はじめに
この記事のターゲットは「文書要約やりたいけど、ゼロからサーベイするのはちょっとしんどい・・・」という人です。おそらく未来の自分ですね。これさえ読めば、2021年以降のサーベイだけでもランドスケープがぼんやりわかるぞ![]() ってなるように書きました。
ってなるように書きました。
記事は全3部の構成です。第一部では時系列順に文書要約というタスクの歴史を辿っていきます。第二部では、第一部でぱらぱらと出てきた知識を体系的にまとめます。最後に第三部において、実際に要約モデルを動かしてみたいと思います。手を動かさないと理解するのは難しいので。
それでは、まずは文書要約の歴史を追いかけてみましょう。
第1部 文書要約の歴史
前ニューラル時代 (2000以前〜2014) → 抽象型要約の登場 (2015) → 抽象型要約の発展 (2016〜2018) → BERTの登場、そして抽出型要約の再流行 (2019) → BERTを超えたPre-trainingへ (2020) という流れで紹介します。
1.1. 前ニューラル時代 (2000以前~2014)
コンピュータによる文書要約 (Text Summarization) の起源は、20世紀にまで遡ります。2000年頃からぽつぽつ現代でも引用されることのある論文が現れますが、90年代後半にはInderjeet Mani等が既に活躍しています(Maniの著書『自動要約』(訳:奥村先生) は、文書要約について体系的にまとめられた数少ない書籍です)。
この時代にはブラックボックスな割にやたらと精度の高いニューラル言語モデルが登場していなかったので、様々な角度から文書要約に対する取り組みが行われました。
たとえば [Knight and Marcu, AAAI-2000] では文を構文解析して木構造で表し、重要な構造だけを圧縮する手法が提案されました。他には、テキストをグラフ構造で表現し、その関係を元に要約する TextRank [Mihalcea and Tarau, EMNLP-2004] が有名です(下図にTextRankのグラフの例を示します)。ちょうどこの辺りでトピックモデルが世に出てきたので、トピックベースのアプローチ [Ozsoy el al., 2011] も考案されました。
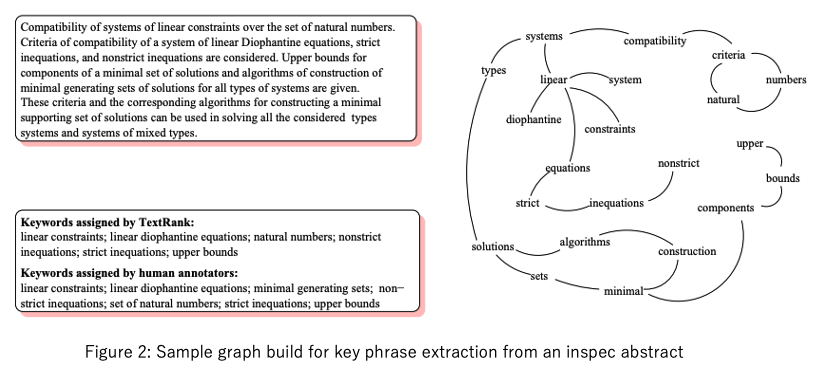
また、タスクの基礎が固まっていなかったので、解きたい問題やその評価方法についても試行錯誤が行われました。ヘッドライン生成 [Banko et al., ACL-2000] や、入力文書とクエリから要約を行うクエリフォーカス要約 [Tombros and Sanderson, 1998] などは、通常の文書要約とは違う問題に焦点を当てたタスクです。また、ROUGE [Lin, ACL-2004] は要約の自動評価指標であり、現代でも頻繁に使用される重要なものです。
1.2. 抽象型要約の登場 (2015)
これまでの文書要約は、基本的に入力文書から文字列を抜き出すアプローチが取られていました。これを抽出型要約と呼びます。一方、ニューラル言語モデル、とりわけEncoder-Decoderモデル[Sutskever et al., NIPS-2014]の登場により、入力側にない情報を出力側に出すことが可能となりました。そこで登場したのが、入力文書を与えてエンコードした後、要約文を生成する抽象型要約です。
抽象型要約の先鋒は[Rush et al., EMNLP-2015]による、Attention-Based Sequence-to-Sequence[Baudanau et al., ICLR-2015]を元にしたニューラル要約モデルです。既にAttentionが登場しているあたり、ニューラル翻訳の勢いは著しいですね。
[Rush et al., EMNLP-2015]の実験で、彼らのモデルはROUGEスコアにおいて既存のあらゆる手法を蹴散らしました。またデータの面でも、今なお広く使われるCNN/DailyMail Dataset [Hermann et al., NIPS-2015]が公開され、タスクの整備が進みました。
1.3. 抽象型要約の発展 (2016〜2018)
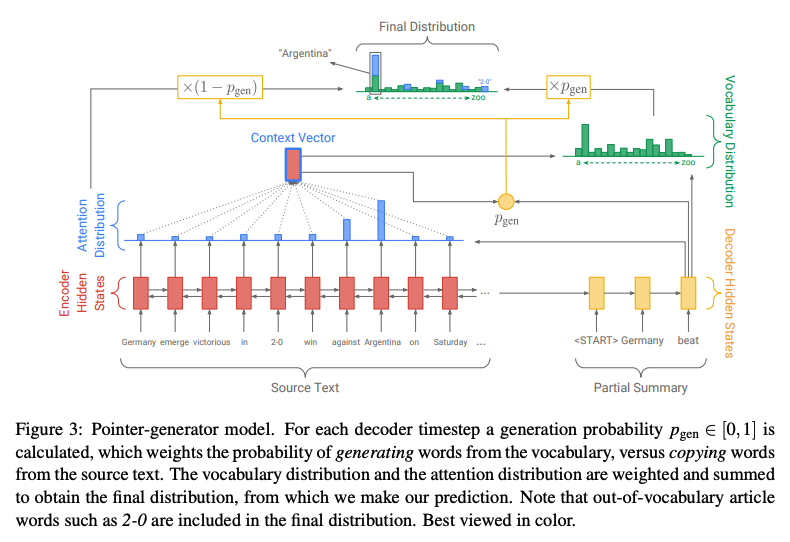
抽象型要約の登場は衝撃的でしたが、一方で抽出型要約にはない弱点が多く見受けられました。その最たるものは、不要な情報を多く生成してしまうことです。軽度なものでは冗長な文を生成してしまったり、重度なものでは矛盾する情報を生成してしまいます。この問題は[Suzuki and Nagata, 2016]やPointer-Generator Networks[See et al., ACL-2017]により取り組まれ、入力文書の単語をそのまま要約として出力する等の工夫がなされることで対策されていきました。
また、他の分野でTransformer [Vaswani et al., NIPS-2017]、階層型Sequence-to-Sequenceといった様々なモデルが生まれたこともあり、Attentionの当て方について議論されたり、複雑なネットワークを構築するタイプの論文が多く採択されました。[Celikyilmaz et al., NAACL-2018]では段落毎に複数のエンコーダに投入し、Source-to-Target Attentionで各段落の情報を統合するマルチエンコーダモデルが提案されました。さらに[Gehrmann et al., EMNLP-2018]では、Pointer-Generator NetworksのAttentionが当たる範囲を制限したBottom-Up Attentionが考案されました。
このように、抽象型要約の弱点を解消するようにモデルを複雑化させていったことが、この時代の特徴です。
モデルが複雑になるたび、要するGPUメモリ数や訓練時間は増え、研究する側として大変だった記憶があります。一方で、フルスクラッチにモデルを実装する楽しさやメリットがあったのも、この時代ならではの思い出ですね。モデリングに「きらめきと魔術的な美」がありました。それらはBERTを持ってきてFine-tuningするという流れ作業の登場とともに失われていくのです・・・。
1.4. BERTの登場、そして抽出型要約の再流行 (2019)
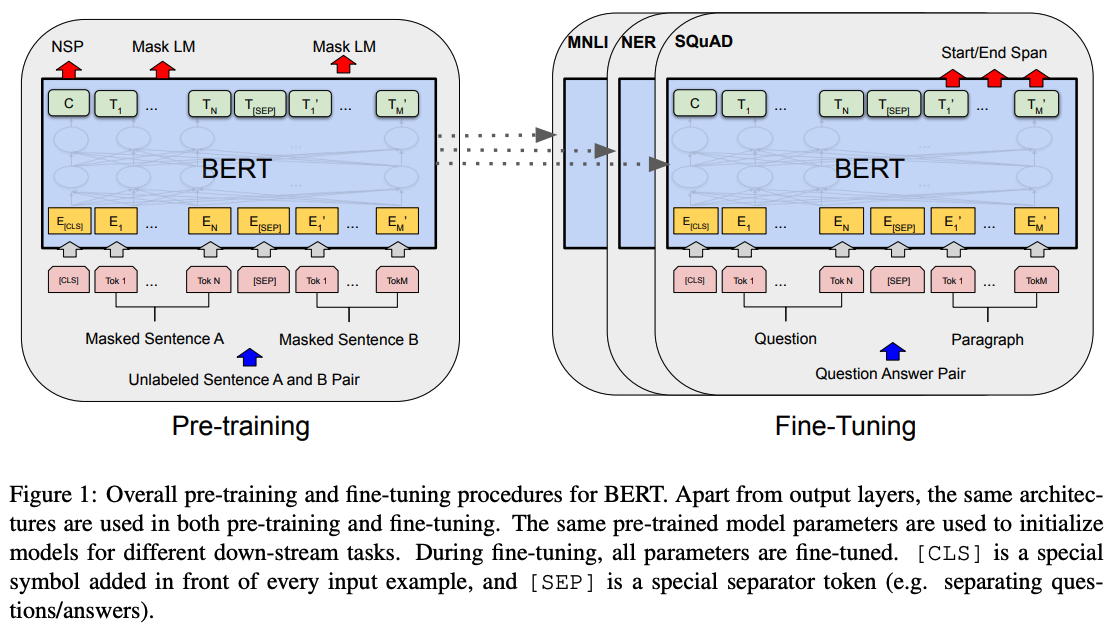
BERT [Devlin et al., NAACL-2019] の登場はNLP史上における革命でした。事前学習済み (Pre-trained) モデルを使用することで、少数のデータでもニューラル言語モデルを訓練することができるようになり、NLPの発展や実用化を大きく妨げていたデータ不足問題を解消する筋道を示したのです。
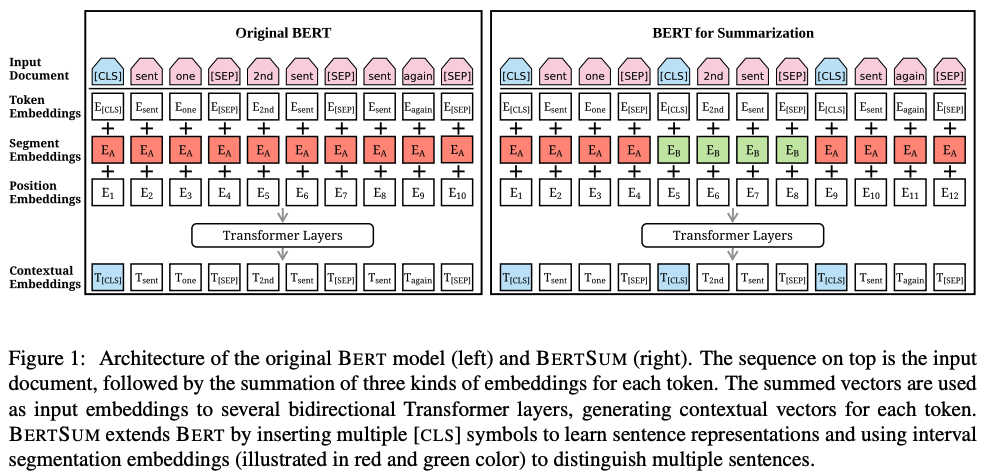
以上はNLPにおける一般論ですが、文書要約においては、他に思わぬ影響をもたらしました。それは抽出型要約の復権です。抽出型要約とは文の二値分類タスクとして捉えることができるのですが、BERTをFine-tuningするのであれば、分類タスクに適応させることがシンプルなのです。代表的なものはHIBERT [Zhang et al., ACL-2019] やBERTSum [Liu and Lapata., EMNLP-2019] です。BERTSumに関しては第3部でまた取り上げる予定ですが、抽象型要約も可能な柔軟なモデルです。
変わったところでは、複数の文書を入力文書とする抽出型要約モデルが [Cho et al., EMNLP-2019] により提案されました。また、細々と続いていたクエリフォーカス要約の系譜にも、BERTを用いた手法 [Zhu et al., 2019] が現れました。このように、BERTをFine-tuningして抽出型要約モデルを訓練するアプローチは非常に汎用性に富んでおり、学術・ビジネス問わず様々なアイデアを実現できるようになりました。
その一方で、BERTはあまりにも巨大で複雑なモデルになり過ぎた気がします。このようなモデルをスクラッチに訓練できる機関は限られており、同等以上のものをフルスクラッチでモデリングをするというのは、より難しいです。こうして一部の人間が事前学習済みモデルを作成し、それ以外は、モデルを使わせてもらう格差の時代へ突入した・・・と思うのは私だけでしょうか?
1.5. BERTを超えたPre-trained Modelへ (2020)
BERTは持たざる者の味方でもありましたが、大規模なモデルを膨大な計算機とデータで訓練するという発想は、持てる者にも多大な影響を与えました。BERTよりも大きなモデルを。より複雑な訓練を。より大量なデータを。こうして、BERTよりも優れた事前学習済みモデルを作る流れが現在の主流です。
文書要約においても、汎用言語モデルのみならず要約に特化したモデルが次々と研究されています。しかし今年の主流は抽象型要約です。持てる者がスクラッチで大規模に訓練する以上は、何も分類タスクにこだわる必要はありません。むしろBERTでさえ高精度な要約を実現できる抽出型要約よりも、未だ品質に難のあった抽象型要約の方を、新たなアプローチで挑戦しようという流れのように思います。
著名なものでは、従来よりも少ないデータでSOTAを達成したPEGASUS [Zhang et al., ICML-2020] や、未来の系列を訓練するProphetNet [Yan et al., EMNLP-2020]、デコード時の露出バイアス (Exposure Bias) に取り組んだERNIE-GEN [Xiao et al., 2020]といったところでしょうか。これらにインスピレーションを与えたBART [Lewis et al., ACL-2020]も抑えておきたいところです。
ここで挙げたモデルの恐ろしい点は、BERTの10倍ほどの巨大なデータによって訓練されていることです。BERTでさえ難しいスクラッチの訓練が、さらに途方もない領域へ突入しているのを目の当たりにしています。この先、我々のような一般人がSOTAを競うことができるのでしょうか・・・?
こうなっては、一刻も早くGPUインスタンスの価格がお安くなるのを願うばかりです。
第2部 文書要約界の知識の体系化
さて、2020年の暮れまでの文書要約の歴史を一通り辿ってみました。どうでしたか?正直、書いている方も目眩がします。
混乱するとしたら、それは時系列順に情報の洪水を浴びせられたからだと思います。体系的に分類すれば、頭の中も整理できるはずです。
第2部ではタスク・アプローチ・データセット・評価方法の4項目に、これまでの情報をまとめていきます。その4項目を押さえれば、きっと論文だって書けるでしょう。
2.1. タスク
文書要約のタスクには、次に挙げるような分類が存在します。
- 複数文書の要約 (Multi-Document Summarization)
- クエリフォーカス要約 (Query Focused Summarization)
- ヘッドライン生成 (Headline Generation)
- キーフレーズ抽出 (Keyphrase Extraction)
このような特殊な分類のいずれにも属さない、一般の要約のことは文書要約 (Text Summarization) と呼びます。前ニューラル時代にはこうした様々なタスクが盛り上がりを見せていたのですが、近年ではアプローチの方法が中心となって要約界を牽引していたように思います。よって、タスクの小分類についてはあまり語らないことにします。(タスクについては、@icoxfog417さんの記事が詳しいです。)
ニッチ層を攻めて採択確率を上げるのであれば、上に挙げたようなジャンルを狙っていくのがいいと思います。競争相手もサーベイ対象も限られるので、論文のストーリーの組み立てが大分簡単になります。レッドオーシャンを少しでも避けたい方はぜひ。一方で、とりあえず情報を多く手に入れようと思うなら、あるいは汎用的な実装を探しているのであれば、普通の文書要約について調べる方が有益でしょう。
2.2. アプローチ
現在の文書要約を語る上で重要なものが、抽出型要約、抽象型要約の二大アプローチです。次の表に示すように、かなり明確に一長一短です。
| 要約の自然さ | 情報の正確さ | |
|---|---|---|
| 抽出型要約 | 不自然 | 正確 |
| 抽象型要約 | 自然 | 不正確 |
要約の自然さ、というのは少しわかりづらい表現かもしれません。ちょっと具体的に説明してみます。例えば、このような文があったとしましょう。『雪国』の冒頭3行です。
国境の長いトンネルを抜けると雪国であった。
夜の底が白くなった。
信号所に汽車が止まった。
この文書を要約する場合、どうしたらよいでしょうか。難しい問題ですが、抽出型要約では、次の例のように行単位で抜き出します。
国境の長いトンネルを抜けると雪国であった。
一方で抽象型要約では、次のような要約文を生成します。(参考: 雪国と Snow Country (上巻))
汽車は長いトンネルを抜け雪国に出た。
抽出型では、原文の文字が正確に再現されている一方で、汽車についての情報が不足しており、要約としては不自然です。片や抽象型では、元の3行の文書の情報をできるだけ自然にまとめている一方で、原文の美しい文字の並びは崩れています。
どちらが要約として相応しいのでしょうか?それは目的によりけりです。文学を楽しみたいのか、教養としてあらすじだけ知れば十分なのか。解きたい問題に合わせて適したアプローチを選択してください。
2.2.1. 抽出型要約 (Extractive Summarization)
『雪国』の例よりも、もう少し丁寧に抽出型要約の特徴を説明します。抽出型要約には、大きく二つの長所と一つの短所があります。
一つ目の長所は、入力文書にない文字列をけして出力しないことです。抽出型要約の結果は、言葉足らずなことはあるかもしれませんが、誤った情報を出力することはありません。二つ目の長所は、一文単位の文の品質はよいことです。文単位でそのまま抜き出すので、文と文の接続に関する部位を除けば、非常に流暢です。そのため、抽出型要約の結果が完全に破綻した要約となることは少なく、基本的に間違った要約にはなりづらいです。
そして短所は、要約の長さを制御しづらいことです。短い要約を生成しようとすると情報が欠落しやすくなり、長い要約を生成しようとすると、冗長な情報を多く含んでしまいがちです。『雪国』の例はその代表的なもので、短い要約を出力しようとしたことで汽車に関する情報が欠落してしまっています。一方で汽車の情報まで含めようとすると、要約として不自然な長過ぎるテキストになってしまいます。また、ドメイン固有の問題として、位置バイアス (positional bias) が挙げられます。これは新聞記事のような、文書の冒頭に要約として必要な情報が詰まっているデータを要約した場合、言語モデルを訓練するというより位置を予測するモデルが訓練されてしまうことです。
抽出型要約として有名な手法は以下のものです。
- 文の二値分類問題 (Sentence Classification) タスクとして解く
- グラフベース (Graph Base Method)
現在、一般的に抽出型要約というと、ニューラル言語モデルを用いて文の二値分類問題を解く手法を指すことが多いと思います。教師なし学習のアプローチを取りたい場合には、TextRankなどグラフベースの手法を用いるとよいでしょう。
最新の手法においては、文単位ではなく発話 (Discourse) というより小さな単位で抽出を行うDiscoBERTが有力です。DiscoBERTでは、抽出型要約の正確さと抽象型要約の簡潔さを上手く組み合わせたモデルと言えます。
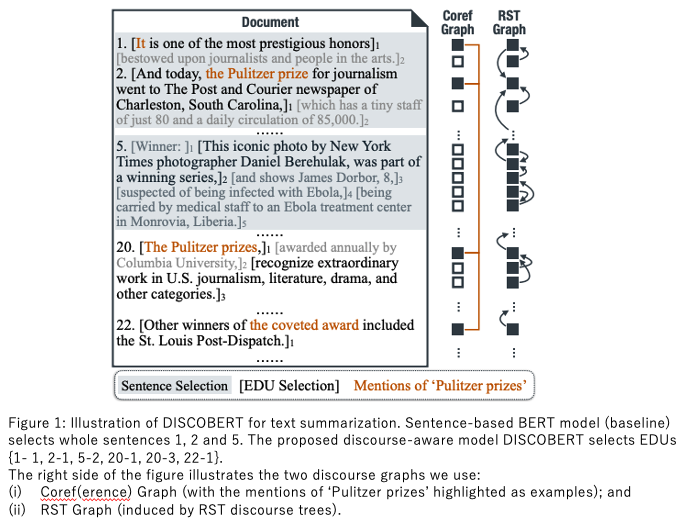
2.2.2. 抽象型要約 (Abstractive Summarization)
抽象型要約の長所と短所は、抽出型要約のそれをひっくり返したものです。
まず長所は要約の長さを制御しやすいことです。文単位で抜き出すという制約がないので、自然な要約になるよう文字列を生成します。人為的に長さを制御する方法としては [Makino et al., ACL-2019]の長過ぎる文にペナルティを与える手法などが挙げられます。要約というのは何文字の要約が欲しいのかが場面によって異なるので、ビジネス的な需要も大きく見込めます。
一方で短所は、生成する文字列の不正確性 (inaccurately) です。これにより入力文書にない情報を出力したり、文法的におかしなシーケンスを生成してしまう可能性があります。矛盾した要約、ノイズにあふれた要約が得られることも少なくありません。ある系列の無意味な繰り返し (repeatition) や重要ではない情報を生成してしまう問題 (poor content) も不正確性の一種と言えるでしょう。その他に、Encoder-Decoderモデル共通の問題として、露出バイアス (exposure bias) が挙げられます。これはLeft-to-Rightにデコードを実施する際、文末の単語を予測する際に大きなバイアスが掛かってしまうことです。
抽象型要約の代表的なものを下に示します。基本的にすべてEncoder-Decoderモデルです。
- BERTSumABS [Liu and Lapata, EMNLP-2019]
- BART [Lewis et al., ACL-2020]
- PEGASUS [Zhang et al., ICML-2020]
- BART-RXF [Aghajanyan et al., ICLR-2021]
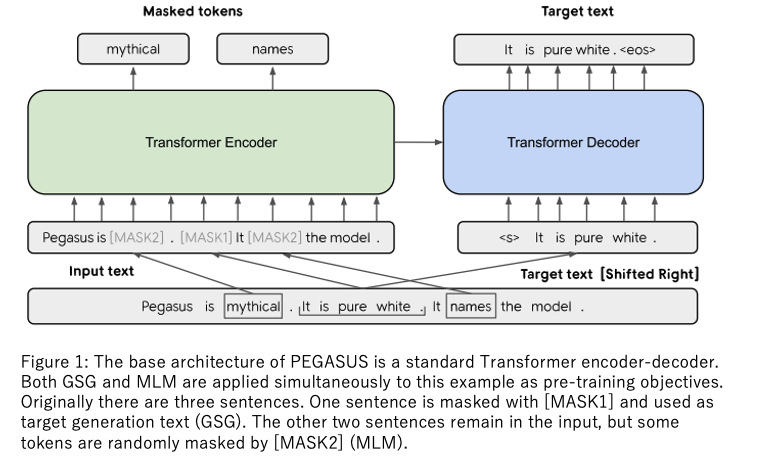
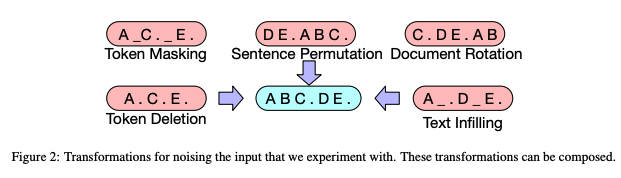
今年も様々な手法がSOTAを争いましたが、それらの最新手法は、BARTのアイデアを元にしているものが多いです。BARTはBERTの10倍のデータを用いて事前学習を実施したことで有名ですが、文を並び替えたり単語を位置情報ごと削除したりと様々なノイズを与えた状態での文の復元に注目した訓練方法を採用しています。NLPは画像のような回転させたり二値化したりといったオーグメンテーションが難しい、と言われていましたが、下図のBARTの例のようにノイズを付与することで効果的なオーグメンテーションを実現しています。
XSumデータセットにおけるROUGEスコアの向上に見られるように、今年の抽象型要約の進化は著しいものでした。抽出型よりもはるかに難しいとされる抽象型要約ですが、近いうちに実用的な品質のものが登場するでしょう。
2.3. データセット
比較的、人気のありそうな文書要約用データセットをまとめました。論文を通そうと思うのであれば、次の中から2,3コーパス選べば査読で言いがかりをつけられないと思います。
- CNN/DailyMail [Herman et al., NIPS-2015]: 新聞記事の要約。非常によく使われるデータセット
- NYT dataset [Sandhaus et al., 2008]: 新聞記事の要約。こちらも頻繁に見かける
- XSum [Narayan et al., EMNLP-2018]: データ数は多めだが、要約の品質は不安定な気がする
- DUC 2004 [Over et al., 2007]: 歴史のあるコーパス。少し古い論文ではよく使われている
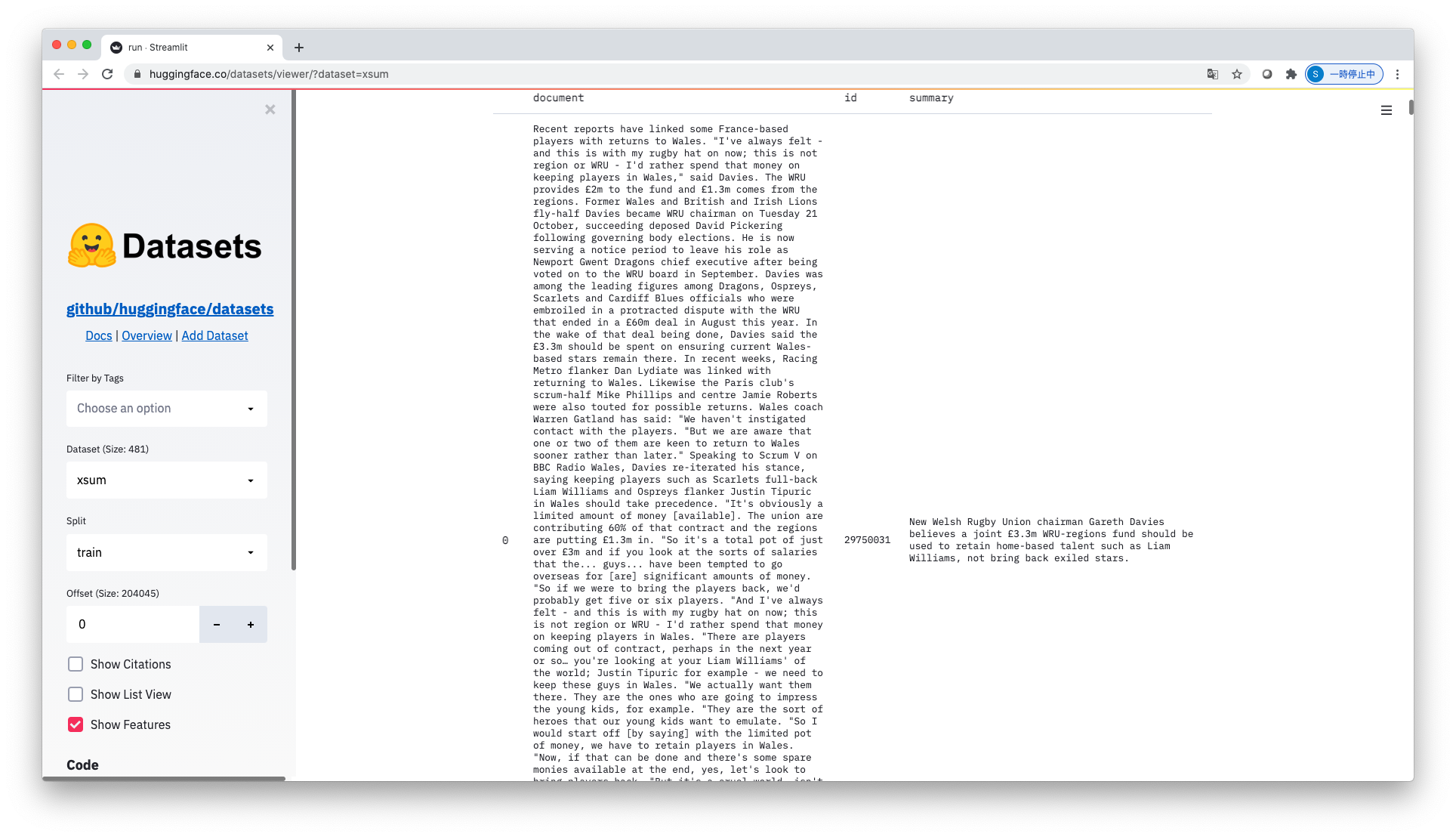
最近はHuggingFaceでどのようなデータなのか確認することができます。下に示すのは、XSumの入力文書・要約の例です。他にCNN/DailyMailなどもあるので、色々と触ってみてください。
2.4. 評価方法
2.4.1. 自動評価 (Automatic Evaluation)
定量的な自動評価には多くの穴があるものの、その手軽ゆえに主流の評価方法となっています。自動評価の有無がタスクの発展性を左右する大きな要因の一つです。
2.4.1.1. N-gramの単語一致率を計算する手法
もっともシンプルな自動評価の方法は、単語のオーバーラップを測るものです。次に挙げるものは、現在の主要な評価指標とされています。
ROUGEは生成した要約がどれだけ真の要約をカバーできたか、ということを示す指標です。一方で、BLEUは生成した要約がどれだけ真の要約とあっているか、を示します。個人的には、RecallとPrecisionの関係に近いと考えています。この中ではROUGE-1, ROUGE-Lがよく使われます。BLEUとMETEORは機械翻訳で一般的な指標で、要約ではたまに使われることがある、という程度です。
2.4.1.2. セマンティックな一致度を計算する手法
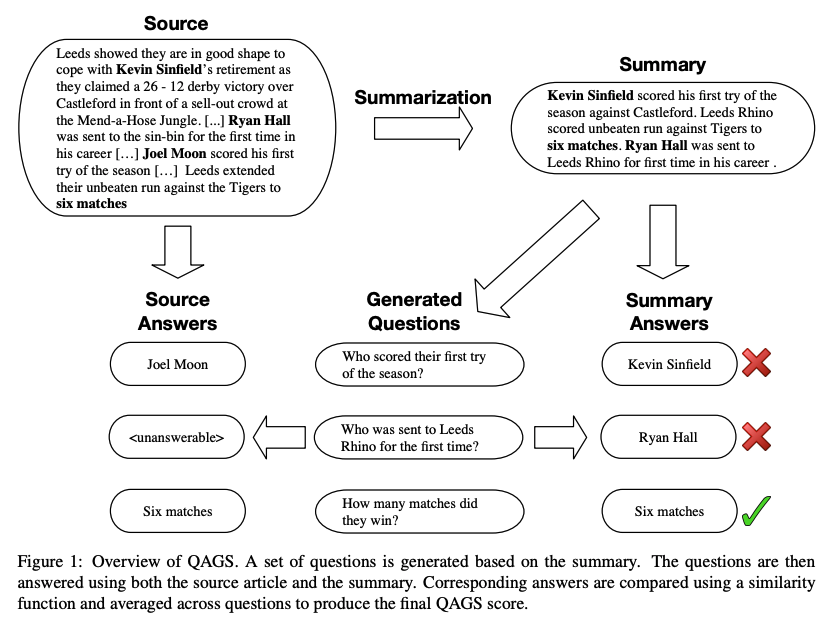
分散表現の発展により、文法的 (Syntactic) な一致度よりも、意味的 (Semantic) な一致度を自動評価することができるようになりました。NLPの様々なタスクで広く使われているのはBERTScore [Zhang et al., ICLR-2020]ですが、要約においてはより専門的な手法として、要約から質問文を生成し、入力文書・質問文の対が出す答えと、要約・質問文の対が出す答えの間の一致度を測るQAGS [Wang et al., ACL-2020]が提案されています。
2.4.2. 人手評価 (Human Evaluation)
要は人間が目で見て、いい要約かわるい要約か判断することです。非常に大変で、作業者の確保や判断基準といった、多くの問題を抱えていますが、これまでに上げたような自動評価 (Automatic Evaluation) だけでは定性的な評価ができないため、最後には実施せざるを得ません。
2.4.2.1. 二つの要約モデルの比較
人手評価の中では一番簡単です。入力文書・真の要約・モデルAの要約結果・モデルBの要約結果を並べて、どちらの要約結果が優れているかを数え上げます。従来法と提案法とで比較して、提案法がよかった件数が多ければ、ひとつの主張になります。ただ、これだけだとどうにも弱いので、自動評価と組み合わせることをおすすめします。
下表はBARTの論文で使われた、BARTと従来法の比較です。単純ですが、論文の説得力を補強するのに手頃です。
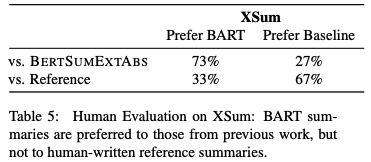
2.4.2.2. 性質の評価
要約では可読性 (Readability) や流暢さ (Fluency) 、情報量の多さ (Informative) 、内容の一貫性 (Consistency)といった性質が重要です。これらの要素を五段階評価などでレビューしていくことで、より定性的な面からモデルを評価することが出来ます。
2.4.2.3. 質問応答ベース (QA-based Evaluation)
評価者に質問を与え、モデルの要約結果を見ながら答えてもらうものです。QAGSを人手でやるようなものでしょうか。質問と答えのペアを作る必要があったり、質問に答えられているかどうかの評価をさらに行う必要があるので、とてもコストのかかる方法ですが、丁寧に評価できる点が長所です。
2.4.2.4. ポストエディット (Human post-editing)
要約モデルの結果の誤りを評価者に修正してもらう方法です。評価の方法はいくつかあると思いますが、[Makino and Iwakura, ACL-2019]では修正にかかった時間を測定し、短いほうを優れた要約モデルであると見なすアプローチを用いています。
第3部 BERTSumによるデモ
おまたせしました。ようやく手を動かして要約をするフェーズに入ります。
ここで取り上げるのはBERTSum [Liu and Lapata, EMNLP-2019]です。BERTSumの優れている点は簡単に動かせるところですね。BERTとOpenNMTをところどころ借りた感じの実装なので、NLPerにとっては割と馴染みやすいと思います。(コードのリファクタはもっとしてほしいですが・・・)
3.1. 準備+環境設定
注:私の環境はデフォルトで色んなものが入っているため、一部抜け漏れがある可能性があります。
まずは変数を設定し、各種インストール作業を実施しましょう。
STORY_PATH=/path/to/story
CLASSPATH=/path/to/stanford-corenlp-full-2017-06-09/stanford-corenlp-3.8.0.jar
RAW_PATH=/path/to/corpus_dir
TOKENIZED_PATH=/path/to/tokenized_dir
JSON_PATH=/path/to/json_dir
BERT_DATA_PATH=/path/to/bert_data_dir
MODEL_PATH=/path/to/model_dir
cd /path/to/workspace
git clone https://github.com/nlpyang/PreSumm
cd PreSumm
pip install -r requirements.txt
PreSumm本体のインストールができたら、CNN/DailyMail データセットをダウンロードして$STORY_PATHに展開してください。また、Stanford CoreNLPも同様にダウンロードして、$CLASSPATHに展開してください。
3.2. 前処理
まずはトークナイズを行い、終端記号毎に区切ります。その後、データをサンプリングしてバッチを作成します。
cd src # PreSumm/src
python preprocess.py -mode tokenize -raw_path $RAW_PATH -save_path $TOKENIZED_PATH
python preprocess.py -mode format_to_lines -raw_path $RAW_PATH -save_path $JSON_PATH -n_cpus 1 -use_bert_basic_tokenizer false -map_path $MAP_PATH
python preprocess.py -mode format_to_bert -raw_path $JSON_PATH -save_path $BERT_DATA_PATH -lower -n_cpus 1 -log_file ../logs/preprocess.log
3.3. モデル訓練
今回は抽出型モデルであるBERTSumEXTを訓練してみます。
python train.py -task ext -mode train -bert_data_path $BERT_DATA_PATH -ext_dropout 0.1 -model_path $MODEL_PATH -lr 2e-3 -visible_gpus 0,1,2 -report_every 50 -save_checkpoint_steps 1000 -batch_size 3000 -train_steps 50000 -accum_count 2 -log_file ../logs/ext_bert_cnndm -use_interval true -warmup_steps 10000 -max_pos 512
3.4. 推論および評価
それでは評価してみましょう。
python train.py -task abs -mode validate -batch_size 3000 -test_batch_size 500 -bert_data_path $BERT_DATA_PATH -log_file ../logs/val_abs_bert_cnndm -model_path $MODEL_PATH -sep_optim true -use_interval true -visible_gpus 1 -max_pos 512 -max_length 200 -alpha 0.95 -min_length 50 -result_path ../logs/abs_bert_cnndm
要約結果の一例をお見せします。
| text | |
|---|---|
| 入力文書 (Source) | ( cnn ) japanese prime minister shinzo abe is scheduled to speak wednesday to a joint meeting of congress . the address marks the first time in history that the head of the japanese government will address the entire u.s. congress , and given the importance of the u.s. - japan relationsh ip , it is an invitation long overdue . so far , prime minister abe 's appearance has garnered much less attention than last month 's speech to congress by israeli prime minister benjamin netanyahu . this is not surprising ; in a recent survey by the pew research center nearly three - quarters of the respondents indicated they had " never heard of " shinzo abe , underscoring just how difficult it is for the obama administration to sell its much - vaunted " pivot " or " rebalance " to the american public . nevertheless , abe arrives in washington at an opportune time to help along the economic centerpiece of the " pivot , " the trans - pacific partnership free trade agreement , or tpp . the tpp is a potentially ... (省略) |
| 真の要約 (Reference / Gold) | japanese prime minister shinzo abe will address congress on wednesday . paul sracic : abe has a lot riding on tpp trade agreement . |
| 抽出型の要約 (BERTSumEXT) | ( cnn ) japanese prime minister shinzo abe is scheduled to speak wednesday to a joint meeting of congress . nevertheless , abe arrives in wash ington at an opportune time to help along the economic centerpiece of the " pivot , " the trans - pacific partnership free trade agreement , or tpp . but the immediate battle in congress is not over the tpp directly , but something called trade promotion authority , or " fast - track . " |
あまりにも長すぎるので入力文書は省略していますが、この膨大な文書から重要な箇所だけを上手く抽出できていそうなことがおわかりいただけるでしょうか?これが文書要約の世界で積み重ねられた研究の結果です。ちょっと感動しますね。
ここでは一部分しかお見せすることが出来ませんが、BERTSumをいじくり回していると色々な姿が見えてきます。第2部でまとめた問題点もたくさん出てきますし、後続の手法がそれらを改善できそうだというのもわかるかと思います。知識をインプットしては、実際に触ってみて、そしてこうしてアウトプットをする、ということをして、これを読み返したときの自分が成長できていると嬉しいです。
おわりに
今年一年溜め込んだ知識を活かす機会がなかったので供養しました。がんばって調べたものを墓場まで持っていくしかないのは悲しいので、この場で吐き出させてもらえて感謝です。時間が切れたのでこの辺りで終わりにしておきますが、まだ書ききれてないことも多くて心残り・・・。
残りはTwitter(siida36@Toujika25)にでも流しておくので、よかったら見てください。
参考文献
- A. Aghajanyan, A. Shrivastava, A. Gupta, N. Goyal, L. Zettlemoyer, S. Gupta. 2021. Better Fine-Tuning by Reducing Representational Collapse. in ICLR. arXiv preprint arXiv:2008.03156.
- D. Bahdanau, K. Cho, Y. Bengio. 2015. Neural Machine Translation by Jointly Learning to Align and Translate. in ICLR. arXiv preprint arXiv:1409.0473.
- S. Banerjee and A. Lavie. 2005. METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments. in Proc. ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, pp.65–72.
- M. Banko, V. O. Mittal, M. J. Witbrock. 2000. Headline Generation Based on Statistical Translation. in Proc. 38th ACL, pp.318–325.
- J. Devlin, M. W. Chang, K. Lee, and K. Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. in Proc. NAACL, pp.4171–4186.
- A. Celikyilmaz, A. Bosselut, X. He, Y. Choi. 2018. Deep Communicating Agents for Abstractive Summarization. in Proc NAACL, pp.1662–1675.
- S. Cho, C. Li, D. Yu, H. Foroosh, F. Liu. 2019. Multi-Document Summarization with Determinantal Point Processes and Contextualized Representations. in Proc. 2nd Workshop on New Frontiers in Summarization, pp.98–103.
- S. Gehrmann, Y. Deng, A. Rush. 2018. Bottom-Up Abstractive Summarization. in Proc. EMNLP, pp.4098–4109.
- K. M. Hermann, T. Kocisky, E. Grefenstette, L. Espeholt, W. Kay, M. Suleyman, and P. Blunsom. 2015. Teaching machines to read and comprehend. in Proc. 28th NIPS, pp.1693–1701.
- K. Knight and D. Marcu. 2000. Statistics-Based Summarization — Step One: Sentence Compression. in Proc. 17th AAAI, pp.703-710.
- C. Y. Lin. 2004. ROUGE: A Package for Automatic Evaluation of Summaries. in ACL, pp.74-81.
- Y. Liu, M. Lapata. 2019. Text Summarization with Pretrained Encoders. in Proc. EMNLP, pp.3730–3740.
- M. Lewis, Y. Liu, N. Goyal, M. Ghazvininejad, A. Mohamed, O. Levy, V. Stoyanov, L. Zettlemoyer. 2020. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. in Proc 58th ACL, pp.7871–7880.
- T. Makino, T. Iwakura, H. Takamura, M. Okumura. 2019. Global Optimization under Length Constraint for Neural Text Summarization. in Proc 57th ACL, pp.1039–1048.
- R. Mihalcea and P. Tarau. 2004. TextRank: Bringing Order into Text. in Proc. EMNLP, pp.404–411.
- K. Papineni, S. Roukos, T. Ward, and W. J. Zhu. 2002. BLEU: a method for automatic evaluation of machine translation. in Proc. 40th ACL, pp.311–318.
- W. Qi, Y. Yan, Y. Gong, D. Liu, N. Duan, J. Chen, R. Zhang, M. Zhou. 2020. ProphetNet: Predicting Future N-gram for Sequence-to-SequencePre-training. in Proc. EMNLP, pp.2401–2410.
- A. M. Rush, S. Chopra, J. Weston. 2015. A Neural Attention Model for Abstractive Sentence Summarization. in Proc. EMNLP, pp.379–389.
- A. See, P. J. Liu, C. D. Manning. 2017. Get To The Point: Summarization with Pointer-Generator Networks. in Proc. 55th ACL, pp.1073–1083.
- I. Sutskever, O. Vinyals, and Q. V. Le. 2014. Sequence to sequence learning with neural networks. in Proc. 27th NIPS, pp.3104–3112.
- J. Suzuki and M. Nagata. 2016. RNN-based Encoder-decoder Approach with Word Frequency Estimation.
- A. Tombros and M. Sanderson. 1998. Advantages of Query Biased Summaries in Information Retrieval. in SIGIR '02: Proc. 21st annual international ACM SIGIR conference on Research and development in information retrieval, pp.2-10
- A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. Gomez, L. Kaiser, and I. Polosukhin. 2017. Attention is all you need. in Proc. 30th NIPS, pp.5998–6008.
- A. Wang, K. Cho, M. Lewis. 2020. Asking and Answering Questions to Evaluate the Factual Consistency of Summaries. in Proc. 58th ACL, pp.5008–5020.
- D. Xiao, H. Zhang, Y. Li, Y. Sun, H. Tian, H. Wu, H. Wang. 2020. ERNIE-GEN: An Enhanced Multi-Flow Pre-training and Fine-tuning Framework for Natural Language Generation. arXiv preprint arXiv:2001.11314.
- J. Xu, Z. Gan, Y. Cheng, J. Liu. 2020. Discourse-Aware Neural Extractive Text Summarization. in Proc. 58th ACL, pp.5021–5031.
- J. Zhang, Y. Zhao, M. Saleh, P. J. Liu. 2020. PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization. in ICML.
- T. Zhang, V. Kishore, F. Wu, K. Q. Weinberger, Y. Artzi. 2020. BERTScore: Evaluating Text Generation with BERT. in ICLR. arXiv preprint arXiv:1904.09675.
- X. Zhang, F. Wei, M. Zhou. 2019. HIBERT: Document Level Pre-training of Hierarchical Bidirectional Transformers for Document Summarization. in Proc. 57th ACL, pp.5059–5069.
- H. Zhu, L. Dong, F. Wei, B. Qin, T. Liu. 2019. Transforming Wikipedia into Augmented Data for Query-Focused Summarization. arXiv preprint arXiv:1911.03324.