この記事について
将来的に書く予定の「JavaFX で DynamoDB Viewer作ってみた」記事の1ステップ。
結構大きな話になると思うので、少しずつ技術ポイント毎に記事を書いて、ある一定程度の要件を満たせた段階で前述まとめ記事書く予定。
第一回記事:DynamoDBの情報を読み込んでJavaFXで表示してみる
第二回記事:JavaFXで動的にテーブル列を設定する
第三回記事:AWS java SDKでDynamoDBテーブル情報を取得してみる
第四回記事:JavaFX の TableView の選択範囲をクリップボードにコピーする。
第五回記事:JavaFX でコンポーネント作って動的生成してみる
※これまでの記事が基本になってます。メソッドなど細かい部分で再説明していない部分があります。不明点などありましたらコメントなど頂けたら対応しようと思います。
前提
AWS Java SDKは software.amazon.awssdk の2.15.64を使用
※SDKのバージョンや種類によって関数の有無があったりする様子
今回の追加機能
文字型、数値型以外のリスト型などのデータ型に対応。
現在の進捗

この時点でのソース(github) ※今回修正したソースファイル
まずは使用可能なデータ型把握
王道、オフィシャルページ「命名ルールおよびデータ型」を参照。カテゴリを整理すると以下の様になる
- スカラー型
- 文字型
- 数値型
- Bool型
- バイナリ型
- Null型
- ドキュメント型
- List型
- Map型
- セット型
- 文字列セット
- 数値セット
- バイナリセット
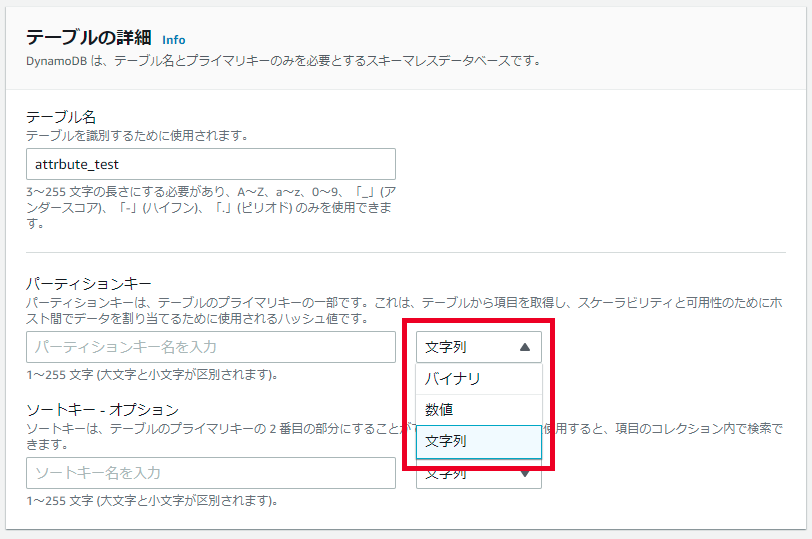
パーティションキーに使用可能な型
テーブル作成時の画面。文字列、数値、バイナリ型のみが使用可能な事が解る。
項目属性に使用可能な型
データを追加する時の画面。前述のデータ型全て使用な事が解る。
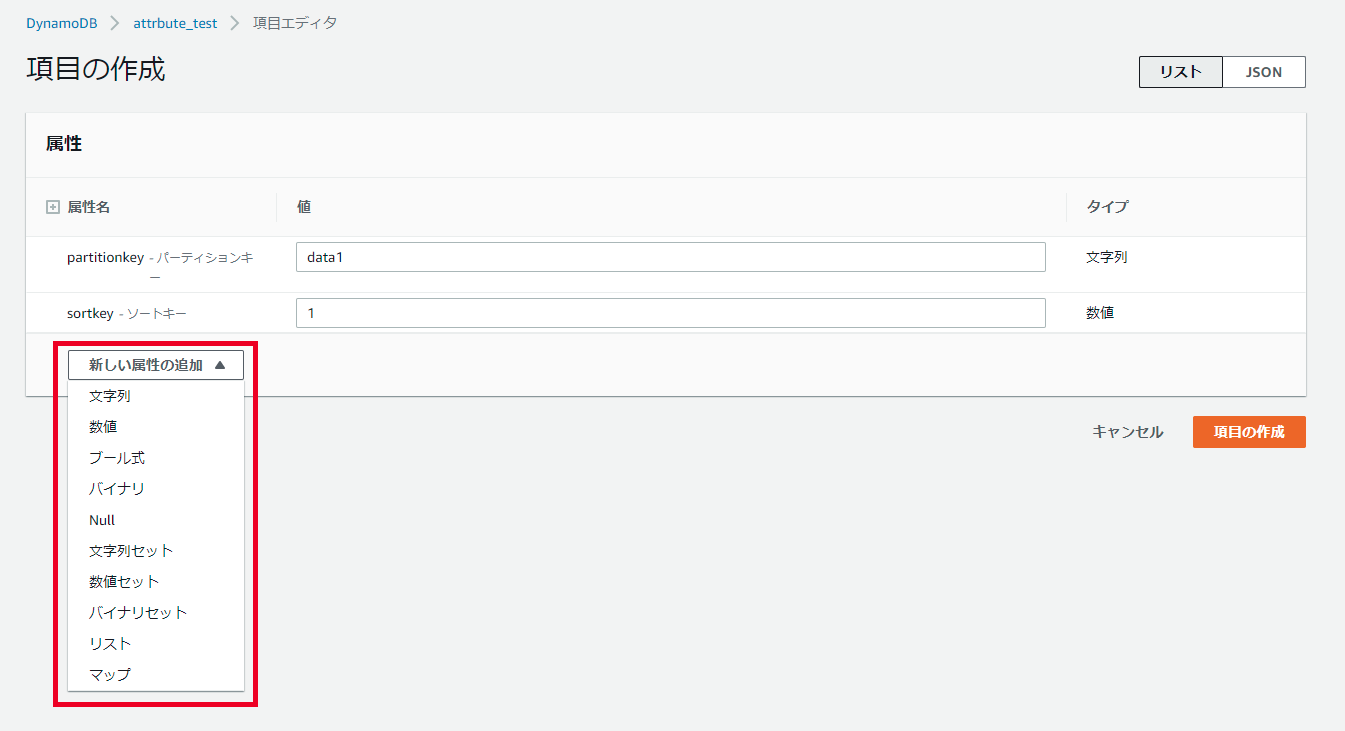
ちなみに、バイナリ型を画面から登録する時は、Base64型で文字列エンコードして登録する。
List型とセット型の違いは?
一見同じように見えるが、以下の違いがある様子。
- List型は順序付き。セット型の順序は保証されない
- List型はMapを含む複数のデータ型を登録可能。入れ子も可能。セット型の内部要素は対応するスカラー型1種類のみ
- セット型の内部要素値は、一意である必要あり(同じ値を2つ入れられない)
javaで例えると、セット型はEnumっぽい。ドキュメント型はListとMapによるJSONオブジェクトっぽい。
前者はそのレコードに紐づけられたタグとかを保持するのによさそう。後者は複雑な構造の情報を保持する時に使う感じ。
※コンソール画面でセット型に同一値を入れようとしてエラーになった画面

データ型の取得方法考察
プライマリキー属性
TableDescription -> attributeDefinitions -> attributeType() で ScalarAttributeType が取得可能。プライマリキー属性なので、スカラー型のみ。
公式ページサンプル
項目属性
QueryResponse/ScanResponse#items() にて、List<Map<String, AttributeValue>> 型の結果が取得できる。一つの項目は AttributeValueクラス。以下のメソッドがあり、項目の属性を判断できる。
- hasSs():文字列セット
- hasNs():数値セット
- hasBs():バイナリセット
- hasM():マップ型
- hasL():リスト型
それ以外のスカラー型を判断するメソッドは無さそう。
ScalarAttributeType
セット型やドキュメント型はスカラー型の集合。スカラー型をちゃんと把握する必要がある。
AWS JavaSDKの 公式ページ:Enum ScalarAttributeType を見る。S,N,B,UNKNOWN_TO_SDK_VERSION とある。Nullは無い。基本ScalarAttributeTypeはテーブル定義で使用するので、Null値は考慮されていないと思われる。
※参考:公式ページ:Amazon DynamoDB が DynamoDB テーブルの非キーの文字列およびバイナリ属性の空の値のサポートを開始
UNKNOWN_TO_SDK_VERSION は将来的にDynamoDB本体に新しいデータ型が来た時に古いSDK使ってる時の対応と思われ。
公式ページ:サポートされているデータの種類 からすると、日付は文字列、Boolean型は数値として扱われる様子。
BはバイナリなのかBooleanなのか迷うが、パーティションキーはBooleanは使用できない(というか数値の0/1)ので、バイナリと思われる。
動作確認用に全データ型を含むデータを登録
そのデータのjson形式表示
{
"partitionkey": {
"S": "data1"
},
"sortkey": {
"N": "1"
},
"col-number": {
"N": "5"
},
"col-null": {
"NULL": true
},
"col-numset": {
"NS": [
"0",
"2",
"1"
]
},
"co-map": {
"M": {
"map-num1": {
"N": "1.23456"
},
"map-null": {
"NULL": true
},
"map-str1": {
"S": "map-strdata"
}
}
},
"col-string1": {
"S": "string-attr"
},
"col-list": {
"L": [
{
"S": "list-str1"
},
{
"N": "0"
},
{
"BOOL": false
}
]
},
"col-bool": {
"BOOL": true
},
"col-binary": {
"BS": [
"YmluYXJ5MQ==",
"dGVzdA=="
]
},
"col-stringset": {
"SS": [
"strlist1",
"strlist2",
"strlist3"
]
}
}
項目属性はレコード毎にデータ型を変えられる!
プライマリキー(パーティションキー、ソートキー)は、項目名とデータ型は固定。しかし、項目属性は、同じ項目名でも異なるデータ型を設定する事が可能。
col-numberという名前の項目に、Null型や数値型が設定されていたり、col-string1という名前の横目に数値型や文字型を設定してAWSコンソール画面で見た所

なので、取得データには、各レコード毎にデータ型情報が存在する。MapやList型は内部要素のデータ型は統一しなくて良いので、それぞれの要素にデータ型が存在する事が解る。
# Null
AttributeValue(NUL=true)
# Bool
AttributeValue(BOOL=true)
# String set
AttributeValue(SS=[strlist1, strlist2, strlist3])
# Number Set
AttributeValue(NS=[0, 2, 1])
# Byte Set
AttributeValue(BS=[SdkBytes(bytes=0x62696e61727931), SdkBytes(bytes=0x74657374)])
# List
AttributeValue(L=[AttributeValue(S=list-str1), AttributeValue(N=0), AttributeValue(BOOL=false)])
# Map
AttributeValue(M={map-null=AttributeValue(NUL=true), map-num1=AttributeValue(N=1.23456), map-str1=AttributeValue(S=map-strdata)})
おまけ:複数データ型のグローバルセカンダリインデックス(GSI)は可能か?
属性名 col-string1 には数値型と文字型が存在する。こちらで実験。
実験1
条件:col-string1 をGSIのプライマリキーとして指定する時、文字型と指定。
予想:自分のイメージではグローバルセカンダリインデックスは別のDynamoDBテーブル作る様なものだと思っているので、エラーになる。
結果:作成成功してしまった。作成時 col-string1 を指定する時、文字型と指定してしまったから数値は文字として処理して成功したかも。
実験2
条件:col-string1 をGSIのプライマリキーとして指定する時、数値型と指定。
予想:さすがに文字列は数値化出来ないので失敗
結果:別のエラー
One or more parameter values were invalid: Attributes cannot be redefined. Please check that your attribute has the same type as previously defined. Existing schema: Schema:[SchemaElement: key{col-string1:S:HASH}] New schema: Schema:[SchemaElement: key{col-string1:N:HASH}]
実験1で作成した col-string1 を使用したGSIと整合性が取れてないというエラーっぽい。
また、このエラーから、GSIを作る時にはHASH化したデータを使用している事が解る。
実験2改
条件:実験1で作成したGSIを削除し、再度実験2
予想:実験2と同じ
結果:作成成功してしまった。
考察1:HASH化しているという事から、データをバイナリとして扱ってHASHしてるからGSIの作成自体は成功。
考察2:使う時には指定時のデータ型しか使えないので、GSI指定のデータ型以外のレコードは取得できない
試しに数値型で設定したGSIで文字列による検索してみる。
DynamoDbClient dbclient = DynamoDbClient.builder().region(Region.AP_NORTHEAST_1).build();
Map<String, Condition> keyConditions = new HashMap<String, Condition>();
keyConditions.put(
"col-string1",
Condition.builder()
.attributeValueList(AttributeValue.builder().n("string-attr").build())
.comparisonOperator(ComparisonOperator.EQ).build());
QueryRequest queryReq = QueryRequest.builder()
.tableName("attrbute_test")
.indexName("test-gsi")
.keyConditions(keyConditions).build();
QueryResponse response = dbclient.query(queryReq);
数値に変換できないというエラーに
software.amazon.awssdk.services.dynamodb.model.DynamoDbException: The parameter cannot be converted to a numeric value: string-attr (Service: DynamoDb, Status Code: 400, Request ID: SDQLAE4RPNSOFC3GIMDVQF1ILRVV4KQNSO5AEMVJF66Q9ASUAAJG, Extended Request ID: null)
・・以下略・・
キー指定部を文字列型でやってみたら、定義してある型と違うという想定通りのエラー。
※前述テストソースの.n("string-attr")を.s("string-attr")に変更
software.amazon.awssdk.services.dynamodb.model.DynamoDbException: One or more parameter values were invalid: Condition parameter type does not match schema type (Service: DynamoDb, Status Code: 400, Request ID: 1QSQLJHELVDR96N9S2J0BKPTUFVV4KQNSO5AEMVJF66Q9ASUAAJG, Extended Request ID: null)
この実験結果からの考察
数値型(例:123)で登録したつもりなのに文字列(例:'123')で登録した様なケースに注意する必要がある
※補足(2021-02-22追記)
別件で、このレコードを更新しようとしたらエラーが出た。やはりGSIを作成する時にはデータ型には注意すべし。
Caused by: software.amazon.awssdk.services.dynamodb.model.DynamoDbException: One or more parameter values were invalid: Type mismatch for Index Key col-string1 Expected: N Actual: S IndexName: test-gsi (Service: DynamoDb, Status Code: 400, Request ID: N0STUR7P0UC7JMV468G02JDE9JVV4KQNSO5AEMVJF66Q9ASUAAJG, Extended Request ID: null)
実装
今回は表示の対応。前述の検証結果を元に、AttributeValue(DynamoDBのデータ要素)を文字列化する関数は以下の様になった。
private String getAttrString(AttributeValue attrVal) {
if (attrVal == null) {
return "<noattr>";
} else if (attrVal.s() != null) {
return attrVal.s();
} else if (attrVal.n() != null) {
return attrVal.n();
} else if (attrVal.b() != null) {
return getBase64StringFromSdkBytes(attrVal.b());
} else if (attrVal.bool() != null) {
return attrVal.bool().toString();
} else if (attrVal.hasSs()) {
return attrVal.ss().toString();
} else if (attrVal.hasNs()) {
return attrVal.ns().toString();
} else if (attrVal.hasBs()) {
return attrVal.bs().stream()
.map(attr -> getBase64StringFromSdkBytes(attr))
.collect(Collectors.toList()).toString();
} else if (attrVal.hasM()) {
return attrVal.m().entrySet().stream()
.collect(Collectors.toMap(entry -> entry.getKey(), entry -> getAttrString(entry.getValue())))
.toString();
} else if (attrVal.hasL()) {
return attrVal.l().stream().map(attr -> getAttrString(attr)).collect(Collectors.toList()).toString();
} else if (isNullAttr(attrVal)) {
return "<null>";
}
return attrVal.toString();
}
private String getBase64StringFromSdkBytes(SdkBytes sdkByte) {
return Base64.getEncoder().encodeToString(sdkByte.asByteArray());
}
// work around of AttributeValue#nul()
private boolean isNullAttr(AttributeValue attrVal) {
String wkStr = attrVal.toString();
return wkStr.equals("AttributeValue(NUL=true)");
}
今回のポイント
- レコード毎に存在しない項目属性もあるので、表示データセットにはその分をセットする必要があった。
- AttributeValue#nul() はNull型か判断できそうだが、使用すると
NullPointerExceptionが出て使えなかった。今回はAttributeValue#toString().equals("AttributeValue(NUL=true)")で代用。 - レコード毎にデータ型が変わる可能性があるのでそのケアをする様にした(今までは最初のレコードの型で判断していた)。
次回予定
編集(更新)機能を付ける予定。
参考にさせて頂いたページ
公式ページ
サポートされているデータの種類
命名ルールおよびデータ型
式を使用する時の項目属性の指定
Enum ScalarAttributeType
Class AttributeValue
Amazon DynamoDB が DynamoDB テーブルの非キーの文字列およびバイナリ属性の空の値のサポートを開始