Summary
Transformer[Vaswani+17]のattentionがどこに向いているのかを分析した。結果として、低次の層では表面的な文法に、高次の層では文の持つ意味に対してattentionが向く傾向にあることがわかった。
Data
WMT18のshared taskで提供されたニュース翻訳文からなる対訳コーパスを用いる。
ダウンロード元:http://data.statmt.org/wmt18/translation-task/preprocessed/
| 言語 | 文数 |
|---|---|
| English-Czech | 51,391,404 |
| English-German | 25,746,259 |
| English-Estonian | 1,064,658 |
| English-Finnish | 2,986,131 |
| English-Russian | 9,140,469 |
| English-Turkish | 205,579 |
| English-Chinese | 23,861,542 |
Model settings
OpenNMTによる実装でのTransformerモデルを使用。ハイパーパラメータは[Vaswani+17]の設定に従う。データはBPE[Sennrich+16]によって未知語のない10万語彙にtokenizeされ、訓練は20 epochs行われた。
Evaluation
4種類のアプローチからattentionの分析を行う。
Visualization
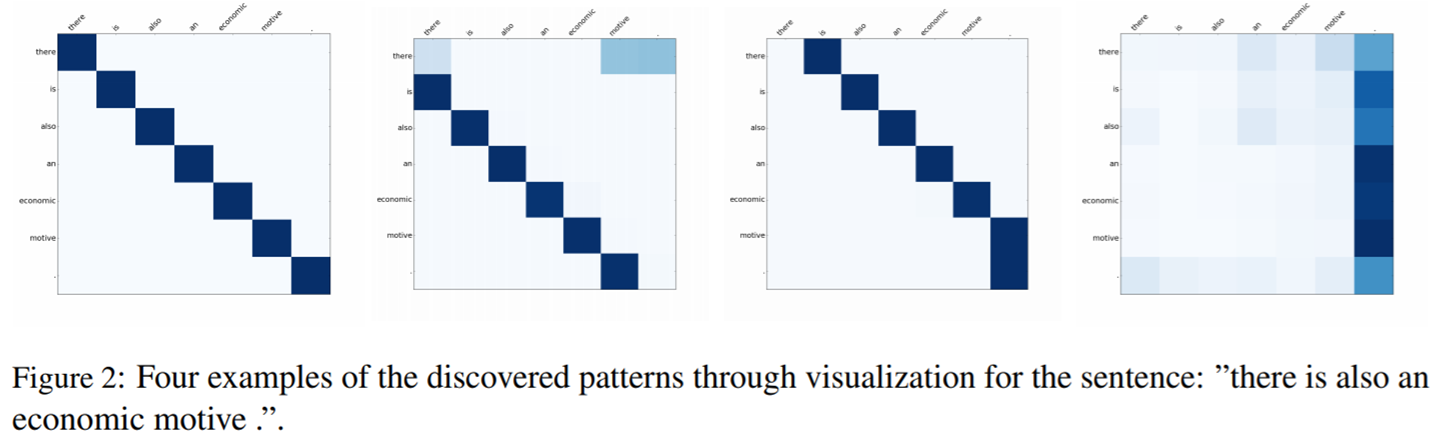
縦軸と横軸は同じ単語の並び"there/is/also/an/economic/motive/."である。
- 左から1枚目:自分自身へattentionが向いている
- 左から2枚目:前の単語へattentionが向いている
- 左から3枚目:前の単語へattentionが向いている
- 左から4枚目:文末へattentionが向いている
Transformerの最初の層では、一番左の画像のように、自分自身の単語にattentionが向いている。それがより高次の層になるにつれ、隣の単語へ、より遠くの単語へのattentionが向くようになってゆく。
Inducing Tree Structure
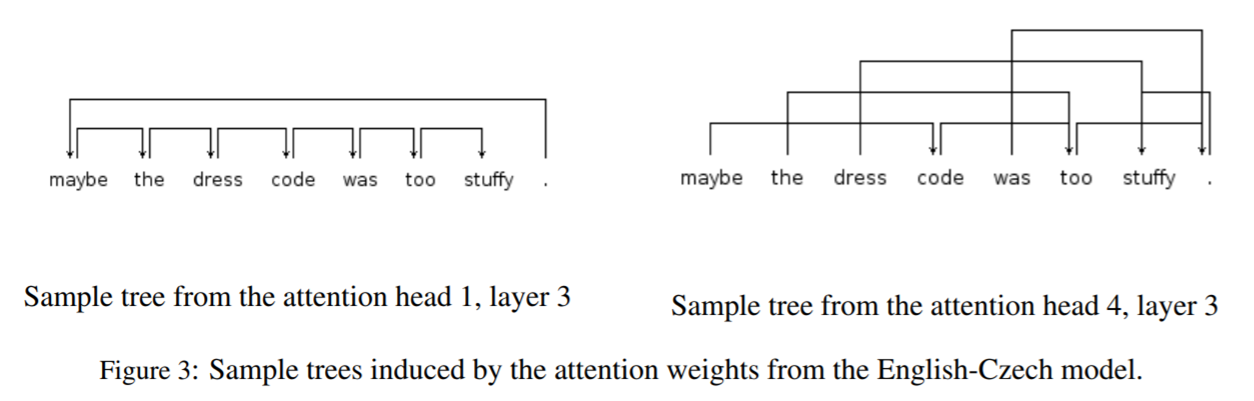
同じ層の中でも、Headによって近くの単語にattentionを向けているのか、遠くの単語にattentionを向けているのかが異なっている。
Probing Sequence Labeling Tasks
機械翻訳のタスクで学習したEncoderのパラメータを使い4種類の異なるタスクを解かせることで、attentionがどのような働きを持っているのかを検証した。Decoder側はすべて一層のmulti-head attentionとFFNNからなり、またEncoderのパラメータは固定してDecoderのパラメータのみ更新する。
まずはタスクの概要を示す。
| タスク | タスクの解説 | 使用されたデータセット | データセットの規模 (train+test) |
|---|---|---|---|
| Part-of-Speech(PoS) tagging | 単語の品詞を判定する | Universal Dependencies English Web Treebank v2.0 | 13,543文 |
| Chunking | 文を文節で区切る | the CoNLL2000 Chunking shared task | 10,054文 |
| Named Entity Recognition(NER) | 固有表現抽出 (東京→地名、太郎→人名、等) |
the CoNLL2003 NER shared task | 18,671文 |
| Semantic Tagging(SEM) | 文の意味を判定する | Parallel Meaning Bank (PMB) | 67,090文 |
各タスクのprecisionを測ったところ、PoS taggingやChunkingでは低次の層、NERでは中間の層、SEMでは高次の層で優れた結果が得られる傾向にあった。すなわち、低次の層は品詞や文節へのattentionを、高次の層は意味へのattentionを向けようとしていることがわかる。
Transfer Learning
English-Germanの翻訳タスクで訓練したEncoderのパラメータをEnglish-Turkishの翻訳タスクの初期値に利用することで、利用しなかった場合に比べてよい成果を出した。
| モデル | newstest 2017 | newstest 2018 |
|---|---|---|
| baseline | 6.93 | 6.22 |
| Fine tuning | 8.72 | 7.93 |
| Transfer Learning | 7.82 | 6.91 |
Transfer LearningはEncoderのパラメータを更新しない。Fine tuningではTransfer Learningをした後でEncoderのパラメータを更新する。