背景や課題感
Google Analytics Standard版(以下GA)を使っているので、BigQueryにデータ連携ができない。(こちらを参照)
だが、GAのデータをBigQueryにためて、Lookerでビジュアライズしたい。
ゆくゆくは、トラッキングデータのorder_idを受注データベースのorder_idと紐づけて、より細かな分析を行なっていきたい。
この記事の想定対象者
技術よりのビジネスサイドの方。
分析基盤を構築したいと考えているが、どういう構成したらいいのかお悩みの方。
Google Cloud Platform(以下GCP)を利用して、手軽に始めたいとお考えの方。
または、それに準じる方。
あとは、ビジネスサイドとエンジニアサイドの橋渡しになるような記事になればと考えています。
前提条件
- Google Analytics Standard版を利用
- Web SiteはSPA( Single Page Application )
ざっくりな構成図
簡単にまとめると以下の流れになります。
- Web Site からイベントデータをGAに送信する
- Reporting APIを利用して、GAからデータを引っ張ってくる
- 引っ張ってきたデータをBigQueryにロードする
- GA取得&BigQueryロードの日次バッチ処理
- BigQueryにためたデータをLookerで結合し、分析用の派生テーブルを作成する
- Dashbordを作るもよし、アドホック分析をしてもよし、データを料理し放題
それでは各フェーズを細かく説明していきます。
1. Web Site からイベントデータをGAに送信する
以下の流れにそって説明します。
- イベントデータの概念
- イベントデータの定義
- イベントデータ送信処理の設計・実装
イベントデータを送信する前に、「何を送信するのか?」を定義する必要があります。
ただ、その前にトラッキングのイベントデータの概念を理解する必要があります。
イベントデータの概念
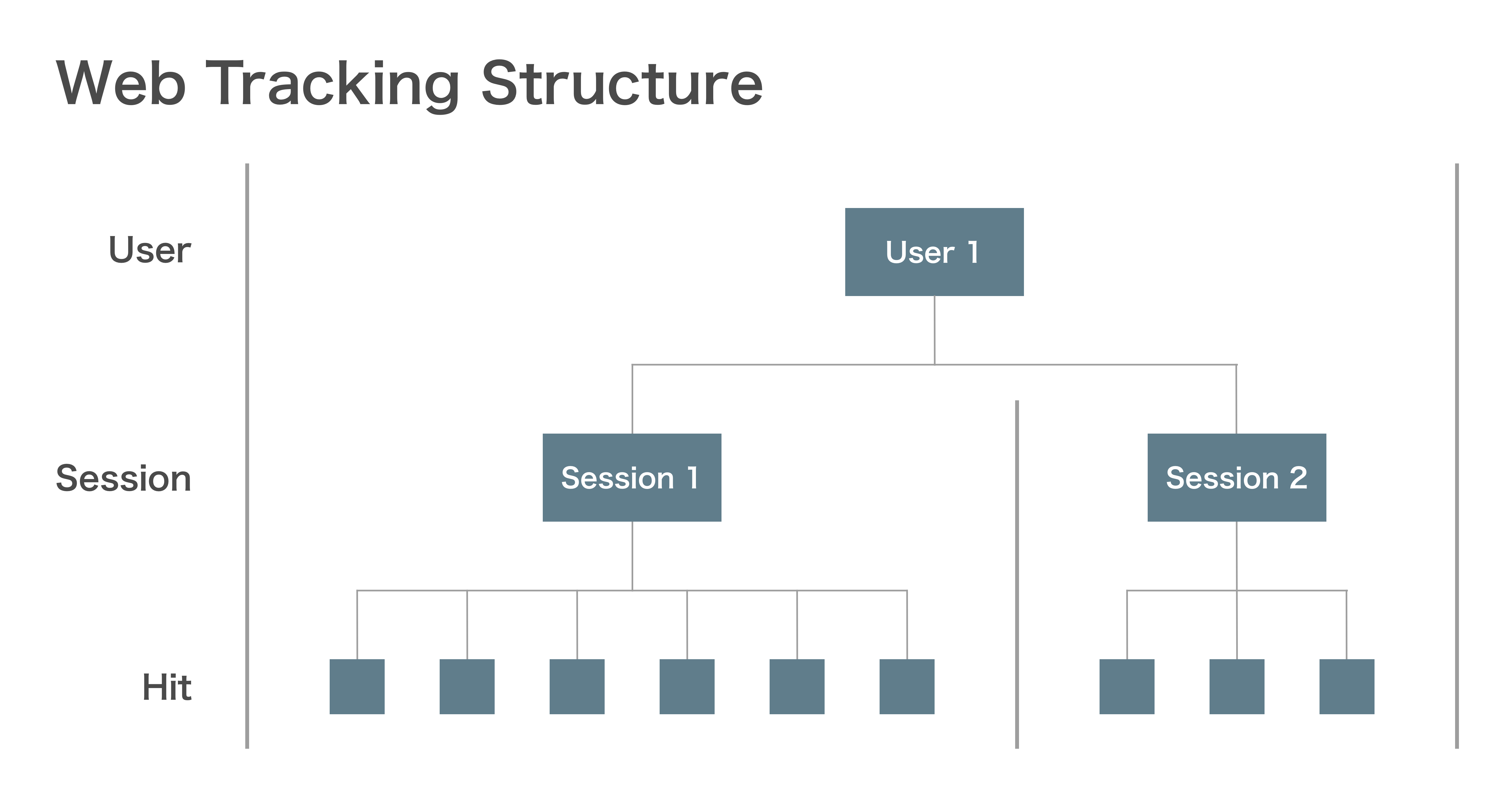
ユーザー User は様々なデバイスを用いて、Web SiteやAppsに訪問 Session し、様々な行動 Hit をしています。
例えば…
- 通勤中は電車の中からスマホで
- 勤務中は、デスクトップPCで
などです。
上記の概念を元に、どのデータが必要なのかを定義していきます。
イベントデータの定義からGA実装まで
イベントデータの定義については、以下のデータが必要になります。(詳細は別記事にする予定)
いずれもGAの標準のディメンションに存在していないので、カスタムディメンションを作成する必要があります。
また、下記以外のディメンションについては、GAから引っ張ってこられるので詳細は Reporting APIのリファレンスを参照し、適時決定していきます。
| # | ディメンション名 | 説明 | 参考例 |
|---|---|---|---|
| 1 | hit_id | トラッキングデータをRAWデータとして扱うためのID 各ヒットととりまとめるために必要 timestampとuser_idもしくはclient_idと組み合わせることで一意とする |
timestamp + ( user_id or cliend_id ) |
| 2 | user_id | 各サービスで利用しているユーザーID クロスデバイストラッキングで必要 ない場合は、cliend_idで代用(ただし、クロスデバイストラッキングはできない) |
|
| 3 | client_id | GAでブラウザごとに吐き出されるID session_idを作成するときに必要 |
Cookieに保存されている「_ga」を取得、送信する |
| 4 | datetime | GAだと秒のディメンションがないので、ヒットのタイミングでGAに送るように仕込んでおくと何かと便利 |
yyyy-MM-dd HH:mm:ss を取得し、送信する |
| 5 | session_sequence_number | 各セッションにおける処理順番号 DWH上でシーケンス番号の処理をしてもいいが、ヒットのタイミングでシーケンスナンバーを送るように仕込んでおくと、DWHのリソースを食わなくていい(データが大量になるほど) ただ、GAの仕組み上、クライアントサイドに依存する仕組みなので、データの品質やDWHのリソース等のトレードオフで、DWH側で処理する判断をしても良い |
Cookieで処理をする |
| 6 | order_id | 注文時に発行されるID |
※ ちなみに、GAから引っ張ってこられるディメンションは、ほぼ全て引っ張ってきています。
イベントデータ送信処理の設計・実装
弊社では、Web SiteがSPA(Single Page Application)で構築されている想定で送信処理を設計・実装していきます。
また、gtag.jsを利用しているので、そちらをカスタマイズする方針で設計・実装をしています。
実装の大まかな流れ
- GAで、カスタムディメンションを作成(作成するディメンションは上記表の通り)
- gtag.jsで、カスタムディメンションをGAに送信できるようにコードをカスタマイズ
- Googleタグマネージャーで、発火タイミングの調整
1. GAで、カスタムディメンションを作成
作成するカスタムディメンションは以下の通り。
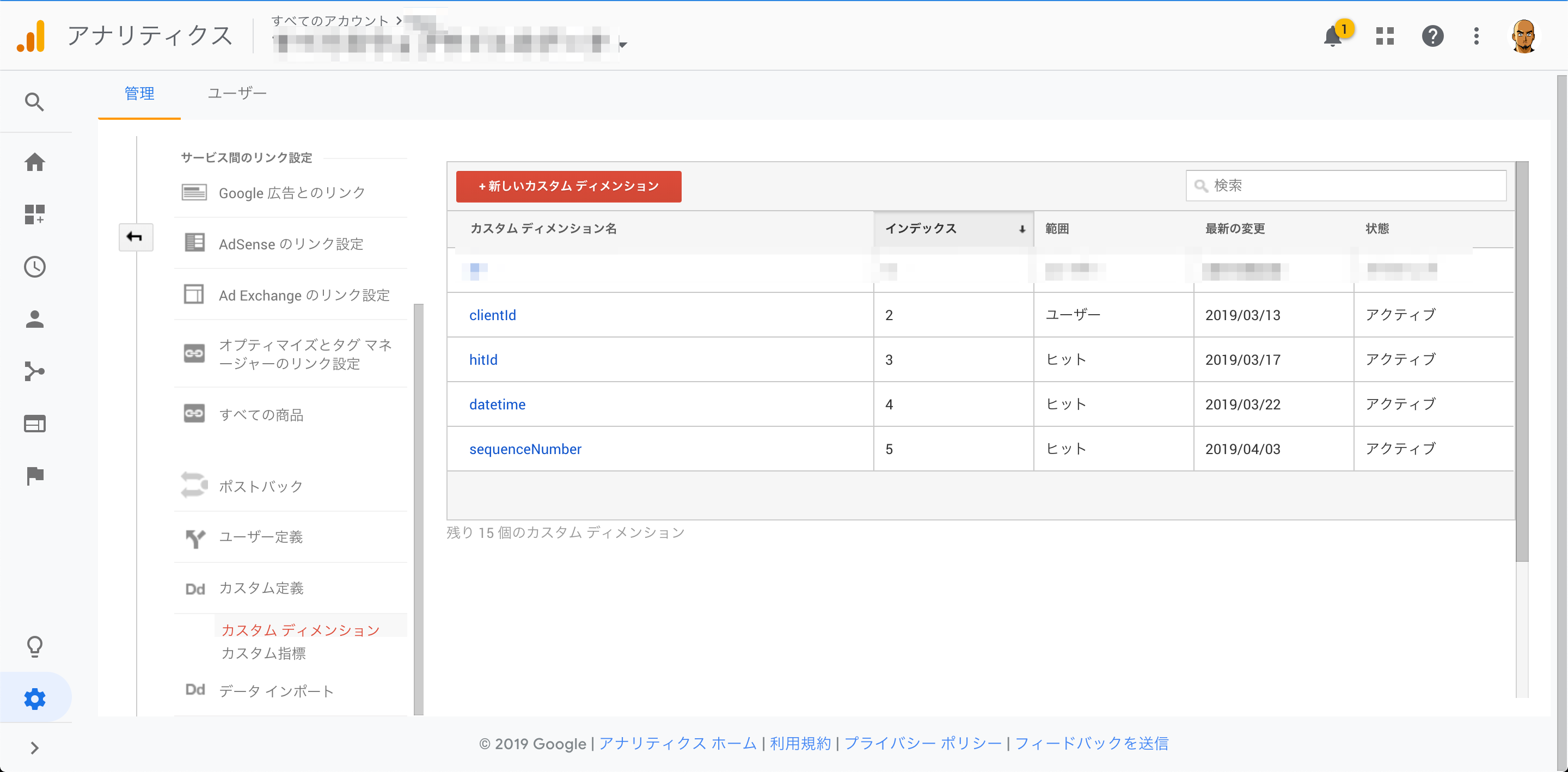
| # | カスタムディメンション名 | 範囲 |
|---|---|---|
| 1 | hitId | ヒット |
| 3 | clientId | ユーザー |
| 4 | datetime | ヒット |
| 5 | sessionNumber | ヒット |
| 6 | order_id | ヒット |
インデックスはのちに使います。
2. gtag.jsで、カスタムディメンションをGAに送信するコード
ここで、上記のカスタムディメンションの他に page_title と page_path をイベントが起きた際にURLのハッシュ以降を取得してGAに送信できるようにもする必要があります。
Googleタグマネージャーとの複合技になるので、ここでは説明は割愛しますが、別途説明ページを設ける予定です。 -> Google Analyticsのgtag.js(カスタムディメンション)とGoogleタグマネージャーで、SPA(Single Page Application)のWebSiteをトラッキングできるようにするを作成しましたので、参考にしていただければと思います。
3. Googleタグマネージャーで、タグの発火タイミングの調整
こちらについても別ページに説明を設ける予定です。
いずれにしてもSPAのタグ発火タイミングはGoogleタグマネージャーを利用します。
イベントデータまとめ
以上で、イベントデータの定義からGA実装までの流れです。
2. Reporting APIを利用して、GAからデータを引っ張ってくる
GAからデータを引っ張ってくるには、Reporting APIを利用するのですが、有効化しないと使えません。
以下の流れにそって説明します。
Reporting API利用の事前準備
- Reporting APIを利用するためにGCPのプロジェクトを作成
- Reporting APIの有効化
- GCPサービスアカウントの作成
- サービスアカウントのJSON形式の認証キーをダウンロード
- サービスアカウントをGAに登録
インスタンスの用意・環境構築
- GCPで作成したプロジェクト配下で、インスタンスを立ち上げる
- 立ち上げたインスタンスに以下をインストール
- Node.js
- @google-cloud/datastore
- @google-cloud/storage
- gcloudコマンドラインツール
- サービスアカウントで作成したJSON形式の認証キーをインスタンスにアップロード
BigQueryの用意
- GAのデータをためておくBigQueryを用意
実装
- Reporting APIからデータを引っ張る処理の実装
それでは、詳細の説明に入ります。
API利用の事前準備
1. Reporting APIを利用するためにGCPのプロジェクトを作成
まずは、GCPでプロジェクトを持っていない場合はプロジェクトを作成します。
もしくは、プロジェクトをすでに持っていて、そのプロジェクトは以下の環境を利用する場合は、次の Reporting APIの有効化 に進んでください。
インスタンス、BigQueryを作成するための元となるプロジェクトです。
GCPにアクセスし、プロジェクトを作成します。


これでGCPにプロジェクトが作成されます。
2. Reporting APIの有効化
次に、 Reporting API を有効化します。
GCPのAPIとサービスにアクセスします。


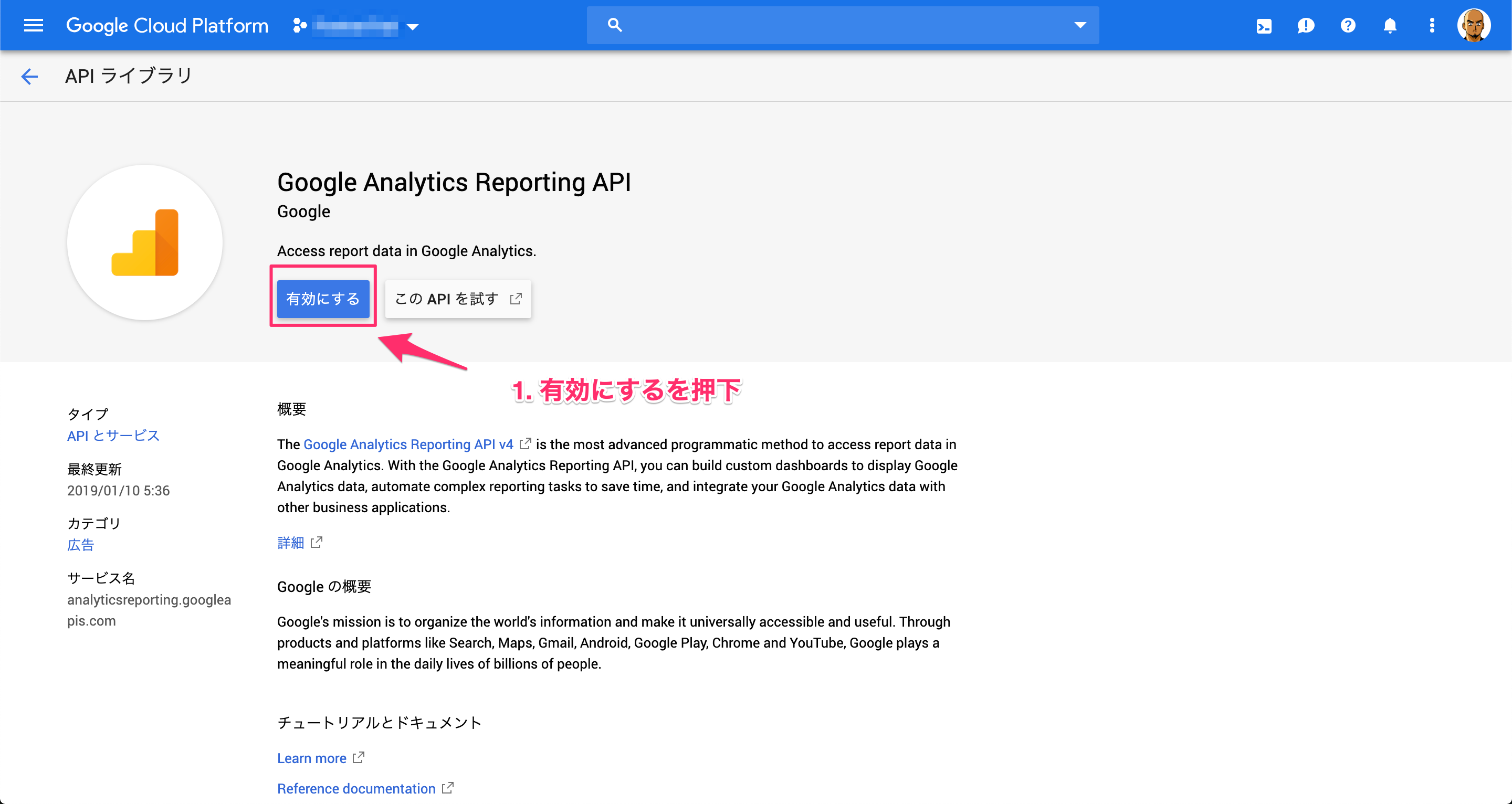

Reporting API が有効化されました。
3. GCPサービスアカウントの作成
Reporting APIを利用するサービスアカウントを作成します。
サービスアカウントからAPIにアクセスします。



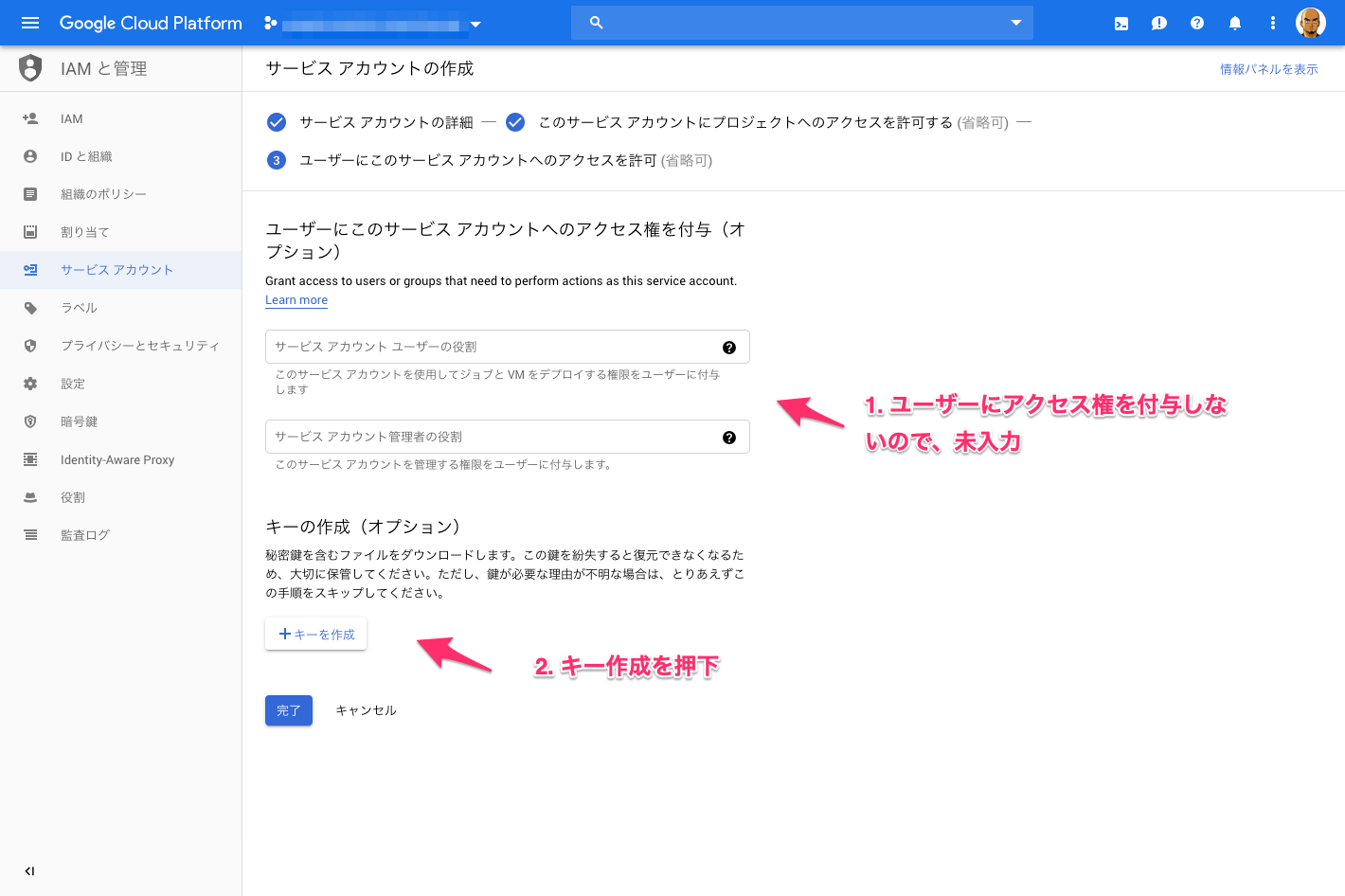
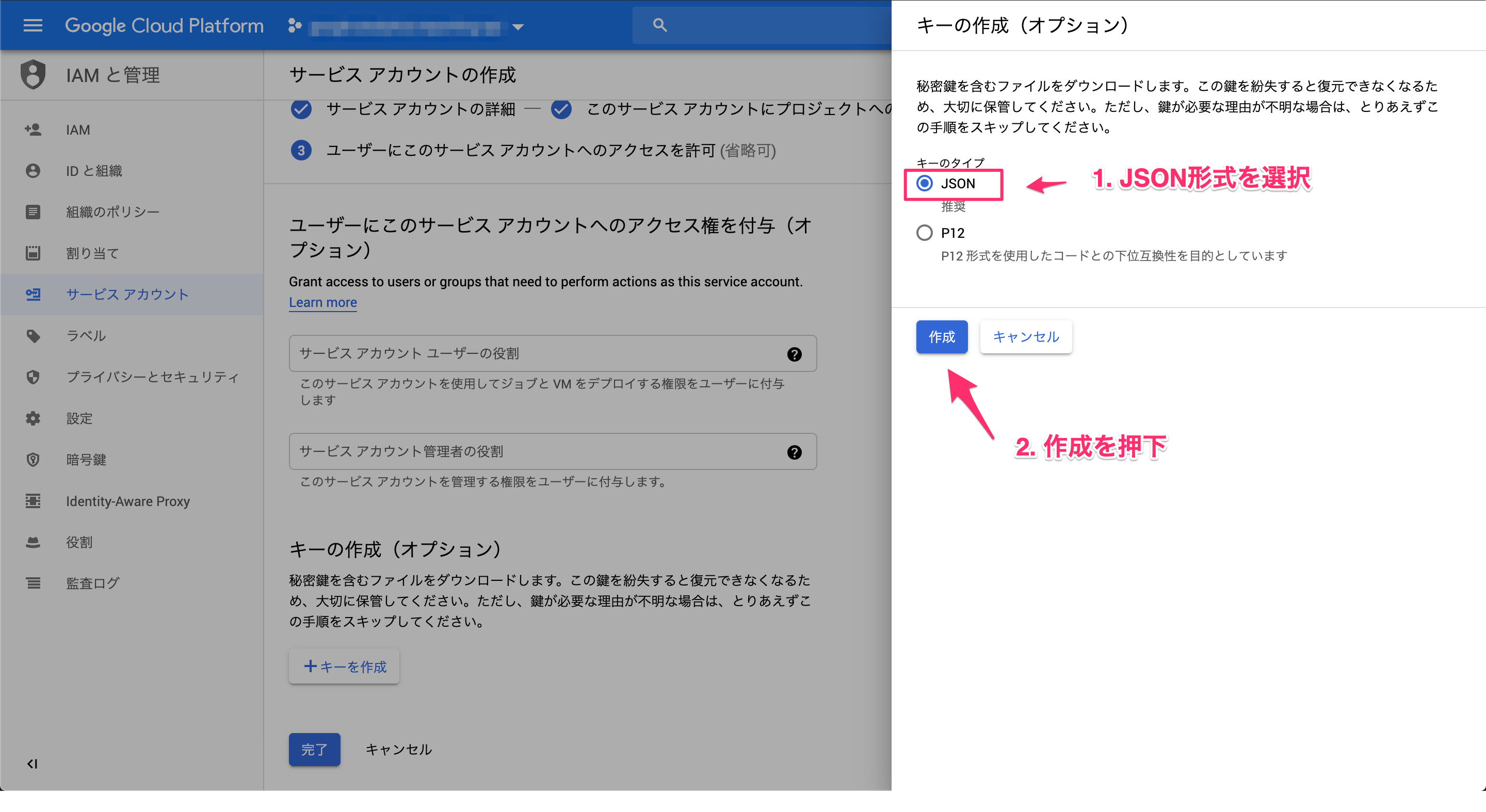
4. サービスアカウントのJSON形式の認証キーをダウンロード
3の手順でJSON形式の認証キーは自動的にダウンロードされます。
大切に保管します。

5. サービスアカウントをGAに登録
作成したサービスアカウントをGAに登録をしておきます。
これをしておかないと、APIを投げた時に弾かれてしまいます。
GAにアクセスします。
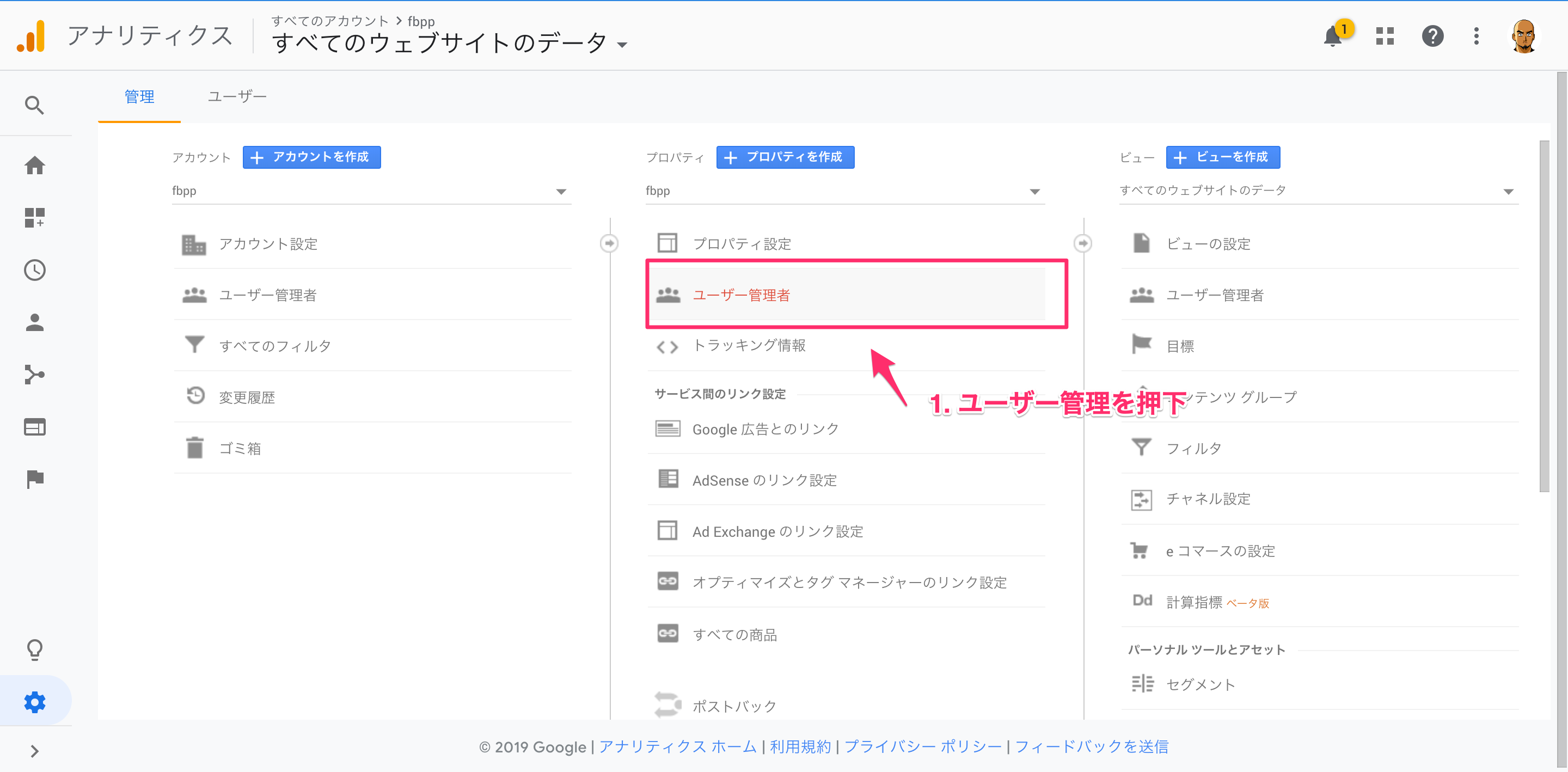
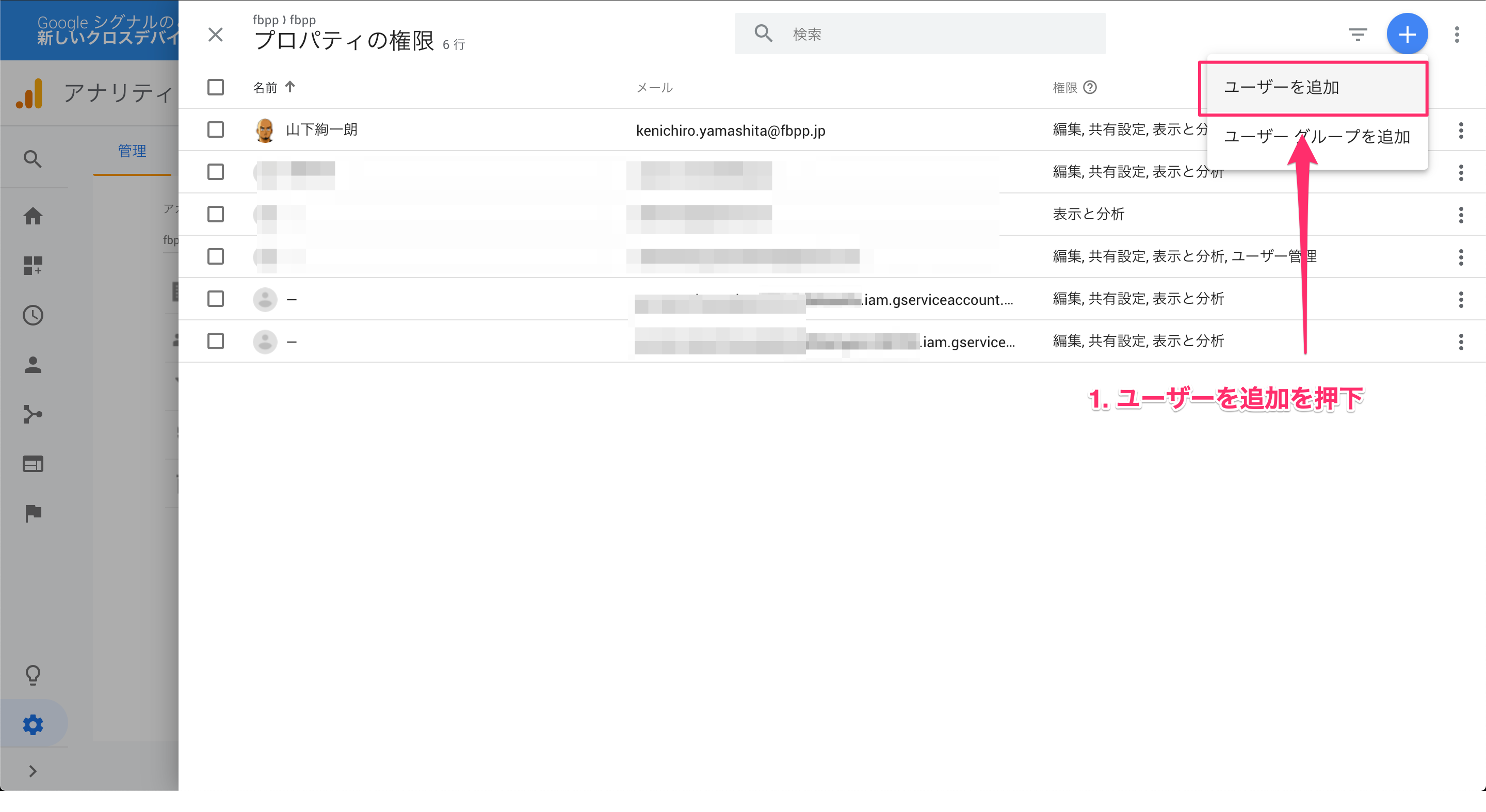

以上で、GAにサービスアカウントを登録できます。
インスタンスの用意・環境構築
Reporting API からデータを取得し、BigQueryにロードするための環境を構築します。
日次バッチ処理でデータを引っ張ってきます。
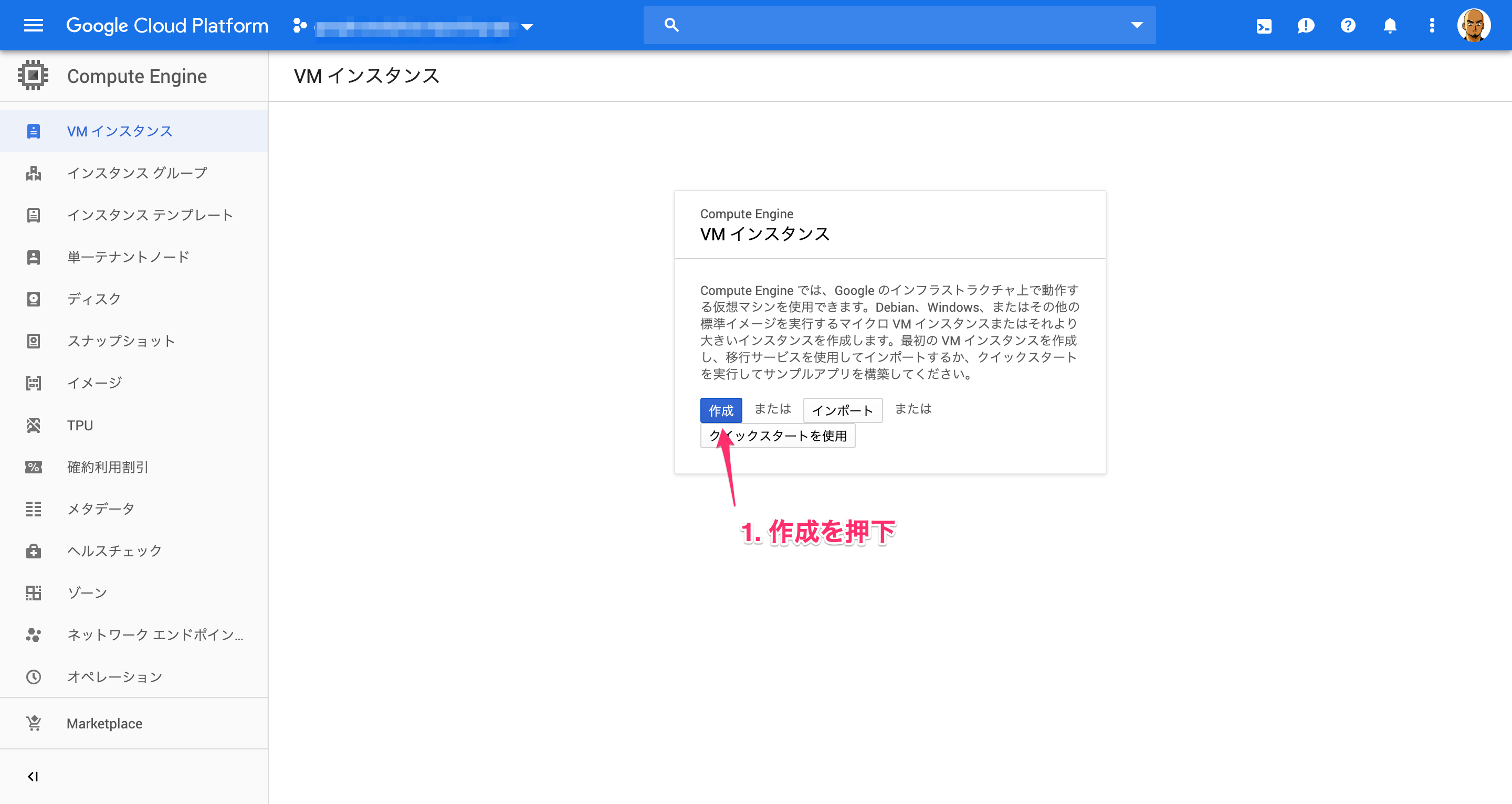
1. GCPで作成したプロジェクト配下で、インスタンスを立ち上げる
GCP Compute Engineにアクセスします。
以下はCompute Engineでインスタンスを立ち上げたことがない状態のコンソールです。
インスタンスを作成していきます。
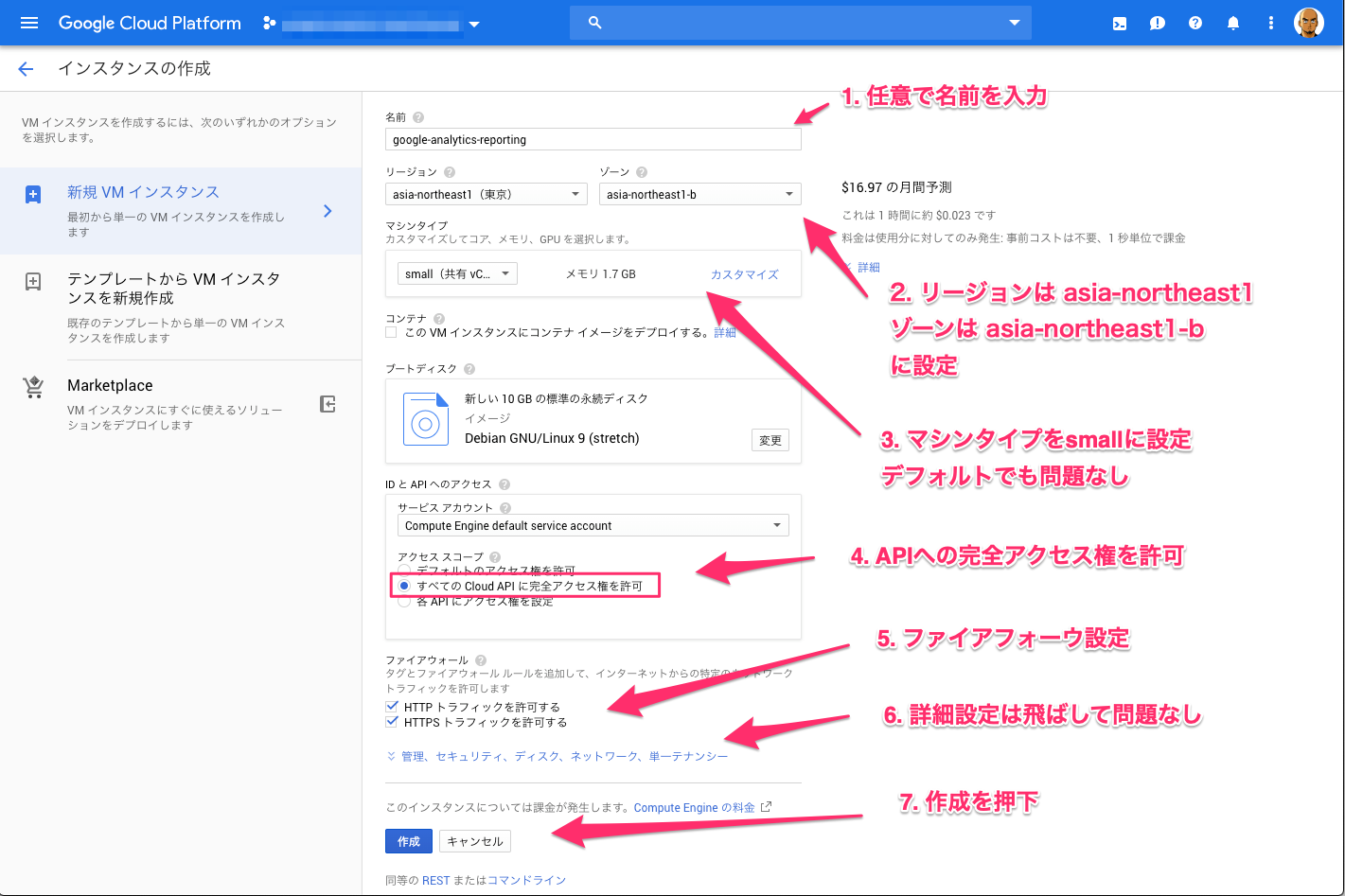
インスタンスが作成されました。
2. 立ち上げたインスタンスに以下をインストール
それでは、環境を作っていきます。
手順としては以下です。
- aptをアップグレードし、gitなどをインストール
- nvmをインストール
- node.jsをインストール
- npmを初期化
-
googleapis@google-cloud/storage@google-cloud/datastoreをインストール -
gcloudコマンドラインツールをインストール
まずは、作成したインスタンスにSSH接続を行います。

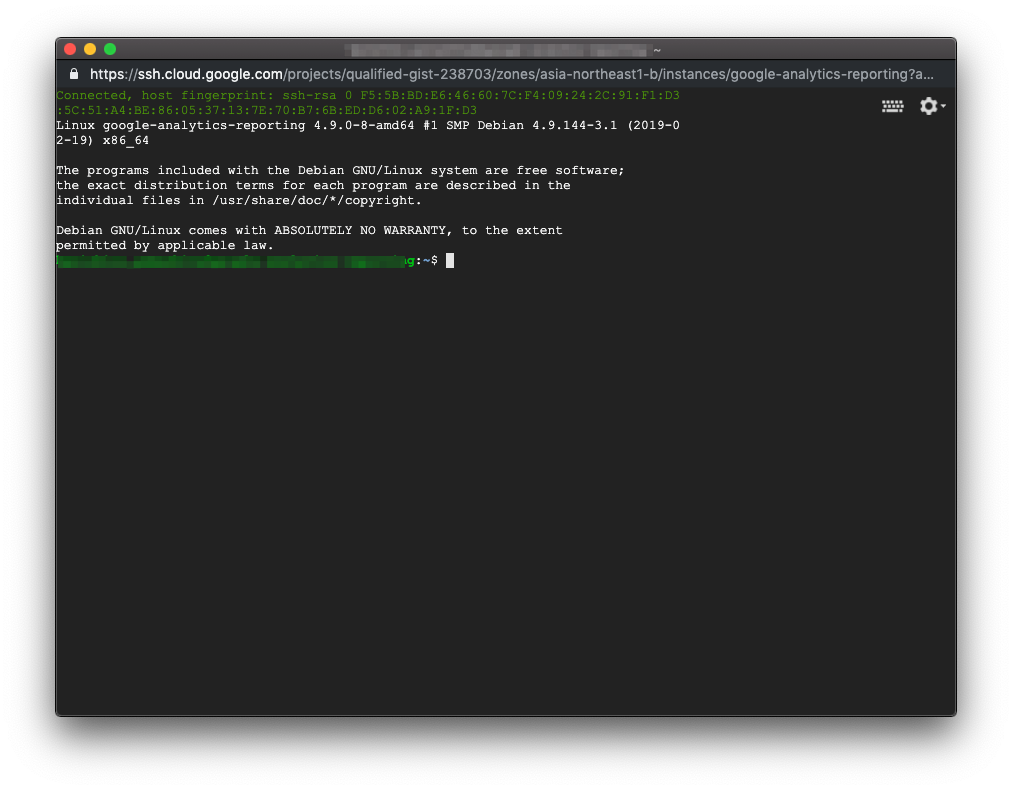
接続できました。
1. aptをアップグレードし、gitなどをインストール
以下を実行します。
sudo apt update
sudo apt upgrade
sudo apt install build-essential curl git m4 ruby texinfo libbz2-dev libcurl4-openssl-dev libexpat-dev libncurses-dev zlib1g-dev gettext apache2
2. nvmをインストール
以下を実行します。
curl -o- https://raw.githubusercontent.com/creationix/nvm/v0.34.0/install.sh | bash
実行後、以下を実行します。
export NVM_DIR="$HOME/.nvm"
[ -s "$NVM_DIR/nvm.sh" ] && \. "$NVM_DIR/nvm.sh" # This loads nvm
[ -s "$NVM_DIR/bash_completion" ] && \. "$NVM_DIR/bash_completion" # This loads nvm bash_completion
3. Node.jsをインストール
以下を実行します。
# インストール一覧を確認
nvm ls-remote
# v6.9.0をインストールする
nvm install v6.9.0
# v6.9.0をdefaultにする
nvm alias default v6.9.0
v6.9.0 をインストールする理由は、最新の安定バージョンを使うと、 @google-cloud/storage をインストールできないからです。
ソースはこちらをご確認ください。
4. npmを初期化
以下を実行します。
# npm初期化しpackage.jsonの中身は適当の設定しておく
npm init
5. googleapis @google-cloud/storage @google-cloud/datastore をインストール
以下を実行します。
npm install --save node-gyp
npm rebuild -save node-gyp
npm install -g node-pre-gyp
npm install --save googleapis
npm install --save @google-cloud/storage
npm install --save @google-cloud/datastore
6. gcloudコマンドラインツール をインストール
Google SDK -> 入門ガイド -> SDKのインストール -> apt-getの使用(DebianとUbuntuのみ)の手順通りインストールを行います。
以下、抜粋します。
# 正しく配布されるように、環境変数を作成します。
export CLOUD_SDK_REPO="cloud-sdk-$(lsb_release -c -s)"
# Google Cloud の公開鍵をインポートします
echo "deb http://packages.cloud.google.com/apt $CLOUD_SDK_REPO main" | sudo tee -a /etc/apt/sources.list.d/google-cloud-sdk.list
# Cloud SDK を更新してインストールします。
sudo apt update
sudo apt install google-cloud-sdk
3. サービスアカウントで作成したJSON形式の認証キーをインスタンスにアップロード
先ほどの手順で用意したJSON形式の認証キーをインスタンスにアップロードします。
前提として、アップロードするローカルPCにも gcloudコマンドラインツール をインストールしている必要があります。
詳細は、Cloud SDKを参照してください。
アップロードはgcloud compute scpで可能です。
# コード
gcloud compute scp --recurse [LOCAL_FILE_PATH] [INSTANCE_NAME]:~/
# 参考例
gcloud compute scp --recurse /Users/kenichiroyamashita/Downloads/reporting/ google-analytics-reporting:/home/kenichiro_yamashita/google-analytics/
BigQueryの用意
1. GAのデータをためておくBigQueryを用意
データをためておく側のBigQueryを用意します。
BigQueryにアクセスします。

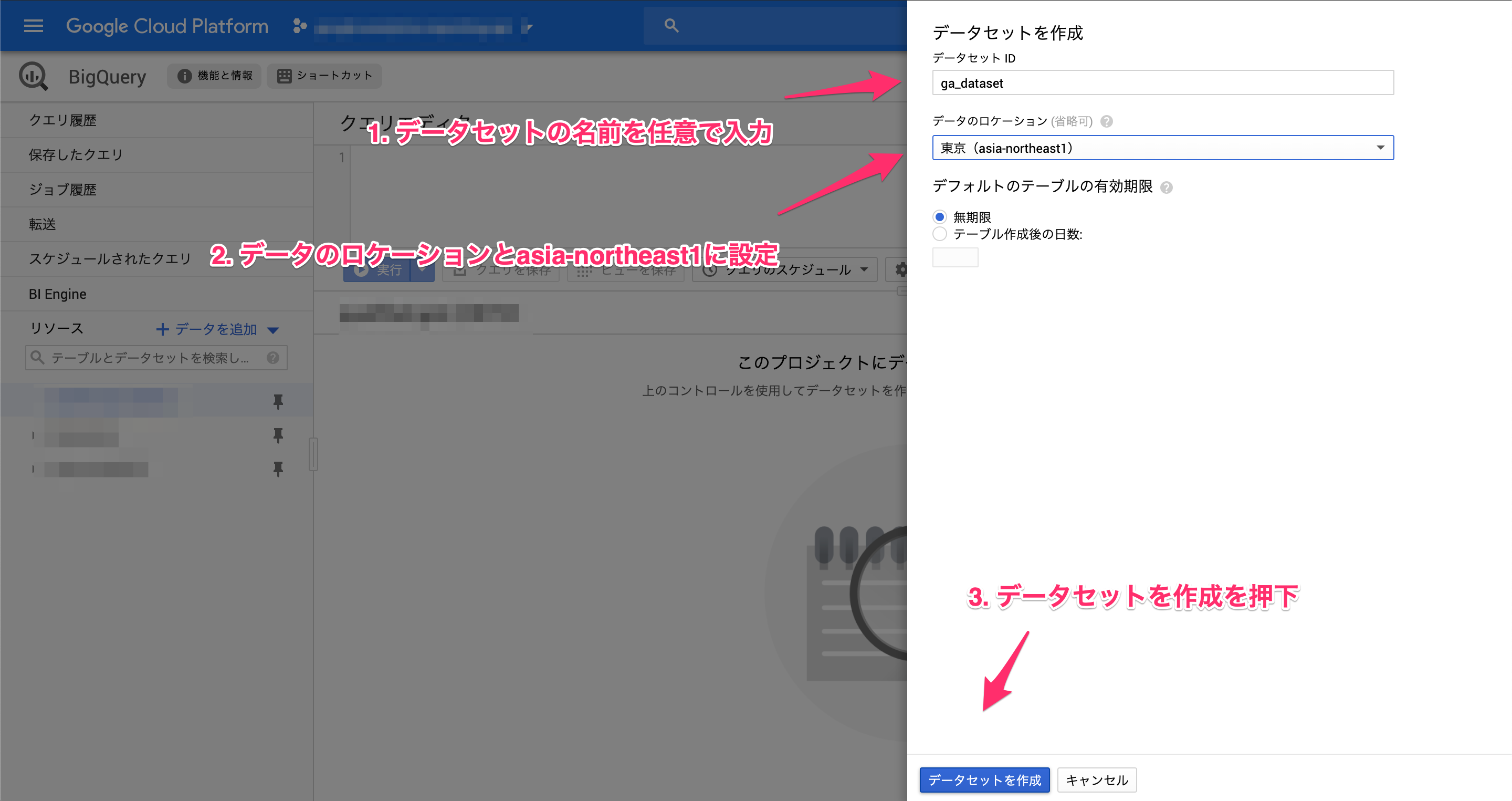
GAをためておくデータセットが作成されました。
実装
1. Reporting APIからデータを引っ張る処理の実装
さて、いよいよ実装です。
Node.jsを利用します。
以下、手順です。
- Node.jsのバージョンを最新安定板に変更
- ディレクトリの用意 例 ->
~/{user_hame}/ga/reporting/ - 上記ディレクトリのパーミッションを変更
- ローカルで用意したファイルをインスタンスにアップロード
- 初回処理バッチを作成
1. Node.jsのバージョンを最新安定板に変更
環境構築した際に v6.9.0 出会ったNode.jsのバージョンを最新安定板に変更する。
これをしておかないと、 Reporting API からデータ取得するために async を使っているんですが、これが動かなくなります。
# インストール一覧を確認
nvm ls-remote
# 最新安定板をインストールする
nvm install stable
# 最新安定板をdefaultにする
nvm alias default stable
2. ディレクトリの用意 例 -> ~/{user_hame}/ga/reporting/
ディレクトリを用意します。
以下は一例です。
mkdir ga
cd ga
mkdir reporting
3. 上記ディレクトリのパーミッションを変更
パーミッションを変更しておかないと、ローカルからファイルをアップロードできません。
以下は一例です。
sudo chmod -R 777 ~/{user_name}/ga
4. ローカルで用意したファイルをインスタンスにアップロード
いよいよ、GAから Reporting API で引っ張ってくる実装になります。
コード例は以下になります。
こちらは、エクスチュア社のGoogle Analytics StandardのデータをBigQueryで分析するための力技を参考にさせていただきました。
権さん、その節はありがとうございました!
ファイル名は main_r_dimensions.js としました。
インスタンスへのアップロードは上記のJSON形式の認証キーをアップロードした手順を参考にしてください。
if (process.argv.length < 4) {
console.log('Usage: node main_r_dimensions.js dimensions YYYY-MM-DD YYYY-MM-DD');
process.exit(1);
}
let dname = process.argv[2];
let start = process.argv[3]; // 30daysAgoなど
let end = process.argv[4]; // yesterdayなど
const {google} = require('googleapis');
// Each API may support multiple version. With this sample, we're getting
// v3 of the blogger API, and using an API key to authenticate.
const analyticsreporting = google.analyticsreporting({
version: 'v4'
});
// 各種定義を行う
let apikey = require('./various-datasets-fdad08a1c355.json'); // Google API Consoleで設定したKeyを読み込む
let viewid = 'xxxxxxxxx'; // 取得したいGoogle AnalyticsのビューIDを設定する
let pagesize = 10000; // デフォルトは1000 10000
j = 1;
const client = new google.auth.JWT(
apikey.client_email,
null,
apikey.private_key,
// scope は以下を指定
['https://www.googleapis.com/auth/analytics'],
null
);
let runReport = async() => {
let res = await analyticsreporting.reports.batchGet({
resource: {
reportRequests: [{
"viewId": viewid,
"pageSize": pagesize,
"dateRanges": [{
"startDate": start,
"endDate": end
}],
"samplingLevel": "LARGE",
"dimensions": [{
"name": "ga:dimension3" // hit_idを設定したdimension{indexNo}を指定
},{
"name": dname
}],
"metrics": [{
"expression": "ga:hits"
}]
}]
},
auth: client
});
let d = res.data.reports[0].data.rows;
if(!res.data.reports[0].nextPageToken){
for(let i = 0; i < d.length; i++){
console.log(d[i].dimensions[0] + '\t' + d[i].dimensions[1]);
j++;
}
}else{
for(let i = 0; i < d.length; i++){
console.log(d[i].dimensions[0] + '\t' + d[i].dimensions[1]);
j++;
if(j == res.data.reports[0].nextPageToken){
nextPageToken = res.data.reports[0].nextPageToken;
client.authorize().then(c => runReportNextPage());
}
}
}
};
let runReportNextPage = async() => {
let res = await analyticsreporting.reports.batchGet({
resource: {
reportRequests: [{
"viewId": viewid,
"pageSize": pagesize,
"dateRanges": [{
"startDate": start,
"endDate": end
}],
"samplingLevel": "LARGE",
"dimensions": [{
"name": "ga:dimension3"
},{
"name": dname
}],
"metrics": [{
"expression": "ga:hits"
}],
"pageToken": nextPageToken
}]
},
auth: client
});
let d = res.data.reports[0].data.rows;
if(!res.data.reports[0].nextPageToken){
for(let i = 0; i < d.length; i++){
console.log(d[i].dimensions[0] + '\t' + d[i].dimensions[1]);
j++;
}
}else{
for(let i = 0; i < d.length; i++){
console.log(d[i].dimensions[0] + '\t' + d[i].dimensions[1]);
j++;
if(j == res.data.reports[0].nextPageToken){
nextPageToken = res.data.reports[0].nextPageToken;
client.authorize().then(c => runReportNextPage());
}
}
}
};
client.authorize().then(c => runReport());
コードについては、また別途記事にまとめたいと思います。
詳細説明は割愛します。
5. 初回処理バッチを作成
バッチ処理で、欲しいデータを全て取得してきます。
バッチ処理については以下です。
ファイル名を report_first.sh としました。
# !/bin/sh
today=`date "+%Y%m%d_%H%M%S"`
mkdir ${today}
# 初回取得条件を定義する
start="2019-03-01"
end="today"
# 初回取得を実行する
# get dimension
node main_r_dimensions.js ga:userType ${start} ${end} > ./${today}/ecommercega_userType.txt
node main_r_dimensions.js ga:sessionCount ${start} ${end} > ./${today}/ecommercega_sessionCount.txt
node main_r_dimensions.js ga:sessionDurationBucket ${start} ${end} > ./${today}/ecommercega_sessionDurationBucket.txt
node main_r_dimensions.js ga:fullReferrer ${start} ${end} > ./${today}/ecommercega_fullReferrer.txt
node main_r_dimensions.js ga:socialNetwork ${start} ${end} > ./${today}/ecommercega_socialNetwork.txt
node main_r_dimensions.js ga:browser ${start} ${end} > ./${today}/ecommercega_browser.txt
node main_r_dimensions.js ga:browserVersion ${start} ${end} > ./${today}/ecommercega_browserVersion.txt
node main_r_dimensions.js ga:operatingSystem ${start} ${end} > ./${today}/ecommercega_operatingSystem.txt
node main_r_dimensions.js ga:operatingSystemVersion ${start} ${end} > ./${today}/ecommercega_operatingSystemVersion.txt
node main_r_dimensions.js ga:mobileDeviceBranding ${start} ${end} > ./${today}/ecommercega_mobileDeviceBranding.txt
node main_r_dimensions.js ga:mobileDeviceModel ${start} ${end} > ./${today}/ecommercega_mobileDeviceModel.txt
node main_r_dimensions.js ga:mobileInputSelector ${start} ${end} > ./${today}/ecommercega_mobileInputSelector.txt
node main_r_dimensions.js ga:mobileDeviceInfo ${start} ${end} > ./${today}/ecommercega_mobileDeviceInfo.txt
node main_r_dimensions.js ga:mobileDeviceMarketingName ${start} ${end} > ./${today}/ecommercega_mobileDeviceMarketingName.txt
node main_r_dimensions.js ga:deviceCategory ${start} ${end} > ./${today}/ecommercega_deviceCategory.txt
node main_r_dimensions.js ga:browserSize ${start} ${end} > ./${today}/ecommercega_browserSize.txt
node main_r_dimensions.js ga:dataSource ${start} ${end} > ./${today}/ecommercega_dataSource.txt
node main_r_dimensions.js ga:latitude ${start} ${end} > ./${today}/ecommercega_latitude.txt
node main_r_dimensions.js ga:longitude ${start} ${end} > ./${today}/ecommercega_longitude.txt
node main_r_dimensions.js ga:pagePath ${start} ${end} > ./${today}/ecommercega_pagePath.txt
node main_r_dimensions.js ga:pageTitle ${start} ${end} > ./${today}/ecommercega_pageTitle.txt
node main_r_dimensions.js ga:exitPagePath ${start} ${end} > ./${today}/ecommercega_exitPagePath.txt
node main_r_dimensions.js ga:eventLabel ${start} ${end} > ./${today}/ecommercega_eventLabel.txt
node main_r_dimensions.js ga:dimension2 ${start} ${end} > ./${today}/ecommercega_dimension2.txt
node main_r_dimensions.js ga:dimension4 ${start} ${end} > ./${today}/ecommercega_dimension4.txt
node main_r_dimensions.js ga:dimension5 ${start} ${end} > ./${today}/ecommercega_dimension5.txt
node main_r_dimensions.js ga:channelGrouping ${start} ${end} > ./${today}/ecommercega_channelGrouping.txt
3. 引っ張ってきたデータをBigQueryにロードする
上記でひっぱてきたデータをBiqQueryにロードします。
ロードについてのリファレンスからもわかる通り、以下でロードが可能です。
# コード例
bq load --source_format=[FORMAT] [DATASET].[TABLE] [PATH_TO_SOURCE] [SCHEMA]
# 参考
bq load --replace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.{table_name} ./userType.txt hit_id:string,user_type:string
上記のGA取得タイミングで、BigQueryへとデータをロードする実装にします。
すると、BigQueryへのロード部分は以下になります。
# !/bin/sh
today=`date "+%Y%m%d_%H%M%S"`
mkdir ${today}
# 初回取得条件を定義する
start="2019-03-01"
# start="30daysAgo"
end="today"
# BigQueryへロード
bq load --replace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.user_type ./${today}/userType.txt hit_id:string,user_type:string
bq load --replace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.session_counts ./${today}/sessionCount.txt hit_id:string,session_counts:integer
bq load --replace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.session_duration_bucket ./${today}/sessionDurationBucket.txt hit_id:string,session_duration_bucket:integer
bq load --replace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.full_referrer ./${today}/fullReferrer.txt hit_id:string,full_referrer:string
bq load --replace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.social_network ./${today}/socialNetwork.txt hit_id:string,social_network:string
bq load --replace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.browsers ./${today}/browser.txt hit_id:string,browsers:string
bq load --replace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.browser_version ./${today}/browserVersion.txt hit_id:string,browser_version:string
bq load --replace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.operating_system ./${today}/operatingSystem.txt hit_id:string,operating_system:string
bq load --replace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.operating_system_version ./${today}/operatingSystemVersion.txt hit_id:string,operating_system_version:string
bq load --replace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.mobile_device_branding ./${today}/mobileDeviceBranding.txt hit_id:string,mobile_device_branding:string
bq load --replace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.mobile_device_model ./${today}/mobileDeviceModel.txt hit_id:string,mobile_device_model:string
bq load --replace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.mobileInput_selector ./${today}/mobileInputSelector.txt hit_id:string,mobileInput_selector:string
bq load --replace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.mobile_device_info ./${today}/mobileDeviceInfo.txt hit_id:string,mobile_device_info:string
bq load --replace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.mobile_device_marketing_names ./${today}/mobileDeviceMarketingName.txt hit_id:string,mobile_device_marketing_names:string
bq load --replace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.device_categories ./${today}/deviceCategory.txt hit_id:string,device_categories:string
bq load --replace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.browser_size ./${today}/browserSize.txt hit_id:string,browser_size:string
bq load --replace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.data_sources ./${today}/dataSource.txt hit_id:string,data_sources:string
bq load --replace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.latitude ./${today}/latitude.txt hit_id:string,latitude:float
bq load --replace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.longitude ./${today}/longitude.txt hit_id:string,longitude:float
bq load --replace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.page_path ./${today}/pagePath.txt hit_id:string,page_path:string
bq load --replace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.page_title ./${today}/pageTitle.txt hit_id:string,page_title:string
bq load --replace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.exit_page_path ./${today}/exitPagePath.txt hit_id:string,exit_page_path:string
bq load --replace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.event_labels ./${today}/eventLabel_output.txt hit_id:string,event_labels:string,order_id:integer
bq load --replace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.dimension2 ./${today}/dimension2.txt hit_id:string,dimension2:string
bq load --replace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.dimension4 ./${today}/dimension4.txt hit_id:string,dimension4:datetime
bq load --replace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.dimension5 ./${today}/dimension5.txt hit_id:string,dimension5:integer
bq load --replace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.channel_grouping ./${today}/channelGrouping.txt hit_id:string,channel_grouping:string
4. GA取得&BigQueryロードの日次バッチ処理
日次バッチ用のファイルを作成します。
ファイル名は report_daily.sh としました。
注意点としては以下。
- 初回ロードを
2daysAgoのデータとした - 初回の日次バッチを
yesterdayのデータとした - 後は日次(実行時間は1:05とする)でバッチを回すだけ
# !/bin/sh
today=`date "+%Y%m%d_%H%M%S"`
mkdir ${today}
# 初回取得条件を定義する
start="yesterday"
end="yesterday"
# 初回取得を実行する
# get dimension
node main_r_dimensions.js ga:userType ${start} ${end} > ./${today}/userType.txt
node main_r_dimensions.js ga:sessionCount ${start} ${end} > ./${today}/sessionCount.txt
node main_r_dimensions.js ga:sessionDurationBucket ${start} ${end} > ./${today}/sessionDurationBucket.txt
node main_r_dimensions.js ga:fullReferrer ${start} ${end} > ./${today}/fullReferrer.txt
node main_r_dimensions.js ga:socialNetwork ${start} ${end} > ./${today}/socialNetwork.txt
node main_r_dimensions.js ga:browser ${start} ${end} > ./${today}/browser.txt
node main_r_dimensions.js ga:browserVersion ${start} ${end} > ./${today}/browserVersion.txt
node main_r_dimensions.js ga:operatingSystem ${start} ${end} > ./${today}/operatingSystem.txt
node main_r_dimensions.js ga:operatingSystemVersion ${start} ${end} > ./${today}/operatingSystemVersion.txt
node main_r_dimensions.js ga:mobileDeviceBranding ${start} ${end} > ./${today}/mobileDeviceBranding.txt
node main_r_dimensions.js ga:mobileDeviceModel ${start} ${end} > ./${today}/mobileDeviceModel.txt
node main_r_dimensions.js ga:mobileInputSelector ${start} ${end} > ./${today}/mobileInputSelector.txt
node main_r_dimensions.js ga:mobileDeviceInfo ${start} ${end} > ./${today}/mobileDeviceInfo.txt
node main_r_dimensions.js ga:mobileDeviceMarketingName ${start} ${end} > ./${today}/mobileDeviceMarketingName.txt
node main_r_dimensions.js ga:deviceCategory ${start} ${end} > ./${today}/deviceCategory.txt
node main_r_dimensions.js ga:browserSize ${start} ${end} > ./${today}/browserSize.txt
node main_r_dimensions.js ga:dataSource ${start} ${end} > ./${today}/dataSource.txt
node main_r_dimensions.js ga:latitude ${start} ${end} > ./${today}/latitude.txt
node main_r_dimensions.js ga:longitude ${start} ${end} > ./${today}/longitude.txt
node main_r_dimensions.js ga:pagePath ${start} ${end} > ./${today}/pagePath.txt
node main_r_dimensions.js ga:pageTitle ${start} ${end} > ./${today}/pageTitle.txt
node main_r_dimensions.js ga:exitPagePath ${start} ${end} > ./${today}/exitPagePath.txt
node main_r_dimensions.js ga:eventLabel ${start} ${end} > ./${today}/eventLabel.txt
node main_r_dimensions.js ga:dimension2 ${start} ${end} > ./${today}/dimension2.txt
node main_r_dimensions.js ga:dimension4 ${start} ${end} > ./${today}/dimension4.txt
node main_r_dimensions.js ga:dimension5 ${start} ${end} > ./${today}/dimension5.txt
node main_r_dimensions.js ga:channelGrouping ${start} ${end} > ./${today}/channelGrouping.txt
# BigQueryに追加ロード
bq load --noreplace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.user_type ./${today}/userType.txt hit_id:string,user_type:string
bq load --noreplace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.session_counts ./${today}/sessionCount.txt hit_id:string,session_counts:integer
bq load --noreplace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.session_duration_bucket ./${today}/sessionDurationBucket.txt hit_id:string,session_duration_bucket:integer
bq load --noreplace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.full_referrer ./${today}/fullReferrer.txt hit_id:string,full_referrer:string
bq load --noreplace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.social_network ./${today}/socialNetwork.txt hit_id:string,social_network:string
bq load --noreplace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.browsers ./${today}/browser.txt hit_id:string,browsers:string
bq load --noreplace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.browser_version ./${today}/browserVersion.txt hit_id:string,browser_version:string
bq load --noreplace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.operating_system ./${today}/operatingSystem.txt hit_id:string,operating_system:string
bq load --noreplace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.operating_system_version ./${today}/operatingSystemVersion.txt hit_id:string,operating_system_version:string
bq load --noreplace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.mobile_device_branding ./${today}/mobileDeviceBranding.txt hit_id:string,mobile_device_branding:string
bq load --noreplace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.mobile_device_model ./${today}/mobileDeviceModel.txt hit_id:string,mobile_device_model:string
bq load --noreplace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.mobileInput_selector ./${today}/mobileInputSelector.txt hit_id:string,mobileInput_selector:string
bq load --noreplace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.mobile_device_info ./${today}/mobileDeviceInfo.txt hit_id:string,mobile_device_info:string
bq load --noreplace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.mobile_device_marketing_names ./${today}/mobileDeviceMarketingName.txt hit_id:string,mobile_device_marketing_names:string
bq load --noreplace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.device_categories ./${today}/deviceCategory.txt hit_id:string,device_categories:string
bq load --noreplace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.browser_size ./${today}/browserSize.txt hit_id:string,browser_size:string
bq load --noreplace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.data_sources ./${today}/dataSource.txt hit_id:string,data_sources:string
bq load --noreplace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.latitude ./${today}/latitude.txt hit_id:string,latitude:float
bq load --noreplace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.longitude ./${today}/longitude.txt hit_id:string,longitude:float
bq load --noreplace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.page_path ./${today}/pagePath.txt hit_id:string,page_path:string
bq load --noreplace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.page_title ./${today}/pageTitle.txt hit_id:string,page_title:string
bq load --noreplace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.exit_page_path ./${today}/exitPagePath.txt hit_id:string,exit_page_path:string
bq load --noreplace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.event_labels ./${today}/eventLabel_output.txt hit_id:string,event_labels:string,order_id:integer
bq load --noreplace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.dimension2 ./${today}/dimension2.txt hit_id:string,dimension2:string
bq load --noreplace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.dimension4 ./${today}/dimension4.txt hit_id:string,dimension4:datetime
bq load --noreplace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.dimension5 ./${today}/dimension5.txt hit_id:string,dimension5:integer
bq load --noreplace --source_format=CSV --field_delimiter="\t" {project_name}:{dataset_name}.channel_grouping ./${today}/channelGrouping.txt hit_id:string,channel_grouping:string
以上です。
これで、構築は一通り完了です。
ぜひ、試してみてください。
5. BigQueryにためたデータをLookerで結合し、分析用の派生テーブルを作成する
BigQueryにデータはたまっていくので、次にデータを結合し、分析用の派生テーブルを作っていくのですが、Looker以降に関しては別記事でまとめていこうと思います。
※流石に記事内容が長くなりすぎる…