruit.kddi-tech.com/